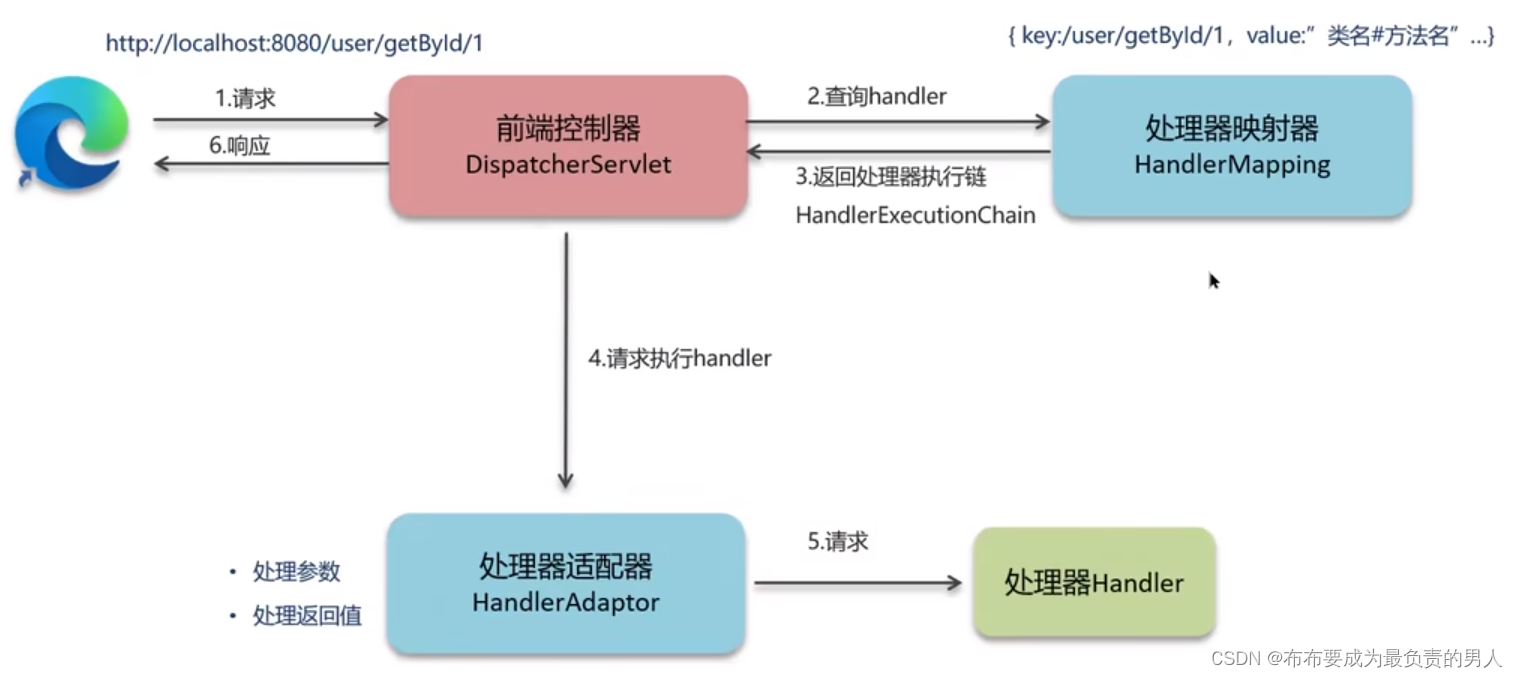
- 实验目的和要求
- 了解ROSTContentMining5.8可视化标签云的基本操作;
- 采集某部小说进行分词与词频分析
- 基于某背景图制作词云
或 - 采集二十大报告进行分词与词频分析;
- 基于某背景图制作二十大报告的词云;
- 数据来源
- 《射雕英雄传》或《鬼吹灯之精绝古城》等
- 《二十大报告》
src:
https://blog.csdn.net/weixin_43373042/article/details/121072950?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E8%AF%8D%E4%BA%91%E8%83%8C%E6%99%AF%E5%9B%BE&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-121072950.142v99pc_search_result_base8&spm=1018.2226.3001.4187
二十大分词
[('坚持', 0.0852576996526393), ('发展', 0.0672213275828808), ('建设', 0.06355633945549423), ('社会主义', 0.06266247522205451), ('人民', 0.06020826767674832), ('体系', 0.05481397677119373), ('推进', 0.05294909245304813), ('现代化', 0.049429352306818185), ('全面', 0.04899317588248663), ('加强', 0.04251966142638262), ('国家', 0.03760984541533897), ('完善', 0.037522416070218216), ('安全', 0.034436901715011216), ('健全', 0.033932414768411245), ('制度', 0.03386976984357081), ('中国', 0.03211665037598586), ('特色', 0.02880738027677419), ('推动', 0.02764605696997499), ('治理', 0.027256509198317232), ('时代', 0.02612111143529412), ('加快', 0.025655167273064515), ('我们', 0.025448047535633088), ('法治', 0.024998151345996207), ('政治', 0.024363583670018975), ('创新', 0.024262188961842332), ('深化', 0.024227404137484906), ('战略', 0.02232624110383388), ('实现', 0.022185627498055027), ('文化', 0.02062999775573659), ('社会', 0.020523082667777297), ('构建', 0.018914992551261858), ('马克思主义', 0.018781615975402795), ('民主', 0.018747444574062445), ('能力', 0.018729954755863375), ('促进', 0.01849270547327497), ('统筹', 0.01833013433794549), ('维护', 0.018159140717653958), ('中华民族', 0.01812105078162153), ('世界', 0.018081888172102812), ('增强', 0.01800056938496119), ('问题', 0.017776669466979474), ('领导', 0.017681859453475075), ('机制', 0.017649157574780056), ('坚定', 0.01751774966746938), ('伟大', 0.017405305109722272), ('强国', 0.01735482829955149), ('重大', 0.01724546981219424), ('保障', 0.017244019562220114), ('教育', 0.017141947579222012), ('科技', 0.01660040235315939), ('工作', 0.01631216753542781), ('人才', 0.01590416244110402), ('中国共产党', 0.015594813327443505), ('必须', 0.015585077451676727), ('生态', 0.015326346720972918), ('干部', 0.015199776382722099), ('更加', 0.015116105621925996), ('思想', 0.014940002537860963), ('复兴', 0.014780285222903224), ('精神', 0.014541262510143177), ('基层', 0.014445577024307401), ('贯彻', 0.014371670620135415), ('实施', 0.01423353194115577), ('改革', 0.014206087284535103), ('基本', 0.014079639633724338), ('国际', 0.013889565709535966), ('提高', 0.013883239530146628), ('实践', 0.013782052225316543), ('优化', 0.013600376772602209), ('落实', 0.013050872041537001), ('经济', 0.012947692954031398), ('我国', 0.01277141566394687), ('历史', 0.012705171842401242), ('事业', 0.012611721495705538), ('群众', 0.012469979350008625), ('高质量', 