大模型落地实战指南:从选择到训练,深度解析显卡选型、模型训练技、模型选择巧及AI未来展望—打造AI应用新篇章
0.前言大模型发展史
- 早期阶段(1950s~1980s)
在1950年代初期,人们开始尝试使用计算机处理自然语言文本。然而,由于当时的计算机处理能力非常有限,很难处理自然语言中的复杂语法和语义。随着技术的发展,自然语言处理领域在20世纪60年代和70年代取得了一些重要的进展。例如,1970年,美国宾夕法尼亚大学的Adele Goldberg和David Robson创建了一个名为Lunenfeld Project的系统,它可以进行自动翻译。同时,中国科学院自动化研究所也在20世纪70年代开始研究自然语言处理技术,主要集中在机器翻译领域。
- 中期阶段(1980s~2010s)
进入20世纪80年代和90年代,自然语言处理领域的研究更加深入。例如,1981年,Xerox PARC的研究人员Ron Kaplan和Martin Kay开发了一个名为Lexical Functional Grammar(LFG)的语法框架,这为后续的NLP研究提供了重要的理论基础。在这个阶段,NLP技术开始逐渐应用于实际场景中,如机器翻译、语音识别和文本分类等。
- 现代阶段(2010s~至今)
进入21世纪后,尤其是近年来,NLP大模型的发展迎来了革命性的突破。这主要得益于深度学习技术的快速发展和计算能力的提升。在这一阶段,预训练模型成为NLP领域的主流方法。
其中,2018年是一个重要的时间节点。在这一年,BERT模型的出现标志着NLP大模型时代的开始。BERT是一个基于Transformer结构的双向编码器模型,通过在大量文本数据上进行预训练,学习到了丰富的语言知识和上下文信息。随后,GPT系列模型也相继问世,这些模型在预训练的基础上,通过微调可以适应各种NLP任务,取得了显著的性能提升。
此外,随着计算资源的不断丰富和模型结构的优化,NLP大模型的规模也在不断扩大。从最初的几百万参数到现在的几十亿甚至上百亿参数,这些大模型在性能上不断刷新记录,推动了NLP技术的快速发展。
