原文
8万字带你入门Rust
1.包管理工具Cargo
新建项目
1)打开 cmd 输入命令查看 cargo 版本
cargo --version
2) 使用 cargo new 项目名
在文件夹,按 shift + 鼠标右键 ,打开命令行,运行如下命令,即可创建一个新项目
cargo new hello-rust
Cargo 已经帮我们创建好默认项目了,还创建了个 git 的本地仓库,还有一些配置文件。
src/main.rs: 为编写应用代码的地方
Cargo.toml: 项目的配置文件,其中包括项目名,依赖等内容。
Cargo.lock: 如果项目编译正常,会生成一个Cargo.lock文件,这个文件记录项目依赖的实际版本。不需要碰这个文件,让 Cargo 处理它就行了。
.gitignore: 是个git忽略文件列表,在上传到git时,并不是所有文件都要上传到github的。同时这也提醒我们,cargo为我们创建了一个github仓库。
3)在终端中构建项目
cargo build
4)编译并运行
cargo run
5)可以指定版本管理系统,--vcs=git,可选参数有 git, hg, pijul, fossil, none
cargo new --vcs=git
使用 --vcs 参数指定或者切换版本管理系统,如果文件夹已经有了仓库了,那么默认就不会创建仓库了。
6)检查代码的工具,该命令快速检查代码确保其可以编译,但并不产生可执行文件:
cargo check
7)发布项目
发布项目时,可以以release构建项目,以让 Rust 代码运行的更快,不过启用这些优化也需要消耗更长的编译时间。
cargo build --release
Debug是为了开发,你需要经常快速重新构建;
Release是为用户构建最终程序,它们不会经常重新构建,并且希望程序运行得越快越好。
编写第一个rust程序
Cargo.toml 文件是一个管理项目配置的文件,包括项目依赖等相关配置
在 [dependencies] 区域中添加依赖:ferris-says = "0.3.1",这个根据当前的版本来写版本号
终端运行
cargo build
即完成添加依赖
在main.rs 中编写代码
use ferris_says::say; // from the previous step
use std::io::{stdout, BufWriter};
fn main() {let stdout = stdout();let message = String::from("Hello fellow Rustaceans!");let width = message.chars().count();let mut writer = BufWriter::new(stdout.lock());say(message.as_str(), width, &mut writer).unwrap();
}
原文代码似乎不适用于当前版本,say() 函数第一个参数期望的类型是 &str(字符串切片类型),而不是 &[u8](字节切片类型)。可以使用 as_str() 方法来实现,而不是 as_bytes()。
编译并运行代码
cargo run
运行结果如下

格式化输出
fn main() {// 1println!("{} days", 31); // {}相当于c++的%d这种占位符println!("{} day {} month", 4, 3); // 使用两个占位符// 2println!("{} world", "hello"); // 字符串类型替换掉占位符,{}可以表示作为任意类型的占位符,即通用// 3println!("{0} 是 张三, {1} 是 李四,张三不是 {1}, 李四不是 {0}", "张三", "李四"); // 占位符里的序号i,由 ,后的序号为i的变量替换// 4 用参数名代替序号println!("{subject} {verb} {object}", object = "你", subject = "我", verb = "爱");// 5 输出带有指定格式占位符的字符串// :前表示的是参数的序号,即,后边的参数序号// 后边表示以进制格式,{x}: 十六进制;{o}: 八进制;{b}: 二进制// 代码中的字符串换行,打印出来也是换行的println!("{} 的二进制表示是: {0:b}{0} 的八进制表示是: {0:o}{0} 的16进制表示是: {0:x}", 10);// 6 指定宽度对齐// 左对齐println!("{number:<width$}", number = 1000, width = 6);// <width$ 是一个格式说明符,其中 width 是通过 $ 符号引用的命名参数,表示宽度为 6。< 则表示左对齐// 右对齐,一共4位,左边两个空白格println!("{number:>width$}", number = 1000, width = 6);let name = "Alice";println!("{:15}", name); // 默认情况下左对齐,宽度为10println!("{:<15}", name); // 左对齐,宽度为10println!("{:^15}", name); // 居中对齐,宽度为10println!("{:>15}", name); // 右对齐,宽度为10// 7 数字输出缺位补0println!("{number:>0width$}", number = 1, width = 6);
}
2.变量和数据类型
fn main() {// 1.定义变量(不可变)let x = 5;let y = 5.0;let str1 = "hello_1";let str2 = String::from("hello_2");println!("{0} {1} {2} {3}", x, y, str1, str2);// 2.定义变量时指定类型let x: i32 = 5;let y: f64 = 5.0;// let str1: String = "hello_1"; // 错误的,"" 类型的字符串是 &str,而不是 QStringlet str1: &str = "hello";println!("{0} {1} {2}", x, y, str1);// 3.定义可变变量let mut x: i32 = 5;println!("{}", x);x = 10;println!("{}", x);
}
Shadowing
可以使用相同的名字声明新的变量,新的变量就会 shadow 之前声明的同名变量
基本数据类型
数值类型又分为整数型、浮点数、序列类型。
整型
| 长度 | 有符号 | 无符号 | 无符号范围 |
|---|---|---|---|
| 8-bit | i8 | u8 | 0~127 |
| 16-bit | i16 | u16 | 0 ~ 255 |
| 32-bit | i32 | u32 | 0 ~4294967295 |
| 64-bit | i64 | u64 | |
| arch | isize | usize |
其他长度也类似,8-bit、16-bit、128-bit
