目录
一.概念:
1.静态顺序表:使用定长数组存储元素。
2.动态顺序表:使用动态开辟的数组存储。
二.顺序表的实现:
1.顺序表增加元素
1.检查顺序表
2.头插
3.尾插
2.顺序表删除元素
1.头删
2.尾删
3.指定位置删
3.顺序表查找元素
4.顺序表修改元素
1.指定位置修改:
顺序表的问题:
数据结构和算法概述-CSDN博客![]() https://blog.csdn.net/lh11223326/article/details/136221673
https://blog.csdn.net/lh11223326/article/details/136221673
一.概念:
顺序表在数据结构中是线性表的一种。
顺序表是用一段物理地址连续的存储单元依次存储数据的线性结构,一般情况下采用数组存储,在数组上完成数据的增删查改...........
顺序表可以分为:
1.静态顺序表:使用定长数组存储元素。
#include<stdio.h>
#define N 7
typedef int SLDataType;
typedef struct SeqList
{
SLDataType array[N];//定长数组
size_t size;//有效数据的个数
}SeqList;
2.动态顺序表:使用动态开辟的数组存储。
#include<stdio.h>
typedef struct SeqList{//顺序表的动态存储
SLDataType*array;//指向动态开辟的数组
size_t size;//有效数据个数
size_t capicity;//容量空间的大小
}SeqList;
二.顺序表的实现:
一般来说我们写大型程序的时候会把声明跟引入文件放在一个头文件中如下,创建一个SeqList.h文件把下列代码放入:
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//动态顺序表
typedef int SLDataType;typedef struct SeqList {SLDataType* a;//去堆上动态开辟,用来指向动态开辟的数组int size;//存储的有效数据个数int capacity;//空间大小
}SL;//对顺序表进行管理:增删查改
void SLInit(SL *ps);//顺序表初始化
void SLDestroy(SL *ps);//顺序表销毁
void SLPrint(SL* ps);
void SLCheckCapacity(SL* ps);//头插头删,尾插尾删
void SLPushBack(SL* ps, SLDataType x);//后插
void SLPopBack(SL* ps);//后删
void SLPushFront(SL* ps, SLDataType x);//头插
void SLPopFront(SL* ps);//头删//返回下标,没有找到返回-1
//找数据
int SLFind(SL* ps, SLDataType x);
//在指定位置插入x
void SLInsert(SL* ps,int pos,SLDataType x );
//删除指定位置的值
void SLErase(SL* ps, int pos);
//修改坐标处的元素
void SLModify(SL* ps, int pos, SLDataType x);1.顺序表增加元素
在增加元素之前需要初始化顺序表,此时需要使用malloc创建一块空间,代码如下:
void SLInit(SL *ps) {//顺序表的初始化assert(ps);ps->a = (SLDataType*)malloc(sizeof(SLDataType)*4);if (ps->a==NULL) {perror("malloc failed");exit(-1);//终止程序}ps->size = 0;ps->capacity = 4;
}1.检查顺序表
如果顺序表满了就需要扩容............
void SLCheckCapacity(SL* ps) {assert(ps);//满了要扩容if (ps->size == ps->capacity) {SLDataType* tmp = (SLDataType*)realloc(ps->a, ps->capacity * 2 * (sizeof(SLDataType)));if (tmp == NULL) {perror("realloc failed");exit(-1);}ps->a = tmp;ps->capacity *= 2;}
}2.头插
在头部插入数据之前需要把全部数据都往后移动一位.......
void SLPushFront(SL* ps, SLDataType x) {assert(ps);SLCheckCapacity(ps);//挪动数据int end = ps->size - 1;while (end >= 0) {ps->a[end + 1] = ps->a[end];--end;}ps->a[0] = x;ps->size++;
}3.尾插
在末尾插入数据之前检查一下,如果有数据就是满了先扩容再插入......
void SLPushBack(SL* ps, SLDataType x) {assert(ps);SLCheckCapacity(ps);ps->a[ps->size] = x;ps->size++;
}2.顺序表删除元素
1.头删
void SLPopFront(SL* ps) {assert(ps);assert(ps->size > 0);int begin = 1;while (begin < ps->size) {ps->a[begin - 1] = ps->a[begin];++begin;}ps->size--;
}2.尾删
直接把有效数据个数减一就行了...........
void SLPopBack(SL* ps) {assert(ps);assert(ps->size > 0);ps->size--;
}3.指定位置删
把数据删除之后把数据都移前面补全.........
void SLErase(SL* ps, int pos) {assert(ps);assert(pos >= 0 && pos < ps->size);int begin = pos + 1;while (begin < ps->size) {ps->a[begin - 1] = ps->a[begin];++begin;}ps->size--;
}3.顺序表查找元素
把每个数据都比对一遍然后返回下标.........