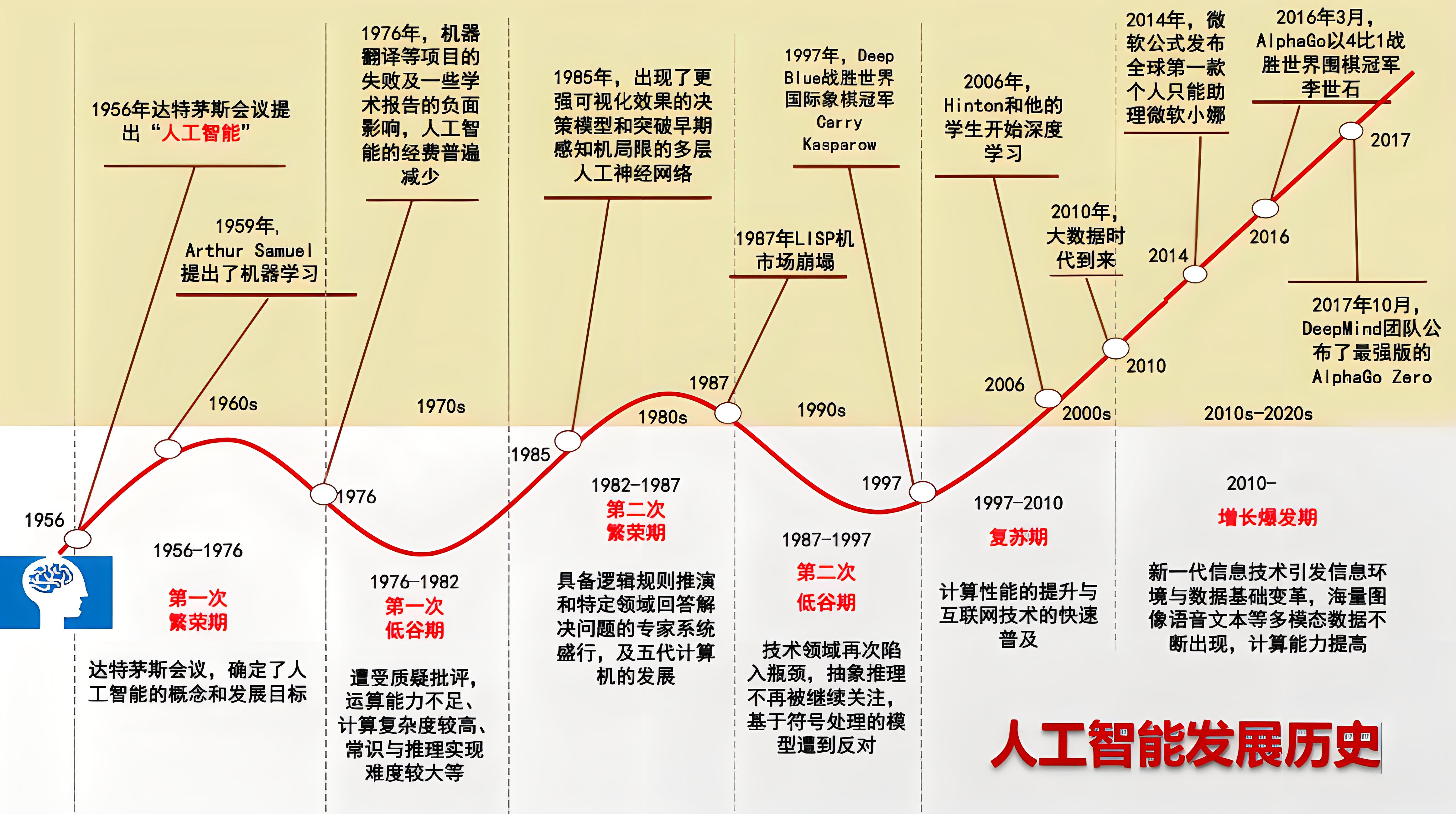

NLP领域主要模型的发展历程可以大致分为如下几个阶段:
- 早期研究阶段:侧重于设计人工编写的规则和语法,如基于规则和知识的方法等;
- 统计方法崛起:引入数学和统计方法,侧重于从大规模语料库中自动学习语言规律,如隐马尔可夫模型(HMM)、条件随机场(CRF)等;
- 深度学习革命:基于神经网络模型的方法,强调自动提取特征和端到端的训练,如循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)等;
- 预训练模型兴起:基于大规模数据和深度学习模型的预训练方法,提升了NLP任务的性能,如BERT、GPT、T5等。
可以发现,NLP领域的主要模型,从深度学习阶段开始,经过预训练模型兴起,直到如今的各种聊天大模型的爆发,NLP模型一直在向着参数量更多、通用性更强的方向发展。

-
左图介绍:语言模型(LM)是一种利用自然文本来预测词(Token)顺序的机器学习方法。大语言模型(LLM)则通常指参数数量达到亿级别的神经网络语言模型,例如:GPT-3、GPT-4、PaLM2等,仅有左下方的灰色分支为非Transformer模型,其余颜色的分支均为基于Transformer的模型
-
自然语言处理是计算机科学、人工智能和语言学的交叉领域,研究如何让计算机处理、理解和生成人类语言。目标是:能够实现人机交互、自动翻译、信息检索、情感分析等任务。应用领域包括:搜索引擎、社交媒体监测、智能客服、新闻生成等。
1.显卡选择篇-硬件配置
先说结论,大模型的训练用 4090 是不行的,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
- 看链接相关文章超详细讲解
英伟达系列显卡大解析B100、H200、L40S、A100、A800、H100、H800、V100如何选择,含架构技术和性能对比带你解决疑惑
如何选择GPU显卡,带你对比A100/H100/4090性价比、训练/推理该使用谁?
