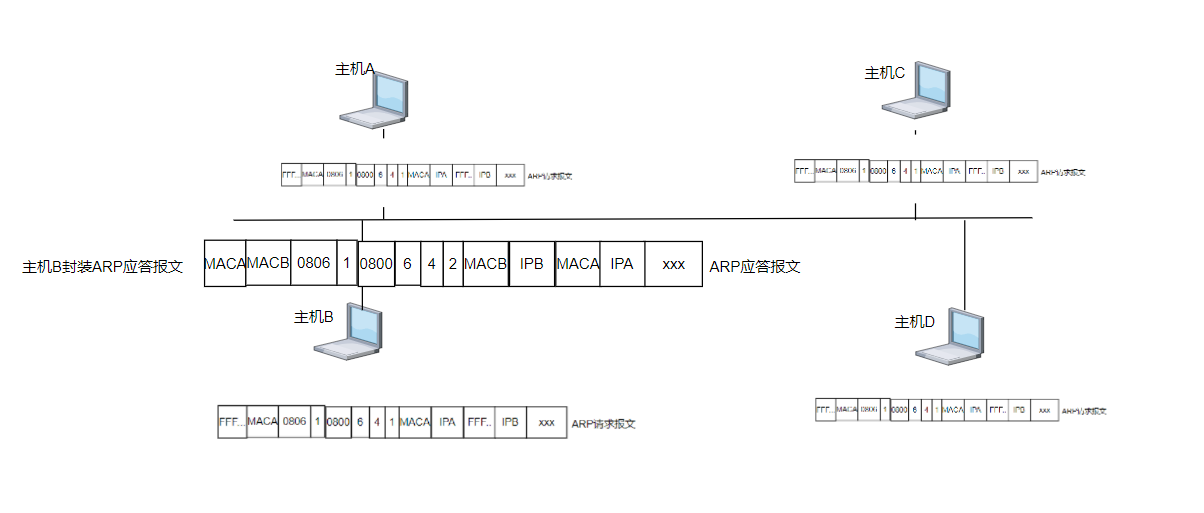
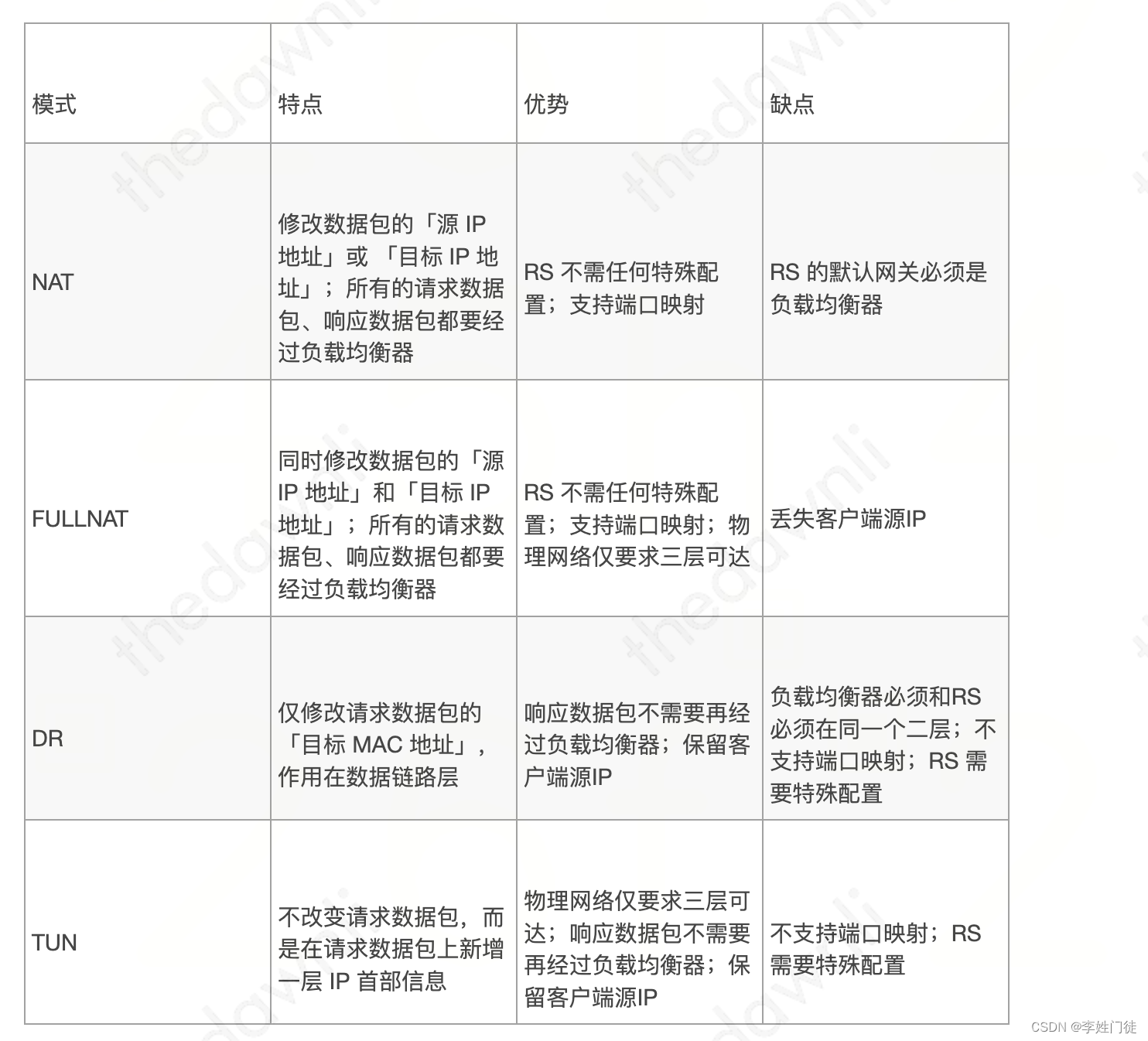
Golang里map底层数据结构具体如下图所示:

map其实就是一个指向 hmap 的指针,占用了8个字节
hmap各自段存放的字段意义如下:
| 字段 | 含义 |
|---|---|
| count | map中元素的个数,对应len (map)的值 |
| flags | 状态标志位,标记map的一些状态 |
| B | 桶数以2为底的对数,即B=log_2(len(buckets)),比如B=3,那么桶数为2^3=8 |
| noverflow | 溢出桶数量近似值 |
| hash0 | 哈希种子 |
| *buckets | 指向buckets数组的指针,buckets数组的元素为bmap,如果数组元素个数为0,其值nil |
| *oldbuckets | 是一个指向buckets数组的指针,在扩容时,oldbuckets 指向老的buckets数组(大小为oldbuckets为空 |
| nevacuate | 表示扩容进度的一个计数器,小于该值的桶已经完成迁移 |
| extra | 指向mapextra结构的指针,mapextra存储map中的溢出桶 |
bmap数组内各自段存放的字段意义如下:
| 字段 | 含义 |
|---|---|
| tophash | 代表哈希桶中该元素的高字节,在哈希冲突发生时,快速对比两个键的高字节判断是否相等,避免每次都需要比较完整的键,提高了比较的效率 |
| keys | 存储了bmap里8个key/value键值对的key |
| values | 存储了bmap里8个key/value键值对的value |
| *overflow | 指向溢出桶的指针 |
hmap其中最重要的就是buckets,它指向了一个包含多个结构为bmap(桶)的bucket数组,bucket的底层采用链表将bmap链接起来。
[]bmap是一个底层数组,我们把它称之为 桶(哈希桶)数组 ,它被*buckets所指向,是真正用于存储数据的地方。

每一个bmap能存储8个键值对,当map中的数据过多,bmap数组存不下的适合就会存储到extra指向的溢出的bucket(桶)里面

| 字段 | 含义 |
|---|---|
| overflow | 溢出桶链表地址 |
| nextOverflow | 下一个空闲溢出地址 |
因为哈希冲突的原因,所以一般[]bmap数组只存放一个指针,该指针指向一个链表用于存放键值对
哈希冲突是什么意思?
存储一个key / value 键值对时,存放到正确的位置需要进行两个步骤
1.通过哈希函数hashFunc计算hash值
2.计算索引位置 (hash值对桶取模得到索引值)
但是如果有两个键值对通过计算得到的哈希值相同,这两个键值对的索引也必然相同,那么也会存放到同一个位置,那该怎么处理?覆盖某一个键值对?舍弃某一个键值对? 这就是哈希碰撞的问题,当然,对于这两组键值对最后的处理结果,必然是都存储下来的。
解决哈希碰撞一般都有两种方式:拉链法和开放寻址法
拉链法:
在buckets中不存储数据元素,而是存放指针,该指针指向一个链表,当出现key1和key2哈希值相同的情况,那就将数据链接到链表上,如果没有出现哈希碰撞的情况,buckets数组中某个索引位置存放的指针,指向的链表中自然只有一个元素了。
当链表元素过长,则推荐使用红黑树代替链表

开放寻址法
开放地址法是另外一种非常常用的解决哈希冲突的策略,与拉链法不同,开放地址法是将具体的数据元素存储在数组桶中,在要插入新元素时,先根据哈希函数算出hash值,根据hash值计算索引,如果发现冲突了,计算出的数组索引位置已经有数据了,就继续向后探测,直到找到未使用的数据槽为止。

在存储键值对<b,101>的时候,经过hash计算,发现原本应该存放在数组下标为2的位置已经有值了,存放了<a,100>,就继续向后探测,发现数组下标为3的位置是空槽,未被使用,就将<b,101>存放在这个位置。