vLLM:给大模型提提速
- 提出背景
- 迭代级调度
- 细粒度批处理机制
- PagedAttention算法、KV缓存管理器、分布式执行
提出背景
论文:https://dl.acm.org/doi/pdf/10.1145/3600006.3613165
代码:https://github.com/vllm-project/vllm
文档:https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html
在未优化的系统中,每个请求的KV缓存被存储在连续的内存空间中。
当这些请求动态增长和缩减时,系统很难精确地预测每个请求所需的最大内存大小。
这导致了大量的内部碎片化(预留的内存未被完全使用)和外部碎片化(由于连续内存的需求,可用内存块被分散,不能被有效利用)。

它突出了三种类型的内存浪费—预留、内部碎片和外部碎片。这些浪费阻止了内存的有效使用,导致无法为其他请求提供空间。
图中的标记(如"four"、“score”、“and”、"seven"等)代表它们自己的KV缓存。
由于为最大潜在序列长度预留了内存,以及由于内存碎片化,导致并非所有内存插槽都得到有效利用,造成了内存空间的浪费。
例如,如果系统为每个请求预留了足够存储2048个令牌的空间,但实际上大多数请求只生成了几百个令牌,那么剩余的内存就浪费了。
同时,由于内存是连续预留的,其他较短的请求也无法利用这些未使用的内存空间。
-
PagedAttention算法:灵感来源于操作系统中的虚拟内存和分页技术,PagedAttention算法将请求的KV缓存分割成块,每个块包含固定数量的令牌的注意力键和值。
这种方法使得KV缓存的管理更加灵活,类似于操作系统的虚拟内存。
为了解决这个问题,我们引入了PagedAttention算法。
该算法将KV缓存分割成多个块(页),每个块只存储固定数量的令牌信息。
这样,当一个请求需要更多的令牌存储时,系统只需分配更多的块,而不是预留一个巨大的连续空间。这大大减少了内部和外部碎片化。
例如,如果一个请求初始只生成了200个令牌,系统只需要分配足够存储这200个令牌的块。
如果请求继续生成更多令牌,系统可以根据需要继续分配更多的块。
这种方式使得内存利用率大大提高,也允许系统更灵活地管理不同请求的内存需求。
之所以采用这种子解决方案,是因为KV缓存的动态增长和缩减特性以及其对连续内存空间的需求造成了内存碎片化。