2.大模型训练流程
训练一个大模型,到底需要投入多少块,需要多少数据,训练多长时间能达到一个不错的效果? 本文引用靠谱的数据,来回答这些问题。

- 全流程训练
大模型的训练,简单来说,分为Pretraining和Finetuning微调,Pretraining需要非常多的数据和算力,Finetuning相对来说对算力的要求比较低。

LoRA:基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数P-tuning v1微调方法是将 Prompt 加入到微调过程中,只对 Prompt 部分的参数进行训练,而语言模型的参数固定不变Freeze:即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数- RLHF(OpenAI)2022.12 (Reinforcement Learning fromHuman Feedback,人类反馈强化学习)起到的作用是,通过将人类的反馈纳入训练过程,为机器提供了一种自然的、人性化的互动学习过程。
- RRHF(阿里巴巴)2023.4
- RLTF(腾讯)2023.7
- RRTF(华为)2023.7
- RLAIF(谷歌)2023.9
百度千帆大模型训练全流程Mass:

2.1 SFT监督微调&RLHF讲解
-
人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法:
-
人工智能LLM模型:奖励模型的训练、PPO 强化学习的训练、RLHF
2.2 Prompt工程原理篇
-
大语言模型的预训练[3]之Prompt Learning:Prompt Engineering、Answer engineering、Multi-prompt learning详情
-
大语言模型的预训练[4]:指示学习Instruction Learning:Entailment-oriented、PLM oriented、human-oriented以及和Prompt工程区别
-
大语言模型的预训练[5]:语境学习、上下文学习In-Context Learning:精调LLM、Prompt设计和打分函数(Scoring Function)设计以及ICL底层机制等原理详解
-
大语言模型的预训练[6]:思维链(Chain-of-thought,CoT)定义原理详解、Zero-shot CoT、Few-shot CoT 以及在LLM上应用
2.3 Prompt工程实践篇
-
Prompt进阶系列1:LangGPT(从编程语言反思LLM的结构化可复用提示设计框架)
-
Prompt进阶2:LangGPT(构建高性能Prompt策略和技巧)–最佳实践指南
-
Prompt进阶3:LangGPT(构建高性能质量Prompt策略和技巧2)–稳定高质量文案生成器
-
Prompt进阶系列4:LangGPT(构建高性能Prompt实践指南)–结构化Prompt
-
