目录
1、迷宫(《信息学奥赛一本通》)
2、奶牛选美(USACO 2011 November Contest Bronze Division)
3、树的重心(模板)
4、大臣的旅费(第四届蓝桥杯省赛Java & C++ A组)
5、扫雷(第十三届蓝桥杯省赛C++ B组)
1、迷宫(《信息学奥赛一本通》)
一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由 n∗n的格点组成,每个格点只有2种状态,.和#,前者表示可以通行后者表示不能通行。
同时当Extense处在某个格点时,他只能移动到东南西北(或者说上下左右)四个方向之一的相邻格点上,Extense想要从点A走到点B,问在不走出迷宫的情况下能不能办到。
如果起点或者终点有一个不能通行(为#),则看成无法办到。
注意:A、B不一定是两个不同的点。
输入格式
第1行是测试数据的组数 k,后面跟着 k 组输入。
每组测试数据的第1行是一个正整数 n,表示迷宫的规模是 n∗n 的。
接下来是一个 n∗n 的矩阵,矩阵中的元素为.或者#。
再接下来一行是 4 个整数 ha,la,hb,lb描述 A处在第 ha 行, 第 la 列,B 处在第 hb 行, 第 lb 列。
注意到 ha,la,hb,lb全部是从 0 开始计数的。
输出格式
k行,每行输出对应一个输入。
能办到则输出“YES”,否则输出“NO”。
数据范围
1≤n≤100
输入样例:
2
3
.##
..#
#..
0 0 2 2
5
.....
###.#
..#..
###..
...#.
0 0 4 0
输出样例:
YES
NO思路:
经典的问题,选择用两个数组来枚举上、下、左、右四个情况
代码:
#include<bits/stdc++.h>using namespace std;int k,n;int dx[4]={0,0,1,-1};
int dy[4]={1,-1,0,0};const int N=103;char g[N][N];bool f; void dfs(int x1,int y1,int aimx,int aimy)
{if(x1==aimx && y1==aimy){//cout<<y1<<" "<<aimy<<endl;f=true;return ;}g[x1][y1]='#';for(int i=0;i<4;i++){int nx=dx[i]+x1;int ny=dy[i]+y1;if(nx>=1 && nx <= n && ny>=1 && ny<=n && g[nx][ny]=='.'){//cout<<nx<<" "<<ny<<endl;//cout<<g[nx][ny]<<endl;dfs(nx,ny,aimx,aimy);}}
} int main()
{cin>>k;while(k--){//cout<<"intput n";cin>>n;for(int i=1;i<=n;i++)for(int j=1;j<=n;j++){//cout<<"reading"<<endl;cin>>g[i][j]; } //cout<<g[1][4];//cout<<"yeah";int x1,y1,x2,y2;cin>>x1>>y1>>x2>>y2;x1++,y1++,x2++,y2++;//因为我的坐标是从1开始计的 f=false;//cout<<"readover";//cout<<x1<<" "<<y1<<endl;if(g[x1][y1]!='#')dfs(x1,y1,x2,y2);if(f)cout<<"YES"<<endl;else cout<<"NO"<<endl;}return 0;
}2、奶牛选美(USACO 2011 November Contest Bronze Division)
听说最近两斑点的奶牛最受欢迎,约翰立即购进了一批两斑点牛。
不幸的是,时尚潮流往往变化很快,当前最受欢迎的牛变成了一斑点牛。
约翰希望通过给每头奶牛涂色,使得它们身上的两个斑点能够合为一个斑点,让它们能够更加时尚。
牛皮可用一个 N×M 的字符矩阵来表示,如下所示:
................
..XXXX....XXX...
...XXXX....XX...
.XXXX......XXX..
........XXXXX...
.........XXX....
其中,X 表示斑点部分。
如果两个 X在垂直或水平方向上相邻(对角相邻不算在内),则它们属于同一个斑点,由此看出上图中恰好有两个斑点。
约翰牛群里所有的牛都有两个斑点。
约翰希望通过使用油漆给奶牛尽可能少的区域内涂色,将两个斑点合为一个。
在上面的例子中,他只需要给三个 .. 区域内涂色即可(新涂色区域用 ∗∗ 表示):
................
..XXXX....XXX...
