文章信息
论文题目:Zero-delay Lightweight Defenses against Website Fingerprinting
期刊(会议): 29th USENIX Security Symposium
时间:2020
级别:CCF A
文章链接:https://www.usenix.org/system/files/sec20-gong.pdf
概述
在强调低成本、实用性和易用性的同时,本文设计了两种新的防御方法,可以击败最优秀的网站指纹(Website Fingerprinting, WF)攻击:FRONT和GLUE。我们称它们为零延迟轻量级防御系统,这意味着它们不会延迟客户端的数据包,而且只在真实流量中添加少量虚假数据包。
- FRONT可混淆特征丰富的网络跟踪的前端部分,这对攻击者的成功至关重要。它使用随机数量的虚假数据包,破坏攻击者的训练过程。
- GLUE在网络跟踪之间添加了虚假数据包,使客户端看起来好像在连续访问网页,没有停顿。这就迫使攻击者解决困难的拆分问题,而之前的研究发现,即使是最好的攻击也做不到这一点 。
相关工作
网站指纹攻击
我们挑选了四种最新的最佳攻击进行评估,所有这些攻击在开放世界场景中都非常有效:
- kNN:这种攻击由Wang等人于2014年提出,使用基于自动学习不同特征权重的k近邻分类器。它旨在破解WF防御,因为它会通过降低不良特征的权重来适应防御性特征扰乱。
- CUMUL:Panchenko等人于2016年提出了这种利用轨迹“累积表示”的SVM分类器。它比kNN更准确,而且计算时间极短。
- kFP:2016年,Hayes和Danezis提出了这种联合使用随机森林和k近邻的攻击方法。它在开放世界场景中具有很高的精度。
- DF:DF是一种使用深度卷积神经网络的最新攻击。它的表现优于其他深度学习攻击,实现了高精度和高召回率。它是第一个被证明能有效对抗WTF-PAD的攻击,WTF-PAD是一种轻量级WF防御。
网站指纹防御
为了抵御本地的被动WF攻击者,可以在匿名网络上部署WF防御措施,修改客户端与网络代理对话的方式。这通常是通过添加虚假数据包或根据某种策略延迟真实数据包来实现的;攻击者无法区分虚假数据包和真实数据包。无需修改网络服务器。多年来,研究人员提出了许多防御措施,以保护对隐私敏感的客户端免受WF攻击。我们将他们用来抵御WF攻击的策略大致分为三类:混淆特征、混淆流量和正则化。
- 混淆特征旨在混淆WF攻击所依赖的特定特征。许多早期的防御方法都会混淆数据包长度,以击败较早的WF攻击。
- 混淆流量旨在让攻击者难以确定加载的是某一组给定跟踪中的哪一个。
- 正则化防御限制客户端发送和接收数据包的方式,以严格限制攻击者可用的特征空间。其中一些防御措施对客户端执行固定的数据包速率,并规定序列结束时间。
