更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验
缓存发展史
缓存经典场景
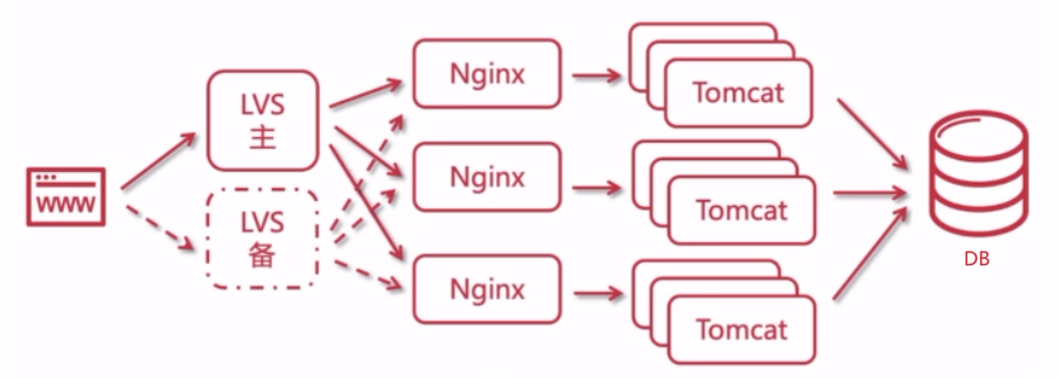
在没有引入缓存前,为了应对大量流量,一般采用:
- LVS 代理
- Nginx 做负载均衡
- 搭建 Tomcat 集群
这种方式下,随着访问量的增大,响应力越差,逐渐无法满足用户体验。
在引入缓存后:
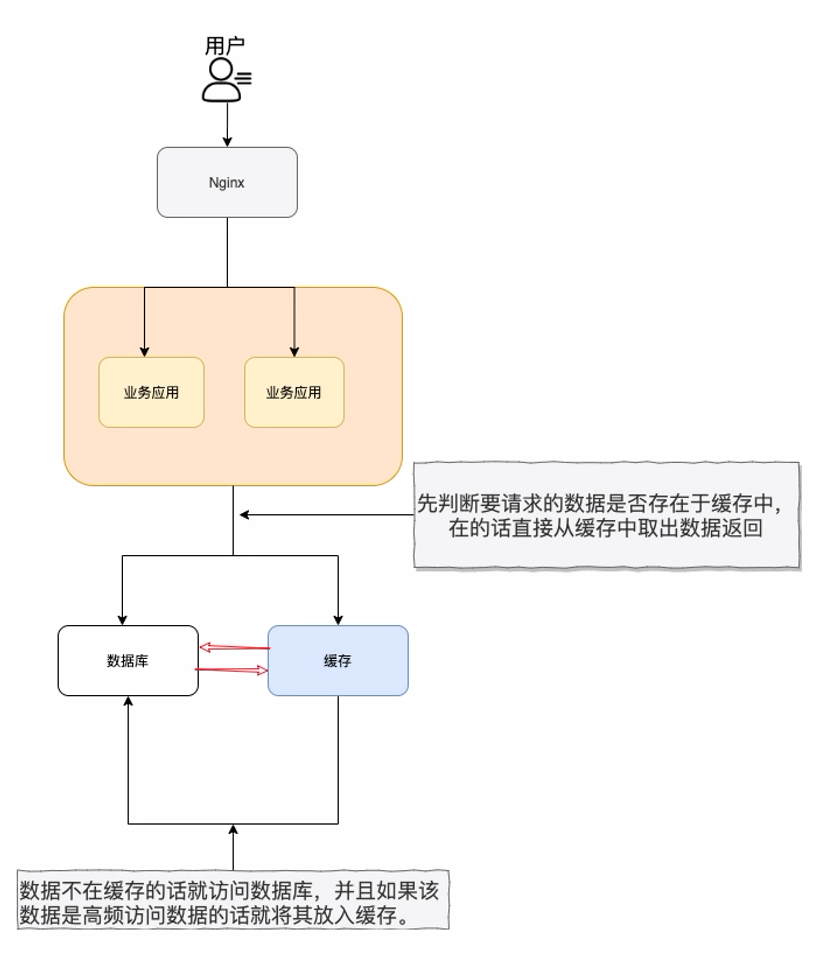
三大经典缓存读写策略
旁路缓存模式:Cache Aside Pattern
- 写:先更新
DB,然后直接删除cache - 读:从
cache中读取数据,读取到直接返回,否则查DB后返回,然后将查到的数据写入cache
读写穿透模式:Read/Write Through Pattern
- 写:先查
cache,cache中不存在,直接更新DB,否则先更新cache,然后cache服务更新DB - 读:从
cache中读取数据,读取到直接返回,否则查DB后写入到cache,之后返回数据
异步缓存写入:Write Behind Pattern
- 写:写入只更新
cache,然后异步批量更新DB - 读:从
cache中读取数据,读取到直接返回,否则查DB后写入到cache,之后返回数据
双写一致性解决方案
以上三种经典的读写策略在一定条件下都会产生缓存和数据库数据不一致的问题,这里给出两种解决方案
同步方案:
- 延迟双删:更新数据时先删除缓存,然后修改数据库,延迟一段时间后再次删除缓存
- 延迟一段时间是为了保证数据库集群下的数据同步
异步方案:
- 使用消息队列:更改代码加入异步操作缓存的逻辑代码,数据库操作完毕后将要同步的数据发给 mq,mq 的消费者从 mq 获取数据更新缓存
- 使用 canal 组件实现同步:不需要更改业务代码,只需要部署一个 canal 服务,canal 把自己伪装为了 mysql 的从节点,canal 读取 binlog 日志更新缓存
分布式缓存方案选型
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。
因为,本地缓存只在当前服务里有效,部署两个相同的服务,他们两者之间的本地缓存数据无法共通。
常见的分布式缓存方案为:
- Redis
- Memcache
- Tair
Redis 和 Memcache 对比
共同点:
- 都是基于内存的数据库,一般都用来当做缓存使用
- 都有过期策略
区别:
- Redis 支持的数据类型更丰富,而 Memcached 只支持最简单的 key-value 数据类型
- Redis 支持数据持久化,有 RDB 和 AOF 两种方案,而 Memcached 没有持久化功能,数据全部存在内存之中
- Redis 原生支持集群模式,Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据
- Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持
Redis 和 Tair 对比
共同点:
- 都支持数据持久化
- 都有过期策略
- 都支持分布式存储
区别:
- Redis 开发语言为 C,Tair 是 C++,
- Redis 支持的数据类型更丰富,而 Tair 主要支持字符串和列表
