文章目录
- 复习
- 一、http和https协议
- 二、网络请求的过程
- 1.浏览器发送http请求的过程
- 2.DNS服务器
- 三、Headers参数介绍
- 总结
复习
在本节开始讲述的时候,我们先来复习一下爬虫的基本步骤:
一、http和https协议
HTTP协议(Hypertext Transfer Protocol)是一种用于传输超文本的应用层协议。
工作原理:客户端发送请求给服务器,服务器接收并处理请求,并返回相应的响应给客户端。请求和响应都包含一个首部和一个可选的消息体。首部包含了请求或响应的元数据,消息体包含了实际的数据。
HTTP协议使用TCP/IP作为传输协议,通常使用80端口。它支持多种请求方法,包括GET、POST、PUT、DELETE等,每个方法都有不同的语义和用途。
HTTP协议也支持状态码来表示请求的处理结果,常见的状态码包括200表示成功,404表示未找到资源,500表示服务器内部错误等。
除了传输超文本外,HTTP协议还可以传输其他类型的内容,如图片、音频、视频等。在传输时,可以使用压缩、缓存、加密等技术来提高传输效率和安全性。
备注:上面提到的一些基本概念会在后面陆续讲解到,不懂的话可以先放着,我们后面通过实例来进行了解。
http和https的区别:
HTTP
- 超文本传输协议
- 默认端口号:80
HTTPS
- HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协议
- 默认端口号:443
HTTPS比HTTP更安全,但是性能更低
二、网络请求的过程
1.浏览器发送http请求的过程
-
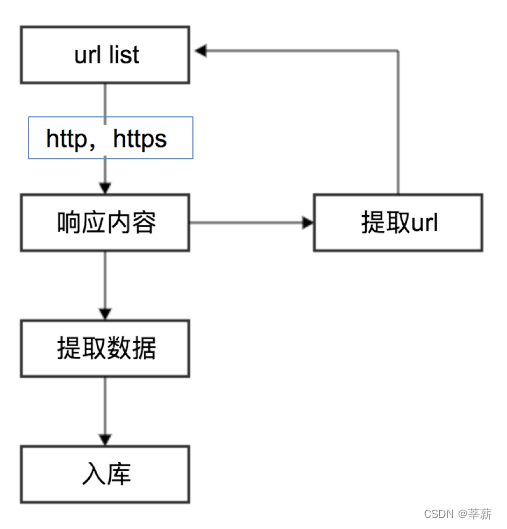
浏览器先向地址栏中的url发起请求,并获取相应
-
在返回的响应内容(html)中,会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应
-
浏览器每获取一个响应就对展示出的结果进行添加(加载),js,css等内容会修改页面的内容,js也可以重新发送请求,获取响应
-
从获取第一个响应并在浏览器中展示,直到最终获取全部响应,并在展示的结果中添加内容或修改————这个过程叫做浏览器的渲染
http请求的形式
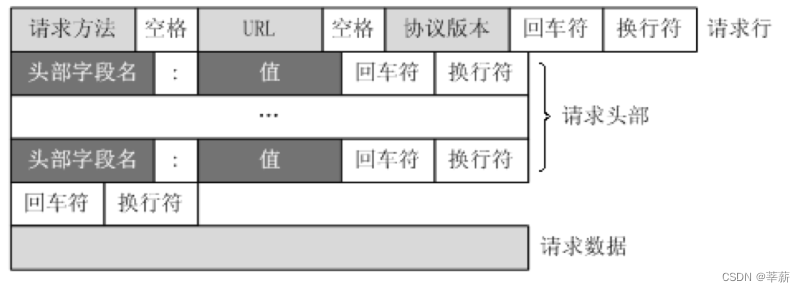
