本期作者

前言
云原生时代下, Kubernetes已成为容器技术的事实标准, 使得基础设施领域应用下自动化运维管理与编排成为可能。对于无状态服务而言, 业界早已落地数套成熟且较完美的解决方案。可对于有状态的服务, 方案的复杂度就以几何倍数增长, 例如分布式应用多个实例间的依赖关系(主从/主备),数据库应用的实例依赖本地盘中存储的数据(实例被干掉, 丢失实例与本地盘中数据的关联关系也会导致实例重建失败)。
多种原因导致有状态的应用一度成为了容器技术圈子的禁忌话题, 直到目前, 有状态的服务是否适合放置在容器中并交由K8s编排托管(例如生产环境的数据库)的话题依然争论不止。本文基于Elasticsearch/Clickhouse在B站生产环境的容器化/K8s编排能力落地, 将阐述为何我们需要进行容器化/on k8s, 容器化中遭遇的挑战以及解决方案, 落地的技术细节以及收益。
一、现状
企业级、生产环境下项目的推进, 核心需要围绕成本、质量、效率,我们首先对B站目前使用es/ck的现状进行分析。
以elasticsearch为例(简称'es'), es在B站拥有广泛的应用场景, 包括各类2b/2c的在线业务及站内搜索, 内部审核、企效、风控等平台。 我们为此搭建了数套公共ES集群, 并为每套集群划分职能, 例如2c公共集群、2b公共集群、内部系统集群等。
起初, 这套系统运行的较为稳定, 运维工作也相对简单, 我们只需关注公共集群资源利用率并对其进行相应的扩缩容即可。
但随着业务的不断接入, 缺陷也逐渐暴露, 不同的业务写入/查询qps具有波动性, 当集群在某一时刻资源水位线达到峰值时(如瞬时cpu), 整个集群所有业务的查询请求可能会出现耗时增加甚至超时。并且, 公共集群模式下所有业务共享集群中的查询缓存与操作系统page cache, 而缓存淘汰策略(通常为LRU)无法基于业务优先级进行设定, 导致集群中部分业务查询耗时不稳定, 降低了用户体验。
为此我们进一步的对集群进行拆分, 直接响应c端用户的集群, 我们使用裸金属服务器搭建独立集群, 与其它业务进行隔离, 解决查询超时的问题。
稳定性的问题看似解决了, 但成本也提高了, 由于ES属于分布式存储, 为了防止脑裂、维持高可用, 一个集群我们至少使用3台裸金属服务器进行搭建, 而大部分业务资源占用极少, 部分独立集群整体资源利用率甚至不到5%。这在以降本增效为主题的互联网时代下也是不可接受的。
同理, 对于clickhouse(简称'ck'), 目前在B站主要应用于交互式的查询分析、报表以及日志、调用链等可观测场景, 目前集群数量30+, 拥有500+个物理机器节点。以上es集群面临的多租户以及资源利用率低的问题同样适用于ck。
使用运维手段解决是否可行呢, 为每个集群中的节点设定相应的cgroup与namespace限制, 在有限的裸金属服务器上尽可能的承载更多的集群, 有效的提升资源利用率。这在理论上看似可行, 但随着集群数量的增多, 运维工作的复杂度呈几何倍数递增, 不同配置的集群的创建、销毁、扩缩容将成为日常运维工作的噩梦, 我们很快便否决了这一方案。 事实证明我们的决定也是正确的, 以es为例,测试环境与线上环境的集群数量有100+套, 如果采用这种模式, 我们无法接受臃肿庞大的运维成本。 对于ck来说, 组件的运维复杂度甚至高于es, 显然也不可取。
开源ES与CK并没有很好的考虑多租户的问题, 基于源码进行二次开发是否可行呢?经过评估, 我们也否决了这个路径, 在应用层支持多租户的隔离确实是一个方案, 如果要做到良好的隔离的效果, 技术复杂度与开发成本是相当高的, 同时资源隔离的特性, 也不适宜在应用层花费巨大精力进行改造, 好比大炮打蚊子, 收益与代价不成正比。
事情仿佛陷入了困局, 仔细思考一下我们究竟需要怎样的能力来改善现状
-
良好的资源隔离能力, 解决不同业务间相互影响的问题
-
集群资源的编排能力, 保证集群高可用的前提下尽可能提升资源利用率
-
良好的自动化运维能力, 低运维甚至免运维
-
开发成本低, 少重复造轮子
-
对标裸金属服务器集群, 性能不能有明显劣化
梳理完核心需求后, 经过调研, 剩下两条技术路径
-
自研运维平台, 集成对集群拓扑、资源自动化调度、编排能力
-
将ES/CK运行于容器中, 并交由k8s进行资源调度与编排
| 解决方案 | 运维成本 | 隔离性 | 开发成本 | 资源利用率 |
| 公共集群 | 中 | 弱 | 低 | 中 |
| 独立集群 | 中 | 强 | 低 | 低 |
| 运维平台 | 中 | 强 | 高 | 高 |
| 组件二开 | 中 | 中 | 高 | 中 |
| on k8s | 低 | 强 | 中 | 高 |
各类方案对比
两条路径本质相同, 都是利用Linux Namespace, Linux Cgroups和rootfs三种技术构建隔离环境并对隔离的资源进行编排调度。但对于自研运维平台来说, 如果平台设计的自动化能力较低, 日常隐形的运维成本将会大大增加, 如需求平台自动化能力较强, 包括智能的对集群编排, 资源分配, 随之对应的就是较大的开发成本, 这与自己实现了一套k8s的编排调度的能力无甚区别, 属于重复造轮子, 也不合理。