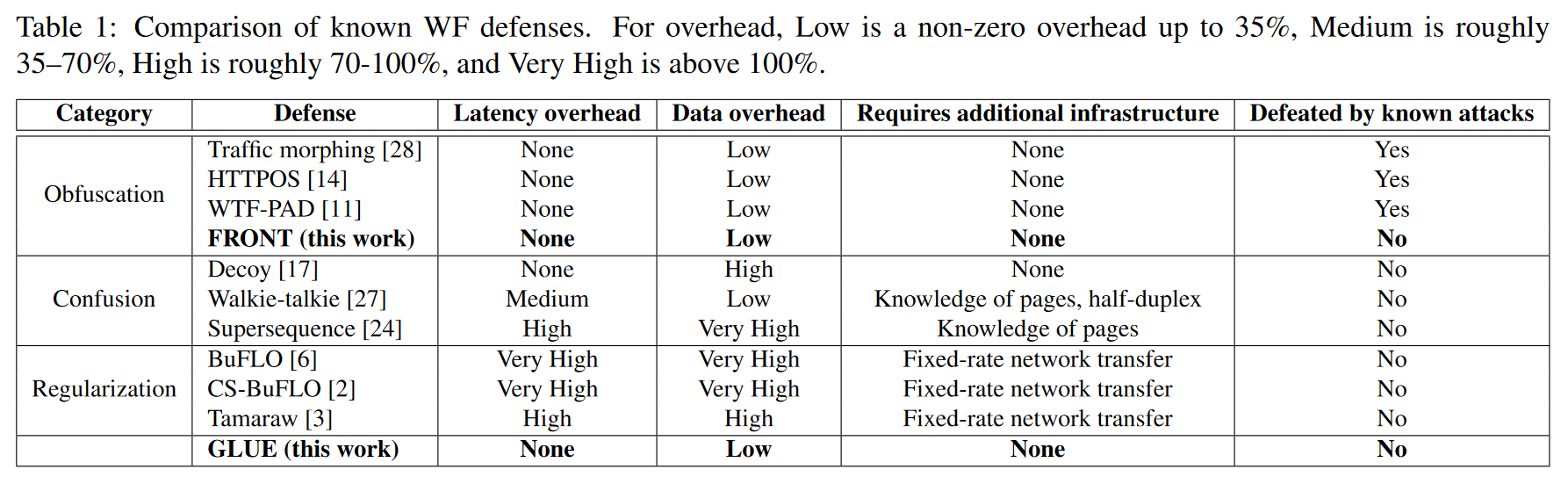
在调查中本文发现,现有的防御措施要么具有较大的数据开销,要么会对用户流量造成较大的延迟。这些因素阻碍了所有这些防御措施的采用;Tor开发人员不希望损害其匿名网络的用户体验。因此,为了创建零延迟的轻量级防御,我们决定避免混淆和正则化防御。在我们的新防御措施中,FRONT是一种混淆防御措施,而GLUE 则自成一类,因为它迫使WF攻击者解决一个不同的、更困难的问题。
准备工作
威胁模型
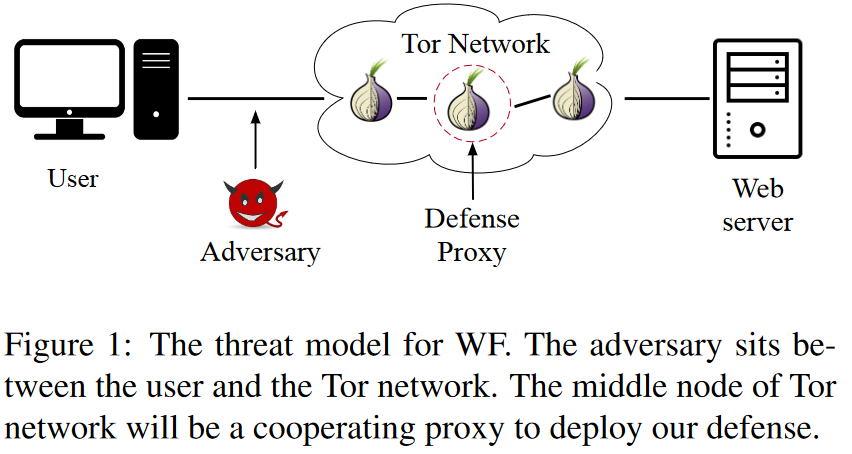
我们考虑的是用户本地的被动对手。图1展示了攻击模型。对手位于用户和Tor网络入口节点之间,通过加密信道窃听网络通信。对手不会延迟、修改或丢弃任何数据包。
分类
从攻击者的角度来看,WF可被视为一个分类问题。在网页加载过程中,WF攻击者会记录网络流量跟踪(也称为数据包序列)。攻击者事先访问一定数量的受监控网页,并在这些痕迹上训练机器学习模型。每个网页都是一个类,属于该类的特定轨迹称为一个实例。然后,在观察客户端的跟踪时,攻击者根据训练好的模型预测跟踪属于哪个网页。
WF攻击可在封闭世界或开放世界场景下进行评估。在封闭世界场景中,我们假设用户只访问一组特定的网页,也称为受监控网页。在开放世界场景中,客户端也可以访问非监控网页,因此攻击者必须预测某个跟踪是监控网页还是非监控网页。如果是受监控的,攻击者必须进一步回答是哪一个。攻击者从不在客户端访问的同一网页上进行训练;因此,攻击者对客户端行为的事先了解为零。我们将重点放在更为现实的开放世界场景上。
精确度
阳性(positive):如果WF攻击者将跟踪归类为属于受监控网页,则为阳性(positive)。如果分类正确,则为真阳性(true positive)。如果分类不正确,序列实际上属于另一个受监控网页,则为错误阳性(wrong positive)。如果分类不正确,序列实际上属于非监控网页,则为假阳性(false positive)。
在实验中,让 N P N_{P} NP和 N N N_{N} NN分别表示阳性和阴性的数量。让TPR和WPR分别表示真阳性和错误阳性占 N P N_{P} NP的比例。让FPR表示假阳性与 N N N_{N} NN的比例。那么精确度为
π = T P R T P R + W P R + r ⋅ F P R \pi=\frac{TPR}{TPR+WPR+r\cdot FPR} π=TPR+WPR+r⋅FPRTPR
其中,r是客户访问非监控网页的频率与客户访问监控网页的频率之间的比率。r越大,精确度越低,开放世界分类问题也就越难;以前的攻击显示,针对 r = 1000 r=1000 r=1000的客户端的攻击取得了成功。我们希望证明,即使对于频繁访问受监控网页的低r客户端,我们的防御也是有效的。因此,在本文中,我们将设置 r = 10 r=10 r=10,代表客户端每访问十个非监控网页访问一个监控网页。此后,我们将评估此类客户端的精度。