注意:在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等),浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样,所以在爬虫中,需要以url地址对应的响应为准来进行数据的提取
2.DNS服务器
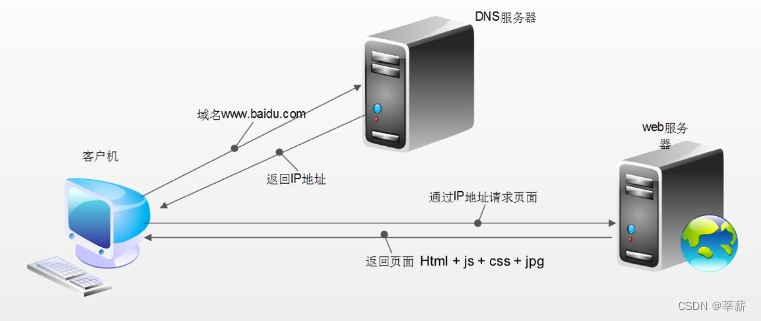
定义:DNS服务器(Domain Name System Server)是一种用于解析域名和IP地址之间映射关系的服务器。它将人类可读的域名转换为计算机可理解的IP地址,以便在互联网上进行通信。
工作原理:
-
当用户在浏览器中输入一个域名时,浏览器需要通过DNS服务器来获取对应的IP地址,然后才能与该网站建立连接。DNS服务器负责将域名解析为IP地址,并将解析结果返回给用户的设备。
-
DNS服务器通过一种分布式的、层级化的系统来工作。它们组成了一个大的网络,每个DNS服务器都存储着一部分域名和对应的IP地址。当一个DNS服务器无法解析某个域名时,它会向上一级的DNS服务器发送请求,直到找到能够解析的DNS服务器为止。
作用:
1.DNS根据域名解析出对应的IP地址
2.返回IP地址给本机电脑
3.使用IP地址去百度首页的服务器(仓库)
4.返回给客户端相应的数
除了域名解析外,DNS服务器还可以提供其他功能,如记录域名的邮件服务器、将一个域名重定向到另一个域名等。
总而言之,DNS服务器是用于解析域名和IP地址之间映射关系的服务器,它将域名转换为IP地址以便进行互联网通信。它通过分布式、层级化的系统工作,并可以缓存解析结果以提高效率。
三、Headers参数介绍
定义:Headers(头部)是HTTP协议中的一部分,用于在HTTP请求和响应中传递元数据信息。Headers以键值对的形式出现,每个键值对由冒号分隔,键值对之间用换行符分隔。在HTTP请求中,Headers包含了客户端(浏览器或其他客户端应用)向服务器发送的信息,如请求的方法、URI、支持的压缩算法、用户代理信息等。
那么我们如何找到Headers,查看客户端和服务器的交流过程呢?(重点)
1.打开你想要搜索的网址页面(这里我以百度网页进行展示,输入www.baidu.com进入百度首页。