将有状态的服务容器化并托管k8s也并非易事, 简单的跑个demo和在生产环境稳定运行, 并能在发生相应故障下做到快速排障, 止损, 恢复, 是完全不同的两个概念。 在遇到故障时, 排障难度是叠加的, 但技术领域很难通过堆人来叠加排障效率, 同时存在一个k8s专家和一个ES专家, 可能都会对疑难杂症束手无策, 毕竟站在不同的视角只能了解到局部的故障细节, 但运行在容器与k8s中的有状态应用在排障时则需要全局视角的技术储备。
尽管这是一件较有挑战性的事, 但作为以终身学习标榜的技术人员不应安于现状, 偏安一隅, 如果你是一名数据库专家, 为何不能同时也成为一名k8s专家呢。
同时, B站在k8s引擎的技术储备丰富, 拥有专家团队提供技术支持, 我们更不应该面对新技术时故步自封。 最终, 我们选择了第二条路径, 开始着手调研es容器化与k8s编排。
二、 总体架构
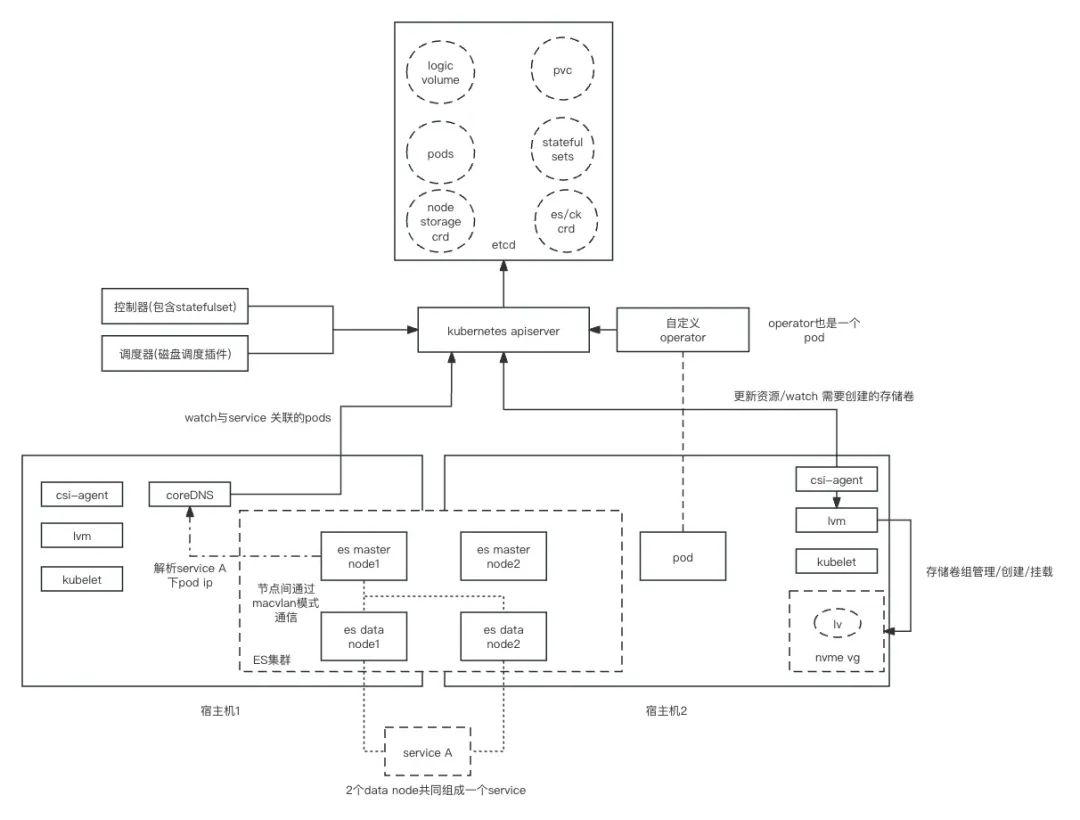
整体架构图
ps: 生产环境不会搭建只有2个master节点的es集群,以上仅做示例
Operator负责创建各种有状态的应用(StatefulSet),存储卷(PVC), 以及负责StatefulSet的调谐工作。 同时节点会将cpu、mem、磁盘等可用资源信息上报, 调度器将基于这些信息将 Pod调度到合适的节点,并在该节点上创建存储卷并挂载至容器。
k8s集群内容器间的服务发现通过CoreDNS来实现。同时,pod之间的通信都是通过 Macvlan来完成。
三、 技术细节
将有状态的服务容器化并交由k8s编排并不简单, 我们需要关注许多技术难点, 此章节对k8s中的控制器、持久化存储、磁盘调度、调度器、容器网络、服务发现、集群高可用等细节进阐述, 在解决了这些技术难点后, es/ck on k8s就是一件水到渠成的事了。
3.1 控制器
在k8s中, 编排策略与资源调度的最小单位一般基于pod来完成, pod是一个逻辑概念,可以包含一个或者多个容器,pod内容器共享网络和存储,通过Cgroups与Namespace对资源隔离和限制。我们可以简单的理解每一个pod都是一个虚拟机(但并不是虚拟机), 容器则是运行在这个虚拟机中的用户程序。控制器是一个重要的组件,它可以根据我们的期望状态和实际状态来进行调谐,以确保我们的应用程序始终处于所需的状态。在 K8s 中,用户通过声明式 API 定义资源的“预期状态”,Controller则负责监视资源的实际状态,当资源的实际状态和“预期状态”不一致时,Controller则对系统进行必要的更改,以确保两者一致, 这个过程称为调谐(reconcile)。而这些控制器的主要管理职责为保证 Pod 资源健康运行,如副本个数、发布策略等。
k8s具有以下默认的控制器, 这些控制器决定了pod编排以及调度的行为
-
Deployment: 无状态控制器, 主要用于创建无状态的服务
-
Replicaset: 无状态控制器, 并提供副本参数配置, 控制器会维持pod的数量在期望值
-
Statefulset: 有状态控制器, 管理有状态应用的工作负载。
-
Job与CronJob: 任务控制器, 支持定时, 一次或多次执行某类任务
我们发现k8s中默认的控制器都不能很好的满足我们的需求, 以es为例, es中节点分为master/data/coordinating/ingest等, 每个实例都可能具备一种或多种角色, 而Statefulset仅仅依赖init container行为以及pod的序号来维护这些实例间的关系, 较为死板, 并且pod名一旦被确定, 那么集群拓扑关系也随之确定, 如果我们要往集群中加入一个master节点, 流程将会较为繁琐。
k8s中还支持自定义资源(CRD)与自定义的控制器, 在自定义控制器内, 我们可以根据自定义API变化来完成具体的部署和运维工作。
以下是对CRD及自定义operator工作流程的说明。如对此概念熟悉的读者可酌情跳过阅读。
CRD(custom resource definition)
用来定义和管理标准k8s对象之外的资源,是k8s api的扩展,允许用户使用自己的模式和行为定义资源。
operator
用来自动化管理在k8s上特定的应用和服务资源(如有状态应用数据库、缓存、监控等)的工具,本质上就是k8s中的控制器。它们监视着自定义资源的更改变化事件,根据资源指定的状态进行处理。
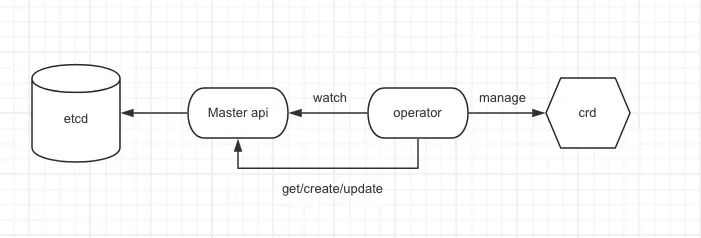
当有被监视资源的相关事件触发时,会进入到reconcile cycle(调谐循环)。简单来说,就是根据资源期望状态和实际状态的差异来采取适当的操作,比如资源的创建更新和删除就是在这个循环机制中进行。
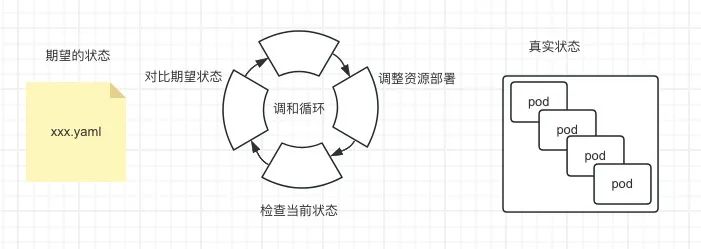
k8s operator的实现有多种方式,使用operator sdk或者其他脚手架工具/框架(如kubebuilder)去构建。因此有了这个crd + operator,可以开发出满足自己业务需求的控制器。我们可以基于crd与operator完成pod的数据存储,pod重启后数据是否丢弃数据等行为进行定制化的控制。
3.2 持久化存储
基于较高的 IOPS和低延迟等性能考虑, 我们选择使用本地盘(local pv)。
使用本地盘代表着如果宿主机宕机, 势必会导致数据丢失, 所以Elasticsearch中的索引需要配置副本, 在Clickhouse中可以选择ReplicatedMergeTree表引擎来使用副本,这是数据高可用的前提。
