AI:Nvidia官网人工智能大模型工具合集(文本生成/图像生成/视频生成)的简介、使用方法、案例应用之详细攻略
目录
Nvidia官网人工智能大模型工具合集的简介
1、网站主要功能包括:
Nvidia官网人工智能大模型工具合集的使用方法
1、SDXL-Turbo的使用
2、GEMMA-7B的使用
T1、在线生成代码
T2、采用gemma-7b的API实现
3、LLAMA2-70B的使用
T1、在线生成代码
T2、采用LLAMA2-70B的API实现
4、StabilityAI的Stable-Video-Diffusion使用
5、MistralAI的Mistral-7B-Instruct-v0.2使用
6、CodeLLAMA-70B的使用
Nvidia官网人工智能大模型工具合集的案例应用
Nvidia官网人工智能大模型工具合集的简介
NVIDIA NIM APIs让开发者可以轻松地调用NVIDIA的AI模型,这些模型经过优化可以在GPU上高效运行。所以总体来说,这个网站是NVIDIA展示他们AI模型库的平台,让开发者能方便地评估和应用这些模型,在产品和服务中集成人工智能功能。
官网地址:Try NVIDIA NIM APIs
1、网站主要功能包括:
>> 展示NVIDIA开源和内部训练的不同领域的AI模型,如图像生成、语言生成、视频生成等。
>> 用户可以在线试用这些模型,给出输入看模型的输出。
>> 提供每个模型的文档和说明,了解它能做什么和如何调用。
>> 按照应用领域(如游戏、医疗等)和任务(如图像识别、自然语言处理等)过滤模型。
>> 登陆后可能提供更高级功能,比如定制模型或将模型部署到用户自己的服务器。
Nvidia官网人工智能大模型工具合集的使用方法
1、SDXL-Turbo的使用
生成图像
NVIDIA NIM
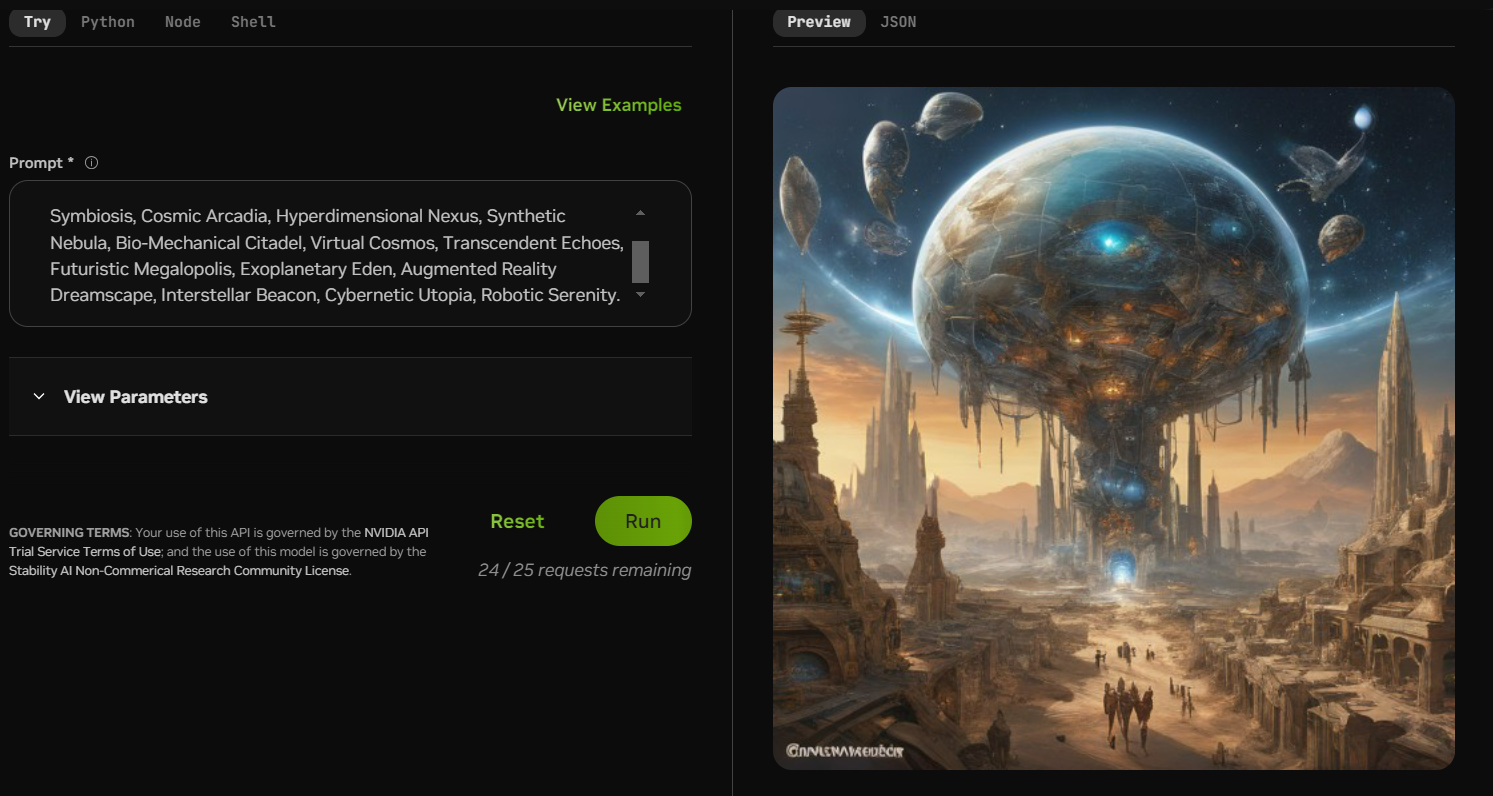
快速生成文本到图像的模型,可以在单次网络评估中从文本提示中合成逼真的图像。
Sci-Fi Image Generator Prompt: Quantum Flux, Cyborg Oasis, Alien Metropolis, Galactic Nexus, Celestial Portal, Techno-Organic Fusion, Astral Frontier, Nano-Symbiosis, Cosmic Arcadia, Hyperdimensional Nexus, Synthetic Nebula, Bio-Mechanical Citadel, Virtual Cosmos, Transcendent Echoes, Futuristic Megalopolis, Exoplanetary Eden, Augmented Reality Dreamscape, Interstellar Beacon, Cybernetic Utopia, Robotic Serenity.
2、GEMMA-7B的使用
聊天
语言生成
前沿文本生成模型,能够理解文本、进行转换和生成代码。
T1、在线生成代码
Certainly! Here's a prompt in English that you can use to generate Python machine learning code:
"Please create a Python script that implements a machine learning algorithm for classifying iris flowers based on the iris dataset. The script should include steps for data loading, preprocessing, model training, and evaluation using accuracy as the metric. Use a popular machine learning library such as scikit-learn, and provide comments in the code for clarity."

#Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score#Load the iris dataset
iris_data = pd.read_csv('iris.csv')#Preprocess the data
X = iris_data.drop('species', axis=1)
y = iris_data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)#Train the logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)#Evaluate the model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('The accuracy of the model is:', accuracy)
T2、采用gemma-7b的API实现
from openai import OpenAIclient = OpenAI(base_url = "https://integrate.api.nvidia.com/v1",api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
)completion = client.chat.completions.create(model="google/gemma-7b",messages=[{"role":"user","content":"who are you?"}],temperature=0.5,top_p=1,max_tokens=1024,stream=True
)for chunk in completion:if chunk.choices[0].delta.content is not None:print(chunk.choices[0].delta.content, end="")3、LLAMA2-70B的使用
聊天
语言生成
前沿的大型语言人工智能模型,能够根据提示生成文本和代码。
T1、在线生成代码
Please create a Python script that implements a machine learning algorithm for classifying iris flowers based on the iris dataset. The script should include steps for data loading, preprocessing, model training, and evaluation using accuracy as the metric. Use a popular machine learning library such as scikit-learn, and provide comments in the code for clarity.