...XXXX*...XX...
.XXXX..**..XXX..
........XXXXX...
.........XXX....
请帮助约翰确定,为了使两个斑点合为一个,他需要涂色区域的最少数量。
输入格式
第一行包含两个整数 N 和 M。
接下来 N 行,每行包含一个长度为 M 的由 X 和 .. 构成的字符串,用来表示描述牛皮图案的字符矩阵。
输出格式
输出需要涂色区域的最少数量。
数据范围
1≤N,M≤50
输入样例:
6 16
................
..XXXX....XXX...
...XXXX....XX...
.XXXX......XXX..
........XXXXX...
.........XXX....
输出样例:
3思路:
先把两个斑点区域包含的坐标通过深度优先搜索全部保存,然后对两块区域中的坐标进行枚举,用一个变量维护最小的横、纵坐标差之和,得到最小的涂色数量(res-1)
代码:
#include<bits/stdc++.h>using namespace std;const int N=53;char g[N][N];
int st[N][N];
int dx[4]={0,0,-1,1};
int dy[4]={1,-1,0,0};int n,m;
int cnt=0;
typedef pair<int,int> PII;vector<PII> area[2];#define x first
#define y second/* 6 16
................
..XXXX....XXX...
...XXXX....XX...
.XXXX......XXX..
........XXXXX...
.........XXX....
*///3//把每个x的位置记下来,然后进行计算
void dfs(int x,int y)
{st[x][y]=1;area[cnt].push_back({x,y});for(int i=0;i<4;i++){int nx=x+dx[i];int ny=y+dy[i];if(!st[nx][ny] && nx>=1 && nx <=n && ny>=1 && ny<=m && g[nx][ny]=='X'){dfs(nx,ny);}//cout<<"yes"; }
} int main()
{cin>>n>>m;//读入数据 for(int i=1;i<=n;i++)for(int j=1;j<=m;j++)cin>>g[i][j];//cout<<"res";for(int i=1;i<=n;i++)for(int j=1;j<=m;j++){if(!st[i][j] && g[i][j]=='X'){dfs(i,j);cnt++;}//cout<<g[i][j];}int res=3000;for(auto a : area[0])for(auto b :area[1]){//cout<<a.x<<" "<<b.x<<" "<<endl;//cout<<a.y<<" "<<b.y<<" "<<endl;res=min(res,abs(a.x-b.x)+abs(a.y-b.y));}cout<<res-1;return 0;
} 3、树的重心(模板)
给定一颗树,树中包含 n 个结点(编号 1∼n1)和 n−1 条无向边。
请你找到树的重心,并输出将重心删除后,剩余各个连通块中点数的最大值。
重心定义:重心是指树中的一个结点,如果将这个点删除后,剩余各个连通块中点数的最大值最小,那么这个节点被称为树的重心。
输入格式
第一行包含整数 n,表示树的结点数。
接下来 n−1 行,每行包含两个整数 a 和 b,表示点 a和点 b 之间存在一条边。
输出格式
输出一个整数 m,表示将重心删除后,剩余各个连通块中点数的最大值。
数据范围
1≤n≤1e5
输入样例
9
1 2
1 7
1 4
2 8
2 5
4 3
3 9
4 6
输出样例:
4思路:
递归搜索每一个连通块,找到重心并删除,再用ans在递归过程中维护剩余连通块最大点数值
代码:
#include<bits/stdc++.h>
/*
9
1 2
1 7
1 4
2 8
2 5
4 3
3 9
4 6
*/
using namespace std;const int N=1e5+3,M=2*N;bool st[N];
int h[N],e[M],ne[M],idx=0;int n;
int ans=N;//add里面a是头,b是插入元素
void add(int a,int b)
{e[idx]=b;ne[idx]=h[a];h[a]=idx++;
} int dfs(int u)