Prompt进阶系列5:LangGPT(提示链Prompt Chain)–提升模型鲁棒性
-
Prompt工程全攻略:15+Prompt框架一网打尽(BROKE、COAST、LangGPT)、学会提示词让大模型更高效
3.大模型如何选择
3.1 大模型能力对比



国内外依然有一定差距。GPT4-Turbo总分92.71分领先,高于其他国内大模型及国外大模型。其中国内最好模型文心一言4.0总分87.75分,距离GPT4-Turbo有4.96分,距离GPT4(网页)有2.61分的差距。本次最新上榜的Google开源模型的Gemma-7b-it表现不佳,可能的原因之一是训练数据中中文语料占比较少。
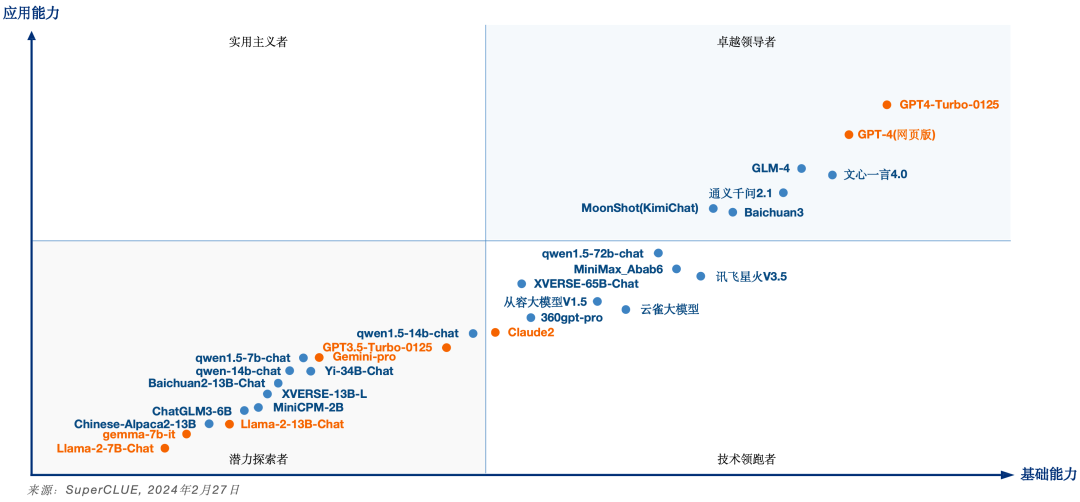
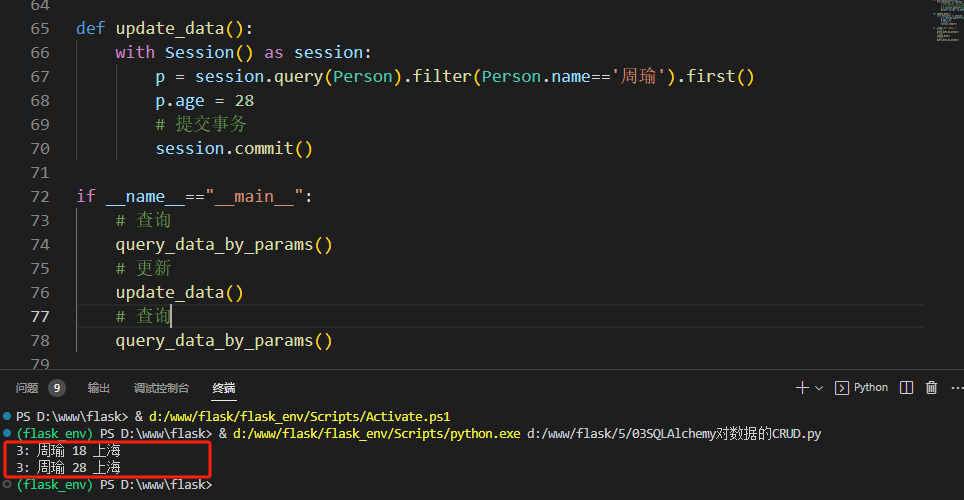
- 国内大模型历月前三甲

SuperCLUE月榜首位的大模型有5个。分别是文心一言、BlueLM、SenseChat3.0、Baichuan2-13B-Chat、360智脑。其中,百度的文心一言登顶SuperCLUE月榜的次数最多,分别在7月、11月、12月、24年2月取得了SuperCLUE最好成绩。
3.2 开源模型对比推荐
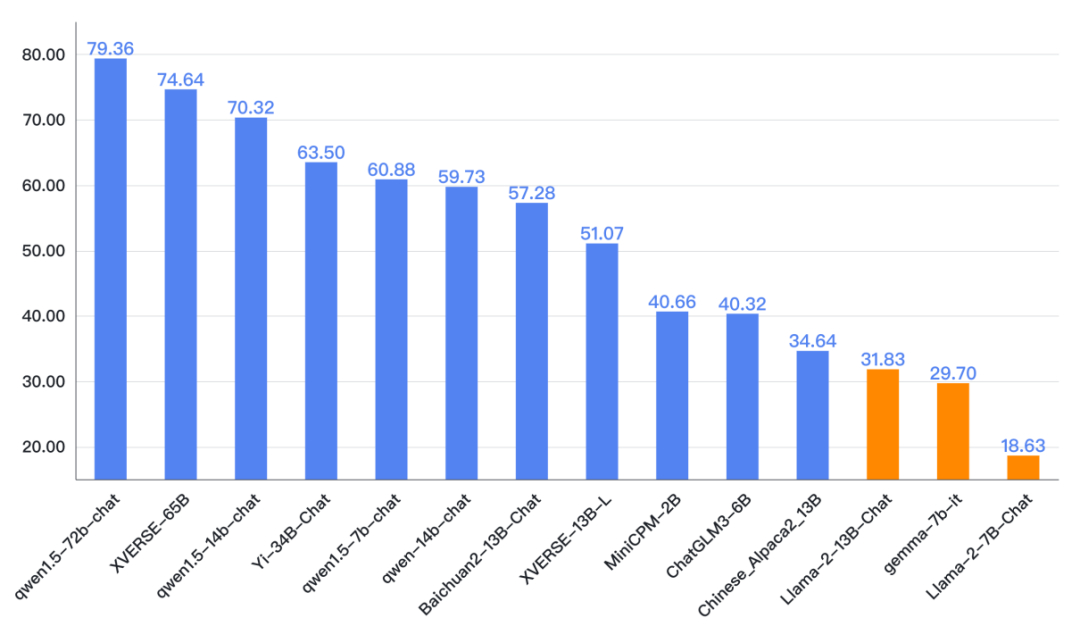
总体上大版本(如34B)的模型优于中小版本(13B、6B)的开源模型,更大的版本(如72B)的模型表现要更好。但也有小模型好于大模型的情况,如qwen1.5的70亿参数版本好于一些130亿参数的大模型,面壁智能的MiniCPM-2b好于智谱AI的ChatGLM3-6B
