实战高效RPC方案在嵌入式环境中的应用与揭秘
开篇
在嵌入式系统开发中,大型项目往往采用微服务架构来构建,其核心思想是将一个庞大的单体应用分割成一系列小型、独立、松耦合的服务模块,这些模块可以是以线程或进程形式存在的多个服务单元。各服务间为了协同工作,不可避免地需要进行进程间通信(IPC, Inter-Process Communication)。
已有的IPC方案众多,包括但不限于信号、管道、消息队列和Socket通信等。此前也分享过系列文章,详细介绍过这些方案的使用方式(可以在公众号聊天界面获取历史文章目录)。不过,大多数传统IPC方案主要侧重于单向数据传递,对于服务调用后的同步返回值处理并未提供直接的支持。
鉴于此,本文参照Android平台中的Binder机制,设计并实现了一套具备同步返回值功能的RPC(Remote Procedure Call,远程过程调用)方案。这套方案汲取了Binder的优点,能够有效地在进程间进行服务调用并同步接收返回结果,解决了传统IPC方案在双向通信方面的局限性,提升了嵌入式应用中服务间通信的效率和灵活性。
选择共享环形缓冲区的缘由
首先,对于RPC的实现要求,数据传输的顺序必须按照接口传入参数的顺序依次传输。调用者和被调用者保持相同的内存偏移同步写入和读取,确保数据不乱套。
为什么选用共享内存,而非其他的IPC方案?
- 零拷贝(Zero-copy)优势:共享内存允许进程直接访问同一块内存区域,省去了数据在用户态和内核态之间的多次复制,对于RPC会存在的高频调用,可以显著降低系统开销,提升性能。
- 实时性与低延迟:由于数据在内存层面直接交互,共享内存的通信延迟较低,能够提升同步参数与返回值过程的耗时。
- 灵活的访问模式:不同于管道、消息队列等其他IPC方式,共享内存支持多个进程同时读写,通过合理的同步机制可以实现并发访问,适用于复杂的数据交互模式。
为什么采用环形缓冲区?
- 先进先出(FIFO)特性:环形缓冲区天然符合FIFO数据传输的需求,保证了数据的有序传输,适用于RPC调用时参数和返回值的有序传递。
- 资源复用与空间管理:环形缓冲区通过循环利用内存空间,有效避免了频繁分配和回收内存资源,从而减少内存碎片,提高内存利用率。
- 简化同步复杂性:通过维护读写指针,环形缓冲区可以相对简单地实现多进程间的同步和数据一致性,相较于非循环结构的缓冲区,更容易管理何时可以安全地读写数据。
设计思路
我们的目的是实现进程间接口的远程调用,外部的需求主要两点:1.参数传递 2. 结果同步返回。
基于此,大致时序如下:
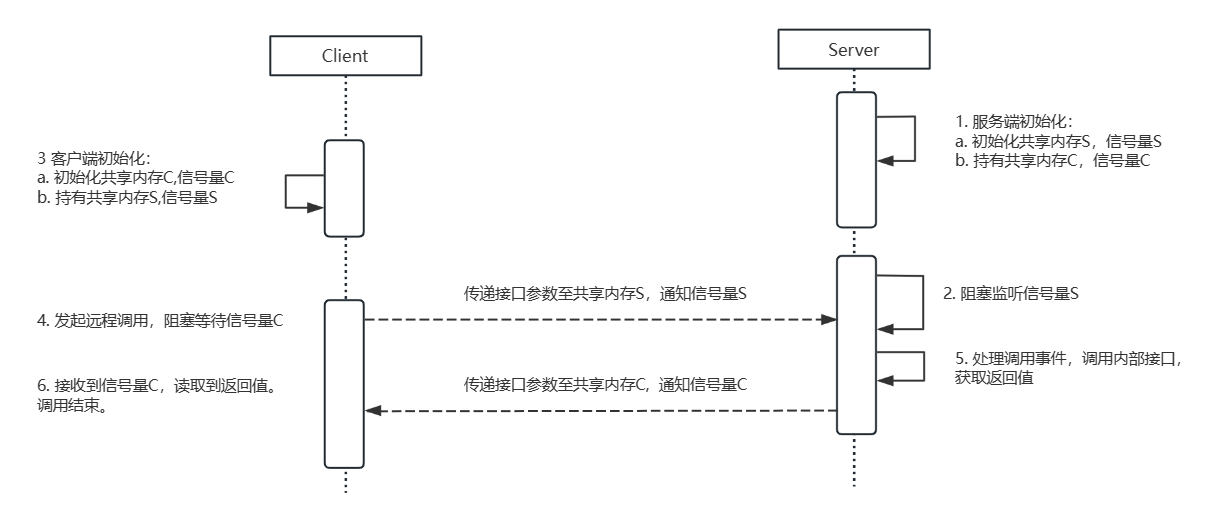
首先约定:服务端与客户端各创建一片共享内存和信号量。同时持有彼此的共享内存和信号量。(方便调试的做法,实际项目应该统一管理分配)
- 服务进程持先启动,初始化共享内存S和信号量S,同时持有客户端的共享内存C和信号量C。
- 服务端初始化完毕后,阻塞监听信号量S。
- 客户端后启动,初始化共享内存C和信号量C,同时持有服务端的共享内存S和信号量S。
- 客户端发起远程调用,将参数写入共享内存S。信号量S通知服务端,阻塞等待信号量C。
- 服务端解除阻塞,读取共享内存S。读取到参数,并调用本地接口,获取返回值。
并将返回值写入共享内存C,通过信号量C通知客户端。 - 客户端解除阻塞,读取共享内存C,获取到返回值。本次调用完毕。
源码实现
编程环境
- 编译环境: Linux环境
- 语言: C++11
接口定义
- 环形缓冲区接口(SharedRingBuffer)
struct Root
{uint8_t work; // 使能状态uint8_t busy; // 忙碌状态uint8_t rwStatus; // 可读状态uint32_t wp; // 写入位置uint32_t rp; // 读取位置
};enum ECmdType
{CMD_WRITEABLE = 0x01,CMD_READABLE = 0x02,CMD_BUTT,
};class SharedRingBuffer
{
public:SharedRingBuffer(std::string path, uint32_t capacity);~SharedRingBuffer();bool IsReadable() const noexcept;bool IsWriteable() const noexcept;int write(const void* data, uint32_t len);int read(void* data, uint32_t len);private:uint32_t AvailSpace() const noexcept;uint32_t AvailData() const noexcept;void SetRWStatus(ECmdType type) const noexcept;void DumpMemory(const char* pAddr, uint32_t size);void DumpErrorInfo();private:Root* mRoot;void* mData;uint32_t mCapacity;std::mutex mMutex;std::string mShmPath;