开销
跟踪(trace):跟踪是在页面加载过程中收集的数据包序列,表示为 P = ⟨ ( t 1 , L 1 ) , ( t 2 , L 2 ) , ⋯ , ( t ∣ P ∣ , L ∣ P ∣ ) ⟩ P=\left \langle (t_1,L_1),(t_2,L_2),\cdots,(t_{\left | P \right | },L_{\left | P \right | }) \right \rangle P=⟨(t1,L1),(t2,L2),⋯,(t∣P∣,L∣P∣)⟩,其中 ∣ P ∣ \left | P \right | ∣P∣是跟踪中cell的总数。 t i t_i ti是第i个数据包的时间戳, L i L_i Li表示第i个数据包的方向和长度。Tor使用自己的数据报,这些数据报被称为 “cell”,所有cell都被填充为相同长度。由于Tor单元的长度相同,我们只需使用 L i = + 1 L_i=+1 Li=+1表示来自客户端的cell,-1表示来自服务器的cell。
l-跟踪:l-跟踪由对 ℓ \ell ℓ个网页的连续访问所产生的跟踪组成,记为 P = P 1 ∥ P 2 ∥ ⋯ ∥ P ℓ P=P_1\parallel P_2 \parallel \cdots \parallel P_\ell P=P1∥P2∥⋯∥Pℓ。
让P表示原始跟踪,P′表示实施某种防御D后的跟踪。我们对该跟踪的延迟和数据开销定义如下,它们是实施防御D的成本:
延迟开销:防御 D 在 P 上的延迟开销 T (D) 是传输真实数据包所需的额外时间除以原始传输时间。将发送完 P′ 中的最后一个真实数据包所用的时间表示为 t k t_k tk,则有 T ( D ) = t k − t ∣ P ∣ t ∣ P ∣ T(D)=\frac{t_k-t_{|P|}}{t_{|P|}} T(D)=t∣P∣tk−t∣P∣。
数据开销:防御 D 在 P 上的数据开销 O(D) 是假数据总量除以真实数据总量: O ( D ) = ∣ P ′ ∣ − ∣ P ∣ ∣ P ∣ O(D)=\frac{|P^{\prime}|-|P|}{|P|} O(D)=∣P∣∣P′∣−∣P∣。
请注意,延迟开销不包括整个跟踪 P′,只包括直到最后一个真实数据包的序列。这是因为在接收到最后一个真实数据包时,客户端的页面已经完全加载;在此之后发送或接收的额外虚假数据包不会影响客户端的体验。我们的防御系统FRONT和 GLUE的延迟开销为零(零延迟),数据开销很小(轻量级)。
FRONT
概述
混淆特征丰富的跟踪前沿:每次跟踪的前几秒(我们称之为跟踪前沿)都会泄露对WF分类最有用的特征。一些最佳攻击明确使用前沿跟踪进行分类。我们将大部分数据预算用于混淆跟踪前沿,而不是将它们平均分配到跟踪中。