{st[u]=true;int sum=1;//当前已经有一个点u int res=0;for(int i=h[u];i!=-1;i=ne[i]){int j=e[i];if(!st[j]){int s=dfs(j);//以j为根节点的连通块的节点数量(包括j)res=max(res,s); sum+=s; } }res=max(res,n-sum);ans=min(ans,res);return sum;
} int main()
{cin>>n;memset(h,-1,sizeof h);for(int i=1;i<=n-1;i++){int a,b; cin>>a>>b;add(a,b);add(b,a);}dfs(1);cout<<ans;return 0;
} 4、大臣的旅费(第四届蓝桥杯省赛Java & C++ A组)
很久以前,T 王国空前繁荣。
为了更好地管理国家,王国修建了大量的快速路,用于连接首都和王国内的各大城市。
为节省经费,T 国的大臣们经过思考,制定了一套优秀的修建方案,使得任何一个大城市都能从首都直接或者通过其他大城市间接到达。
同时,如果不重复经过大城市,从首都到达每个大城市的方案都是唯一的。
J 是 T 国重要大臣,他巡查于各大城市之间,体察民情。
所以,从一个城市马不停蹄地到另一个城市成了 J 最常做的事情。
他有一个钱袋,用于存放往来城市间的路费。
聪明的 J发现,如果不在某个城市停下来修整,在连续行进过程中,他所花的路费与他已走过的距离有关。
具体来说,一段连续的旅途里,第 1 千米的花费为 11,第 2 千米的花费为 12,第 3 千米的花费为 13,…,第 x 千米的花费为 x+10。
也就是说,如果一段旅途的总长度为 1 千米,则刚好需要花费 11,如果一段旅途的总长度为 2 千米,则第 1 千米花费 11,第 2 千米花费 12,一共需要花费 11+12=23。
J大臣想知道:他从某一个城市出发,中间不休息,到达另一个城市,所有可能花费的路费中最多是多少呢?
输入格式
输入的第一行包含一个整数 n,表示包括首都在内的 T 王国的城市数。
城市从 1 开始依次编号,1 号城市为首都。
接下来 n−1 行,描述 T 国的高速路(T 国的高速路一定是 n−1 条)。
每行三个整数 Pi,Qi,Di表示城市 Pi和城市 Qi 之间有一条双向高速路,长度为 Di千米。
输出格式
输出一个整数,表示大臣 J最多花费的路费是多少。
数据范围
1≤n≤1e5
1≤Pi,Qi≤n
1≤Di≤1000
输入样例:
5
1 2 2
1 3 1
2 4 5
2 5 4
输出样例:
135思路:
其实就是求树的直径,具体的做法如下:
1、随意选一个点x,开始搜索,找到离着当前节点最远的节点y
2、从上一轮搜索到的最远节点y,再次搜索一遍,找到离这个节点最远的节点z
3、y到z的路径就是树的直径
代码:
//----------------------------------------------------------------------------------------//从首都到达每个大城市的方案都是唯一的,所以这是一颗树
//求这棵树的直径()/*----------------------------------------------------------------------------------------树的直径的定义在一棵树中,每一条边都有权值,树中的两个点之间的距离,定义为连接两点的路径上边权之和,
那么树上最远的两个点,他们之间的距离,就被称之为,树的直径。
树的直径的别称,树的最长链。
请注意:树的直径,还可以认为是一条路径,不一定是只是一个数值。*///--------------------------------------------------------------------------------------//二次dfs求数的直径//1、随意选一个点x,开始搜索,找到离着当前节点最远的节点y
//2、从上一轮搜索到的最远节点y,再次搜索一遍,找到离这个节点最远的节点z
//3、y到z的路径就是树的直径 //----------------------------------------------------------------------------------------
/*
5
1 2 2
1 3 1
2 4 5
2 5 4
*/
#include<bits/stdc++.h>using namespace std;const int N=1e5+3;int h[2*N],e[2*N],w[2*N],ne[2*N],idx=0;int n;int maxd=-1,maxu;void add(int a,int b,int c)
{e[idx]=b;w[idx]=c;ne[idx]=h[a];h[a]=idx++;
}void dfs(int son,int father,int d)