0.012383541786192859), ('协商', 0.012245892289676555), ('理论', 0.012245804056661206), ('深入', 0.012142396952732448), ('坚决', 0.012074910291256685), ('党和国家', 0.01168683353655339), ('领域', 0.011670466496485251), ('依法', 0.011634336530317405), ('协调', 0.011202288980162152), ('保护', 0.011176134425847853), ('巩固', 0.011023604218749353), ('党中央', 0.010967651292309815), ('文明', 0.010915486989178885), ('统一', 0.010904176526600829), ('全党', 0.010826880460919442), ('提升', 0.010571652501024669), ('力量', 0.010543924249658445), ('不断', 0.010361366055028463), ('弘扬', 0.010336476067194239), ('强军', 0.010094404928928758), ('就业', 0.009863478302991202), ('强化', 0.00978022653749267), ('支持', 0.009633832453092978), ('发挥', 0.009588766440755563), ('着力', 0.009580919565344143)]
词云
import jieba
import jieba.analyse
import jieba
import jieba.posseg as psg
from collections import Counter
# 待分词的文本路径
sourceTxt = r"D:\\学习\\excel\\文本分析\\数据集\\文本分析\\2024年政府工作报告.txt"
# 分好词后的文本路径
targetTxt = r"D:\\学习\\excel\\文本分析\\数据集\\文本分析\\2024年政府工作报告输出.txt"# 对文本进行操作with open(sourceTxt, 'r', encoding = 'utf-8') as sourceFile, open(targetTxt, 'a+', encoding = 'utf-8') as targetFile:for line in sourceFile:seg = jieba.cut(line.strip(), cut_all = False)# 分好词之后之间用空格隔断output = ' '.join(seg)targetFile.write(output)targetFile.write('\n')print('写入成功!')# 提取关键词
with open(targetTxt, 'r', encoding = 'utf-8') as file:text = file.readlines()"""几个参数解释:* text : 待提取的字符串类型文本* topK : 返回TF-IDF权重最大的关键词的个数,默认为20个* withWeight : 是否返回关键词的权重值,默认为False* allowPOS : 包含指定词性的词,默认为空"""keywords = jieba.analyse.extract_tags(str(text), topK = 100, withWeight=True, allowPOS=())print(keywords)print('提取完毕!')import jieba.analyse
import matplotlib as mpl
import matplotlib.pyplot as plt
from wordcloud import WordCloud,STOPWORDS,ImageColorGeneratorcontent = open(r"D:\\学习\\excel\\文本分析\\数据集\\文本分析\\单列输出.txt", encoding = 'UTF-8').read()
tags = jieba.analyse.extract_tags(content,topK=200,withWeight=False)
text = ' '.join(tags)
wc = WordCloud(font_path=r"D:\\coder\\randomnumbers\\Keywords_cloud\\msyh.ttf",background_color='white',max_words=2000,#max_font_size=120,min_font_size=10,random_state=42,width=1200,height=800)
wc.generate(text)
plt.imshow(wc)
plt.axis('off')
plt.show()
词云背景
from PIL import Image
import numpy as npusa_mask = np.array(Image.open("D:\\学习\\excel\\文本分析\\数据集\\文本分析\\mhQ17m-1og0ZdT1kSgi-sg.jpeg"))wordcloud = WordCloud(background_color='white', # 背景色为白色font_path=r"D:\\coder\\randomnumbers\\Keywords_cloud\\msyh.ttf",height=4000, # 高度设置为400width=8000, # 宽度设置为800scale=20, # 长宽拉伸程度程度设置为20prefer_horizontal=0.9999,mask=usa_mask # 添加蒙版).generate(text)
plt.figure(figsize=[8, 4])
plt.imshow(wordcloud)
plt.axis('off')
'''保存到本地'''
plt.savefig('图9.jpg', dpi=600, bbox_inches='tight', quality=95)
plt.show()