};
SharedRingBuffer对外仅暴露四个接口,主要用于数据的检查和读写。
- 数据封装接口(Parcel)
class Parcel
{
public:Parcel(std::string path, int key, bool master);~Parcel();int WriteBool(bool value);int ReadBool(bool& value);int WriteInt(int value);int ReadInt(int& value);int WriteString(const std::string& value);int ReadString(std::string& value);int WriteData(void* data, int size);int ReadData(void* data, int& size);int wait();int post();private:bool mMaster;int mShmKey;sem_t* mSem ;std::string mShmPath;SharedRingBuffer* mRingBuffer;
};
Parcel持有共享环形缓冲区和信号量,负责数据的封装。对外提供各种数据类型的写入和读取,同时提供数据同步机制接口wait(),post() 。
关键接口实现
篇幅有限,文章仅列举关键实现接口(完整代码可在聊天界面输入标题获取)
- SharedRingBuffer::write(const void* data, uint32_t len)
int SharedRingBuffer::write(const void* data, uint32_t len) {int ret = -1;int retry = RETRY_TIMES;// It's hard to believe, but it actually happened:// Although post after it is written in the shared memory, synchronization still might not be timely,// and the AvailSpace() returns 0. Only add a retry to avoid itwhile (retry > 0) {std::lock_guard<std::mutex> lock(mMutex);int32_t avail = AvailSpace();if (avail >= len) {memcpy(static_cast<char*>(mData) + mRoot->wp, data, len);mRoot->wp = (mRoot->wp + len) % mCapacity;SetRWStatus(CMD_READABLE);ret = 0;break;} else {SPR_LOGE("AvailSpace invalid! avail = %d\n", avail);DumpErrorInfo();retry--;usleep(RETRY_INTERVAL_US);}}return ret;
}
write 接口实现的是将数据写入共享内存,并同步写入偏移量和相关状态。这里加了失败重试机制和一些线程同步。
- SharedRingBuffer::read(void* data, uint32_t len)
int SharedRingBuffer::read(void* data, uint32_t len)
{int ret = -1;int retry = RETRY_TIMES;// Refer to write commentswhile (retry > 0) {std::lock_guard<std::mutex> lock(mMutex);int32_t avail = AvailData();if (avail >= len) {memcpy(data, static_cast<char*>(mData) + mRoot->rp, len);mRoot->rp = (mRoot->rp + len) % mCapacity;SetRWStatus(CMD_WRITEABLE);ret = 0;break;} else {SPR_LOGE("AvailData invalid! avail = %d, len = %d\n", avail, len);DumpErrorInfo();retry--;usleep(RETRY_INTERVAL_US);}}return ret;