{//cout<<"yes";//cout<<a<<" "<<h[a]<<endl;for(int i=h[son];i!=-1;i=ne[i]){//cout<<"yes";int j=e[i];//j是son的子节点 int k=w[i];if(j==father)continue;//避免回头访问,确保每个节点只被访问一次 if(maxd<k+d){//cout<<"yes";maxd=k+d;maxu=j;}dfs(j,son,d+k);}
}int main()
{memset(h,-1,sizeof h);cin>>n;for(int i=1;i<=n-1;i++){int a,b,c;scanf("%d%d%d",&a,&b,&c);//边权为c,由于是无向图,加两次 add(a,b,c);add(b,a,c);}dfs(1,-1,0);//到-1就是遍历所有,得出距离最远的的点和最大的距离 dfs(maxu,-1,0);//寻找maxu的最远的点和最大的距离long long sum=(long long)(11+maxd+10)*(maxd)/2;cout<<sum;return 0;
}5、扫雷(第十三届蓝桥杯省赛C++ B组)
小明最近迷上了一款名为《扫雷》的游戏。
其中有一个关卡的任务如下:
在一个二维平面上放置着 n 个炸雷,第 i 个炸雷 (xi,yi,ri)表示在坐标 (xi,yi) 处存在一个炸雷,它的爆炸范围是以半径为 ri 的一个圆。
为了顺利通过这片土地,需要玩家进行排雷。
玩家可以发射 m 个排雷火箭,小明已经规划好了每个排雷火箭的发射方向,第 j 个排雷火箭 (xj,yj,rj)表示这个排雷火箭将会在 (xj,yj)处爆炸,它的爆炸范围是以半径为 rj 的一个圆,在其爆炸范围内的炸雷会被引爆。
同时,当炸雷被引爆时,在其爆炸范围内的炸雷也会被引爆。
现在小明想知道他这次共引爆了几颗炸雷?
你可以把炸雷和排雷火箭都视为平面上的一个点。
一个点处可以存在多个炸雷和排雷火箭。
当炸雷位于爆炸范围的边界上时也会被引爆。
输入格式
输入的第一行包含两个整数 n、m。
接下来的 n 行,每行三个整数 xi,yi,ri表示一个炸雷的信息。
再接下来的 m 行,每行三个整数 xj,yj,rj,表示一个排雷火箭的信息。
输出格式
输出一个整数表示答案。
数据范围
对于 40% 的评测用例:0≤x,y≤1e9,0≤n,m≤1e3,1≤r≤10
对于 100% 的评测用例:0≤x,y≤1e9,0≤n,m≤5×1e4,1≤r≤10
输入样例:
2 1
2 2 4
4 4 2
0 0 5
输出样例:
2
样例解释
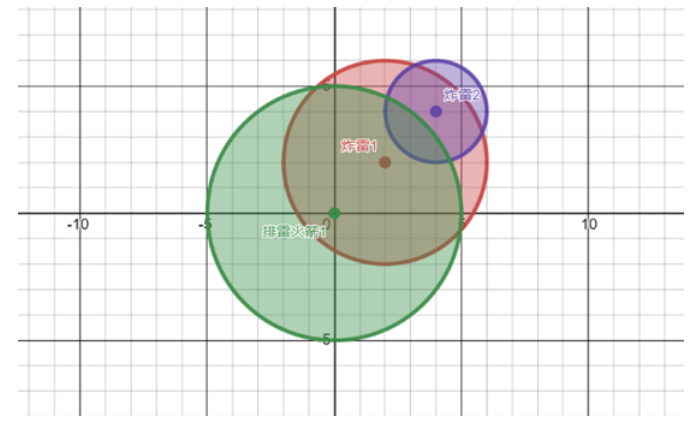
示例图如下,排雷火箭 1 覆盖了炸雷 1,所以炸雷 1 被排除;炸雷 1 又覆盖了炸雷 2,所以炸雷 2 也被排除。
思路:
用unordered_map会超时,我们选择手写散列表(速度更快)
开两个哈希表来维护某个位置的信息(地雷数量和最大爆炸半径),每个坐标赋予一个对应的id(key)用来访问地雷信息
为了正确的分配key,我们再开一个哈希表维护key
代码:
#include<bits/stdc++.h>using namespace std;typedef long long LL;const int X=1e9+1;int n,m,res=0;const int MAXMAX=-1;const int N=999997,M=999997;LL h[N];//哈希数组int hn[N],hr[N];//炸弹数量和最大半径int st[N];LL get_hash_number(int x,int y)
{return (LL)x*X + y;
} int find(int x,int y)
{LL t=get_hash_number(x,y);int key=(t%M+M)%M;//cout<<key;while(h[key]!=MAXMAX && h[key]!=t){key++;if(key==M)key=0;}//cout<<key<<endl;return key;
}bool check(int x,int y,int x1,int y1,int r)
{int d=(x-x1)*(x-x1)+(y-y1)*(y-y1);return d<=r*r;
}void dfs(int x,int y,int r)
{for(int i=-r;i<=r;i++)for(int j=-r;j<=r;j++){int nx=x+i;int ny=y+j;int t=find(nx,ny);//if(nx==4 && ny==4)cout<<hn[find(4,4)]<<endl;//cout<<t;//cout<<nx<<" "<<ny<<endl;if(!st[t] && hn[t] && check(x,y,nx,ny,r)){//cout<<"yes";//cout<<t;st[t]=1; res+=hn[t];int nr=hr[t];//cout<<hr[t];//cout<<nx<<" "<<ny;//cout<<hn[find(nx,ny)];//cout<<"dfs"<<endl;dfs(nx,ny,nr);// 2 2 4---->4 4 2}}}int main()