如果一台机器存在多块的磁盘,且为不同介质(ssd/hdd), 假如每一个分区被独立的使用,容易产生碎片, 资源利用率低。此外, pod挂载的存储也有动态扩容的需求(不停服务进行磁盘扩容)。基于以上考虑我们选择使用了LVM(Logical Volume Manager)技术。
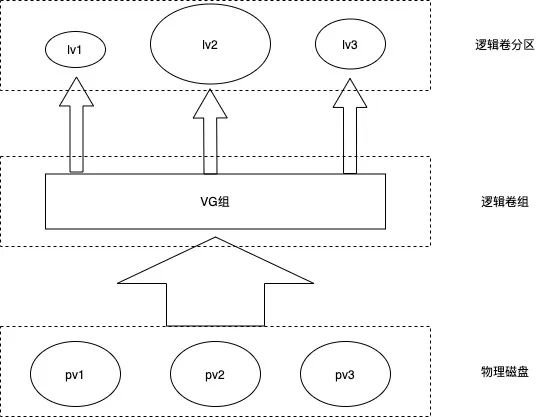
LVM(Logical Volume Manager)
LVM技术将物理卷(physical volume)组成卷组(volume group), 基于逻辑卷(logical volume)进行磁盘管理, 提供了动态扩缩容的能力。以下是一些概念简介。
PV:物理卷(physical volume)就是指硬盘分区或从逻辑上与磁盘分区具有同样功能的设备(如raid),是LVM的基本储存逻辑块,但和基本的物理存储介质(如分区,磁盘等)比较,却包含有与LVM相关的管理参数。
VG:卷组(volume group)LVM卷组类似于非LVM系统中的物理硬盘,尤其物理卷组成,可以在卷组上创建一个或多个LVM分区(逻辑卷),LVM卷组由一个或多个物理卷组成
LV:逻辑卷(logical volume)LVM的逻辑卷类似非LVM系统中的硬盘分区,在逻辑卷之上可以创建文件系统。
有了LVM这个利器, kubernetes就可以利用这个工具给 pod 创建数据卷,我们使用LVM 把同介质的多块磁盘统一为一个卷组。如果pod需要一块Nvme介质的数据卷,那么就在这个卷组上创建一个逻辑卷,并在这个逻辑卷上创建需要的文件系统,这样pod的数据卷(pv)对应的数据盘就完成了初始化,pod创建时可直接挂载并使用。
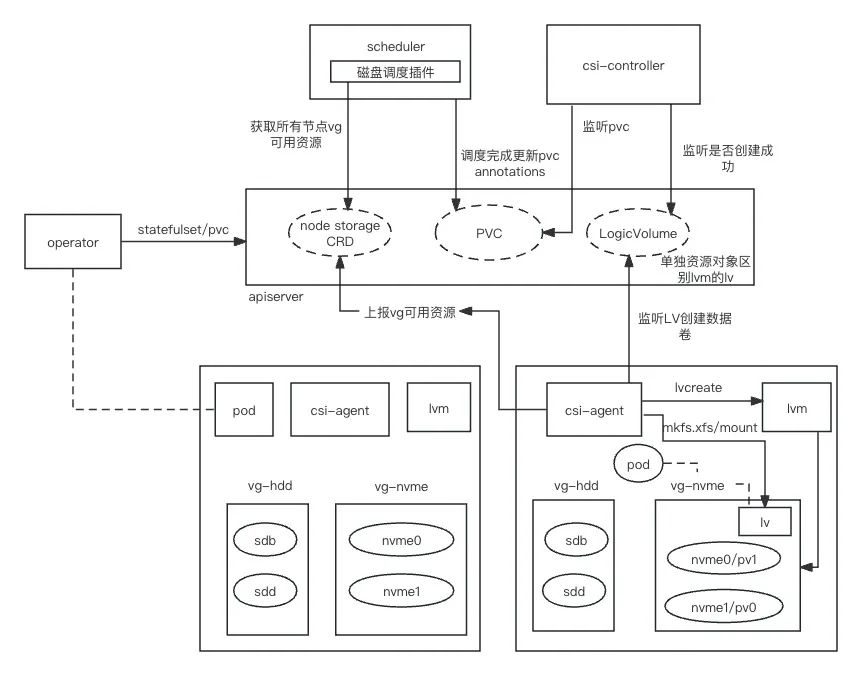
首先, agent将上报每一个机器的逻辑卷组可用大小, 上报完成后, 调度器就可基于每个机器卷组类别以及可用大小选择合适的机器来创建逻辑卷,最后机器上的agent会按照pvc申明的逻辑卷的大小和磁盘类别等信息通过Lvm在逻辑卷组上创建逻辑卷, 最后, 在pod创建时, agent会将数据卷挂载并提供pod使用。具体过程如下。

3.3 磁盘上报
csi-agent通过lvm来管理磁盘分区,首先agent会识别机器上的裸盘(未经格式化或分区的磁盘,即磁盘上没有任何文件系统或分区表的数据),通过lvm创建物理卷,然后把该同类型的物理卷组成一个lvm的卷组,最后在卷组上创建逻辑卷。lvm提供了现成的工具来获取机器的卷组类型和大小, csi agent只需进行上报即可。
status:allocatable:csi.storage.io/csi-vg-hdd: "178789"csi.storage.io/csi-vg-ssd: "3102"capacity:csi.storage.io/csi-vg-hdd: "178824"csi.storage.io/csi-vg-ssd: "3112"
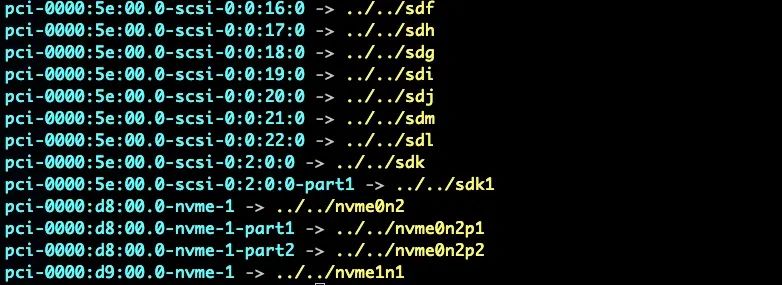
如上展示了一台机器上的两个卷组,一个介质为hdd, 另一个介质为ssd, 并且提供了容量大小信息。 创建卷组时, 卷组下所有磁盘分区需要为裸盘,同时, 我们也需要将磁盘介质区分清楚, 防止将不同介质的磁盘划分为一个卷组, 尤其节点磁盘在拥有磁盘raid时需要特别注意。另外, 在实践中我们发现机器重启时, nvme盘的盘符会发生变化, 基于盘符去创建物理卷会产生问题, 而nvme的插槽口一般是不会改变的, 我们后续基于了nvme的槽口信息来创建物理卷。
3.4 磁盘调度
完成了磁盘上报, 接下来就可以根据磁盘信息进行调度了。
调度器会对当前集群下所有机器的各类磁盘的水位线进行计算, 结合策略(集中式或分散式)进行pod调度,pod所调度的目标节点一定具备满足pod所需要的所有类型的数据盘。用户只需通过申请pvc, 申明所需要的资源类型,大小和读写属性。调度器会自动进行数据盘挂载, pvc与pv的绑定。下文详细阐述了这些自动化的步骤是如何实现的。
k8s的api都是申明式的,磁盘同理,用户只需申明磁盘的大小,类型,磁盘创建的时机和属性等等,控制器会自动实现你期望的结果。
先介绍几个关键的申明对象的概念。
Persistent Volume(PV)
对底层存储的一种抽象,例如一个持久化存储在宿主机上的目录,独立于pod的生命周期,lvm基于某一个卷组创建逻辑卷。csi-agent监听到事件后在节点上创建localvolume。如果已经存在,pod重启后不会再创建。
PersistentVolumeClaim(PVC)
描述Pod期望使用的的持久化存储的属性(如大小、读写权限), 通常由开发人员创建。无需关注具体PV实现的底层细节, PVC与PV绑定后Pod即可正常使用。es和clickhouse的pvc都是对应operator自动创建。
StorageClass
定义创建PV的模板(PV的属性, 例如大小、类型), 并使用存储插件动态的创建PV,这是低运维甚至免运维的前置条件之一。在pvc申明对应的StorageClass,比如StorageClass定义了lvm的vg组,那么创建pv时就会在vg组上创建逻辑卷,还比如只有pod创建的时候在创建pv,可以指定StorageClass的volumeBindingMode为WaitForFirstConsumer来实现。因此StorageClass就是申明创建pv的属性和类型等。