-
vLLM系统:在PagedAttention的基础上构建的一个高吞吐量的分布式LLM服务引擎,采用块级内存管理和预先请求调度,实现了KV缓存内存的近零浪费。
之所以开发vLLM系统,是为了克服现有服务系统在KV缓存管理上的效率低下问题,特别是内存碎片化和无法利用内存共享的机会。
自回归式生成的效率问题:每个翻译请求都需要模型逐个生成翻译后的词汇,依赖于前面所有词汇的上下文。
由于这种生成方式的顺序性,每次只能处理一个词汇,导致GPU的并行计算能力得不到充分利用,同时内存受限也成为瓶颈。
请求多样性:来自不同用户的请求在长度和复杂度上差异巨大,从简单的病症查询到需要深入分析的研究论文摘要。
如果按照传统批处理方式处理,短请求可能需要等待长请求完成,影响用户体验。
迭代级调度
应用场景:为了提高GPU的利用率并减少内存束缚,我们采用迭代级调度技术。
在处理翻译请求时,系统不是在整个批次完成后才开始处理新的请求,而是在每次迭代生成一个词后,就检查是否有请求已完成。
完成的请求会从当前批次中移除,同时加入新的请求。
这种方法使得新请求能够在下一个迭代就开始处理,大大减少了用户等待的时间。
想象你在一家快餐店工作,你负责制作汉堡。每个汉堡都需要按顺序添加配料:首先是面包底,然后是生菜,接着是汉堡肉,最后是面包顶。客人的订单(即请求)随时都在到来,而且每个客人可能要的汉堡数量不同。
如果你每次只为一个客人制作完所有汉堡后,才开始处理下一个客人的订单,那么后来的客人就需要等很长时间。特别是在忙时,等待时间会变得非常长。
传统处理方式(不使用迭代级调度):
- 方式:你等待直到有5个客人的订单后,再开始同时为这5个客人制作汉堡。
- 但是,你得等待最后一个客人的所有汉堡做完,才能开始新一轮的订单处理。
- 问题:早到的客人需要等待后到客人的汉堡完成,导致不必要的延迟。
改进的处理方式(迭代级调度的比喻):
- 方式:你开始制作第一轮的5个客人的汉堡,但在每完成一步(比如加完生菜)后,就检查是否有客人的全部汉堡都完成了这一步。
- 如果是,那这个客人的订单就可以先出去,不用等其他客人的订单完成。
- 同时,如果有新的客人来了,你就把他们的订单加入到下一步的制作中。
- 优势:这样做的好处是,每个客人的汉堡可以更快完成,不需要等所有人的都做完才开始出餐。这样就大大减少了客人的等待时间。
假设客人A的订单先完成了加生菜的步骤,而此时客人B的订单刚刚到达。
