在本文中,为了实现高效的信息抽取,我们采用了一个自主研发的多模态AI的大模型NLP平台。
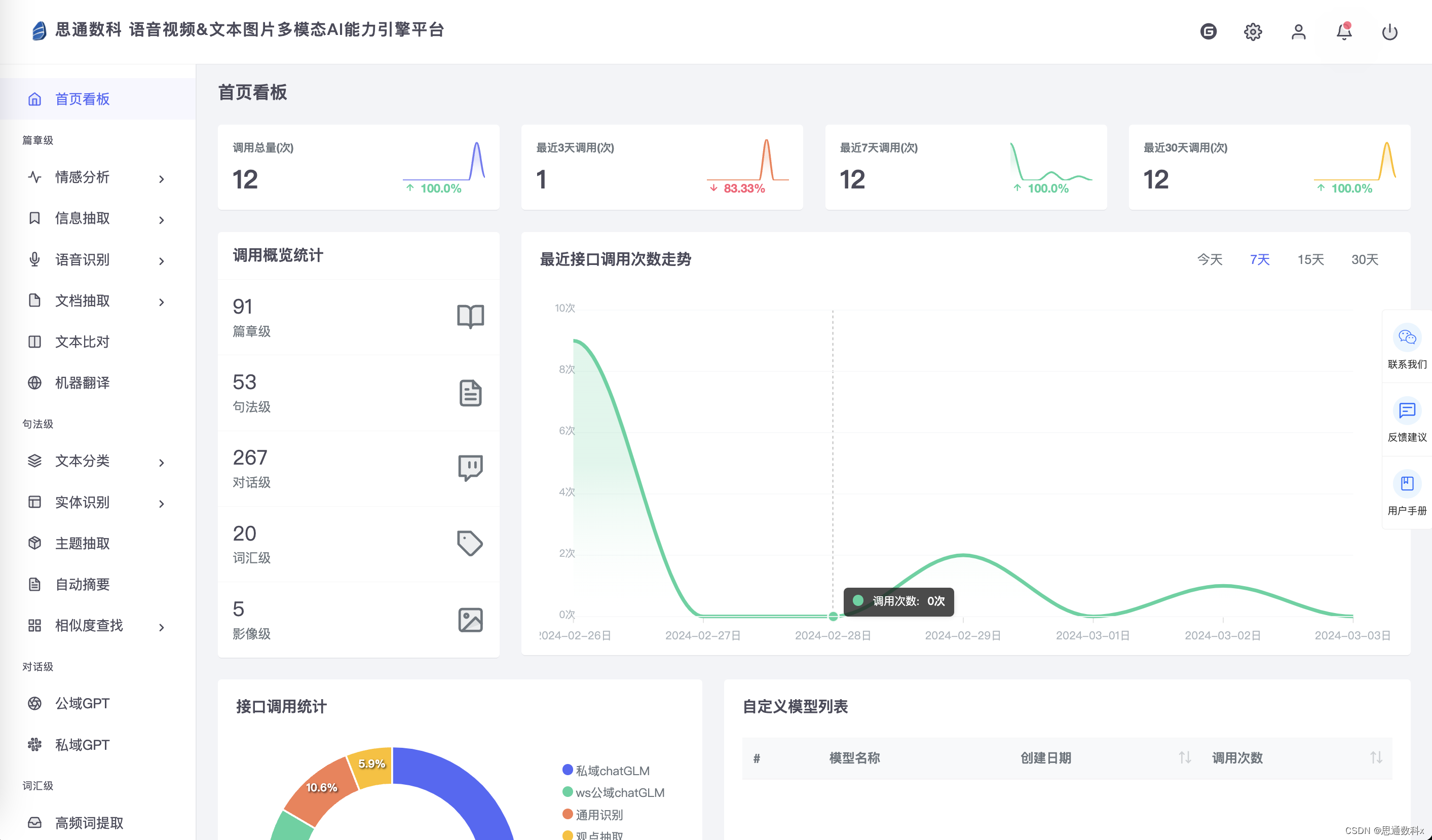
这个平台的使用过程分为以下几个步骤:
- 数据收集:我们收集了与项目相关的100条数据样本,这些样本涵盖了各种商品描述,以便更好地捕捉到项目所需的各种情况。
- 数据清洗:我们对收集到的数据进行了预处理,包括去除无关信息、纠正拼写错误、标准化术语等,以确保数据质量。
- 样本标注:通过该平台的在线标注工具,我们对数据进行了标注。标注过程中,我们确保所有标注者遵循相同的标准,以保证标注的一致性。经过多轮标注和校对,我们得到了高质量的标注数据。
- 样本训练:根据标注的数据,我们提取了文本特征,如词性标注、命名实体识别(NER)、依存句法分析等。我们使用这些标注好的数据样本训练了模型,并通过调整模型参数来优化性能。
- 模型评估:我们选择了精确度(Precision)、召回率(Recall)和F1分数等评估指标,来衡量模型的性能。我们使用交叉验证等方法来确保模型的泛化能力,避免过拟合。根据评估结果,我们对模型进行了多次迭代,以达到最佳性能。
- 结果预测:将训练好的模型部署到生产环境中,以便对新的文本数据进行信息抽取。模型接收新的文本输入,自动执行信息抽取任务,输出结构化的结果。
通过上述过程,我们成功地应用了NLP平台,实现了商品描述文本中关键信息的提取。这一技术的应用不仅提高了库存管理的效率,还为市场营销策略的制定提供了有力支持,使零售企业能够更好地满足消费者需求,提高市场竞争力。

伪代码示例
import requests