跟踪间随机性(Trace-to-trace randomness):FRONT 以高度随机的方式添加虚假数据包,确保同一网页的不同跟踪在总长度、数据包排序和数据包方向上彼此不同。为此,FRONT 随机化了数据预算和注入假数据包的区域。由于我们必须允许攻击者在防御跟踪而非原始跟踪上进行训练,因此跟踪间的随机性会损害攻击者为网页类别找到任何有意义模式的能力。大多数正则化防御措施都存在跟踪间一致性的问题。
防御设计
使用 FRONT 对跟踪进行防御有三个步骤:采样虚假数据包数量、采样填充窗口大小和安排虚假数据包。表 2 汇总了 FRONT 的参数。
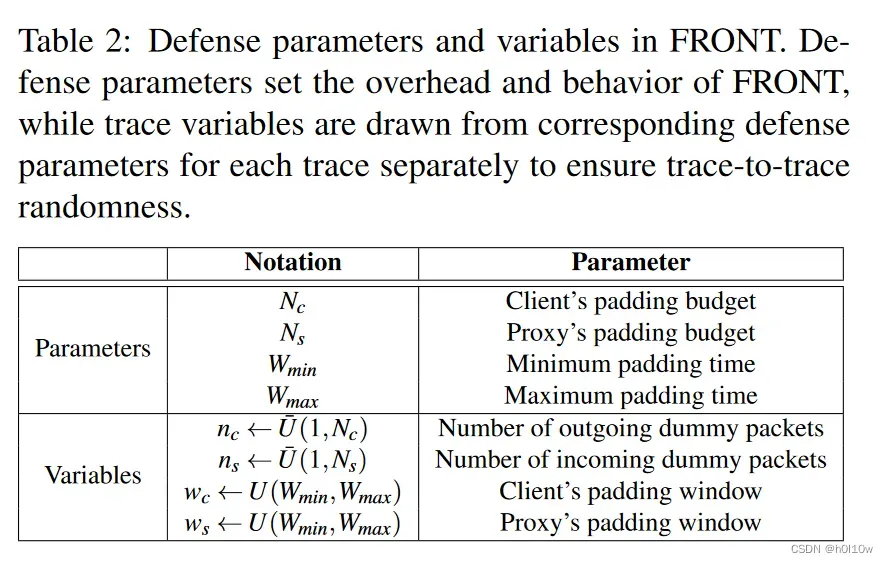
采样虚假数据包数量: N c N_c Nc和 N s N_s Ns是决定 FRONT 数据开销的两个参数,分别代表客户端的填充预算和代理的填充预算。对于每个跟踪,客户端从1和 N c N_c Nc之间的离散均匀分布中采样以获得 n c n_c nc,记为 U ˉ ( 1 , N c ) \bar{U}(1,N_{c}) Uˉ(1,Nc);代理从 U ˉ ( 1 , N s ) \bar{U}(1,N_{s}) Uˉ(1,Ns)中抽取 n s n_s ns。 n c n_c nc和 n s n_s ns是它们将注入跟踪的假数据包的实际数量。
采样填充窗口大小:FRONT 将其大部分预算用于混淆跟踪前沿。为此,客户端和代理服务器都将首先生成一个填充窗口,以控制将大部分虚假数据包注入原始轨迹的位置。对于每个跟踪,客户端从 W m i n W_{min} Wmin和 W m a x W_{max} Wmax之间的均匀分布中采样 w c w_c wc,记为 U ( W m i n , W m a x ) U(W_{min},W_{max}) U(Wmin,Wmax);代理从相同的分布中采样 w s w_s ws。我们之所以设置下限 W m i n W_{min} Wmin而不是0,是为了确保生成的填充窗口大小不会太小;如果太小,防御可能需要极高的带宽速率来支持。
安排虚假数据包:对上述变量进行采样后,客户端和代理分别生成时间表,安排各自的 n c n_c nc和 n s n_s ns个虚拟数据包的发送时间。它们通过从瑞利分布(Rayleigh Distribution)中采样 n c n_c nc和 n s n_s ns次来生成时间戳。其概率密度函数为
f ( t ; w ) = { t w 2 e − t 2 / 2 w 2 t ≥ 0 0 t < 0 f(t;w)=\begin{cases}\frac t{w^2}e^{-t^2/2w^2}&t\geq0\\0&t<0&\end{cases} f(t;w)={w2te−t2/2w20t≥0t<0