- Redis 利用主从赋值进行数据备份和同步 ,而 Tair 配置了复制因子的多副本机制,保证数据的可靠性
- 对于数据量大的场景下,Tair 更适用
推荐阅读:技术选型系列 - Tair&Redis对比
Redis 数据类型
Redis 的 key 设计规范
Redis 常见的数据类型:字符串(String),哈希(Hash),列表(List),集合(Set),有序集合(Zset)
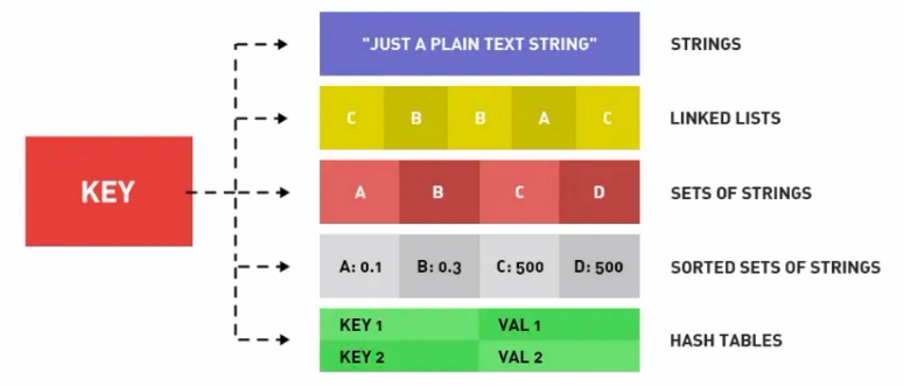
对于 Key 的设计,一般遵循如下规范:
- 可读性:一般以业务名(数据库名)为前缀,用冒号分割,例如:
数据库名:业务名:表名id - 简洁性:保证可读性的前提下,Key 的长度越短越好,原则上每个 Key 不能超过 44 字节,不能包含特殊字符(空格、换行、转义)
- 避免 BigKey:
- 情况一:键值对的值本身就很大,如 value 为 1 MB 的 string 类型,在业务层尽量将 string 大小控制在 10 KB 以下
- 情况二:键值对的值是集合类型,集合元素个数非常多,此时尽量把集合类型的元素个数控制在 1 万以下
- 针对高频 Key 进行设计:一般只将热点数据的 Key 考虑加入 Redis,如即时排行榜、直播信息等
String 类型
基础概念
String 的底层结构是,简单动态字符串(Simple Dynamic String,SDS),特点:
- SDS 不仅可以保存文本数据,还可以保存二进制数据
- SDS 获取字符串长度的时间复杂度是 O(1)
- Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出
在保存数字、小字符串时因为采用 INT 和 EMBSTR 编码,内存结构紧凑,只需要申请一次内存分配,效率更高,更节省内存。
对于超过44字节的大字符串时则需要采用 RAW 编码,申请额外的 SDS 空间,需要两次内存分配,效率较低,内存占用也较高,但大小不超过 512 MB,因此建议单个 value 尽量不要超过 44 字节。
扩展操作
缓存对象:
set key value单值缓存
针对数值进行操作:
-
# 设置数值数据增加指定范围的值 incr key incrby key increment incrbyfloat key increment -
# 设置数值数据减少指定范围的值 decr key decrby key increment -
# 设置数据具有指定的生命周期 setex key seconds value psetex key milliseconds value
分布式锁:setnx key:xxx true 设置分布式锁,用于请求限流
注意:
- string 在 redis 内部存储默认就是一个字符串,当遇到增减类操作
incr,decr时会转成数值型进行计算 - 按数值进行操作的数据,如果原始数据不能转成数值,或超越了redis 数值上限范围,将报错 9223372036854775807(java中Long型数据最大值,
Long.MAX_VALUE)
应用场景
主页高频访问信息显示控制,例如:新浪微博大 V 主页显示粉丝数与微博数量,需要针对这些高频访问的信息进行缓存处理
解决方案:
-
在 Redis 中为大 V 用户设定用户信息,以用户主键和属性值作为 Key,后台设定定时刷新策略即可
-
user:id:3506728370:fans 114514 user:id:3506728370:blogs 1919 user:id:3506728370:focuses 810 -