大厂中开源的主导力量是阿里云,在各个参数量级中国都有模型开源。但众多的创业公司是开源模型的主力,如智谱AI、百川智能、零一万物、元象科技、面壁智能。
3.2 Qwen 不同大小模型的训练、推理配置
- 通义千问开源模型配置要求
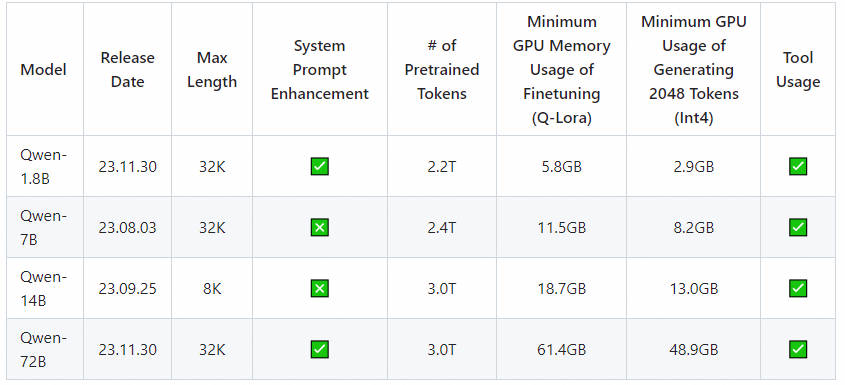
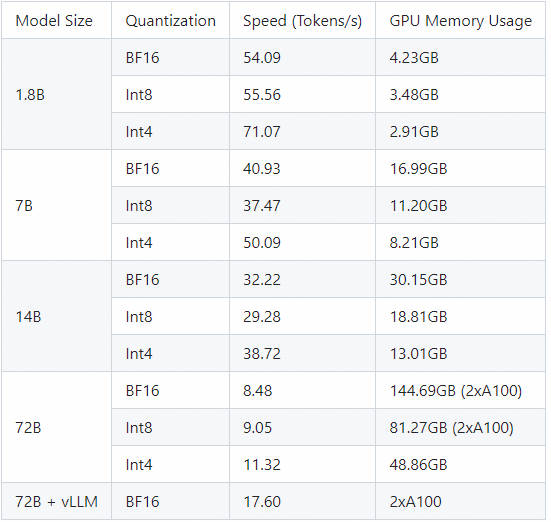
测量了使用BF16、Int8和Int4中的模型生成序列长度(Sequence Length)2048的平均推理速度和GPU内存使用情况。
- 训练所需要内存列表
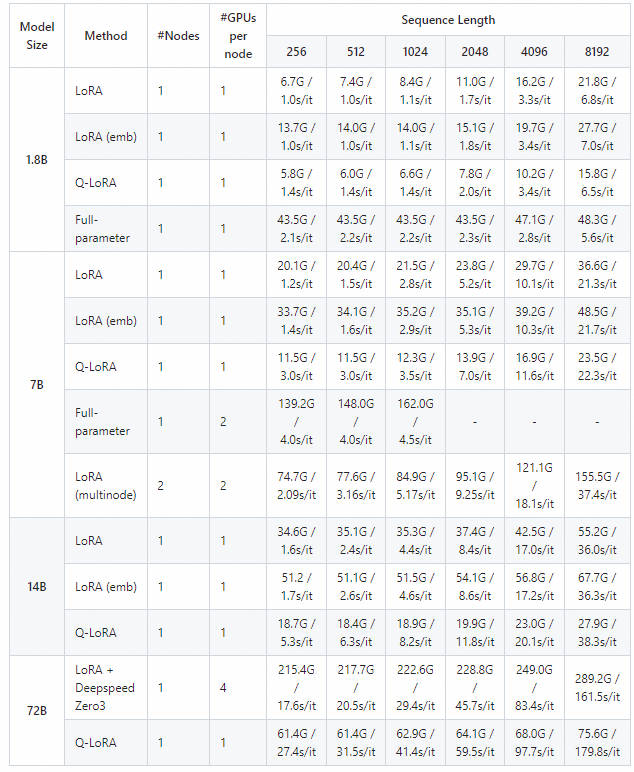
- 推理所需要内存列表
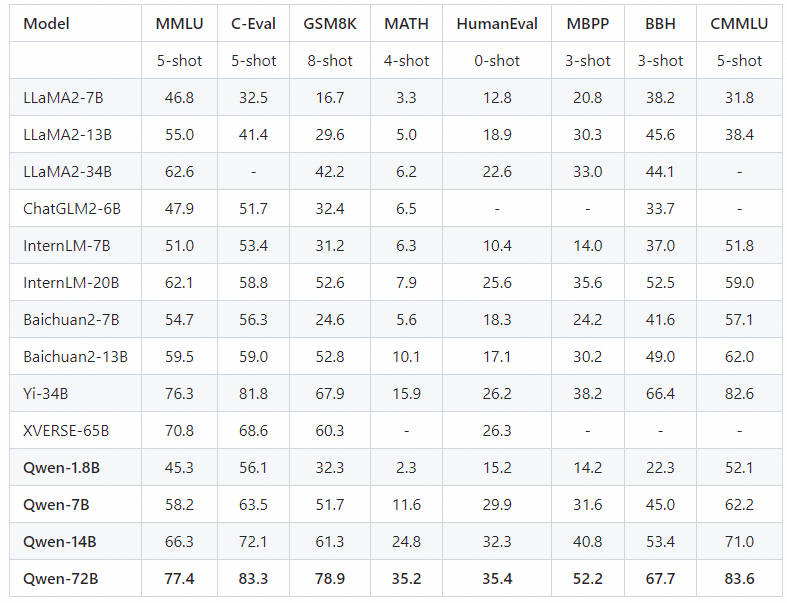
- Qwen在各个评测任务表现-整体效果不错
-
技术创新:通义千问720亿参数模型(Qwen-72B)代表了当时业界开源模型的顶级技术水平,大规模参数量意味着模型具有更强的学习能力和泛化性能,能够处理复杂多样的自然语言任务。
-
性能表现:在多个权威基准评测中取得开源模型最优成绩,证明了其卓越的技术实力和广泛的适用性,不仅超越了部分知名开源模型如Llama 2-70B,而且在与商用闭源模型的竞争中也展现出了竞争力。