利用k8s中Dynamic Provisioning的能力, 可以动态的创建PV, 无需运维人员手动维护。但在k8s中没有内置本地盘的Provisioner, 我们需要自定义存储插件。为此我们基于了开源的存储插件进行了适配性改造。
每一个节点的csi agent插件将上报机器磁盘空闲资源,并通过crd来描述这些资源,而调度器会监听这些crd对象,在调度pod的时候,根据crd描述的每一个机器的资源情况,选择合适的节点进行调度。
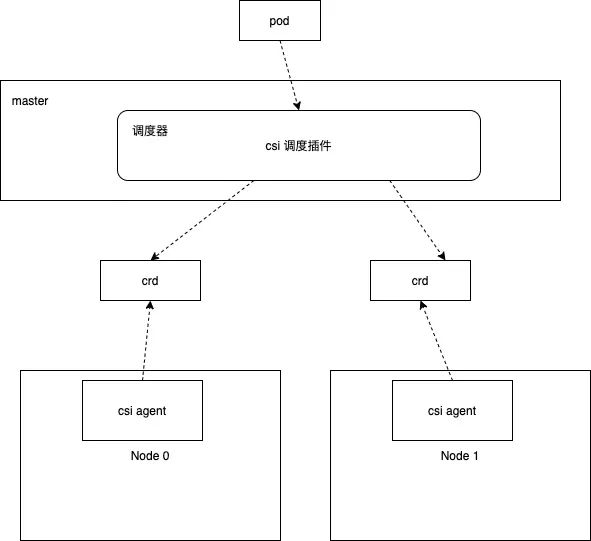
存储插件的架构图
status:allocatable:csi.storage.io/csi-vg-hdd: "178789"csi.storage.io/csi-vg-ssd: "3102"capacity:csi.storage.io/csi-vg-hdd: "178824"csi.storage.io/csi-vg-ssd: "3112"
磁盘CRD信息
通过计算每一类磁盘卷组大小, 以及节点已占用大小, 可以计算出每个节点中每一类介质磁盘的空闲大小, 并且根据集中式或均匀式的策略来进行资源对象的创建。调度过程主要涉及csi-scheduler、csi-agent、csi-controller, 三个组件相互配置并完成资源上报,调度,数据卷的创建和挂载。
下文是三个组件的详细介绍。
调度器(csi-scheduler)
1.csi-scheduler 是 Kubernetes 的调度插件,负责基于申请的 PV 大小、节点剩余磁盘空间大小,磁盘类型,节点负载使用情况进行合理的调度。如果节点后期上报了更多的资源信息,可以实现更加丰富的调度来满足业务的各种需求。基于原生的k8s的调度框架做一个单独的调度插件比较简单,同时调度策略更加灵活,可以实现集中式和分散式调度满足各种业务需求。
2.调度插件主要实现Filter和Score两个阶段,在预选阶段(Filter)过滤掉不满足的资源的节点,在优选阶段(Score)对满足条件的节点根据调度策略是集中式还是分散式打不同的分数,比如集中式策略的目的是减少资源碎片,在满足资源下剩余可用资源越少分数越高。对于分散式资源剩余越多分数越高,最终得分越高的节点越容易被选中。
3.一旦调度完成,那么对应的pvc上会打上annotation,csi-controller监听PVC维护PVC、LV之间的关系, csi-agent监听LV来创建相应的数据卷并且在pod创建的时候负责挂载数据卷。
csi-agent
运行在每个节点上的服务,利用lvm技术管理本地磁盘,自动识别机器的SSD/HDD/NVME 裸盘,并根据这些磁盘类型划分为对应磁盘卷组,用户无需介入。对运维来说只需要按照规范交付裸盘机器。同时csi-agent监听LV创建本地数据卷,在pod创建的时候负责数据卷的挂载等操作。
csi-controller
控制平面, 监听PVC维护PVC、LV之间的关系。节点侧csi-agent监听LV来创建相应的数据卷。
3.5 数据卷创建
Name: csi-sc
IsDefaultClass: No
Annotations: kubectl.kubernetes.io/last-applied-configuration={"allowVolumeExpansion":true,"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{},"name":"csi-sc"},"mountOptions":["rw"],"parameters":{"csi.storage.io/disk-type":"nvme","csi.storage.k8s.io/fstype":"xfs"},"provisioner":"csi.storage.io","reclaimPolicy":"Delete","volumeBindingMode":"WaitForFirstConsumer"}Provisioner: csi.storage.io
Parameters: csi.storage.io/disk-type=nvme,csi.storage.k8s.io/fstype=xfs
AllowVolumeExpansion: True
MountOptions: rw
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>我们基于此存储插件定义的一个StorageClass, 名称为csi-sc, 由存储插件csi.storage.io进行动态pv创建, 磁盘介质为nvme ssd, 文件系统为xfs。
VolumeBindingMode: WaitForFirstConsumer, 将PVC与PV的绑定延迟到Pod调度之后, 防止提前绑定导致Pod调度失败的问题(使用local pv时非常重要的配置)。ReclaimPolicy: Delete, 意味着当用户手动删除pvc时pv也会被自动删除,这在pv所对应的本地盘损坏的情况下是必要的, 可以防止在删除pvc之后pod仍被调度到该宿主机上(pvc和pv的绑定一对一的,pv不被删除,pod就不会漂移)。
最终, 用户只需通过pvc申明期望使用的数据盘,并在pvc里申明了StorageClass, 剩余的工作都是由存储插件完成了。