使用 json 格式保存数据
-
user:id:3506728370 {"fans":12210947, "blogs":6164, "focuses":83 }
Hash 类型
基础概念
与 Java 中的 HashMap 类似,但底层结构是压缩列表和哈希表,特点:
- 如果哈希类型元素个数小于 512(可设置 hash-max-ziplist-entries 修改),所有值小于 64 字节(可设置 hash-max-ziplist-value 修改),则会使用压缩列表作为底层数据结构
- 不满足上述条件则会使用哈希表作为数据结构
存储形式为:key-value,其中 value=[{field1, value1}, {field2, value2}, {field3, value3}],如下图所示:
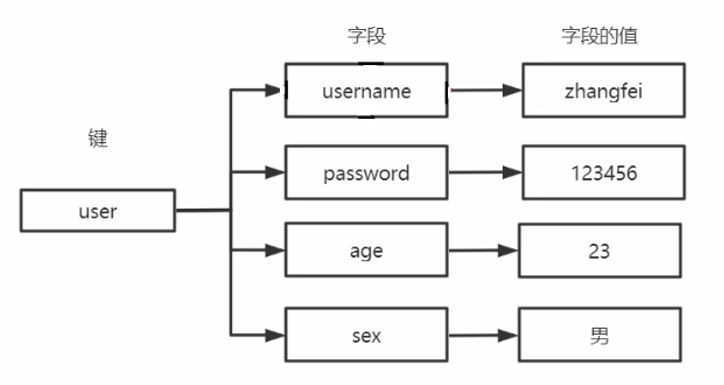
与 Java 中的 HashMap 不同的是,Redis 中的 Hash 底层采用了渐进式 rehash 的算法,在做 rehash 时会创建一个新的 HashTable,每次操作元素时移动一部分数据,直到所有数据迁移完成,再用新的 HashTable 来代替旧的,避免了因为 rehash 导致的阻塞,因此性能更高。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了:
Listpack的内部结构通常由一个连续的字节数组组成,其中包含了列表的元素和元数据- 支持一范围查询、索引和迭代,适用于需要频繁地进行插入、删除和访问的场景
扩展操作
对象缓存:
HMSET user {userId}:username zhangfei {userId}:password 123456HMSET user 1:username zhangfei 1:password 123456HMGET user 1:username 1:password
针对数值进行操作:
-
# 设置指定字段的数值数据增加指定范围的值 hincrby key field increment hincrbyfloat key field increment
注意:
- Hash 类型中 value 只能存储字符串,不允许存储其他数据类型,不存在嵌套现象。如果数据未获取到,对应的值为
nil - 每个 Hash 可以存储 2 32 − 1 2^{32}-1 232−1 个键值对,但不可以将 Hash 作为对象列表使用
- Hgetall 操作可以获取全部属性,如果内部 field 过多,遍历整体数据效率就很会低,有可能成为数据访问瓶颈
应用场景
双十一期间,电商平台用户购物车信息存储,用户会对购物车信息进行频繁访问和修改
解决方案:
购物车信息存储:
- 以用户 id 作为 Key
- value 形式为
{field1, value1},其中field1商品id,value1为数量,也可以选择型将价格、活动信息添加
购物车操作:
- 添加商品:
HSET cart:{userId} {商品Id} 1 - 添加数量:
HINCRBY cart{userId} {商品Id} 1 - 商品总数:
HLEN cart:{userId} - 删除商品:
HDEL cart:{userId} {商品Id} - 获取购物车内所有商品:
HGETALL cart:{userId}