2.点击F12或者鼠标右键点击检查,调出开发者工具

3.上述操作完成之后你就会得到以下页面
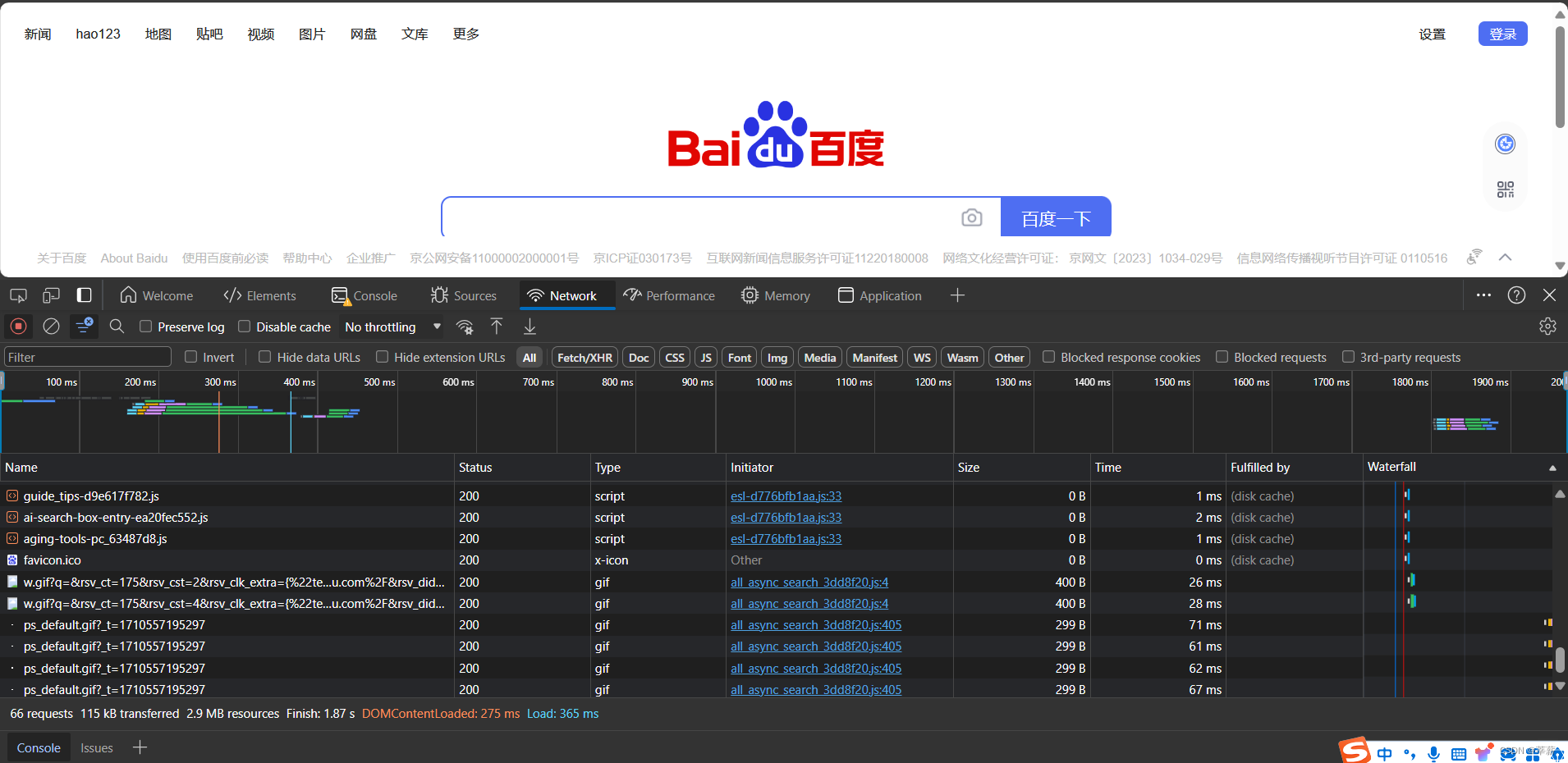
4.之后我们随便点开左侧的一个数据包,我们就可以寻找到Headers

常用参数介绍:
1. General:表示整体信息的描述
- Request url:该数据包的域名
- Request method:请求的方法 (GET POST)
- status Code:200 OK(状态码 301.302 代表跳转 404 代表没有访问成功 5开头的表示对象服务器出现问题 200成功)
- Remote Address:183.2.172.42:443(表示IP地址)
2. Response Headers:(响应头,响应信息):服务器需要遵循这种规则协议,浏览器才能解析出来,并且展示
- Content-Type:text/html; charset=utf-8(表示响应的内容是text、HTML格式,编码格式为utf-8)
- Set-Cookie:用于在响应中设置cookie。服务器可以通过此参数向浏览器发送cookie,以便在后续请求中进行身份验证或跟踪用户状态。
3. Request Headers:请求头(重点) - Accept:指定客户端能够接受的响应内容类型。可以使用MIME类型或通配符。例如,Accept: application/json表示客户端希望接收JSON格式的响应。
- Accept-Encoding:gzip, deflate, br,浏览器可接受的编码格式
- Accept-Language:zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6(浏览器可接受的编码语言)
- Cookie(重点):记录会话信息,记录和服务器的交流信息 包括用户名,身份信息(下次访问就不用填写账号信息),用于在服务器上跟踪用户的会话状态。 cookie是反爬的重点。
- Host:www.baidu.com(指定服务器的主机名和端口号)
- User-Agent:指定发送请求的用户代理信息。通常包含浏览器名称和版本号。
总结
前面的概念知识有点繁琐,但是这是爬虫必不可少的基础,坚持就是胜利,相信自己。
每个梦想,都是在现实中坚持不懈才实现的。