arch 长度根据计算机的架构决定,64位计算机就是64 …
const MAX_POINTS = 100_000; // 可以使用下划线增强可读性Byte类型(仅支持 u8),例子:b'A'
浮点型
| 长度 | 类型 |
|---|---|
| 32-bit | f32 |
| 64-bit | f64 |
所有的浮点型都是有符号的
默认使用的浮点是64位的
fn main() {let x = 2.0; // f64let y: f32 = 3.0; // f32
}
字符类型
字符使用的是单引号,字符串使用的是双引号
Rust的char类型是Unicode的,支持更多的字符,占4字节
let x = 'z';let y: char = 'c';let heart_eyed_cat = '😻';let love_message = "I love Rust! 😍";println!("{0} {1} {2}\n{3}", x, y, heart_eyed_cat, love_message);
布尔类型
fn main() {let t = true;let f: bool = false; // 指定变量类型
}
复合类型
复合类型可以将多个值组合成一个类型。Rust 有两个原生的复合类型:元组(tuple)和数组(array)。
元组
元组是一个将多个其他类型的值组合进一个复合类型的主要方式。可以将多个不同类型的值进行复合,但是元组长度固定:一旦声明,其长度不会增大或缩小。
// 1.定义元组,小括号let tup1 = (500, 6.4, 1);let tup2: (i32, f32, bool) = (500, 6.4, false);// 2.解构let (x, y, z) = tup1;let (a, b, c) = tup2;println!("{} {1} {2}", x, y, z);println!("{} {1} {2}", a, b, c);// 3.取出元素第一个元素,下标和数组一样从0开始,用.运算符取出let x1 = tup1.0;println!("{}", x1);
数组
与元组不同,数组中的每个元素的类型必须相同。Rust 中的数组与一些其他语言中的数组不同,Rust中的数组长度是固定的。
// 1let a = [1, 2, 3, 4, 5]; // 中括号let b = ["first", "second", "third", "fourth"];let c:[i32, 5] = [1, 2, 3, 4, 5];// 2. [数组初始值 ; 数组长度]let d = [3; 5]; // 创建了一个数组d,其中有5个元素,这五个元素都是整数3// 访问数组元素和其他语言一样,使用索引 // 数组访问越界编译可能不会提示,在运行时会 RE println!("{} {1} {2} {3} {4}", d[0], d[1], d[2], d[3], d[4]);
数组的用处:如果你想让你的数据存放在 stack 上,或者想保证有固定数量的元素。
常量
常量与不可变量是类似的,但是是不同的。常量(constants) 是绑定到一个名称的不允许改变的值。
不可变变量(Immutable Variables):
- 不可变变量是在运行时确定的,一旦被绑定了就不能再改变值的变量。
- 在Rust中,所有变量默认都是不可变的,如果需要使变量可变,可以使用mut关键字来标记变量为可变的。
- 不可变变量一旦绑定了值,就不能再修改为其他值,但可以使用遮蔽(shadowing)来重新绑定新的值。
- 不可变变量在其作用域内都不能被修改,但可以被重新绑定。
总的来说,常量是编译时就确定的值,而不可变变量是运行时确定的值,在程序执行过程中可以进行遮蔽和重新绑定。
常量(Constants):
- 常量是在编译时就已经确定的、不可变的值。
- 常量必须在声明时就被显式地标记为const关键字,并且必须注明其类型
- 常量的值在整个程序执行期间都不能改变。
- 常量可以在任何作用域中声明,包括全局作用域和局部作用域。
- 常量的名称使用全大写字母,单词之间用下划线分隔。
fn main() {const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
}
变量只有初始化了才可以使用
let x: i32; // 未初始化,但被使用,errorlet y: i32; // 未初始化,也未被使用,warningprintln!("x is equal to {}", x);
变量解构
let (mut x, y) = (1, 2);x += 2;println!("{} {1}", x, y);
parse 解析类型
使用 parse() 函数解析类型时,要标注需要转换成哪种类型
使用 trim() 去掉字符串首尾的空格
let mut space = " 1";let x:i32 = space.trim().parse().expect("not a number");println!("{} {}",space, x);space = "00001";let x:i32 = space.parse().expect("not a number");println!("{} {}",space, x);
3.函数与流程控制
与 c 语言不同,rust 对函数声明的位置没有要求
fn main() {function(10); // argument
}
fn function(x: i32) { // parameter,必须指明所有变量的类型println!("{}", x);
}
语句和表达式
表达式是有返回值的,而语句没有
let x = 10; // 语句x + 10 // 表达式,如果表达式后边加上";",那么就变成语句了,就没有返回值了
fn main() {let y = {let x = 1;x + 3 // {}代码块的返回值是最后一个表达式// 如果加上分号,代码块中就没有表达式了,就不会返回值了};println!("{}", y);
}
函数的返回值
- 在 rust 中,返回值就是函数体里边最后一个表达式的值
- 若想提前返回,需要使用 return 关键字,并指定一个值,返回值时必须加
{} - 在 -> 符号后边声明函数返回值的类型,但是不可以为返回值命名
fn main() {let x = puls_five(5);println!("{}", x);
}fn puls_five(x: i32) -> i32 {if x == 5 {return x;// 这里是使用 return 关键字返回值,";" 加不加都不影响结果}x + 5
}
if 表达式
if的条件必须是bool类型,与 c++ 等其他语言不同,rust 不会将其他条件转换成bool- if 表达式中,与条件相关联的代码块叫做分支 (arm)
当使用较多的 else if 时,最好使用 match 来重构
由于 if 是表达式,因此可以将 if 表达式的返回值赋值给变量,但是所有情况下 返回值的类型必须相同,i32 和 i64 这种情况也是不可以的