int SLFind(SL* ps, SLDataType x) {assert(ps);for (int i = 0; i < ps->size; i++) {if (ps->a[i] == x) {return i;}}return -1;
}4.顺序表修改元素
代码的位置是用户指定下标位置的修改:
void SLModify(SL* ps, int pos, SLDataType x) {assert(ps);assert(pos >= 0 && pos < ps->size);ps->a[pos] = x;
}1.指定位置修改:
从指定位置的最后面把每个数据都后移一位,不要从前面往后面移,要从后往后,移动完数据之后就可以在指定位置添加了......
void SLInsert(SL* ps, int pos, SLDataType x) {assert(ps);assert(pos >= 0 && pos <= ps->size);SLCheckCapacity(ps);int end = ps->size - 1;while (end>=pos) {ps->a[end + 1] = ps->a[end];--end;}ps->a[pos] = x;ps->size++;
}如下是SeqList.c中全部实现函数代码:
#include"SeqList.h"
void SLInit(SL *ps) {//顺序表的初始化assert(ps);ps->a = (SLDataType*)malloc(sizeof(SLDataType)*4);if (ps->a==NULL) {perror("malloc failed");exit(-1);//终止程序}ps->size = 0;ps->capacity = 4;
}
void SLDestroy(SL *ps)//顺序表的销毁
{assert(ps);free(ps->a);ps->a = NULL;ps->capacity = ps->size = 0;
}void SLPrint(SL* ps) {assert(ps);for (int i = 0; i < ps->size; i++) {printf("%d ", ps->a[i]);}printf("\n");
}void SLCheckCapacity(SL* ps) {assert(ps);//满了要扩容if (ps->size == ps->capacity) {SLDataType* tmp = (SLDataType*)realloc(ps->a, ps->capacity * 2 * (sizeof(SLDataType)));if (tmp == NULL) {perror("realloc failed");exit(-1);}ps->a = tmp;ps->capacity *= 2;}
}void SLPushBack(SL* ps, SLDataType x) {assert(ps);/*SLCheckCapacity(ps);ps->a[ps->size] = x;ps->size++;*/SLInsert(ps, ps->size, x);
}void SLPopBack(SL* ps) {//assert(ps);//直接报错 暴力检查assert(ps->size > 0);ps->size--;//就是无效删除退出 检查/*if (ps->size == 0) {return;}*/
}
void SLPushFront(SL* ps, SLDataType x) {assert(ps);SLInsert(ps, 0, x);
}
void SLPopFront(SL* ps) {assert(ps);SLErase(ps, ps->size-1);
}int SLFind(SL* ps, SLDataType x) {assert(ps);for (int i = 0; i < ps->size; i++) {if (ps->a[i] == x) {return i;}}return -1;
}//在指定位置插入x
void SLInsert(SL* ps, int pos, SLDataType x) {assert(ps);assert(pos >= 0 && pos <= ps->size);SLCheckCapacity(ps);int end = ps->size - 1;while (end>=pos) {ps->a[end + 1] = ps->a[end];--end;}ps->a[pos] = x;ps->size++;
}
//删除指定位置的值
void SLErase(SL* ps, int pos) {assert(ps);assert(pos >= 0 && pos < ps->size);int begin = pos + 1;while (begin < ps->size) {ps->a[begin - 1] = ps->a[begin];++begin;}ps->size--;
}void SLModify(SL* ps, int pos, SLDataType x) {assert(ps);assert(pos >= 0 && pos < ps->size);ps->a[pos] = x;
}最后可以自行设计一个界面:
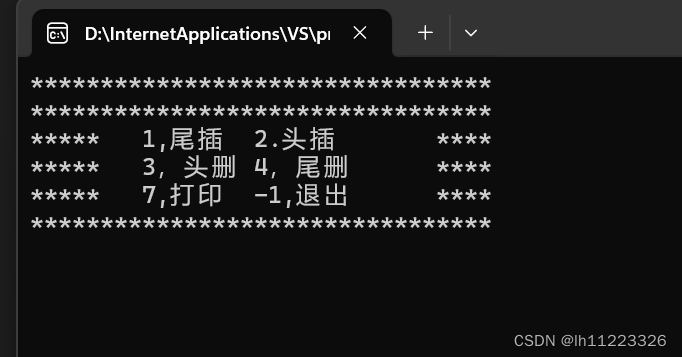
顺序表的问题:
- 中间/头部的插入删除,时间复杂度为O(N).
- 增容需要申请新空间,拷贝数据,释放旧空间,会有不小的消耗。
- 增容一般是呈2倍的增长,势必会有一定的空间浪费,如容量为100,满了以后增容到200,再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。



![[GXYCTF2019]StrongestMind](https://img-blog.csdnimg.cn/direct/ed98afb0d740401f8f8a5ae40dc7aa62.png)