#Import necessary libraries
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score#Load the iris dataset
iris = load_iris()
X = iris.data[:, :2] #we only take the first two features.
y = iris.target#Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)#Scale the data using StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)#Train an SVM model on the scaled training data
svm = SVC(kernel='linear', C=1)
svm.fit(X_train_scaled, y_train)#Evaluate the model on the test data
y_pred = svm.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.3f}")#Use the trained model to make predictions on new data
new_data = [[5.1, 3.5]]
new_data = scaler.transform(new_data)
prediction = svm.predict(new_data)
print(f"Prediction: {prediction}")
T2、采用LLAMA2-70B的API实现
from openai import OpenAIclient = OpenAI(base_url = "https://integrate.api.nvidia.com/v1",api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
)completion = client.chat.completions.create(model="meta/llama2-70b",messages=[{"role":"user","content":"Please create a Python script that implements a machine learning algorithm for classifying iris flowers based on the iris dataset. The script should include steps for data loading, preprocessing, model training, and evaluation using accuracy as the metric. Use a popular machine learning library such as scikit-learn, and provide comments in the code for clarity."}],temperature=0.5,top_p=1,max_tokens=1024,stream=True
)for chunk in completion:if chunk.choices[0].delta.content is not None:print(chunk.choices[0].delta.content, end="")4、StabilityAI的Stable-Video-Diffusion使用