# 设置API端点和访问密钥
api_endpoint = "https://nlp.stonedt.com/api/extract"
secret_id = "your_secret_id"
secret_key = "your_secret_key"
# 准备要抽取的商品描述文本
text_to_extract = "一款蓝色运动鞋,适用于室内室外场地,净含量500毫升,售价9.99美元。"
# 设置请求参数
params = {"text": text_to_extract,"sch": "日常食品、日用品等商品,如沃尔玛、家乐福等","modelID": 123456 # 假设的模型ID
}
# 设置请求头
headers = {"Authorization": f"Bearer {secret_id}:{secret_key}"
}
# 发送请求到NLP平台进行信息抽取
response = requests.post(api_endpoint, json=params, headers=headers)
# 解析抽取结果
if response.status_code == 200:extraction_result = response.json()print("抽取结果:", extraction_result)
else:print("请求失败,状态码:", response.status_code)
数据库表设计
CREATE TABLE product_info (id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(255) NOT NULL,product_description TEXT NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,FOREIGN KEY (id) REFERENCES extracted_data(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE extracted_data (id INT AUTO_INCREMENT PRIMARY KEY,param_name VARCHAR(255) NOT NULL,param_value VARCHAR(255) NOT NULL,entity_name VARCHAR(255) NOT NULL,relationship_type VARCHAR(255) NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,product_info_id INT,FOREIGN KEY (product_info_id) REFERENCES product_info(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
在本项目中,我们需要存储从接口返回的数据。为了实现这一目标,我们将设计一个关系型数据库的表结构。以下是DDL语句,用于创建相关表:
以下是每个表字段的注释:
1.product_info 表:
a.id:商品信息的唯一标识符(主键)。
b.product_name:商品名称。
c.product_description:商品描述文本。
d.created_at:商品信息创建时间。