其中,对客户端来说 w w w是 w c w_c wc,对代理来说w是 w s w_s ws。发送真数据包时没有延迟,假数据包将根据时间表发送。当网页加载结束时,客户端会向中继器发送一个数据包,而时间表上任何未发送的数据包都会被丢弃。
防御分析
FRONT 采用的是瑞利分布(Rayleigh Distribution)。相应的概率密度函数 f ( t ; w ) f(t;w) f(t;w)如图 2 所示。
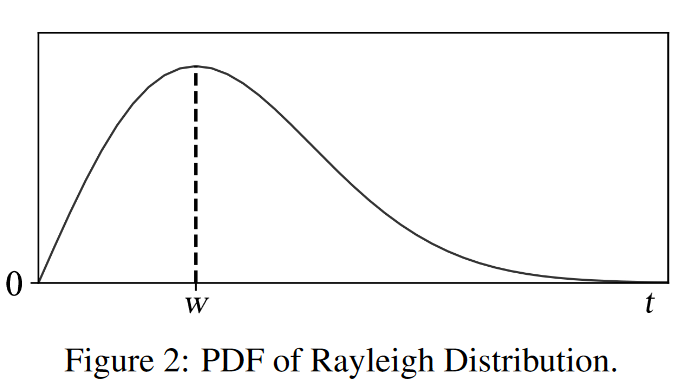
曲线首先快速上升,在 w 处达到峰值,然后逐渐下降。这与我们的第一种直觉相吻合,即在跟踪开始时会出现突发的假数据包。虽然假数据包窗口的标称长度为 w,但该窗口是 "软 "窗口;我们预计 40% 的假数据包位于时间区间 [ 0 , w ] [0, w] [0,w]: ∫ 0 w t w 2 e − t 2 / 2 w 2 d t ≈ 0.40 \int_0^w\frac t{w^2}e^{-t^2/2w^2}\mathrm{d}t\approx0.40 ∫0ww2te−t2/2w2dt≈0.40。
我们对虚假数据包的数量和填充窗口的大小进行采样,以便每次加载网页(即使是同一个网页)时,它们都是不同的。这就消除了攻击者可能利用的模式,正如我们的第二种直觉所建议的那样。
实验评估
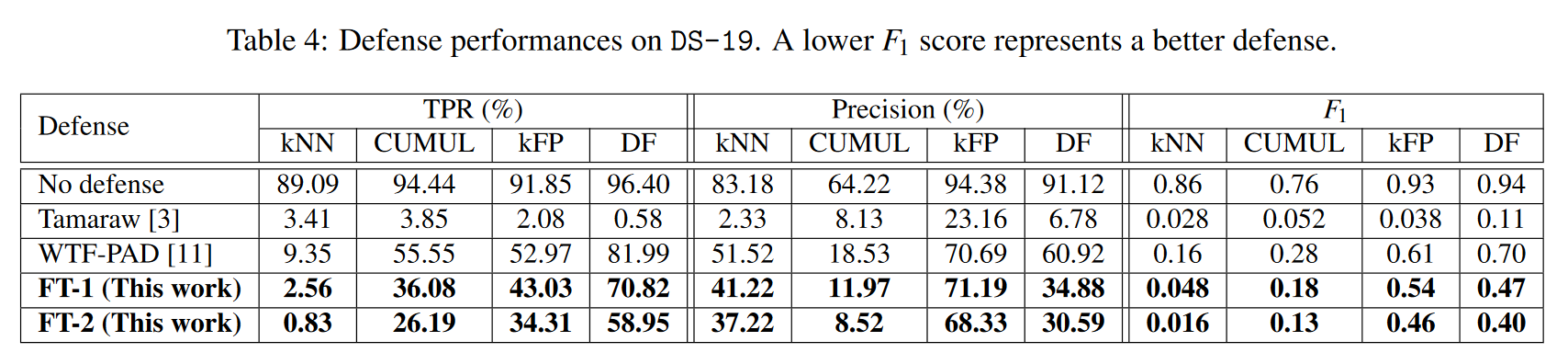
实验评估列举分析了很多,简单起见这里只放一个表
GLUE
概述
近年来发布了许多 WF 攻击,所有这些攻击都依赖于相同的假设:攻击者要分类的每个跟踪都与一个网页完全对应。我们称这些跟踪为单一跟踪。如果客户端在访问下一页之前在网页上停留了一段时间,攻击者就会注意到明显的时间差,并在此时分割跟踪。即使是一秒钟的闲置时间也足够了。相反,当客户连续访问 ℓ ≥ 2 \ell \ge 2 ℓ≥2个页面而没有明显的时间间隔时(例如,在当前页面完全加载之前点击下一页面链接),所有已知的WF攻击都无法成功地对由此产生的 "跟踪"进行分类,即使它们经过适当的训练并意识到这种可能性。
由于已知的WF攻击只能对单一跟踪( ℓ = 1 \ell=1 ℓ=1)进行分类,因此攻击者必须解决两个难题,才能正确地对 ℓ ≥ 2 \ell \ge 2 ℓ≥2的l-跟踪进行分类。首先,攻击者必须正确确定 ℓ \ell ℓ;我们称之为分割决策问题。其次,攻击者必须找到 ℓ − 1 \ell-1 ℓ−1个点,将l-跟踪分割成 ℓ \ell ℓ个独立的单一跟踪;我们称之为分割查找问题。然后,分类器可以将这些单一跟踪输入到强大的WF攻击中。有一些研究表明,后一个问题可以在 ℓ = 2 \ell=2 ℓ=2的情况下解决,但总体上还没有已知的解决方案;而前一个问题则从未解决过。