fn main() {let flag = true;let number: i32 = if flag {5} else {6};println!("{}", number);
}
循环
loop
fn main() {let mut counter = 0;let result = loop {counter += 1;if counter == 10 {break counter * 2; // 当相等时,使用 break 关键字返回值 counter * 2 // 这里是使用 break 关键字返回值,";" 加不加都不影响结果}};println!("{}", result);
}
循环标签
在多个循环之间消除歧义
如果存在嵌套循环,break 和 continue 应用于此时最内层的循环。你可以选择在一个循环上指定一个 循环标签(loop label),然后将标签与 break 或 continue 一起使用,使这些关键字应用于已标记的循环而不是最内层的循环。
fn main() {let mut count = 0;'counting_up: loop {println!("count = {count}");let mut remaining = 10;loop {println!("remaining = {remaining}");if remaining == 9 {break;}if count == 2 {break 'counting_up;}remaining -= 1;}count += 1;}println!("End count = {count}");
}// 输出
/*count = 0remaining = 10remaining = 9count = 1remaining = 10remaining = 9count = 2remaining = 10End count = 2
*/
while
fn main() {let mut counter = 3;while counter != 0 {println!("{}", counter);counter = counter - 1;}println!("finish");
}
while 遍历数组
fn main() {let a = [1, 2, 3, 4, 5];let mut index = 0;while index < 5 {println!("{}", a[index]);index += 1;}
}
for
更好的遍历数组的方式是 for,每次循环不需要判断条件
fn main() {let a = [11, 22, 33, 44, 55];
// iter() 返回一个迭代器,这个迭代器是对 v 的引用,因此不会转移所有权for x in a.iter() { println!("{}", x);}// 直接遍历 a 似乎没有问题// 但是如果是 vector,for x in v {} 这样遍历后,里边元素的所有权就被转移了// Range// rev方法可以反转 Rangefor x in (1..=5).rev() {println!("{}", x);}for x in 0..5 {println!("{}", a[x]);}
}
杂项
区间,Range
// 1. a..=b ---> [a,b]// 2. a..b ---> [a,b)let secret_number = rand::thread_rng().gen_range(1..=100);println!("神秘数是:{}", secret_number);
4.所有权
认识所有权
所有权(系统)是 Rust 最为与众不同的特性,对语言的其他部分有着深刻含义。它让 Rust 无
需垃圾回收(garbage collector)即可保障内存安全,因此理解 Rust 中所有权如何工作是十
分重要的。
栈(Stack)与堆(Heap)
- 栈和堆都是代码在运行时可供使用的内存,但是它们的结构不同。栈中的所有数据都必须占用已知且固定的大小。在编译时大小未知或大小可能变化的数据,要改为存储在堆上。 堆是缺乏组织的:当向堆放入数据时,你要请求一定大小的空间。内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。这个过程称作 在堆上分配内存(allocating on the heap),有时简称为 “分配”(allocating)。(将数据推入栈中并不被认为是分配)。因为指向放入堆中数据的指针是已知的并且大小是固定的,你可以将该指针存储在栈上,不过当需要实际数据时,必须访问指针。
- 入栈比在堆上分配内存要快,因为(入栈时)分配器无需为存储新数据去搜索内存空间;其位置总是在栈顶。相比之下,在堆上分配内存则需要更多的工作,这是因为分配器必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
- 访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。处理器在处理的数据彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。
- 跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据的数量,以及清理堆上不再使用的数据确保不会耗尽空间,这些问题正是所有权系统要处理的。一旦理解了所有权,就不需要经常考虑栈和堆了,不过明白了所有权的主要目的就是管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
所有权规则
- Rust 中的每一个值都有一个 所有者(owner)。
- 值在任一时刻有且只有一个所有者。
- 当所有者(变量)离开作用域,这个值将被丢弃。
String 类型
字符串字面值:我们在编译时就知道其内容,所以文本被直接硬编码进最终的可执行文件中,这使得字符串字面值快速且高效。
String 类型管理被分配到堆上的数据,所以能够存储在编译时未知大小的文本。可以使用 from 函数基于字符串字面值来创建 String
let s = String::from("hello");
内存与分配
对于 String 类型,为了支持一个可变,可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容。这意味着:
- 必须在运行时向内存分配器(memory allocator)请求内存。
- 需要一个当我们处理完 String 时将内存返回给分配器的方法。
第一部分由我们完成:当调用 String::from 时,它的实现 (implementation) 请求其所需的内
存。这在编程语言中是非常通用的。
然而,第二部分实现起来就各有区别了。在有垃圾回收(garbage collector,GC)的语言中,
GC 记录并清除不再使用的内存,而我们并不需要关心它。在大部分没有 GC 的语言中,识别
出不再使用的内存并调用代码显式释放就是我们的责任了,跟请求内存的时候一样。从历史的
角度上说正确处理内存回收曾经是一个困难的编程问题。如果忘记回收了会浪费内存。如果过