3.6 容器网络
容器默认配置下, 不同宿主机上的容器无法通过ip地址进行互相访问。无论是Elasticsearch或是Clickhouse, 都是分布式应用,例如es中选举主节点, 分片rebalance, 或仅仅只是一次简单的查询请求都需要同一集群内的不同实例进行内部通信, 而这些实例又分布在不同宿主机上, 我们需要让这些容器完成可靠、高性能的跨主机通信。
社区拥有众多的容器网络解决方案。macvlan是linux内核支持的一种网络功能,可以支持在不同的网络命名空间上配置二层网络,具有性能损耗小、管理成本低等优点。B站macvlan容器网络方案已在生产环境运行数年, 稳定性有保障, 我们决定复用公司Paas团队的技术沉淀。具体做法是通过每个节点的CNI插件进行pod ip的分配, 以及其它初始化工作。
| 网络模式 | 优势 | 劣势 |
| macvlan | 1. pod拥有独立ip, k8s集群内外皆可访问 2. 请求不经过kube-proxy, 性能理论最优 | 1. ip余量取决于宿主机网段所在的机房、机柜等信息, 可能存在ip不足的情况 2. pod ip变更时客户端需感知 |
| overlay | 1. 无需考虑ip不足的问题 | 1. k8s集群外访问需实现ingress网络方案、nginx反向代理 2. 一次外部请求可能数次转发(kube-proxy、nginx反向代理), 性能理论较差 3. 目前只支持七层代理, 不支持四层代理 4. 过多的service导致iptables规则膨胀, 性能有损 |
| host | 1. 无需考虑ip不足的问题 | 1. 需要对宿主机端口进行规划, 创建集群时的逻辑需要改造 2. 额外维护集群 - 端口号这一映射关系以供客户端访问, 存在隐形维护成本 |
3.7 服务发现
es中存在许多集群间内部通信, 例如节点间的分片rebalance。 为此我们使用了headless service+core dns组件来解决此类问题。当内部请求需要获取pod地址时, core dns组件会返回pod的dns记录, 并解析成对应的pod ip。
macvlan的网络模式虽然解决了从k8s集群外访问到ES集群的问题, 但我们发现Pod的IP是不固定的, 集群的发版, 滚动重启, 扩缩容都可能导致pod ip地址发生变化, 对于下游业务来说, 需要感知集群地址变化是较为麻烦的, 如何通过固定的方式来访问到我们的ES集群是我们下一步需要解决的问题。
为此我们封装了统一的查询网关, 所有客户端查询es的请求都由查询网关代理, 而查询网关则会不断询问并更新k8s集群中具体es集群的地址信息,并将其保存在内存中。考虑到写入流量较大, 可能对查询产生影响。我们也将读写分离, 写入侧会询问查询网关具体某一集群与节点实例的ip列表, 当获取到每个实例(pod)的ip时,将会直连这些节点ip进行数据写入。
同理, 对于ck, 我们也封装了统一的查询网关提供业务外部访问, 对于ck集群内部副本间的通信, 例如ck间的副本通信, 我们为每一个副本都设置了一个headless service。
除此之外,ck还依赖zookeeper组件来完成副本间的同步,我们使用的是ck内部开发的clickhouse keeper(以下简称为'keeper')来替代zookeeper。我们对keeper也进行了容器化,通过不同的namespace来区分不同业务使用的keeper。 其中, keeper集群实例之间也通过headless service来进行通信。
3.8 高可用
高可用分为集群高可用与数据高可用。
以ES为例, 集群高可用需要考虑防止脑裂, 部分节点脱离集群时服务依然可用。数据高可用同理, 分布在某实例上的数据丢失时(如磁盘损坏), 需要通过副本机制来进行恢复与补偿。
举个简单的例子, 一个ES集群由5个ES实例组成(假设同时为master&data节点), 而这5个实例分布在宿主机A, 宿主机B上。
如果宿主机A发生宕机, 会发生什么样的情况?
显而易见, 这个ES集群将会失去3个实例, 集群无法达到最小节点数而无法触发选主, 导致集群不可用。
假如是宿主机B宕机呢? 由于宿主机宕机, 此ES集群只会失去2个实例, 该集群仍然存在3个实例, 集群仍然可用。假设此集群存在一个Index A, Index A有一个分片0与一个副本分片0, 它们分布在ES实例3与ES实例4上。则宿主机的宕机会同时导致该Index主分片与副本同时丢失(因为使用的是本地盘), 造成数据不可用。
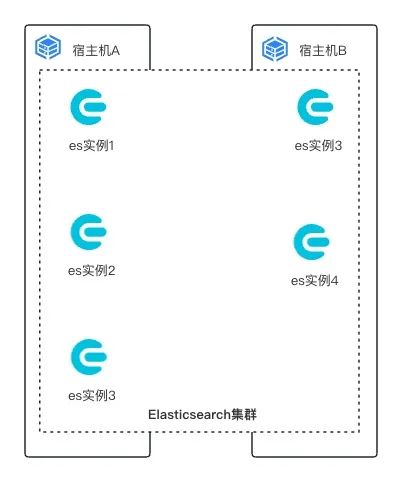
如要同时实现集群高可用与数据高可用, 需要同一集群下的相同角色实例不可分布在同一宿主机上。我们使用k8s中的亲和/反亲和机制来实现, 此处的topologyKey为宿主机hostname。
affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchLabels:elasticsearch.k8s.elastic.co/cluster-name: es-testelasticsearch.k8s.elastic.co/node-data: 'true'topologyKey: kubernetes.io/hostname