{memset(h,-1,sizeof h);cin>>n>>m;for(int i=0;i<n;i++){int x,y,r;scanf("%d%d%d",&x,&y,&r);int key=find(x,y);LL t=get_hash_number(x,y);h[key]=t;//维护哈希表 hn[key]++;hr[key]=max(hr[key],r);}for(int i=0;i<m;i++){int xx,yy,rr;scanf("%d%d%d",&xx,&yy,&rr);dfs(xx,yy,rr);}cout<<res<<endl;//cout<<hn[find(4,4)]<<endl;//cout<<hn[find(2,2)]<<endl;return 0;
}/*
2 1
2 2 4
4 4 2
0 0 52
*/补充:
这一部分可以写一个insert函数替代,更加简洁
int key=find(x,y);LL t=get_hash_number(x,y);h[key]=t;//维护哈希表insert函数:
void insert(int x,int y)
{int key=find(x,y);h[key]=get_hash_number(x,y);;
}修改后的代码:
#include<bits/stdc++.h>using namespace std;typedef long long LL;const int X=1e9+1;int n,m,res=0;const int MAXMAX=-1;const int N=999997,M=999997;LL h[N];//哈希数组int hn[N],hr[N];//炸弹数量和最大半径int st[N];LL get_hash_number(int x,int y)
{return (LL)x*X + y;
} int find(int x,int y)
{LL t=get_hash_number(x,y);int key=(t%M+M)%M;//cout<<key;while(h[key]!=MAXMAX && h[key]!=t){key++;if(key==M)key=0;}//cout<<key<<endl;return key;
}bool check(int x,int y,int x1,int y1,int r)
{int d=(x-x1)*(x-x1)+(y-y1)*(y-y1);return d<=r*r;
}void insert(int x,int y)
{int key=find(x,y);h[key]=get_hash_number(x,y);;
}void dfs(int x,int y,int r)
{for(int i=-r;i<=r;i++)for(int j=-r;j<=r;j++){int nx=x+i;int ny=y+j;int t=find(nx,ny);//if(nx==4 && ny==4)cout<<hn[find(4,4)]<<endl;//cout<<t;//cout<<nx<<" "<<ny<<endl;if(!st[t] && hn[t] && check(x,y,nx,ny,r)){//cout<<"yes";//cout<<t;st[t]=1; res+=hn[t];int nr=hr[t];//cout<<hr[t];//cout<<nx<<" "<<ny;//cout<<hn[find(nx,ny)];//cout<<"dfs"<<endl;dfs(nx,ny,nr);// 2 2 4---->4 4 2}}}int main()
{memset(h,-1,sizeof h);cin>>n>>m;for(int i=0;i<n;i++){int x,y,r;scanf("%d%d%d",&x,&y,&r);insert(x,y);int key=find(x,y);hn[key]++;hr[key]=max(hr[key],r);}for(int i=0;i<m;i++){int xx,yy,rr;scanf("%d%d%d",&xx,&yy,&rr);dfs(xx,yy,rr);}cout<<res<<endl;//cout<<hn[find(4,4)]<<endl;//cout<<hn[find(2,2)]<<endl;return 0;
}/*
2 1
2 2 4
4 4 2
0 0 52
*/