我们利用解决这些问题的难度,创建了一种新的防御方法——GLUE。每当客户端停留在一个网页上时,GLUE 就会添加假数据包,使客户端看起来好像在连续访问新页面。当客户端加载新页面时,GLUE 会停止发送虚假数据包,从而隐藏下一个页面的真正开始。换句话说,GLUE 试图将单一跟踪粘合成 ℓ \ell ℓ很大的 ℓ \ell ℓ-跟踪。由于无法解决分割决策或查找问题,如果错误地拆分跟踪,攻击很可能会失败。如果产生的单一跟踪在跟踪前端有额外的数据包(这对正确分类至关重要),情况就更是如此。
防御设计
假设一个客户端在一段时间内访问了 ℓ \ell ℓ个网页,然后停止了访问。GLUE 试图确保攻击者能看到看似连续的l-跟踪 P = P 1 ∥ P 2 ∥ ⋯ ∥ P ℓ P=P_1\parallel P_2 \parallel \cdots \parallel P_\ell P=P1∥P2∥⋯∥Pℓ。如果没有 GLUE,它们之间可能会有停留时间间隙,从而使攻击者可以轻而易举地分割它们。
用 d i d_i di表示在 P i P_i Pi上的停留时间。GLUE填充的最长时间为 d m a x d_{max} dmax。为了让GLUE 创建一条l-跟踪,我们假设对于 i = 1 , 2 , ⋯ , ℓ − 1 i=1,2,\cdots,\ell-1 i=1,2,⋯,ℓ−1, d i ≤ d m a x d_i \le d_{max} di≤dmax,且 d ℓ > d m a x d_{\ell}>d_{max} dℓ>dmax。当客户端停留在网页上时,客户端和代理将互相发送虚假数据包。图 8 给出了客户端的状态机,代理的状态机与之类似。GLUE还使用FRONT噪声来保护l-跟踪的第一部分。
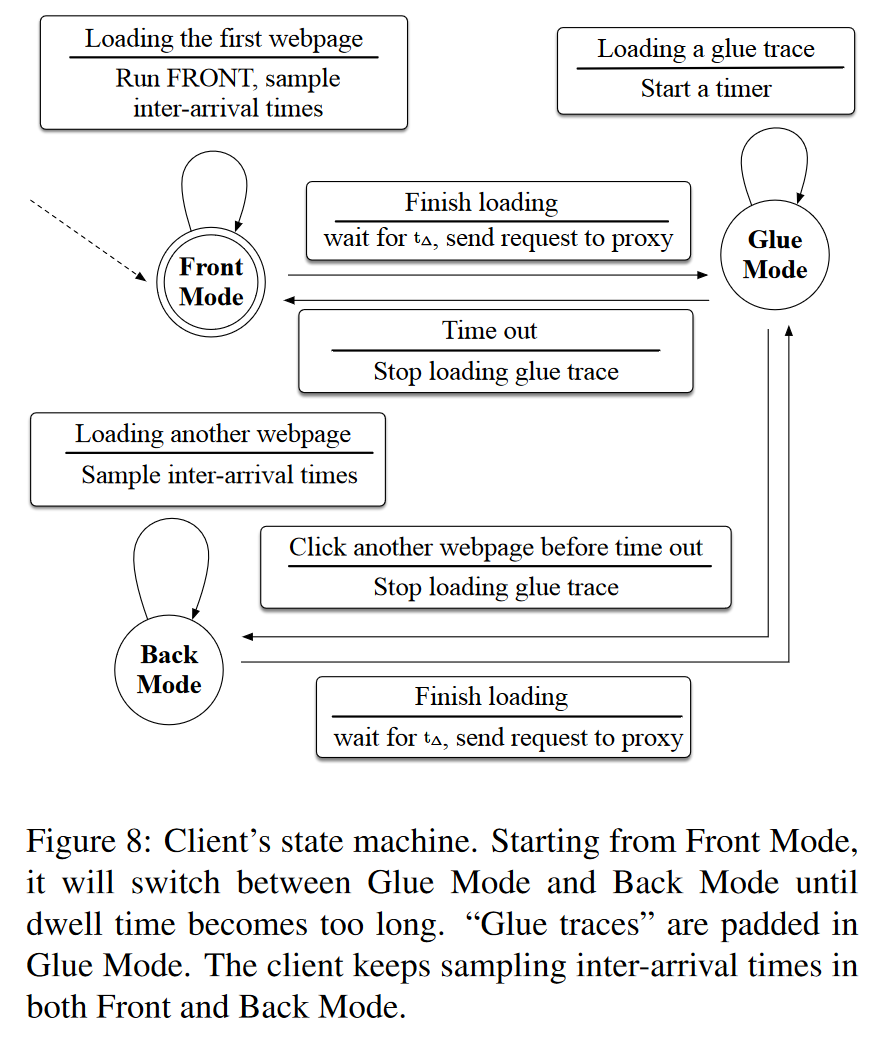
Front模式:从Front模式开始,我们的防御系统会等待客户端访问网页。当客户端访问网页时,我们将按照前几节所述的FRONT防御方法添加假数据包。我们还将对接收到的数据包和发出的数据包之间的到达时间进行采样,以获得某种分布 I。客户端访问完网页后,我们根据 I(如下所述)对 t Δ t_\Delta tΔ进行采样,等待 t Δ t_\Delta tΔ时间后,然后切换到Glue模式。
Glue模式:在Glue模式下,客户端和代理相互发送虚假数据包,看起来就像客户端决定访问一个新的、随机的网页。(客户端后面的人实际上还停留在之前的网页上)他们这样做的时间最多为 d m a x d_{max} dmax。如果客户端在超过 d m a x d_{max} dmax之前实际决定访问另一个网页,他们会立即停止发送假数据包:客户端将通知代理也终止Glue模式。如果客户端在网页上停留的时间超过 d m a x d_{max} dmax,算法将认为客户端处于非活动状态,并返回Front模式。否则,它将进入Back模式。我们把这里添加的虚包称为“glue跟踪”。