早回收了,将会出现无效变量。如果重复回收,这也是个 bug。我们需要精确的为一个 allocate 配对一个 free 。
Rust 采取了一个不同的策略:内存在拥有它的变量离开作用域后就被自动释放。
fn main() {{let s = String::from("hello"); // 从此处起,s 是有效的// 使用 s} // 此作用域已结束,// s 不再有效
}
当变量 s 离开作用域,Rust 为我们调用 drop 函数 ,在这里 String 的作者可以放置释放内存的代码。Rust 在结尾的 } 处自动调用 drop 。这与 C++ 的 RAII 模式类似
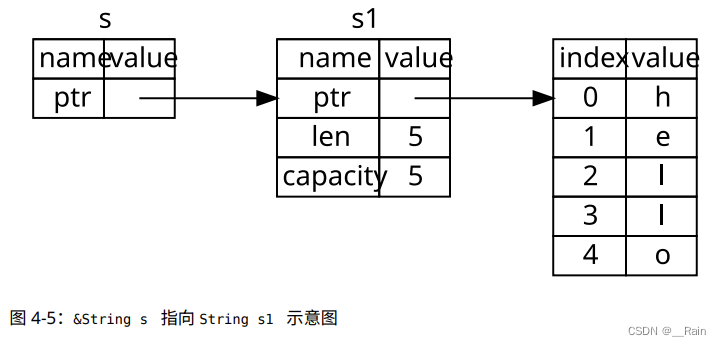
移动(旧变量不可用)
// String 类型
fn main() {let s1 = String::from("hello");let s2 = s1;// 变量 s2 的内存表现,它有一份 s1 指针、长度和容量的拷贝println!("{}", s1); // 报错,s1已经无效,不能使用// 这个过程看起来和浅拷贝差不多,但还是有点区别,rust会认为原来的s1已经失效// 因此 Rust 不需要在 s1 离开作用域后清理任何东西,避免了二次释放的错误
}
克隆
fn main() {let s1 = String::from("hello");let s2 = s1.clone(); // 和深拷贝一样的效果println!("{}", s2);
}
只在栈上的数据:拷贝
// 具有 cpoy trait 的类型
// 将 5 绑定到 x ,接着生成一个值 x 的拷贝并绑定到 y
fn main() {let x = 5;let y = x;
}
- 如果复合类型的元素都是具有
cpoy trait的,那么这个复合类型也具有cpoy trait属性 - Rust 不允许自身或其任何部分实现了 Drop trait 的类型使用 Copy trait
如下是一些 Copy 的类型:
- 所有整数类型,比如 u32 。
- 布尔类型,bool ,它的值是 true 和 false 。
- 所有浮点数类型,比如 f64 。
- 字符类型,char 。
- 元组,当且仅当其包含的类型也都实现 Copy 的时候。比如,(i32, i32) 实现了 Copy ,但(i32, String) 就没有。
所有权与函数
将值传递给函数与给变量赋值的原理相似。向函数传递值可能会移动或者复制,就像赋值语句一样。
fn main() {let s = String::from("hello"); // s 进入作用域takes_ownership(s); // s 的值移动(所有权转移)到函数里// ... 所以到这里不再有效let x = 5; // x 进入作用域makes_copy(x); // x的值拷贝到函数makes_copy中// 在后面可继续使用 x}fn takes_ownership(some_string: String) { // some_string 进入作用域println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法
// some_string 占用的内存被释放fn makes_copy(some_integer: i32) { // some_integer(x的副本) 进入作用域println!("{}", some_integer);
} // 这里,some_integer 移出作用域,没有特殊之处
返回值与作用域
返回值也可以转移所有权
fn main() {// gives_ownership 将返回值的所有权转移给 s1let s1 = gives_ownership();let s2 = String::from("hello"); // s2 进入作用域// s2 被移动到takes_and_gives_back 中,它也将返回值移给 s3let s3 = takes_and_gives_back(s2);
}
// s3 离开作用域并被丢弃
// s2 也移出作用域,但已被移走,所以什么也不会发生
// s1 离开作用域并被丢弃fn gives_ownership() -> String {
// 将返回值移动给调用它的函数let some_string = String::from("yours"); // some_string 进入作用域some_string // 返回 some_string
}// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域a_string // 返回 a_string 并移交所有权
}变量的所有权总是遵循相同的模式:将值赋给另一个变量时移交所有权。当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有。
(引用,References)如何仅使用变量的值而不获取其所有权
fn main() {let s1 = String::from("hello");let len = calculate_length(&s1);println!("The length of '{}' is {}.", s1, len);
}fn calculate_length(s: &String) -> usize {// s 是 String 的引用s.len()
}
// s 离开了作用域,但因为它并不拥有引用值的所有权,所以什么也不会发生
我们将创建一个引用的行为称为 借用(borrowing)。
正如变量默认是不可变的,引用也一样,(默认)不允许修改引用的值。
如果要改变引用的值,就需要可变引用作为参数,在 & 后增加 mut 关键字
fn main() {let mut s = String::from("hello");change(&mut s);
}
fn change(some_string: &mut String) {some_string.push_str(", world");
}
(1)rust为了避免数据竞争,不允许对一个已经有可变引用的变量再次创建可变引用,如下:
fn main() {let mut s = String::from("hello");let r1 = &mut s;let r2 = &mut s;println!("{}, {}", r1, r2);
}
可以使用大括号来创建一个新的作用域,以允许拥有多个可变引用,只是不能 同时拥有:
fn main() {let mut s = String::from("hello");{let r1 = &mut s;} // r1 在这里离开了作用域,所以我们完全可以创建一个新的引用let r2 = &mut s;
}
(2)Rust 不允许同时使用可变与不可变引用
fn main() {let mut s = String::from("hello");let r1 = &s; // 没问题let r2 = &s; // 没问题// 多个不可变引用是可以的,但不能同时存在可变引用let r3 = &mut s; // 大问题println!("{}, {}, and {}", r1, r2, r3);