Stable-Video-Diffusion
图像到视频
NVIDIA NIM
稳定视频扩散(SVD)是一种生成扩散模型,利用单个图像作为条件帧来合成视频序列。
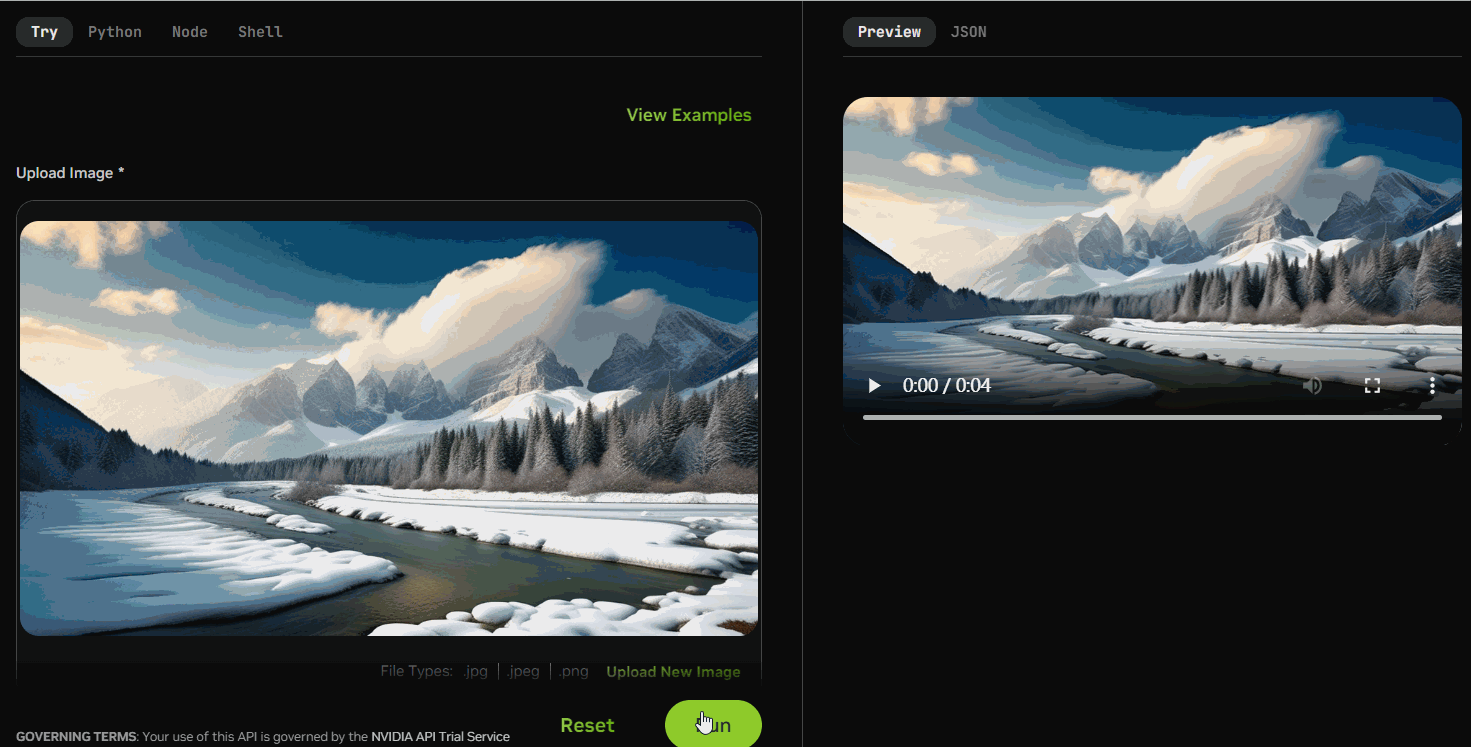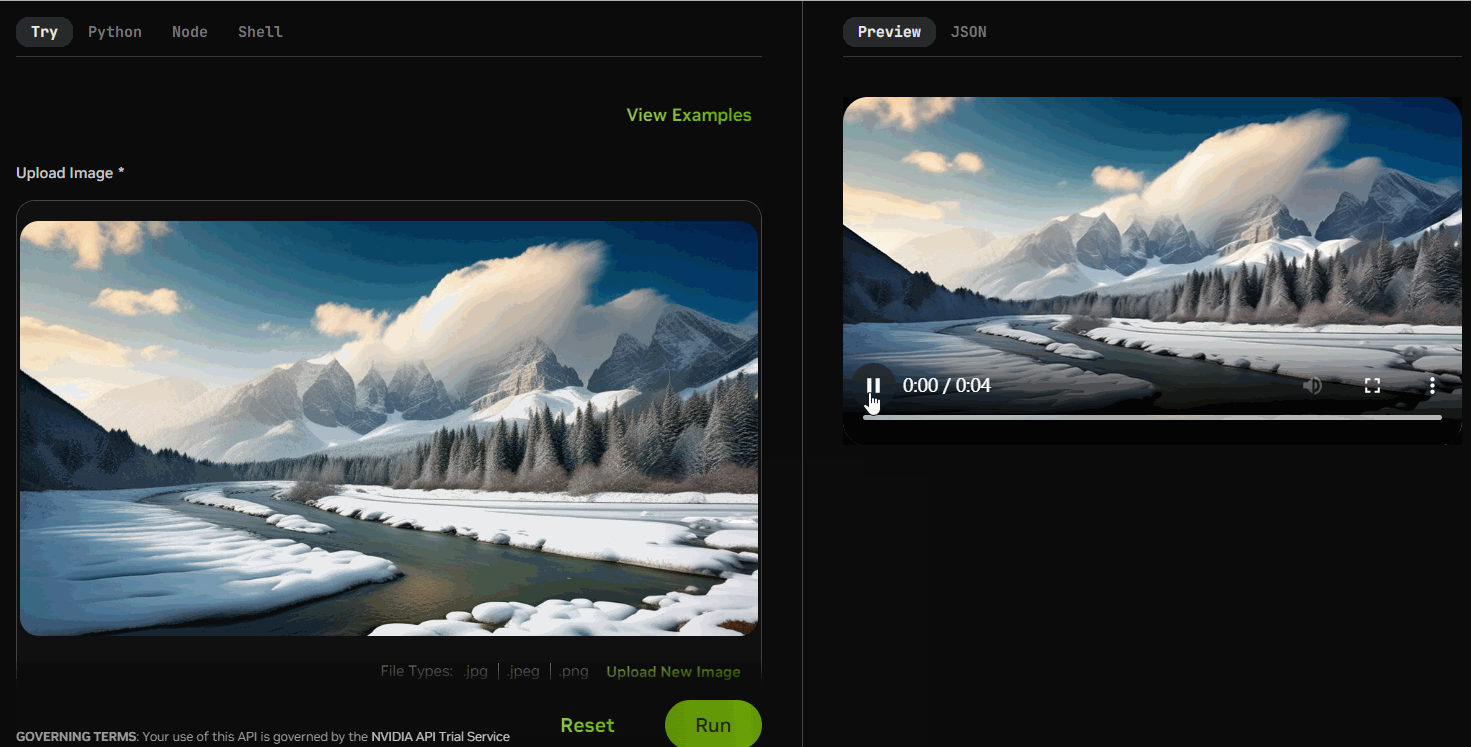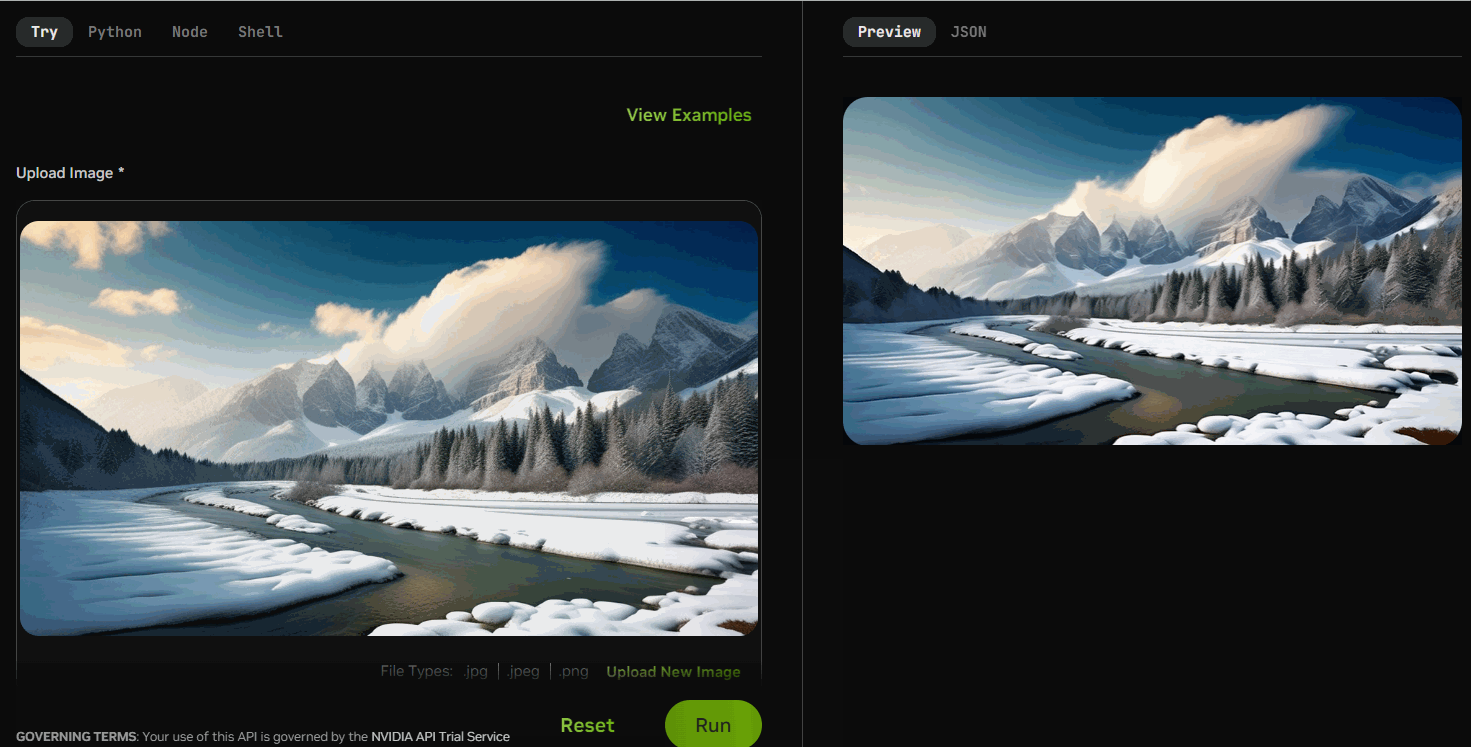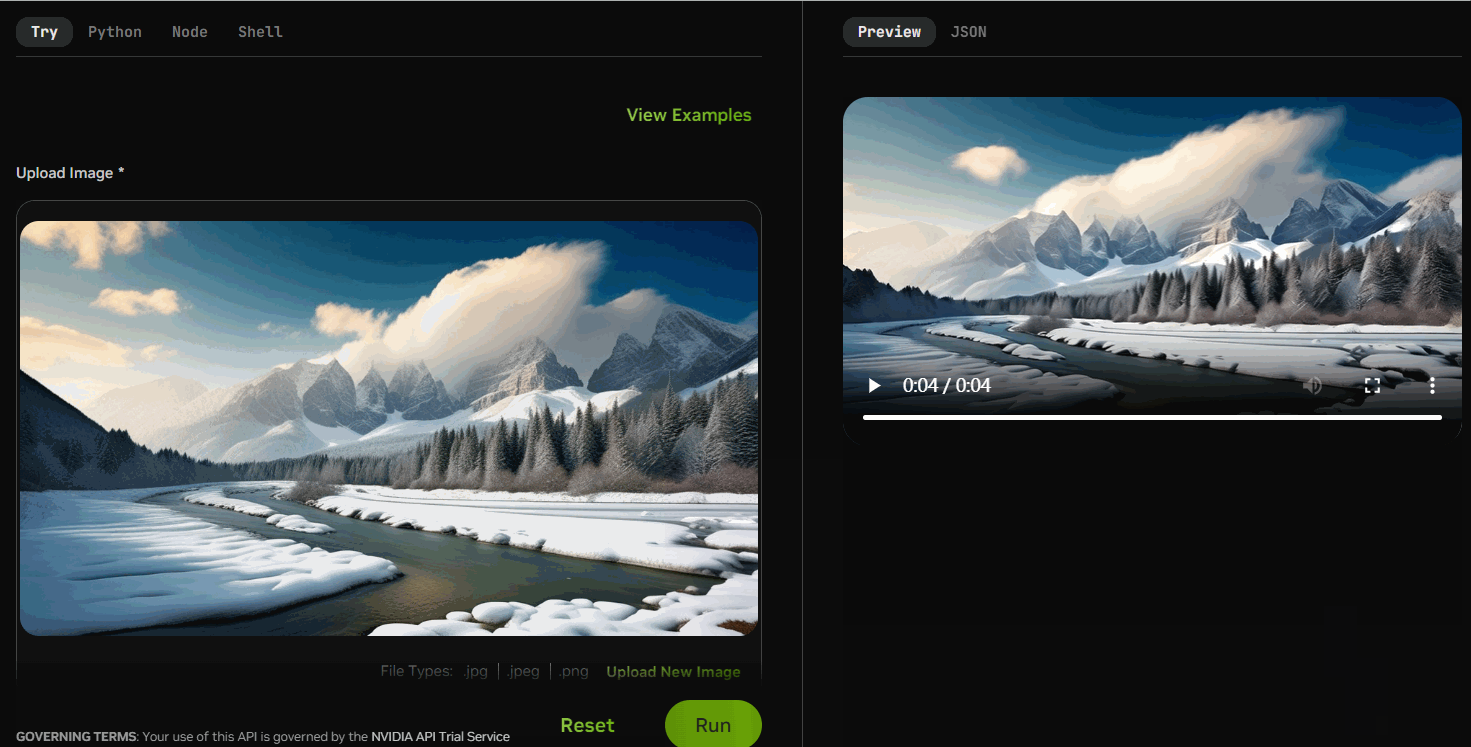
5、MistralAI的Mistral-7B-Instruct-v0.2使用
Mistral-7B-Instruct-v0.2
语言生成
NVIDIA NIM
这个LLM能够遵循指令,完成请求,并生成创造性的文本。
6、CodeLLAMA-70B的使用
聊天
代码生成
Nvidia官网人工智能大模型工具合集的案例应用
持续更新中……


![[NOIP2007 提高组] 树网的核](https://img-blog.csdnimg.cn/img_convert/cfd6909239b74b6fae3601f743fa4ba6.png)