Back模式:在Back模式下,客户端正在访问另一个网页。这与Front模式类似,只是我们添加了零个假数据包。我们仍会对数据包到达间隔时间进行采样,并在等待 t Δ t_\Delta tΔ之后切换回Glue模式。
GLUE 在Front模式中加入了FRONT,确保任何l-跟踪的第一条跟踪都将使用 FRONT填充。这是因为我们发现,GLUE本身并不能很好地保护第一条跟踪,但却能很好地保护所有其他跟踪。我们需要增加一些开销来保护第一条跟踪。
在上文中,I 是到达时间间隔的分布,只包含接收和发出数据包之间的时间间隔。 t Δ t_\Delta tΔ是采样的到达间隔时间。我们选择 t Δ ∈ U ( I 20 ˉ , I 80 ˉ ) t_\Delta\in U(I_{\bar{20}},I_{\bar{80}}) tΔ∈U(I20ˉ,I80ˉ),其中 I 20 ˉ I_{\bar{20}} I20ˉ和 I 80 ˉ I_{\bar{80}} I80ˉ分别是到达时间分布 I 的 20 分位数和 80 分位数。我们故意制造这么小的间隙,是为了模拟在网页加载过程中,客户端从服务器接收数据后发出请求的时间间隔。通过这种方法,我们将真实跟踪与glue跟踪自然地连接在一起,中间没有任何异常间隙。我们还通过从均匀分布中采样来随机化 d m a x d_{max} dmax,这样攻击者就无法轻易消除尾部的噪声。
我们用图 9 来说明 GLUE 的工作原理。假设一个客户端访问了三个网页,其真实跟踪分别为 P 1 P_1 P1、 P 2 P_2 P2和 P 3 P_3 P3,然后停止访问,前两个网页之后的时间间隔分别为 d 1 , d 2 < d m a x d_1,d_2<d_{max} d1,d2<dmax。攻击者将收集到一个3-跟踪,即 P ′ = P 1 ′ ∣ ∣ P 2 ′ ∣ ∣ P 3 ′ P^{\prime}=P_1^{\prime}||P_2^{\prime}||P_3^{\prime} P′=P1′∣∣P2′∣∣P3′。 P 1 ′ P_1^{\prime} P1′包含带有 FRONT 噪声的 P 1 P_1 P1,之后是持续时间为 d 1 d_1 d1的胶水跟踪。 P 2 ′ P_2^{\prime} P2′包含 P 2 P_2 P2和持续时间为 d 2 d_2 d2的胶水跟踪。 P 3 ′ P_3^{\prime} P3′包含 P 3 P_3 P3和持续时间为 d m a x d_{max} dmax的胶水跟踪。当然,攻击者不可能知道每条跟踪的起点或终点。事实上,攻击者甚至不知道有多少条跟踪。如果攻击者试图错误地分割组合跟踪,那么部分或全部分割跟踪的起点或终点都会受到假数据包的污染,这将极大地影响 WF 攻击性能。