对于ck来说,要实现高可用也需依赖副本, 通过副本间的同步,可以让每个副本都能对外提供服务,即使其中某个副本挂掉, 也能保证集群的可用以及数据的完整性。 同时, 我们不允许ck集群下的同一shard的不同replica分布在同一宿主机上。同样使用反亲和机制可以达成此效果。除shard级别不同replica的反亲和,ck operator还支持不同程度的反亲和/亲和,比如chi实例级别反亲和,replica级别反亲和,namespace级别反亲和等。
podDistribution:- type: ShardAntiAffinitytopologyKey: "kubernetes.io/hostname"
以上配置是为了保证keeper集群下不会同时挂掉多个实例而导致整个keeper集群不可用,也是对keeper的实例进行了宿主机级别的反亲和。
3.9 内存隔离
cgroups保证了容器中内存的隔离性, Lucene的一次写入, 文件无变更的特性导致操作系统的page cache也将极大的影响ES的查询性能。
我们深入探究了cgroups对于page cache的作用机制
根据linux内核代码看, cgroup的确只统计了RSS内存(cgroup控制组里所有进程实际使用的物理内存总和) + page cache, 当memory.usage_in_bytes要超过memory.limit_in_bytes时, 内核会自动开始回收这个cgroup控制组里的page cache缓存。
static void mem_cgroup_charge_statistics(struct mem_cgroup *memcg, int nr_pages)
{/* pagein of a big page is an event。So, ignore page size */if (nr_pages > 0)__count_memcg_events(memcg, PGPGIN, 1);else {__count_memcg_events(memcg, PGPGOUT, 1);nr_pages = -nr_pages; /* for event */}__this_cpu_add(memcg->vmstats_percpu->nr_page_events, nr_pages);
}得出结论, 在初始化一个运行ES进程的容器时, 需要同时考虑jvm heap与page cache大小, 其中page cache也受cgroups限制, 回收行为由内核执行。
同理, ck在访问文件时也会使用os的pagecache,当查询访问的数据被pagecache缓存时,也会加速ck的查询, 可以与ck里min_bytes_to_use_direct_io个参数与pod内存结合调整, 提升查询性能。
3.10 IO隔离
考虑到目前B站承载ES与CK的机型, 对于热数据存储都使用了Nvme SSD, IO瓶颈在大部分情况下不会先于CPU与MEM触发。IO隔离的意义不大。
对于hdd上的冷数据, 默认查询都会使用buffer io, cgroup v1版本对buffer io隔离不彻底, 这个特性虽在新版本的内核上已经支持, 但Paas团队评估整体升级内核和适配的成本较高, 经过评估我们将在第二期再进行IO隔离的能力的支持。
3.11 具体实践
以es为例, 秉着避免重复造轮子的理念, 我们基于开源社区cloud-on-k8s项目进行了改造, 使其兼容公司容器平台, 优化了指标、日志采集方式, 具体实践如下。
1. 由paas团队初始化k8s集群, 标准化容器装机
2.登录k8s集群master节点, 安装CRD到集群
kubectl create -f crds.yaml3.将operator部署到k8s集群中
kubectl apply -f operator-bili.yaml其中, 在yaml文件中需要指定提前构建好的operator镜像地址
containers:- image: "{{镜像仓库地址}}/cloud-on-k8s-bili:2.3.2"
4.验证operator是否运行正常
kubectl get pod -n elastic-system这里我们看到operator已经处于READY状态了
NAME READY STATUS RESTARTS AGEelastic-operator-0 1/1 Running 27 260d
通过日志确认operator是否运行正常
kubectl logs -f -n elastic-system elastic-operator-05.CRD已注册成功, operator就位, 可以开始创建es集群
一行命令完成es集群创建
kubectl apply -f elasticsearch.yaml检查es集群状态
kubectl get elasticsearch -n elastic这里可以看到集群已经ready, 集群状态为green
NAME HEALTH NODES VERSION PHASE AGEtest green 3 7.17.9 Ready 1min
进一步检查集群节点日志, 确认集群运行正常
kubectl logs -f -n elastic test-es-datanode-06.集群已初始化完毕, 接下来我们需要获取到外部访问的地址
查看es集群节点信息