}
(3)一个引用的作用域:从声明的地方开始一直持续到最后一次使用为止。例如,因为最后一次使用不可变引用(println! ),发生在声明可变引用之前,所以如下代码是可以编译的:
fn main() {let mut s = String::from("hello");let r1 = &s; // 没问题let r2 = &s; // 没问题println!("{} and {}", r1, r2);// 此位置之后 r1 和 r2 不再使用let r3 = &mut s; // 没问题println!("{}", r3);
}
悬垂引用
Rust 中编译器确保引用永远也不会变成悬垂状态:当你拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
fn main() {let reference_to_nothing = dangle();
}fn dangle() -> &String { // dangle 返回一个字符串的引用let s = String::from("hello"); // s 是一个新字符串&s // 返回字符串 s 的引用
} // 这里 s 离开作用域并被丢弃。其内存被释放。
// 危险!
这里的解决方法是直接返回 String :
fn main() {let string = no_dangle();
}
fn no_dangle() -> String {let s = String::from("hello");s
}
这样就没有任何错误了,所有权被移动出去,所以没有值被释放。
引用的规则
- 在任意给定时间,要么只能有一个可变引用,要么只能有多个不可变引用。
- 引用必须总是有效的。
切片,字符串 slice
字符串 slice(string slice)是 String 中一部分值的引用,即 &str 类型
字符串字面值就是 slice
let s = "Hello, world!"; // s是字符串字面量,是 &str 类型
这里 s 的类型是 &str :它是一个指向二进制程序特定位置的 slice。这也就是为什么字符串字面值是不可变的,&str 是一个不可变引用。
定义一个获取字符串 slice 而不是 String 引用的函数使得我们的 API 更加通用并且不会丢失任何功能:
fn first_word(s: &str) -> &str {let bytes = s.as_bytes();for (i, &item) in bytes.iter().enumerate() {if item == b' ' {return &s[0..i];}}&s[..] //返回整个字符串
}
其他类型的 slice
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
这个 slice 的类型是 &[i32] 。它跟字符串 slice 的工作方式一样,通过存储第一个集合元素的
引用和一个集合总长度。
5.结构体
元组结构体
元组结构体有着结构体名称提供的含义,但没有具体的字段名,只有字段的类型。
要定义元组结构体,以 struct 关键字和结构体名开头并后跟元组中的类型
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {let black = Color(0, 0, 0);let origin = Point(0, 0, 0);
}
注意 black 和 origin 值的类型不同,因为它们是不同的元组结构体的实例。你定义的每一个结构体有其自己的类型,即使结构体中的字段可能有着相同的类型。例如,一个获取 Color 类型参数的函数不能接受 Point 作为参数,即便这两个类型都由三个 i32 值组成。
类单元结构体
类单元结构体常常在你想要在某个类型上实现 trait 但不需要在类型中存储数据的时候发挥作用。
struct AlwaysEqual;
fn main() {let subject = AlwaysEqual;
}
方法语法
方法(method)与函数类似:它们使用 fn 关键字和名称声明,可以拥有参数和返回值,同时包含在某处调用该方法时会执行的代码。不过方法与函数是不同的,因为方法在结构体的上下文中被定义,并且它们第一个参数总是 self ,它代表调用该方法的结构体实例。
#[derive(Debug)]struct Rectangle {width: u32,height: u32,
}// impl 块(impl 是 implementation 的缩写)
// 这个 impl 块中的所有内容都将与 Rectangle 类型相关联
// 每个结构体都允许拥有多个 impl 块
impl Rectangle {
// 这里self使用引用,因为我们并不想获取所有权,只希望能够读取结构体中的数据,而不是写入fn area(&self) -> u32 {self.width * self.height}
}fn main() {let rect1 = Rectangle {width: 30,height: 50,};println!("The area of the rectangle is {} square pixels.",rect1.area());println!("{:#?}", rect1);
}
rust的解引用
在 C/C++ 语言中,有两个不同的运算符来调用方法:. 直接在对象上调用方法,而 -> 在一个对象的指针上调用方法,这时需要先解引用(dereference)指针。换句话说,如果 object 是一个指针,那么 object->something() 就像 (*object).something() 一样。
Rust 并没有一个与 -> 等效的运算符;相反,Rust 有一个叫 自动引用和解引用(automatic referencing and dereferencing)的功能。方法调用 是 Rust 中少数几个拥有这种行为的地方。
它是这样工作的:当使用 object.something() 调用方法时,Rust 会自动为 object 添加 & 、&mut 或 * 以便使 object 与方法签名匹配。也就是说,这些代码是等价的:
#[derive(Debug,Copy,Clone)]
struct Point {x: f64,y: f64,
}
impl Point {fn distance(&self, other: &Point) -> f64 {let x_squared = f64::powi(other.x - self.x, 2);let y_squared = f64::powi(other.y - self.y, 2);f64::sqrt(x_squared + y_squared)}
}
fn main() {let p1 = Point { x: 0.0, y: 0.0 };let p2 = Point { x: 5.0, y: 6.5 };p1.distance(&p2);(&p1).distance(&p2);
}
关联函数