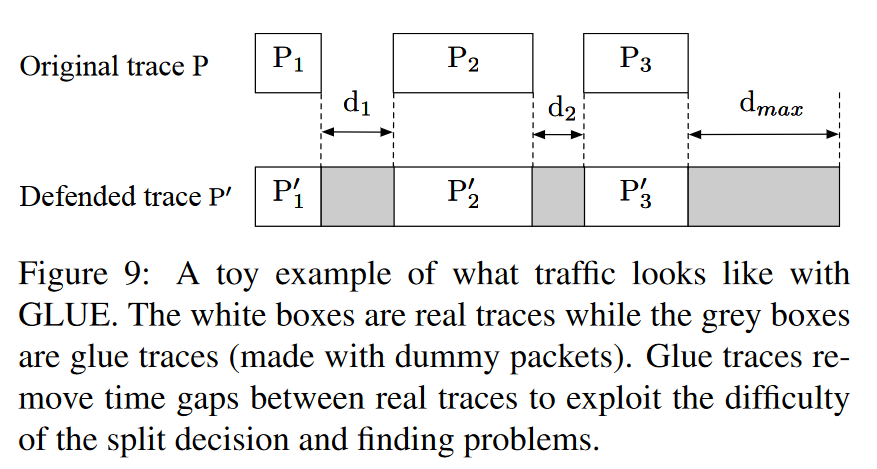
分发Glue跟踪
为了确保胶水跟踪看起来像真实跟踪,客户端需要有一个包含真实网页负载的数据库。我们建议客户端在启动 Tor 时,从 Tor 目录服务器上获取这样一个数据库以及 Tor 节点列表。然后,客户端会在一段时间后要求获取更多信息。在Glue模式下,客户端会指示代理何时发送虚假数据包。
请注意,胶水跟踪不包含真实数据,只包含发送和接收虚拟数据包的时间戳。因此,我们预计跟踪不会造成太多额外的数据开销。我们对分发胶水跟踪的数据开销估计如下。在我们的数据集中,一个跟踪平均有 4441 个数据包。因此,网页的平均大小为 2.3 MB。假设一个时间戳占 2 个字节,那么一个胶水跟踪就占 4441 × 2 = 0.008 MB。因此,在客户端,如果下载的胶水跟踪数量与访问的网页数量相同,则长期数据开销为 0.008/2.3 ≈ 0.003;如果客户端下载的胶水跟踪数量是实际需要的 10 倍,则长期数据开销为 0.03。
在目录服务器端,我们估算的分发成本如下。根据2018年11月至2019年11月的统计数据,我们发现用于回答目录请求的平均带宽为 172 MB/s,而 Tor 用户的平均数量为每天 210 万。如果用户平均每天下载 200 个胶水跟踪,则分发胶水跟踪的平均带宽约为 39 MB/s。因此,目录服务器的数据开销预计约为 39/172 ≈ 23%。为了混淆用户活动,我们可以要求用户定期下载随机数量的胶水痕迹,即使他们不需要下载,也要使用填充来隐藏窃听者下载的胶水痕迹数量。
实验评估
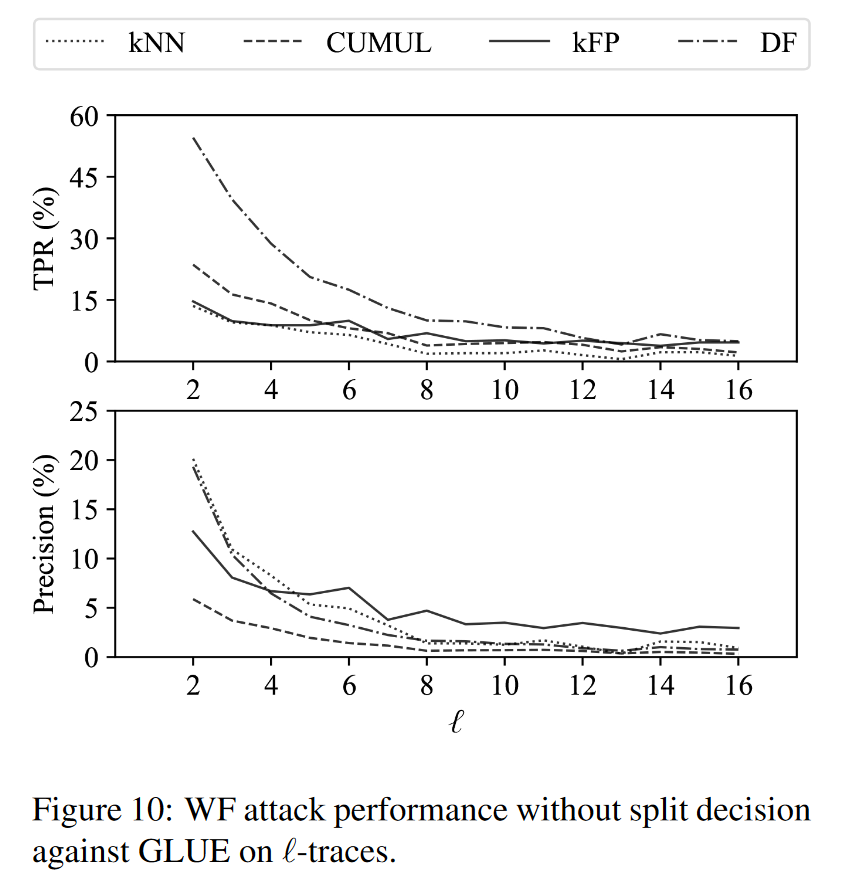
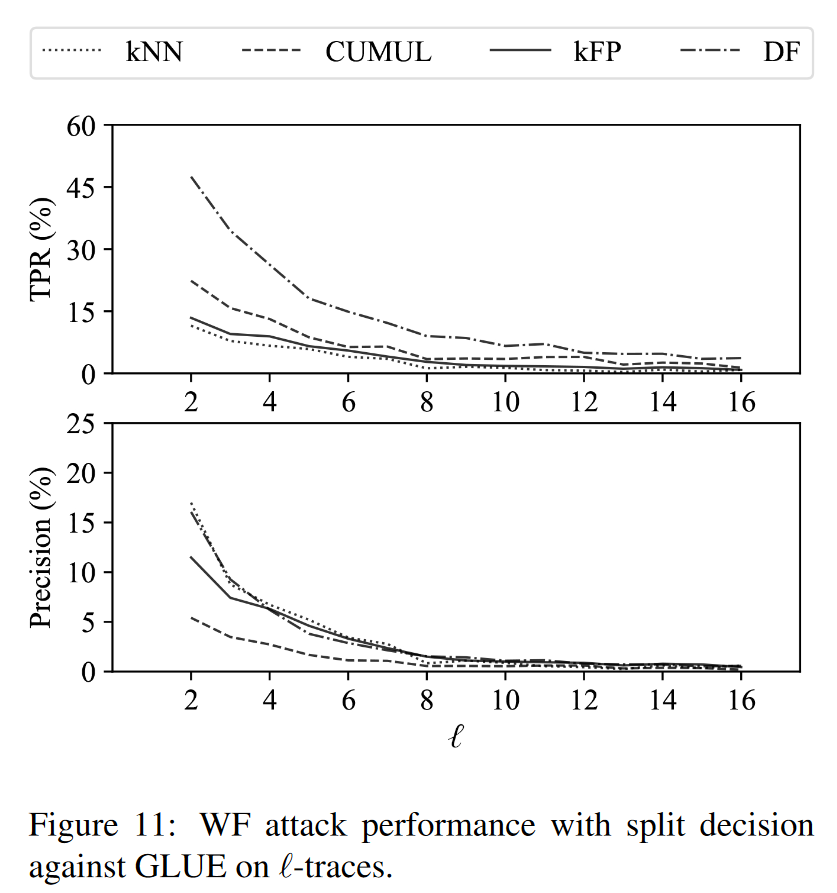
数据开销

总结和未来的工作
第一种防御方法FRONT利用高度随机的噪声来混淆痕迹。它不是均匀地散布虚假数据包,而是专注于混淆跟踪前沿。我们还对虚假数据包的数量和数据包填充窗口进行随机采样,以确保跟踪间的随机性。在数据开销相似的情况下,它击败了使用更简单方案的最著名的轻量级防御 WTF-PAD。
第二种防御方法是GLUE,它通过将单一跟踪粘合成l-跟踪,迫使WF攻击面对两个难题:分割决策和分割查找。当 ℓ \ell ℓ足够大时,GLUE 甚至可以超越Tamaraw等重量级防御。GLUE的开销各不相同,在3%-53%之间,具体取决于客户端行为。




![解决nginx报错nginx: [emerg] unknown log format main in 的方法](https://img-blog.csdnimg.cn/direct/4ad75087aad9426bb851295795af9126.png)