-
全模态能力:开源的模型包括文本和音频等多种模态,实现了“全尺寸全模态”的开源,表明通义千问支持跨模态的应用场景,增强了其在多领域应用的潜力。
-
行业影响:阿里云推动了AI技术普惠化进程,使得学术界、企业和个人开发者可以更便捷地利用这些先进的模型进行研究和开发,降低了准入门槛,促进了AI生态的繁荣与发展。
4. 对AI看法
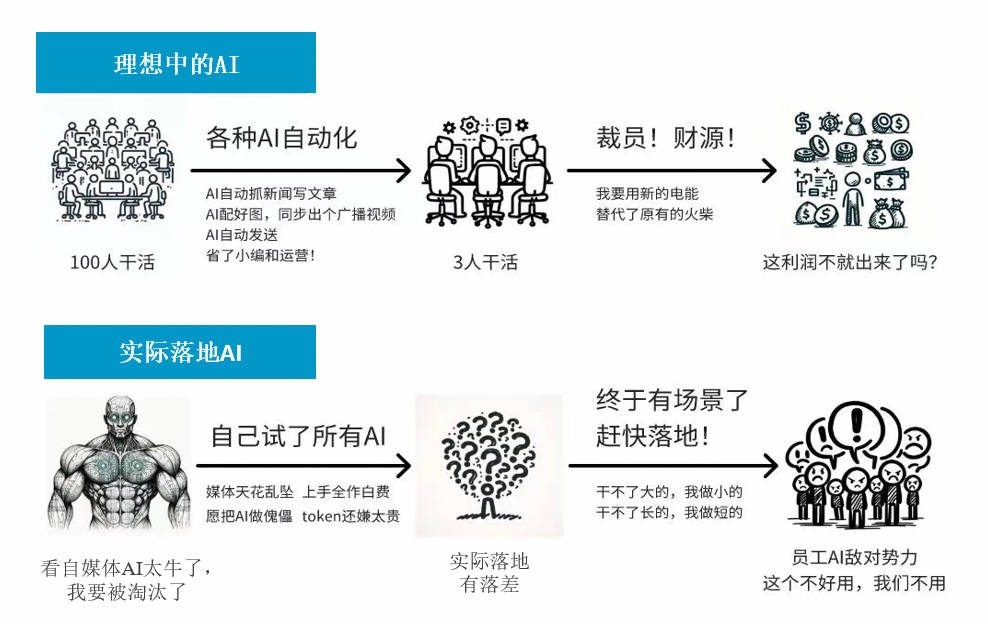
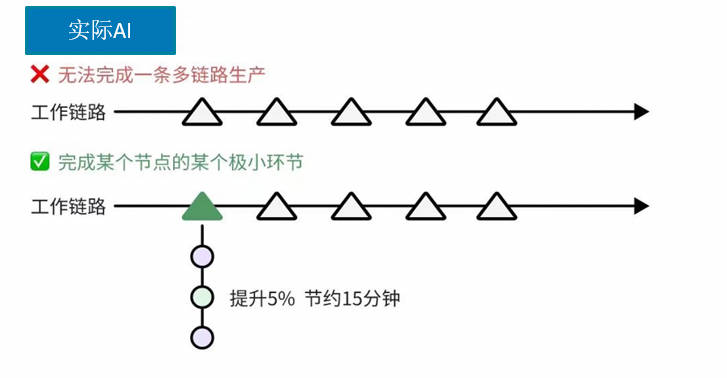
- 提高效率:
- 在多个业务领域中,AI大模型通过自动化和优化流程,显著提高了工作效率;
- 在数据分析领域,AI大模型可以自动处理和分析海量数据,提供有价值的洞察。
- 提高决策准确性
- 基于大量数据的训练,AI大模型可以提供更为准确的分析和预测,可以做出更明智的决策。
- 推动创新
- AI大模型的应用为企业带来了创新的可能性,推动了产品和服务的升级。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
参考链接:
- https://github.com/QwenLM/Qwen?tab=readme-ov-file#profiling-of-memory-and-speed
- https://github.com/Lightning-AI/lit-llama/blob/main/howto/train_redpajama.md