当前仅仅是将商品 id 存储到了 Redis 中,在回显商品具体信息的时候,还需要拿着商品 id 查询一次数据库,获取完整的商品的信息
List 类型
基础概念
List 其实就是链表,只不过在 Redis 的实现中是双向的,如图所示:

3.2 之前的版本 List 底层由由双向链表和压缩列表实现,特点:
- 如果列表元素个数小于 512(可设置 list-max-ziplist-entries 修改),所有值小于 64 字节(可设置 list-max-ziplist-value 修改),则会使用压缩列表作为底层数据结构
- 不满足上述条件则会使用双向链表作为数据结构
3.2 之后的版本,底层仍采用了 ZipList(压缩列表)来做基础存储。当压缩列表数据达到阈值则会创建新的压缩列表。每个压缩列表作为一个双端链表的一个节点, 终形成一个 QuickList 结构。
QuickList:
- 内部结构由多个
ziplist组成,其中每个ziplist都是一个紧凑的压缩列表(compressed list),用于存储有序列表的元素。每个ziplist都包含多个节点,每个节点都可以存储一个元素。 - 使用分层的结构来加速范围查询操作。每个
ziplist都有一个 level 属性,表示该ziplist中节点的高度。通过在不同层级的ziplist上进行跳跃,可以快速定位到目标范围的起始位置,并进行后续的线性搜索。
扩展操作
移除指定数据:
-
lrem key count value
规定时间内获取并移除数据:
-
blpop key1 [key2] timeout brpop key1 [key2] timeout brpoplpush source destination timeout
注意:
- List 中保存的数据都是 string 类型的,数据总容量是有限的,最多 2 32 − 1 2^{32}-1 232−1 个元素
- List 具有索引的概念,但是操作数据时通常以队列的形式进行入队出队操作,或以栈的形式进行入栈出栈操作
- 获取全部数据操作结束索引设置为 -1
- List 可以对数据进行分页操作,通常第一页的信息来自于 List,第 2 页及更多的信息通过数据库的形式加载
应用场景
微信公众号发布文章或视频平台关注的博主发动态,在关注列表里面,这些消息要求按照时间进行推送
解决方案:
- 将订阅号消息放入用户关注列表 List 中
- 对于消息按照
LPUSH或RPUSH的方式压入队列中 - 如,订阅号发布消息:
LPUSH msg:{userId} xxx - 查看最新消息:
LRANGE msg:{userId} 0 4
Set 类型
基础概念
Set 类型的底层数据结构是由哈希表或整数集合实现的:
- 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用 IntSet 作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用 hash 作为 Set 类型的底层数据结构
- Redis提供了求交集、并集等命令
Set 与 Hash 存储结构完全相同,但 Set 仅存储键,不存储值(nil),并且值是不允许重复的
扩展操作
Set 最具特色的就是集合运算:

求两个集合的交、并、差集:
-
sinter key1 [key2 ...] sunion key1 [key2 ...] sdiff key1 [key2 ...]