所有在 impl 块中定义的函数被称为 关联函数(associated functions),因为它们与 impl 后面命名的类型相关。我们可以定义不以 self 为第一参数的关联函数(因此不是方法),因为它们并不作用于一个结构体的实例。我们已经使用了一个这样的函数:在 String 类型上定义的 String::from 函数。
不是方法的关联函数经常被用作返回一个结构体新实例的构造函数。这些函数的名称通常为
new ,但 new 并不是一个关键字。例如我们可以提供一个叫做 square 关联函数,它接受一
个维度参数并且同时作为宽和高,这样可以更轻松的创建一个正方形 Rectangle 而不必指定
两次同样的值:
#[derive(Debug)]
struct Rectangle {width: u32,height: u32,
}
impl Rectangle {fn square(size: u32) -> Self {Self {width: size,height: size,}}
}
fn main() {let sq = Rectangle::square(3);
}
6.1枚举
枚举(enumerations),也被称作 enums。枚举允许你通过列举可能的 成员(variants)来定义一个类型。
enum IpAddrKind {V4,V6,
}
struct IpAddr {kind: IpAddrKind,address: String,
}impl IpAddrKind {fn call(&self) {}
}fn main() {let home = IpAddr {kind: IpAddrKind::V4,address: String::from("127.0.0.1"),};let loopback = IpAddr {kind: IpAddrKind::V6,address: String::from("::1"),};home.kind.call(); // 调用枚举的方法loopback.kind.call(); // 调用枚举的方法
}可以使用 impl 来为结构体定义方法那样,在枚举上定义方法
Option 枚举
存于在 Prelude(预导入模块) 中
Rust 并没有空值(NULL),但有一个可以编码存在或不存在概念的枚举,就是 Option
定义如下:
enum Option<T> {None,Some(T),
}
fn main() {let some_number = Some(5); // some_number: Option<i32>let some_char = Some('e'); // some_char: Option<char>let absent_number: Option<i32> = None; // None值必须指定 T 的类型
}
fn main() {let x: i8 = 5;let y: Option<i8> = Some(5);let sum = x + y; //(×),因为 Option<T> 和 <T> 不是一个类型,无法直接相加
}
6.2模式匹配
match 控制流结构
enum Coin {Penny,Nickel,Dime,Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {match coin {// 一个分支有两个部分:一个模式和一些代码。// 模式 代码Coin::Penny => 1, // 一个分支Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter => 25,}// 上述代码中,每个分支相关联的代码是一个表达式// 而表达式的结果值将作为整个 match 表达式的返回值// 类似于代码块
}
fn main() {let a = Coin::Penny;let b = Coin::Nickel;let c = Coin::Dime;let d = Coin::Quarter;println!("{} {} {} {}", value_in_cents(a),value_in_cents(b),value_in_cents(c), value_in_cents(d),);
}
与 if 的区别:对于 if ,表达式必须返回一个布尔值,而match参数可以是任何类型
绑定值的模式
匹配分支的另一个有用的功能是可以绑定匹配的模式的部分值。这也就是如何从枚举成员中提取值的。
#[derive(Debug)] // 这样可以立刻看到州的名称
#[warn(non_camel_case_types)]
#[warn(dead_code)]
enum CNState {Sd,Hb,Sx,Hn
}enum Coin {Penny,Nickel,Dime,Quarter(CNState), // Quarter 成员也存放了一个 CNState 值的 Coin 枚举
}
fn value_in_cents(coin: Coin) -> u8 {match coin {Coin::Penny => 1,Coin::Nickel => 5,Coin::Dime => 10,Coin::Quarter(state) => { // state会绑定CNState的枚举println!("{:?}", state);25}}
}
fn main() {let a = Coin::Penny;let b = Coin::Nickel;let c = Coin::Dime;println!("{} {} {}", value_in_cents(a),value_in_cents(b),value_in_cents(c));let d1 = Coin::Quarter(CNState::Sd);let d2 = Coin::Quarter(CNState::Sx);let d3 = Coin::Quarter(CNState::Hb);let d4 = Coin::Quarter(CNState::Hn);println!("{} {} {} {}", value_in_cents(d1), value_in_cents(d2), value_in_cents(d3), value_in_cents(d4));// 如果调用 value_in_cents(d1)
// 当将值与每个分支相比较时,没有分支会匹配,直到遇到Coin::Quarter(state)
// 这时,state 绑定的将会是值 CNState::Sd
// 接着就可以在 println! 表达式中使用这个绑定了
// 像这样就可以获取 Coin 枚举的 Quarter 成员中内部的州的值
}
匹配 Option
fn plus_one(x: Option<i32>) -> Option<i32> {match x {None => None,Some(i) => Some(i + 1), // 如果传入的x是Some(5),那么i会绑定5}
}
fn main() {let five = Some(5);let _six = plus_one(five);let _none = plus_one(None);
}
通配模式和 _ 占位符