按照改进的方式,你可以立即把客人A的订单向前推进到下一步(加汉堡肉),同时把新来的客人B的订单加入到加生菜的步骤中。
这样,每个订单都在它准备好进行下一步时立即进行,而不是等待所有订单都达到相同的处理点。
通过这种方法,每个客人的订单都能更快地完成,快餐店能够更高效地处理高峰时期的订单压力,客人满意度也因为等待时间的缩短而提高。
细粒度批处理机制
应用场景:为了应对请求长度差异大的问题,我们采用了细粒度批处理机制。
通过这种机制,系统能够根据每个请求的实际长度动态调整处理批次,避免了为了匹配最长请求而对其他请求进行不必要的填充。
这不仅提升了计算效率,也减少了内存的浪费。
PagedAttention算法、KV缓存管理器、分布式执行
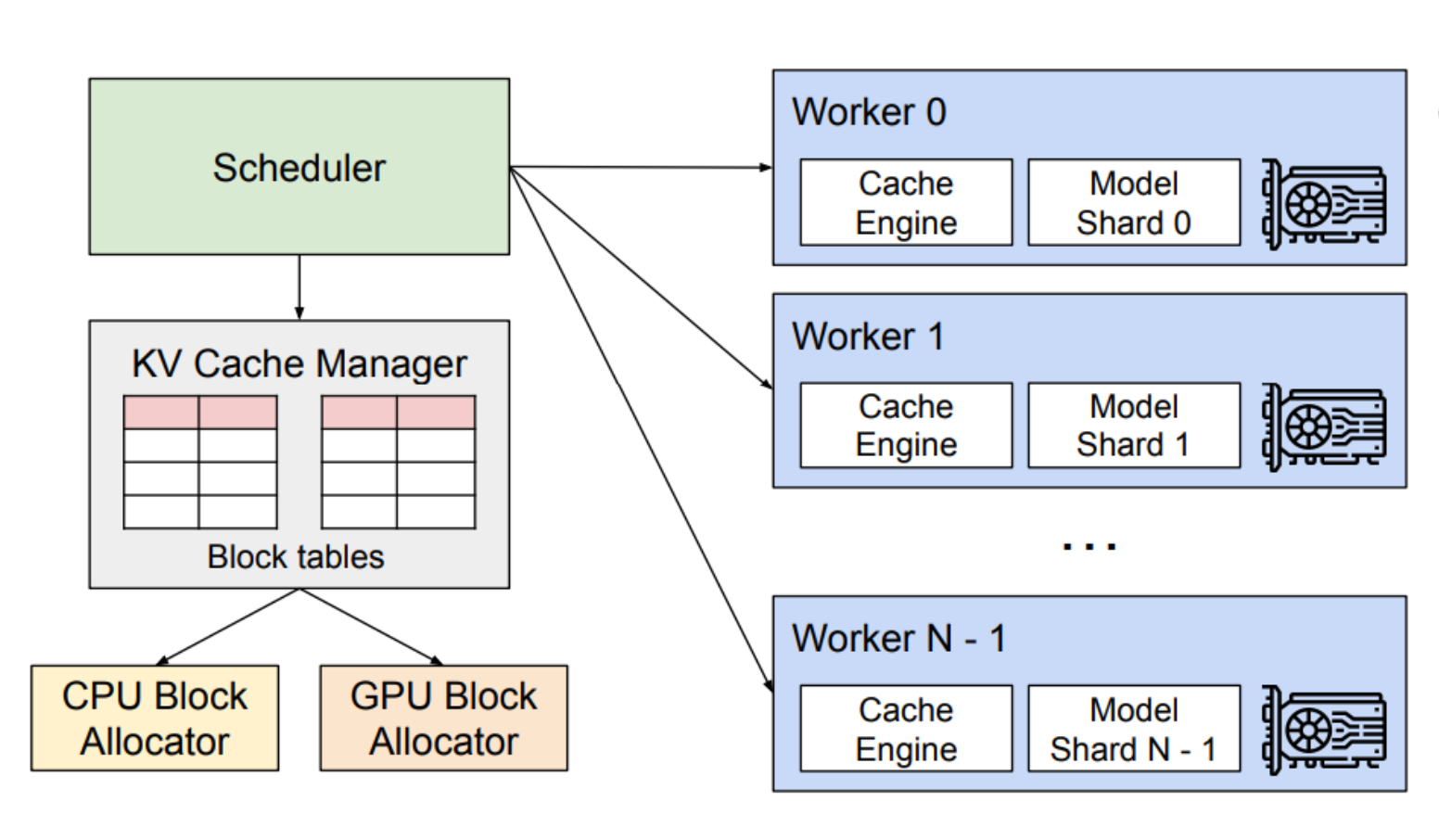
vLLM的系统架构:
想象你在一个图书馆里负责把书放回书架上。
图书馆非常大,有成千上万本书。
每本书必须放回它特定的区域,但是这些区域在空间上并不是连续的。
这就像LLM服务中的KV缓存管理问题。
-
使用PagedAttention: 就像你把书分成几堆,每堆书放在一个可以轻松到达的小车上。
当一个区域的书架满了或者需要在另一个区域放书时,你可以推动小车到那个区域。
这就是分页机制,让你不必一次性找到一个巨大的连续空间来存储所有书籍,而是可以根据需要动态地移动小车(页)。
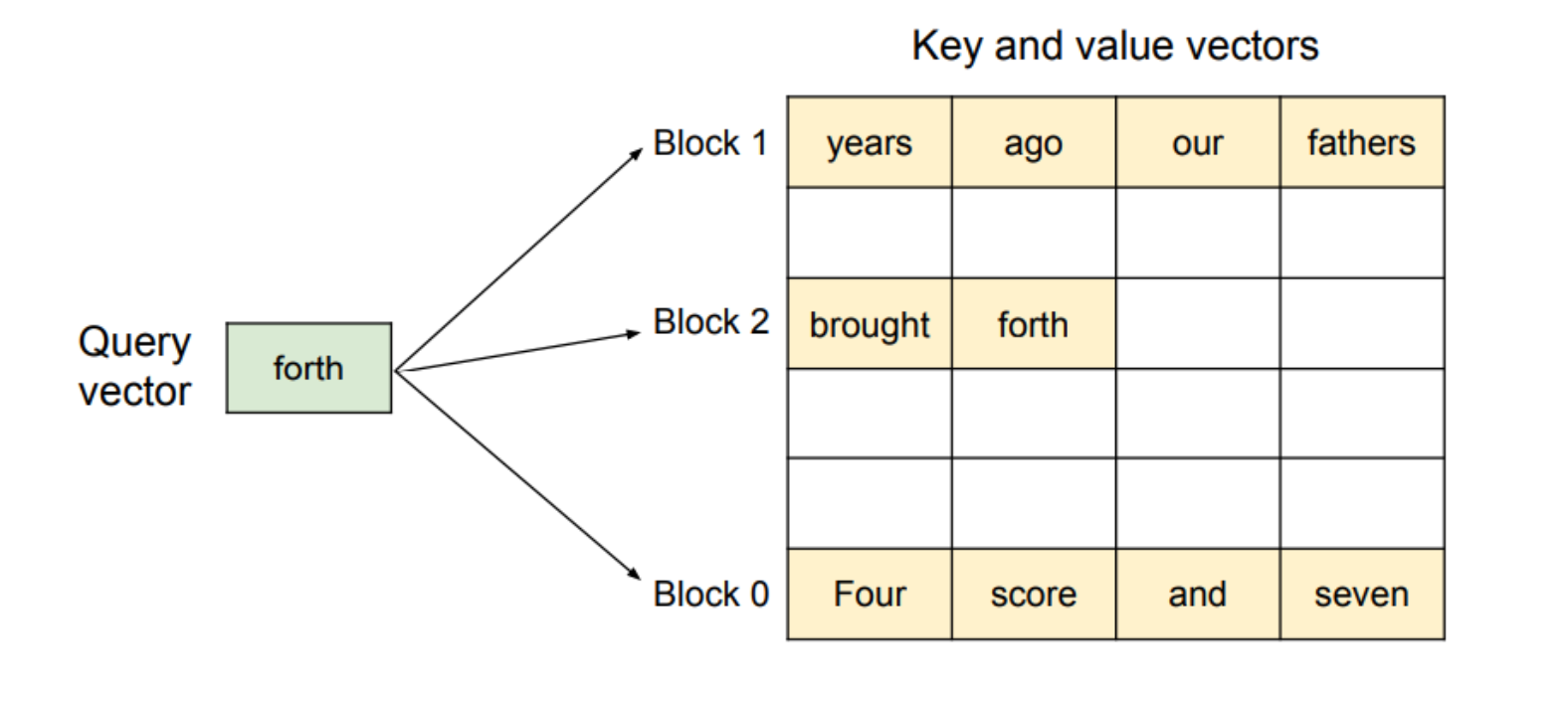
PagedAttention算法的示意图,其中注意力键和值向量存储在非连续的内存块中。
"forth"查询向量指出了该算法如何从物理内存中不连续存储的不同块中检索键和值向量。
-
KV缓存管理器: 假设你有一个助手,他通过无线耳机告诉你哪些书需要放回哪些区域。
你不需要记住所有书的位置,只需跟随指令行动。
这就像KV缓存管理器,它根据中央调度器的指令,在GPU工作器上管理物理KV缓存。
-
分布式执行: 现在,假设图书馆不仅大,而且分布在几栋楼中。
你和你的同事需要分工合作,确保所有的书都能正确归位。
每个人负责一栋楼,但大家通过无线耳机相互协调,确保整个图书馆的运作顺畅。
这就像vLLM的分布式执行策略,使得即使是非常大的模型也可以在多个GPU上有效执行。
通过这种方式,vLLM可以在有限的GPU内存中,以更高的效率处理更多的请求,提高了LLM服务的吞吐量和响应速度。