}
read 接口实现的是将数据从共享内存读取出。大致流程与write一致。
测试效果
实现一个简单的例子,客户端远程调用服务端的一个接口 CalculateSum(int val1, int val2)
- 服务端代码
static int CalculateSum(int val1, int val2)
{return val1 + val2;
}void ServerHandleRequest(Parcel& req, Parcel& reply)
{int cmd;req.ReadInt(cmd);switch (cmd){case PARCEL_CMD_CACULATE_SUM:{int val1 = 0;int val2 = 0;req.ReadInt(val1);req.ReadInt(val2);int sum = CalculateSum(val1, val2);reply.WriteInt(sum);break;}default:SPR_LOGE("Invaild Cmd(0x%x)!\n", cmd);break;}reply.post();
}int main()
{Parcel replyParcel("client_rpc", 88888, false);Parcel reqParcel("server_rpc", 12345, true);while (true){reqParcel.wait();ServerHandleRequest(reqParcel, replyParcel);}return 0;
}
- 客户端代码
Parcel reqParcel("server_rpc", 12345, false);
Parcel replyParcel("client_rpc", 88888, true);int CalculateSum(int val1, int val2)
{int sum = 0;reqParcel.WriteInt(PARCEL_CMD_CACULATE_SUM);reqParcel.WriteInt(val1);reqParcel.WriteInt(val2);reqParcel.post();replyParcel.wait();replyParcel.ReadInt(sum);return sum;
}int main() {char in = 0;do {SPR_LOGD("Input: ");scanf("%c", &in);getchar();switch (in){case '3':{int val1 = 0;int val2 = 0;SPR_LOGD("Input val1 val2: ");scanf("%d %d", &val1, &val2);getchar();int sum = CalculateSum(val1, val2);SPR_LOGD("sum = %d\n", sum);break;}default:break;}} while (in != 'q');return 0;
}
- 测试结果
Client D: Input val1 val2: 11 22
Client D: sum = 33
Client D: Input val1 val2: 10 10
Client D: sum = 20
总结
-
本文介绍了一种实用高效的RPC(远程过程调用)解决方案。传统的IPC机制在处理服务间的双向通信时存在挑战,比如无法很好地支持同步返回结果。于是,受Android Binder机制的启发,运用共享环形缓冲区,实现一套轻量化RPC框架。
-
共享内存配合上数据结构,用起来还是挺高效和方便的。例如之前的《高性能共享内存》 用的是二叉树和共享内存;这篇文章是环形缓冲区和共享内存。应该还有其他数据结构配合共享内存用于新的场景,等待学习。
-
之所以选择共享内存,主要是因为它具有零拷贝、低延迟、高实时性等优点,能显著降低资源开销,尤其频繁调用的RPC场景。而环形缓冲区的引入,则因其自带的先进先出特性,确保了数据传输的有序性,同时通过循环利用内存空间,减少了内存碎片,提高了内存使用效率。
-
在实现过程中,设计SharedRingBuffer类来管理共享内存中的环形缓冲区,提供了判断缓冲区状态和进行读写操作的方法。Parcel类则充当了数据的打包和解包角色,它可以方便地处理不同数据类型的读写,并通过控制信号量实现了服务调用的同步等待与响应。
-
通过具体的示例——远程调用CalculateSum函数,展示如何在客户端和服务端利用上述类实现RPC通信。经过实际测试,达成预期。
-
实现共享环形缓冲区,是因为个人在Linux应用项目中,遇到了需要RPC的场景。但流行的RPC框架,要么代码量太大,移植费劲;要么资源消耗大,不适合用于嵌入式环境。最主要原因的是,个人技术有限,移植一套RPC框架心有余而力不足。