求两个集合的交、并、差集并存储到指定集合中:
-
sinterstore destination key1 [key2 ...] sunionstore destination key1 [key2 ...] sdiffstore destination key1 [key2 ...]
将指定数据从原始集合中移动到目标集合中:
-
smove source destination member
在需要获取用户共同关注的场景下,利用 Set 的集合运算再合适不过了
应用场景
咨询和论坛交流类网站通常针对用户有严格的约束,因此有对黑名单和白名单功能的需求
解决方案:
- 基于经营战略设定问题用户发现、鉴别规则
- 周期性更新满足规则的用户黑名单,加入 Set 集合
- 用户行为信息达到后与黑名单进行比对,确认行为去向
- 黑名单过滤 IP 地址:应用于开放游客访问权限的信息源
- 黑名单过滤设备信息:应用于限定访问设备的信息源
- 黑名单过滤用户:应用于基于访问权限的信息源
对于某个平台需要举办抽奖活动,保证参与的账号唯一且不能重复中奖
解决方案:
- 将某个用户加入待抽奖集合:
SADD key {userId} - 抽取 n 名中奖者;
SRANDMEMBER key [n] / SPOP key [n]
SortedSet 类型
基础概念
SortedSet,也叫 ZSet:
- 其 value 就是一个有序的 Set 集合,元素唯一,并且会按照一个指定的 score 值排序。
- SortedSet 底层的利用 Hash 表保证元素的唯一性。
- 利用跳表(SkipList)来保证元素的有序性,因此数据会有重复存储,内存占用较高,是一种典型的以空间换时间的设计。
- 不建议在SortedSet中放入过多数据。
对于跳表(SkipList)首先是链表,但与传统的链表相比有几点差异:
- 跳表结合了链表和二分查找的思想
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
- 查找时从顶层向下,不断缩小搜索范围
- 整个查询的复杂度为 O ( log n)
应用场景
微博热搜排行榜、直播打赏排行榜、视频热门排行
解决方案:
- 维护一个排行榜的集合
- 点击对应条目,集合对应 Key 分值增加:
ZINCRBY hot:news 1 title1 - 展示排行前 n:
ZREVRANGE hot:news 0 9 WITHSCORES
BitMap 类型
基础概念
BitMap 即位图,是一串连续的二进制数组
- 可以通过偏移量 offset 定位元素。
- BitMap 通过最小的单位 bit 来边行 01 的设置,表示某个元素的值或者状态,时间复杂度为 O ( 1 ) \mathcal{O}(1) O(1)。
- 由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景
BitMap 内部存储形式如图:

存储对比:
- 场景:有 1 亿用户,日均 5 千万登陆用户,要求统计每日用户的登录信息
- 如果是 Set 记录用户 ID(通常为长整型),那么每一个用户都需要 32 bit 的空间来存储
- 如果是 BitMap,则只需要 1 bit 空间来表示用户是否登录即可
基础操作:
SETBIT:为位数组指定偏移量上的二进制位设置值,偏移量从 0 开始计数,二进制位的值只能为 0 或 1。返回原位置值。GETBIT:获取指定偏移量上二进制位的值。BITCOUNT:统计位数组中值为 1 的二进制位数量。BITOP:对多个位数组进行按位与、或、异或运算。
应用场景
签到统计,统计登录用户
解决方案:
- 签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月的签到情况最多用 31 个 bit 位
- 签到操作:
SETBIT uid:online:202403 15 1设置 uid 的用户在 2024 年 3 月的 16 日进行了签到 - 检查某天是否签到:
GETBIT uid:oneline:202403 15返回 1 说明 uid 用户在 2024 年 3 月的 16 日进行了签到 - 统计某月签到次数:
BITCOUNT uid:oneline:202303
Geo 地理位置类型
基础概念
Redis3.2 中增加了对 GEO 类型的支持。GEO,Geographic,地理信息的缩写
- 该类型,就是元素的二维坐标,在地图上就是经纬度
- redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作
基础操作:
- 添加位置信息
- 添加某个位置的经纬度信息到指定集合中:
GEOADD location-set longitude latitude name [longitude latitude name...]