问题描述:如果你掷出骰子的值为 3,角色不会移动,而是会得到一顶新奇的帽子。如果你掷出了 7,你的角色将失去新奇的帽子。对于其他的数值,你的角会在棋盘上移动相应的格子。
fn main() {let dice_roll = 9;match dice_roll {3 => add_fancy_hat(),7 => remove_fancy_hat(),other => move_player(other), // 通配模式}fn add_fancy_hat() {}fn remove_fancy_hat() {}fn move_player(num_spaces: u8) {}
}
让我们改变游戏规则:如果你掷出 3 或 7 以外的值,你的回合将无事发生
fn main() {let dice_roll = 9;match dice_roll {3 => add_fancy_hat(),7 => remove_fancy_hat(),_ => (), // 通配模式}fn add_fancy_hat() {}fn remove_fancy_hat() {}
}
if let 简洁控制流
只匹配一个模式的值而忽略其他情况
fn main() {let _v = Some(4);if let Some(3) = _v {println!("3!!!");} else { // 可以配合elseprintln!("Other");}// if let _v = Some(3) { // 错误写法// println!("3!!!");// }
}
7.1Package, Crate, Module
到目前为止,我们编写的程序都在一个文件的一个模块中。伴随着项目的增长,你应该通过将代码分解为多个模块和多个文件来组织代码。一个包可以包含多个二进制 crate 项和一个可选的 crate 库。伴随着包的增长,你可以将包中的部分代码提取出来,做成独立的 crate,这些 crate 则作为外部依赖项。
模块系统(the modulesystem):
- 包(Packages):Cargo 的一个功能,它允许你构建、测试和分享 crate。
- Crates :一个模块的树形结构,它形成了库或二进制项目。
- 模块(Modules)和 use:允许你控制作用域和路径的私有性。
- 路径(path):一个命名例如结构体、函数或模块等项的方式
Package 和 Crate
crate 是 Rust 在编译时最小的代码单位。如果你用 rustc 而不是 cargo 来编译一个文件,编译器还是会将那个文件认作一个 crate。crate 可以包含模块,模块可以定义在其他文件,然后和 crate 一起编译
Crate 包含两种类型:
binary(二进制项),二进制项可以被编译为可执行程序,比如一个命令行程序或者一个服务器。它们必须有一个 main 函数来定义当程序被执行的时候所需要做的事情。目前我们所创建的 crate 都是二进制项。library(库),库并没有 main 函数,它们也不会编译为可执行程序,它们提供一些诸如函数之类的东西,使其他项目也能使用这些东西。比如 rand crate 就提供了生成随机数的东西。大多数时间 Rustaceans 说的 crate 指的都是库,这与其他编程语言中 library 概念一致。
Crate root 是一个源文件,Rust 编译器以它为起始点,并构成 crate 的根模块。
包(package)是提供一系列功能的一个或者多个 crate。一个包会包含一个 Cargo.toml 文
件,阐述如何去构建这些 crate。其中:至多包含一个 library crate,可以包含任意多的 binary crate,但必须至少包含一个 crate。
Cargo 的惯例
src/main.rs
- 作为 binary crate 的 crate root
- crate 名与 package 名相同
如果还存在文件src/lib.rs
- 这意味着 package 包含一个 library crate
- 作为 library crate 的 crate root
- crate 名与 package 名相同
Cargo 把 crate root 文件交给 rustc 来构建 library 或 binary
Crate 的作用
将相关功能组合到一个作用域内,便于在项目间进行共享 —> 防止冲突
例如 rand crate,访问它的功能需要通过它的名字:rand
定义模块(Module)来控制作用域与私有性
Module:
- 在一个 crate 内,对代码进行分组
- 增加可读性,易于复用
- 控制项目(item)的私有性,public,private
建立 module:
- mod 关键字
- 可嵌套
- 可包含其他项(struct、enum、常量、trait、函数等)的定义
7.2 路径,Path
为了在 rust 的模块中找到某个条目,需要使用路径。
路径的两种形式;
- 绝对路径:从 crate root 开始,使用 crate 名或字面值 crate
- 相对路径:从当前模块开始,使用 self,super 或当前模块的标识符
文件名:src/lib.rs
mod front_of_house {// hosting模块公有,但是 hosting 的 内容(contents)仍然是私有的// 这表明使模块公有并不会使其内容也变成公有// 私有性规则不但应用于模块,还应用于结构体、函数和方法pub mod hosting { pub fn add_to_waitlist() {}}
}
pub fn eat_at_restaurant() {// 绝对路径,方便定义条目的代码和使用条目的代码彼此独立的移动crate::front_of_house::hosting::add_to_waitlist();// 相对路径front_of_house::hosting::add_to_waitlist();
}
私有边界(privacy boundary)
- 模块不仅可以组织代码,还可以定义私有边界
- 如果想把 函数 或 struct 等设为私有,可以把它放到某个模块中
- rust 中的所有条目(函数,方法,struct,enum,模块,常量)默认是私有的。
- 父级模块无法访问子模块中的私有条目
- 子模块可以使用所有祖先模块中的条目
二进制和库 crate 包的最佳实践
我们提到过包可以同时包含一个 src/main.rs 二进制 crate 根和一个 src/lib.rs 库 crate 根,并且这两个 crate 默认以包名来命名。通常,这种包含二进制 crate 和库 crate 的模式的包,在二进制 crate 中只有足够的代码来启动一个可执行文件,可执行文件调用库 crate 的代码。又因为库 crate 可以共享,这使得其它项目从包提供的大部分功能中受益。
模块树应该定义在 src/lib.rs 中。这样通过以包名开头的路径,公有项就可以在二进制 crate 中使用。二进制 crate 就完全变成了同其它外部 crate 一样的库 crate 的用户:它只能使用公有 API。这有助于你设计一个好的 API;你不仅仅是作者,也是用户!