kubectl get pod -n elastic -owide我们使用了macvlan, pod ip可从集群外访问, 直接获取IP字段的值即为节点地址
NAME READY STATUS RESTARTS AGE IP NODE
test-es-datanode-0 1/1 Running 1 1min xx.xxx.xx.xxx xx.xxx.xx.xx
test-es-datanode-1 1/1 Running 1 1min xx.xxx.xx.xxx xx.xxx.xx.xx
test-es-datanode-2 1/1 Running 1 1min xx.xxx.xx.xxx xx.xxx.xx.xx7.operator为集群设置了账号密码, 并保存在secret中, 同样通过命令获取
kubectl get secret test-es-elastic-user -o go-template='{{.data.elastic | base64decode}}' -n elastic8.至此,我们拿到了集群的地址与账号密码,下一步就是从外部(k8s集群外)访问这个es集群了
ck步骤与es几乎一致, 基于社区Altinity开源clickhouse operator进行改造, 唯一区别为搭建集群时不仅要创建ck的集群, 也同样需要在k8s中部署keeper集群。
四、可观测
4.1 指标采集
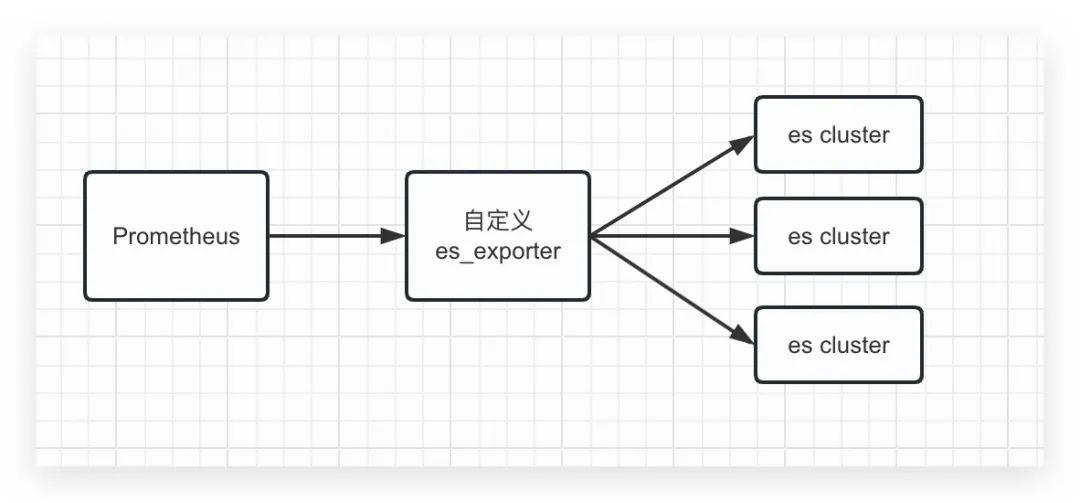
目前ES集群指标是通过es exporter暴露, 统一上报至Prometheus,并由grafana面板可视化展示。
对于裸金属物理机的ES集群, 每搭建一个集群, 就需要去部署一个es exporter, 如下图所示

es on k8s后, es集群创建/销毁/扩缩容频繁, 在面对繁多的集群下, 用原始的一个集群绑定一套exporter显然不是可持续的维护方式。所以我们对es exporter进行了改造,支持es exporter自动感知所有集群, 并支持采集多个集群的指标, 同时exporter也部署在k8s中, expoter本身是无状态的, 支持弹性扩缩容:
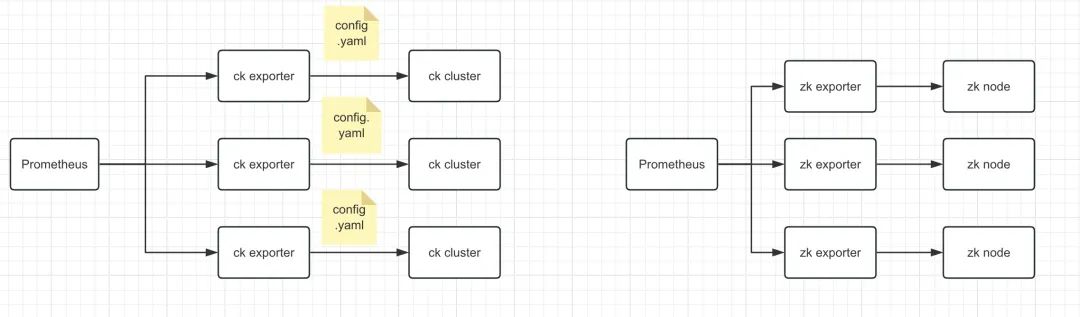
目前ck集群的指标采集使用的是ck exporter,对应的zookeeper的指标采集使用的是zookeeper exporter。其中ck物理集群的指标采集与es物理集群类似,每个物理集群都会有一个对应的ck exporter,只是exporter会从它的配置文件中去获取该集群节点的信息,从而获取到每个节点的指标。但是zookeeper物理集群的采集是单独每个zk instance配置一个zk exporter。
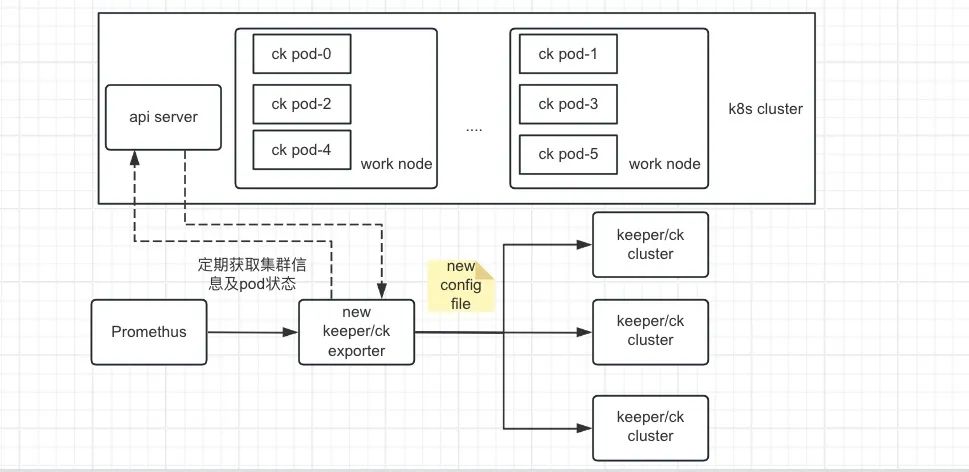
同理于es, 开源方案并不适用于ck容器化集群的采集, 我们改造了现有exporter,也实现了exporter自动感知所有ck集群并进行相应的集群指标自动采集, 容器集群的信息是通过http接口的方式从api server上动态获取的。具体架构图如下。
4.2 关键指标
我们为ES集群的关键指标创建了相应的Grafana视图面板, 主要包含以下部分
-
集群状态、节点数量、shard状态(unassigned/active/relocating)
-
内存监控, 包括jvm堆内存、gc信息、查询缓存、segment占用内存等
-
CPU使用率、load负载等
-
线程池状态(search/write/refresh)、thread rejected数量,search、write的线程池队列任务数等
-
集群查询qps、查询耗时
-
集群写入流量
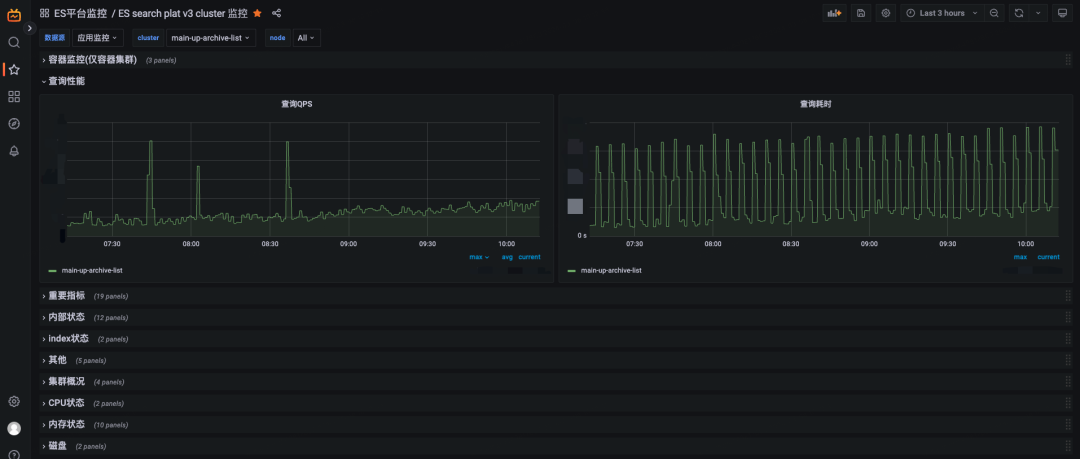
ES集群监控面板
ck集群的指标除了自带的metrics, events等系统表里的数据外还添加了自定义的指标,包括与select/insert/alter相关的各类指标,其中一些用于监控,同时会把指标分为各项大类。
除应用监控外, 我们使用Cadivisor(Container Advisor)对容器指标进行了相应的采集, 例如pagecache也是重要指标之一, 它将显著影响es(lucene)查询性能。如果在你的实践中, 需要关注其它容器指标, 可以自行配置面板。
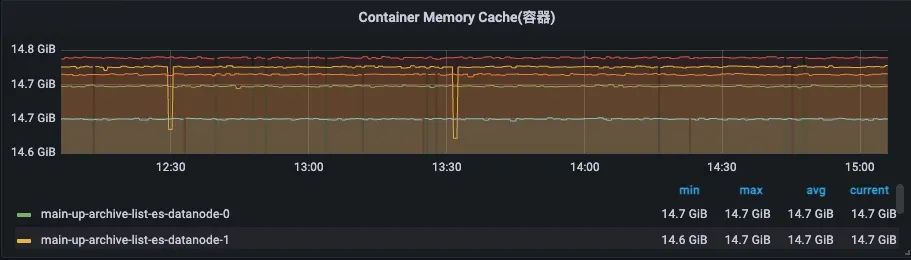
容器page cache监控
4.3 日志采集
暂时用K8S提供的API暴露日志,方便日常排障。后续我们将会集成公司统一日志系统, 对集群日志与慢查询日志采集并持久化、同时提供日志告警、慢查询定位分析等能力。
五、 产品化
与传统的集群搭建方式相比较, 通过简单的几条命令行与yaml配置文件的形式实现集群的创建、扩缩容、滚动重启、发布, 极大的降低了日常工作中的运维成本,但此种方式对人的依赖性依然较大,自动化程度低,操作者也需要对k8s具备相应的技术领域知识,在执行变更时,人工的操作也增加了出错的概率。为了进一步的自动化, 实现低运维甚至免运维, 我们与基础架构 - 平台产品团队进行了深度协作,将组件以私有云服务的形式进行产品化,旨在提升业务研发业务迭代效率与组件平台运营/运维效率。
最终实现的产品化能力如下:
-