- 添加某个位置的经纬度信息到指定集合中:
- 获取位置坐标:
- 根据输入的位置名称和集合获取坐标:
GEOPOS location-set name [name ...]
- 根据输入的位置名称和集合获取坐标:
- 计算两个位置之间的距离:
- 在某个集合中获取其中两个位置的直线距离:
GEODIST location-set location-x location-y [unit] - 其中
unit可选参数为m | km | mi | ft分别代表返回值的单位为米、千米、英里、英尺,不添加则默认单位为米 - 例如,计算武汉到宜昌的距离:
GEODIST hubeiCities wuhan yichang
- 在某个集合中获取其中两个位置的直线距离:
- 指定经纬度坐标范围查询位置信息:
- 命令:
GEORADIUS location-set longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [ASC|DESC] [COUNT count] radius半径大小,可选单位米、千米、英里、英尺WITHCOORD:可选参数,添加则在返回匹配的位置时会将该位置的经纬度一并返回WITHDIST:可选参数,添加则在返回匹配的位置时会将该位置与中心点之间的距离一并返回ASC|DESC:可选参数,添加ASC将返回的匹配位置根据距离从近到远排序,DESC则相反COUNT:可选参数,限制结果数量
- 命令:
- 指定集合中某个位置范围查询位置信息:
- 命令:
GEORADIUSBYMEMBER location-set location radius m|km|ft|mi [WITHCOORD] [WITHDIST] [ASC|DESC] [COUNT count] - 参数和
GEORADIUS用法一致
- 命令:
应用场景
存储不同位置信息:
- 添加武汉的坐标信息到
hubeiCities集合中:GEOADD hubeiCities 114.32538 30.534535 wuhan - 连续添加多个:
GEOADD hubeiCities 112.161882 32.064505 xiangyang 111.305197 30.708127 yichang 111.583717 30.463363 zhijiang
获取位置信息:
- 查询武汉市的位置信息:
GEOPOS hubeiCities wuhan结果返回经度和纬度信息 - 连续查询多个:
GEOPOS hubeiCities xiangyang yichang zhijiang
指定范围查询位置信息:
- 查找
hubeiCities集合中 112.927076 28.235653 (长沙) 500km 以内的位置信息,查找结果中应包含不超过 5 个位置的坐标信息,距离信息,并按距离由近到远排序:GEORADIUS hubeiCities 112.927076 28.235653 500 km withcoord withdist asc count 5 - 在
hubeiCities位置集合中查找距离武汉200km 以内的位置信息(这里指定的目标位置只能是hubeiCities中存在的位置,而不能指定位置坐标),查找结果中应包含不超过 2 个位置的坐标信息,距离信息,并按距离由远到近排序:GEORADIUSBYMEMBER hubeiCities wuhan 200 km withcoord withdist desc count 2
Redis 高级应用
发布订阅
基础概念
Redis 提供了发布订阅功能,可以用于消息的传输。
Redis的发布订阅机制包括三个部分:
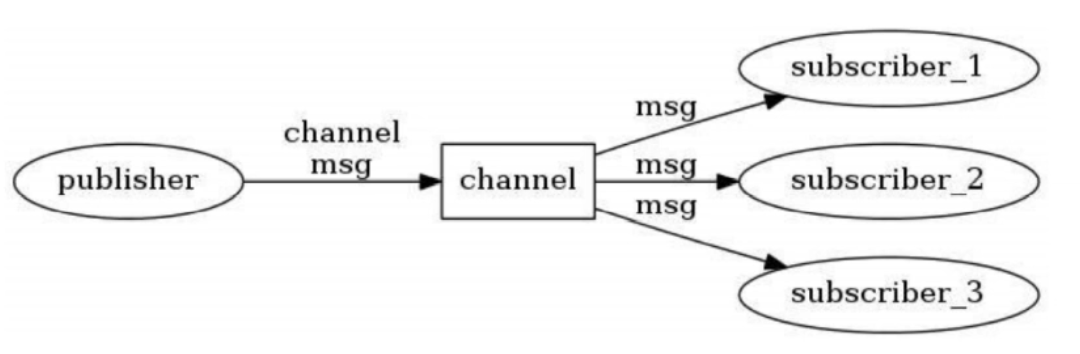
publisher:
- 发布者,是发送信息或数据的一方
- 在Redis中,发布者可以是任何客户端
- 发布者通过
PUBLISH命令将消息发送到一个特定的频道
subscriber:
- 订阅者,是接收信息或数据的一方
- 订阅者可以 “订阅” 一个或多个频道,以便接收发布者发送的消息
- 订阅者使用
SUBSCRIBE命令订阅自己感兴趣的频道
channel:
- 通道,是一种传输信息或数据的媒介
- 通道是发布者和订阅者之间的桥梁,发布者通过通道将信息发送到订阅者
- 通道没有明确的创建和销毁步骤:当有客户端订阅一个频道时,该频道就存在;当最后一个订阅该频道的客户端取消订阅,该频道并不立即消失,但是没有任何作用
指令详情
- 订阅消息:
SUBSCRIBE channel1 channel2,Redis 客户端channel1订阅 客户端channel2 - 发布消息:
PUBLISH channel message,Redis 客户端channel发布一条message,订阅了该channel的客户端将收到message - 退订:
UNSUBSCRIBE channel,退订channel,不再接收来自channel的消息 - 模式匹配订阅:
PSUBSCRIBE ch*,根据正则表达式匹配订阅,订阅所有以ch开头的channel - 模式匹配退订:
PUNSUBSCRIBE ch*,根据正则表达式匹配退订,退订所有以ch开头的channel
使用场景
在 Redis 哨兵模式中,哨兵通过发布与订阅的方式与 Redis 主服务器和 Redis 从服务器进行通信
Redisson是一个分布式锁框架,在 Redisson 分布式锁释放的时候,是使用发布与订阅的方式通知的
注意:如果是注重业务的消息,推荐用消息队列实现
Redis 事务
基础概念
Redis事务的本质是一组命令的集合:
- Redis 的事务是通过 multi、exec、discard 和 watch这四个命令来完成的
- Redis 的单个命令都是原子性的,所以这里需要确保事务性的对象是命令集合
- Redis 将命令集合序列化并确保处于同一事务的命令集合连续且不被打断的执行
- Redis 不能保障失败回滚
注意:Redis 的事务远远弱于 mysql,严格意义上,它不能叫做事务,只是一个命令打包的批处理,不能保障失败回滚
原理分析
事务的创建机制:
- 调用
multi命令,实际上会开启一个命令队列,后续的命令将被视为事务操作添加到该命令队列 - 如果期间出现问题,则会终止操作并清空队列
- 执行
exec命令,则批量提交队列中的命令,事务完成 - 若执行
discard,则不执行命令,直接清空队列
事务的回滚机制:
- 如果命令队列中的命令出现语法错误,Redis 2.6.5 之前的版本不会回滚,之后的版本会将整个事务回滚
- 如果是事务执行期间的错误,Redis 不会回滚,其他正确的指令会继续执行
watch监听机制;
- 该命令用于监视一个(或多个)key,如果在事务执行之前这个(或这些)key 被其他命令所改动,那么事务将被打断
watch命令可以通过监控某个 key 的变动,来决定是不是回滚- 主要应用于高并发的正常业务场景下,处理并发协调
LUA 脚本
基础概念
Iua 是一种轻量小巧的脚本语言,用标准 c 语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活
的扩展和定制功能。
由于 Redis 回滚机制并不完善,因此用 Redis 的事务一般引入 LUA 脚本来实现:
- Redis 会将整个 lua 脚本作为一个整体执行,中间不会被其他命令插入
- 因此在编写脚本的过程中无需担心会出现竞态条件,无需使用事务,能够保证原子性
EVAL 命令
自 2.6.0 起可用,通过内置的 lua 编译/解释器,可以使用 EVAL 命令对 lua 脚本进行求值:
- 命令格式:
EVAL script numkeys key [key ...] arg [arg ...] script:该参数是一段 lua 5.1 脚本程序,脚本不必(也不应该)定义为一个 lua 函数numkeys:用于指定键名参数的个数key:需要操作的键,可以指定多个,在 lua 脚本中通过KEYS[1]、KEYS[2]获取arg:附件的参数,可以指定多个,在 lua 脚本中通过ARGS[1]、ARGS[2]获取
LUA 脚本中调用 Redis 命令
redis.call():- 返回值就是 redis 命令执行的返回值
- 例如,
redis.call('SET', 'KEY:A', '114514') - 如果出错,则返回错误信息,不继续执行
redis.pcall():- 返回值就是redis命令执行的返回值
- 例如,
redis.pcall('GET', 'KEY:A') - 如果出错,则记录错误信息,继续执行
注意:脚本中,使用 return 语句将返回值返回给客户端,如果没有 return,则返回 nil
慢查询日志
客户端请求的生命周期
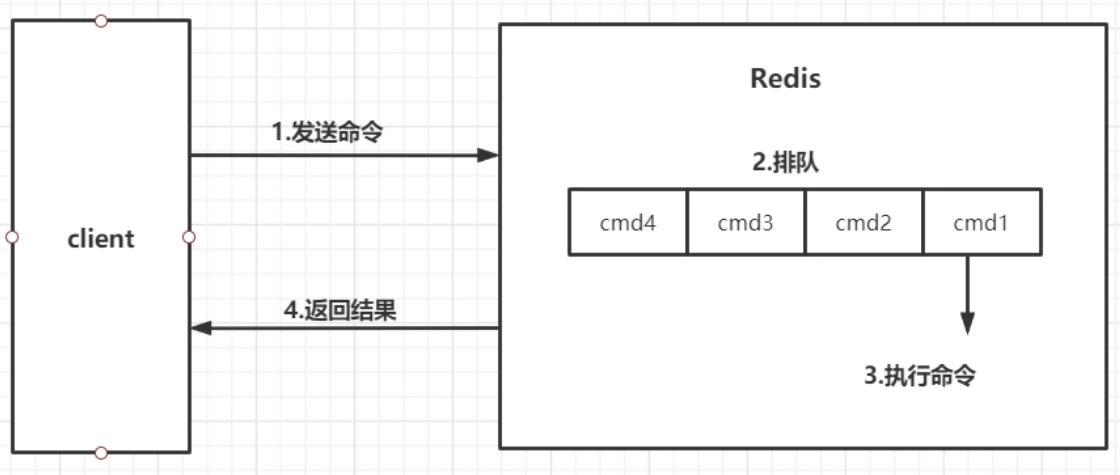
注意:
- 慢查询只统计 步骤3 执行命令的时间,所以没有慢查询并不代表客户端没有超时问题
- 换句话说 Redis 的慢查询记录时间指的是不包括客户端响应、发送回复等 IO 操作,而单单是执行一个查询命令所耗费的时间
慢查询设置
慢查询配置相关的参数
slowlog-log-slower-than:- 选项指定执行时间超过多少微秒的命令请求会被记录到日志上
- 例如,
slowlog-log-slower-than 100,执行时间超过100微秒的命令就会被记录到慢查询日志
slowlog-log-max-len:- 选项指定服务器最多保存多少条慢查询日志
- 服务器使用先进先出的方式保存多条慢查询日志、
- 当服务器储存的慢查询日志数量等于
slowlog-log-max-len值时,服务器在添加一条新的慢查询日志之前,会先将最旧的一条慢查询日志删除
上述配置,在 Redis 中有两种修改方法:
- 一种是直接修改配置文件
- 另一种是使用
config set命令动态修改:config set slowlog-log-slower-than 100
查看慢查询日志:
slowlog get:查看慢查询日志,slowlog get 10查看最新的 10 条慢查询记录
慢查询日志的组成
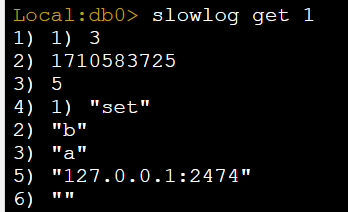
1) 1) 3 // 表示这是第三个被记录的慢查询
2) 1710583725 // Unix 时间戳,表示该慢查询发生的具体时间
3) 5 // 代表查询执行的时长,单位为 ms
4) 1) "set" // 具体的 Redis 命令
2) "b" // 命令的 参数
3) "a"
5) "127.0.0.1:2474" // 发出此指令的客户端的 IP 地址和端口号
6) "" // 代表该查询所在的数据库 ID,"" 表示默认数据库



![三. 操作系统 (6分) [理解|计算]](https://img-blog.csdnimg.cn/direct/18d2bbd4478341e0aa06f19bbf5be332.png)