super,从父模块开始构建相对路径
使用 super 允许我们引用父模块中的已知项,这使得重新组织模块树变得更容易 —— 当模块与父模块关联的很紧密,但某天父模块可能要移动到模块树的其它位置。
创建公有的结构体和枚举
如果我们在一个结构体定义的前面使用了 pub ,这个结构体会变成公有的,但是这个结构体的字段仍然是私有的。我们可以根据情况决定每个字段是否公有。
将枚举类型设为公有后,枚举成员默认是公有的,这与rust的默认私有规则不同。
use
可以使用 use 关键字将路径导入到作用域内,但仍遵循私有性规则
我们将 crate::front_of_house::hosting 模块引入了 eat_at_restaurant 函数的作用域,而我们只需要指定 hosting::add_to_waitlist 即可在 eat_at_restaurant 中调用 add_to_waitlist 函数。
1.函数(指定到父级):当我们要使用其他模块函数的时候,一般使用 use 引入这个函数的父级模块
2.struct,enum,其他:指定完整路径(指定到本身)
mod front_of_house {pub mod hosting {pub fn add_to_waitlist() {}}
}use crate::front_of_house::hosting;pub fn eat_at_restaurant() {hosting::add_to_waitlist();
}
引入结构体
use std::collections::HashMap; // 指定到HashMap结构体本身fn main() {let mut map = HashMap::new(); // 直接使用HashMap即可map.insert(1, 2);
}
将两个具有相同名称但不同父模块的 Result 类型引入作用域
// 使用父模块可以区分这两个 Result 类型。
use std::fmt;
use std::io;
fn function1() -> fmt::Result {// --snip--Ok(())
}
fn function2() -> io::Result<()> {// --snip--Ok(())
}// 使用 as 关键字提供新的名称,进而区分两个result
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {// --snip--Ok(())
}
fn function2() -> IoResult<()> {// --snip--Ok(())
}
use 语句只适用于其所在的作用域,下面例子是无法编译的
/*
use 只能创建 use 所在的特定作用域内的短路径。
将 eat_at_restaurant 函数移动到了一个叫 customer 的子模块
这又是一个不同于 use 语句的作用域,所以函数体不能编译。
*/
mod front_of_house {pub mod hosting {pub fn add_to_waitlist() {}}
}use crate::front_of_house::hosting;mod customer {pub fn eat_at_restaurant() {hosting::add_to_waitlist();}
}
使用 pub use 重导出名称
使用 use 关键字,将某个名称导入当前作用域后,这个名称在此作用域中就可以使用了,但它对此作用域之外还是私有的。如果想让其他人调用我们的代码时,也能够正常使用这个名称,就好像它本来就在当前作用域一样,那我们可以将 pub 和 use 合起来使用。这种技术被称为 “重导出(re-exporting)”:我们不仅将一个名称导入了当前作用域,还允许别人把它导入他们自己的作用域。
mod front_of_house {pub mod hosting {pub fn add_to_waitlist() {}}
}pub use crate::front_of_house::hosting;pub fn eat_at_restaurant() {hosting::add_to_waitlist();
}
使用外部包
在 Cargo.toml 中加入 rand 依赖告诉了 Cargo 要从 crates.io 下载 rand 和其依赖,并使其可
在项目代码中使用。
rand = "0.8.5"
为了将 rand 定义引入项目包的作用域,我们加入一行 use 起始的包名,它以 rand 包名开头,并列出了需要引入作用域的项。
use rand::Rng;fn main() {let secret_number = rand::thread_rng().gen_range(1..=100);
}
注意 std 标准库对于你的包来说也是外部 crate。
use std::collections::HashMap;
这是一个以标准库 crate 名 std 开头的绝对路径。
嵌套路径来消除大量的 use 行
如果使用同一个包或模块下的多个条目,可以使用嵌套路径在同一行内将上述条目进行引入:
路径相同的部分 :: 路径差异的部分
use std::{cmp::Ordering, io};
// use std::io;
// use std::io::Write;
use std::io::{self, Write};
// 谨慎使用,一般用于测试,有时被用于预导入模块
use std::collections::*;
将模块拆分成多个文件
模块定义时,如果模块名后边是 `;`` ,而不是代码块,那么:
- Rust 会从与模块同名的文件中加载内容(同级文件夹中)
- 模块树的结构不会变化
路径的层级结构要和模块的层级结构相匹配