集群一键创建/扩缩容/销毁, 在配置平台填写相应工单, 经对应负责人审批, 自动完成集群创建/扩缩容/销毁(通常1min内即可完成自动变更)。
-
自动绑定cmdb、可观测平台、变更管控平台等, 资源信息透明, 监控告警自动接入、日常变更有迹可循, 提升了整体的稳定性与故障时排障效率。
-
业务一键式接入, 通过对数据集成、集群创建、查询接入等场景进行适度封装, 在自由使用组件的同时, 屏蔽底层细节与复杂概念, 加速业务迭代与上线。
-
在运维平台上, 实现了一键发布、迭代更新、扩容缩容、镜像管理、配置管理、坏盘自动修复/Pod自动漂移等能力,降低日常运维、运营的压力。
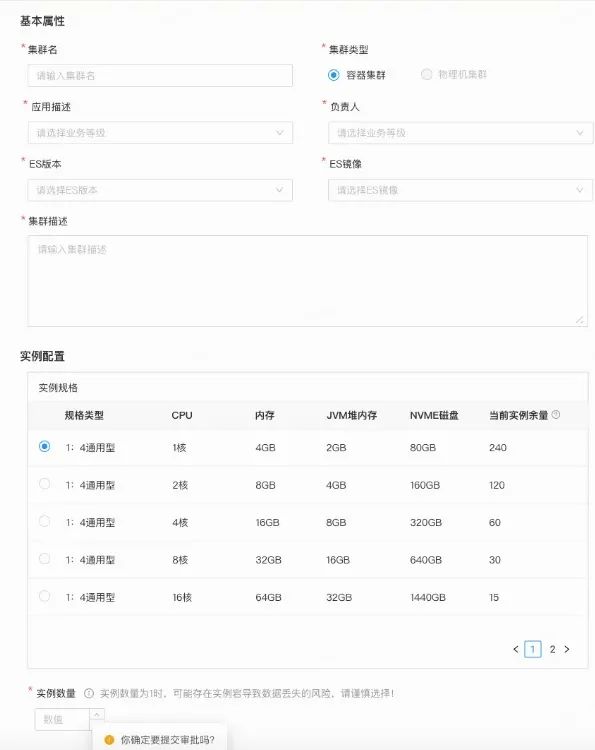
填写简单的表单, 集群自动初始化
六、 收益
完成技术落地与产品化后, 我们来关注一下产生的收益, 主要基于成本、质量、效率来进行考量。
6.1 成本
ES与CK都是分布式存储, 搭建集群存在最少节点数, 在容器化进程之前,业务需要使用独立的ES/CK集群时, 则最少需要申请3-4台裸金属服务器进行集群搭建, 目前B站托管至k8s的容器es/ck集群已有30+套, 扣除实际使用的资源, 已为公司节省100+台裸金属服务器, 迁移进程持续推进中,集群的CPU平均利用率也从原本的5%提升至15%。
6.2 质量
传统的公共集群模式下隔离性差, 造成了同一集群中的不同业务互相影响。在es/ck on k8s的能力具备后, 让我们对资源的隔离性有了进一步的可能。多个业务的稳定性也有了相当大的提升。以B站的关系链搜索场景为例, 原本的99分位查询耗时必定超时, 经过es on k8s独立集群的迁移后, 查询超时的问题已解决, 显著提升了用户对B站的使用体验。
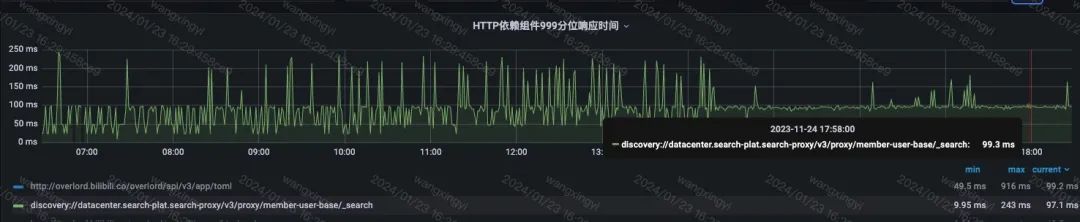
在迁移集群后, 查询毛刺的问题解决
6.3 效率
此前, 我们搭建一套裸金属集群, 步骤如下:
1 协调资源并由系统组交付裸金属服务器
2 创建集群配置, 指定集群名, 日志路径, 数据盘路径, jvm参数等
3 编写部署集群的ansible脚本
4 登录堡垒机, 批量执行ansible脚本进行部署
5 批量执行systemd命令启动集群
6 验证集群是否初始化成功, 节点数量是否符合预期
7 配置集群地址, 以供写入与查询侧使用
现在搭建容器集群步骤如下:
1 在配置页面填写集群名等信息, 指定集群规格
2 提交表单, 等待集群自动创建完成,通常会在1min内自动完成集群初始化工作
创建集群场景, 原先需要部署人员熟悉组件与相应部署脚本, 且需花费>=0.5天/人的工时, 变为从申请到集群交付可用只需1~2min(如集群节点数较少,几十秒内即可完成)。
故障场景, 传统的维护模式, SRE需订阅告警, 接收告警, 通过可观测系统进行定位, 并登录机器进行恢复, 人力消耗大, 效率低下。
而托管于k8s后, operator在调谐循环中会不断的将集群维护在期望状态。例如因oom产生了节点脱离, operator会不断尝试拉起pod, 将集群维持在健康状态。包括此类在内的部分故障不需人为介入,节省了相当大的运维成本。
在集群需要扩容时, 如果是裸金属物理机集群, 因为不同集群间的配置不同, 需要提前准备好脚本及配置文件, 不仅繁琐也容易出错。使用容器化集群, 我们只需在页面简单变更实例数量、实例规格即可由operator自动完成变更。
总结, operator会自动化进行资源编排、调度、滚动发布、集群状态调谐等行为,可以节省传统人肉运维下人力消耗,几乎做到免运维。
七、写在最后
选择容器技术时, 会直面许多操作系统、硬件等底层概念。如容器网络、磁盘调度、IO/CPU/MEM/NETWORK的隔离性等等。无论是项目推进过程中亦或日常排障, 单一的技术领域知识储备远远不足。
在一次容器网络故障案例中, 观察到集群中节点间歇性脱离, 通过日志以及监控只能得出节点间tcp网络通信失败。在排除掉集群本身问题后, 我们怀疑为容器网络问题, 使用工具可以稳定复现网络传输丢包的现象, 因为使用的是macvlan技术, 我们首先将出现问题的pod ip与存量的pod ip进行比对,发现存量pod被分配了重复的ip, 我们临时将pod进行删除重新调度, 并升级了CNI插件解决了这个问题。
如果仅具备数据库领域知识, 对整体容器网络, pod间如何通信缺乏整体的认知, 将很难快速定位到故障的根因, 会极大延长止损恢复的时间。
同样, 如果仅具备k8s/容器领域知识, 组件出现故障时也只能是两眼一抹黑, 因为组件的故障是多因一果, 节点脱离集群只是一个现象, 造成这个现象的原因众多, 你必须将其它原因一一定位并排除。
任何技术面临tradeoff, 我们在享受了容器与k8s资源调度、编排、隔离性便利下, 就不得不接受整体技术方案架构的复杂性。这就要求我们对于自身领域外的知识进行持续学习。如果你是一名数据库专家, 可能你也需要同时成为k8s专家。如果你是一名k8s专家, 在拥抱云原生的时代下, 你也需要去了解不同技术领域的知识。我们在执行技术落地的过程中遭遇的疑难杂症, 面临的挑战与解决的难点也只是冰山一角, 在不同组件, 不同架构下有状态服务落地托管至k8s中可能会有更多缺陷与难点暴露出来, 但伴随着云原生的共识以及开源社区良好的生态模式, 我们相信这些困难都可以迎刃而解。
我们选择拥抱新技术,持续学习, 你是如何选择的呢?