e.updated_at:商品信息更新时间。每当有数据更新时,此字段会自动更新。
2.extracted_data 表:
a.id:抽取数据的唯一标识符(主键)。
b.param_name:抽取的参数名称。
c.param_value:参数值。
d.entity_name:实体名称。
e.relationship_type:实体之间的关系类型。
f.created_at:抽取数据创建时间。
g.updated_at:抽取数据更新时间。每当有数据更新时,此字段会自动更新。
h.product_info_id:外键,引用 product_info 表的 id 字段,表示此抽取数据所属的商品信息。
通过这两个表,我们可以存储从接口返回的数据,包括商品名称、描述、抽取的参数、实体及其关系等。这将有助于我们进一步分析和处理数据,以提高库存管理和市场营销策略的精确度。
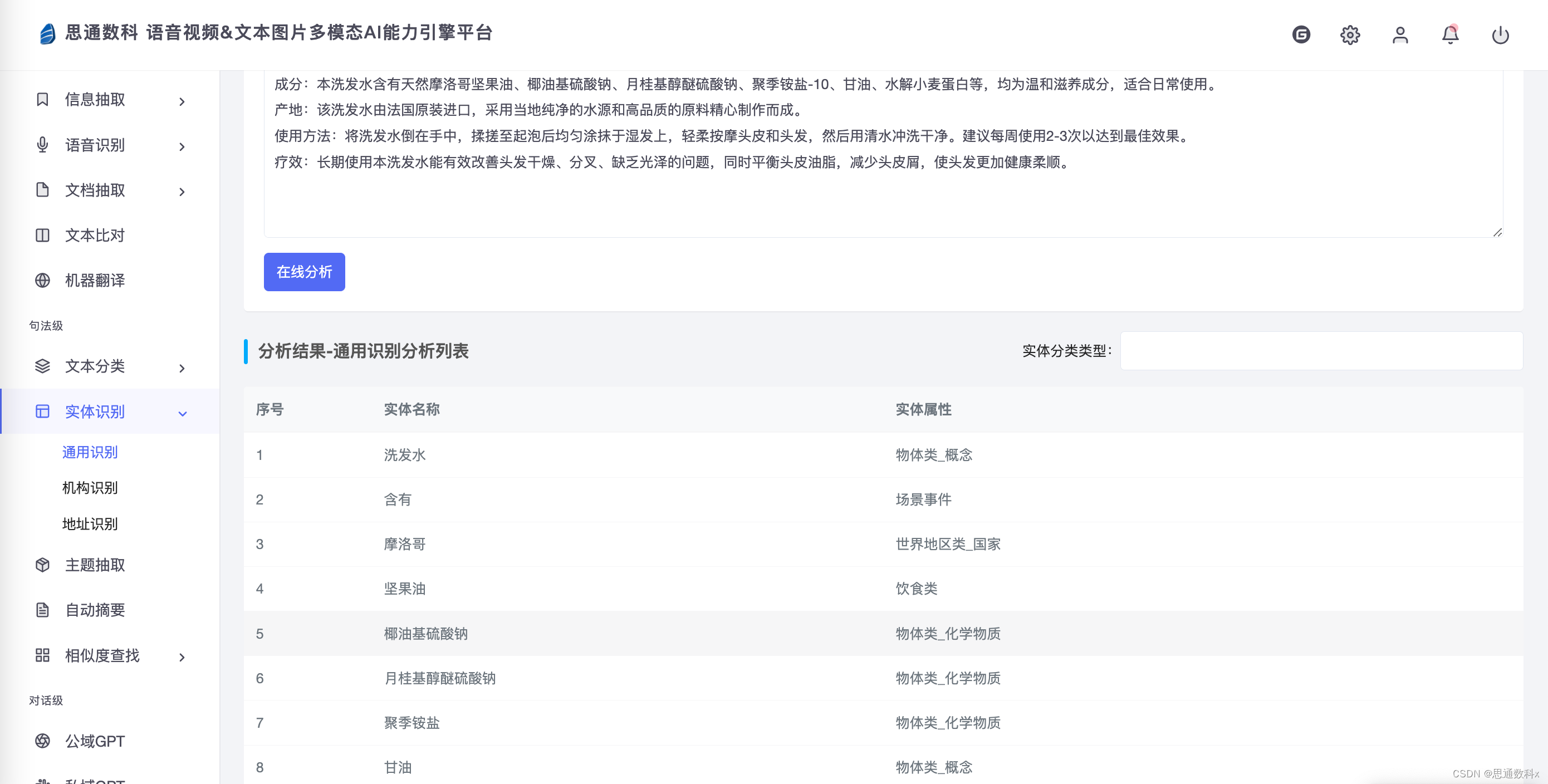
该信息抽取技术成果显著,通过信息抽取技术的实施,我们成功提升了数据处理的自动化程度。在项目初期,数据处理依赖大量的人工操作,成本高昂且效率受限。而如今,自动化技术的应用大幅降低了人工成本,提高了数据处理速度和准确性。
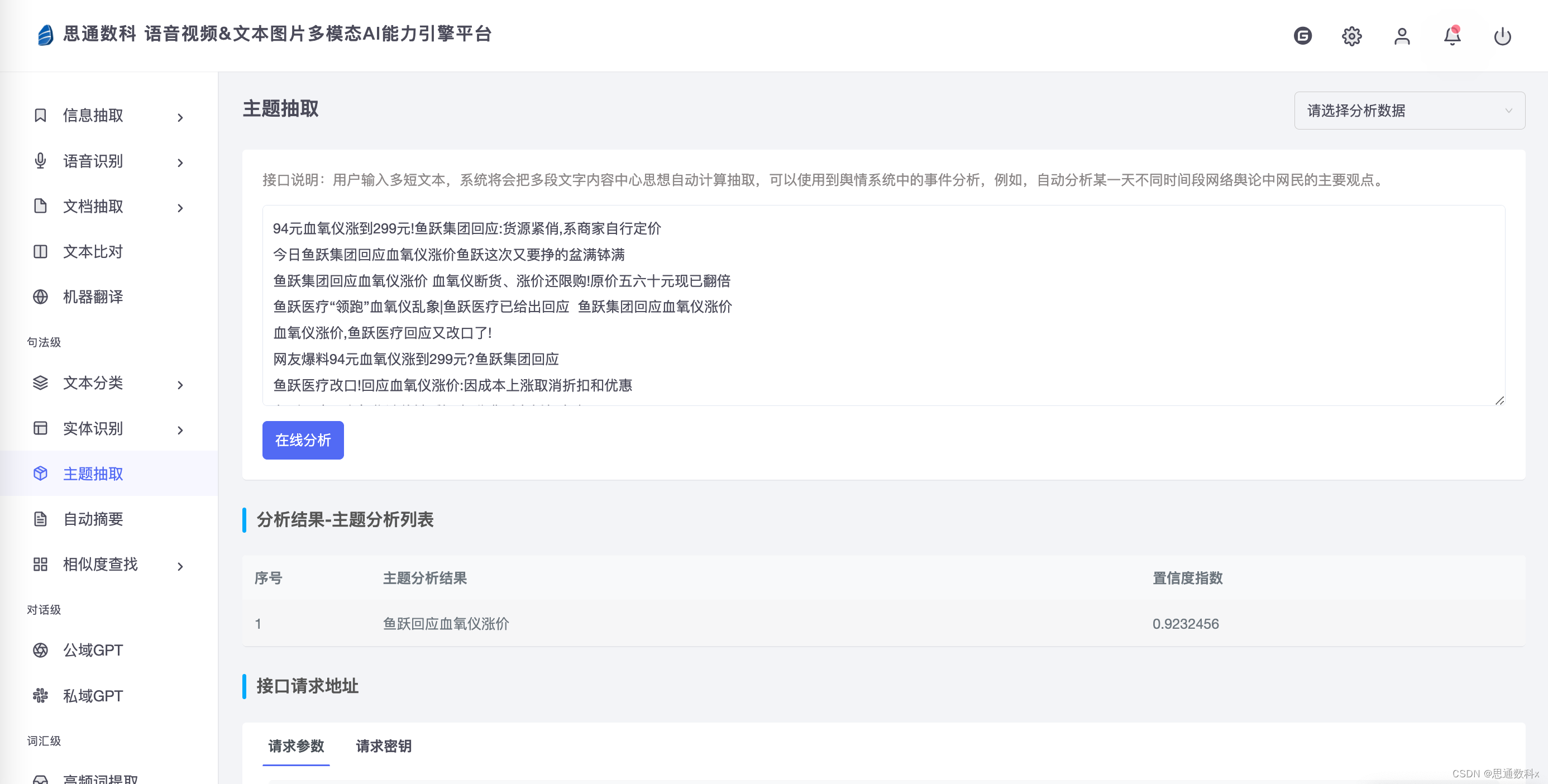
开源项目(可本地化部署,永久免费)
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。
思通数科多模态AI能力引擎平台![]() https://nlp.stonedt.com
https://nlp.stonedt.com