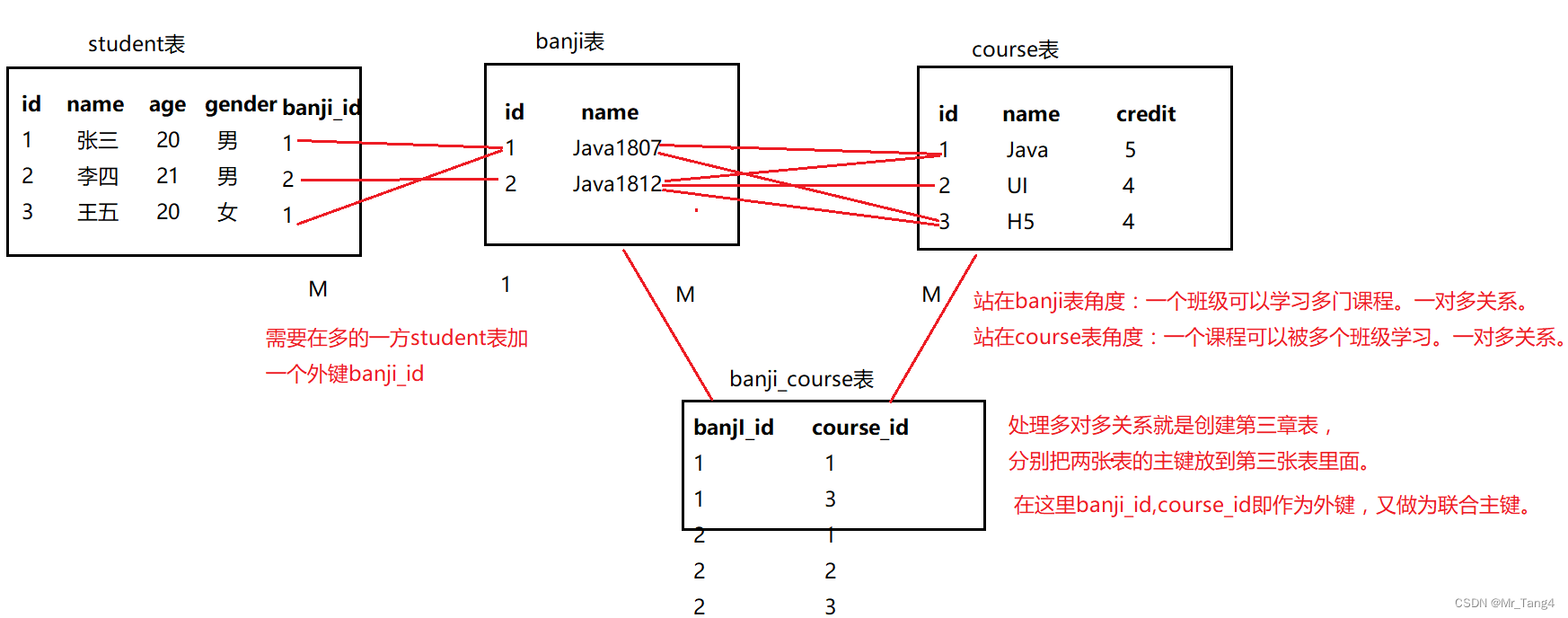
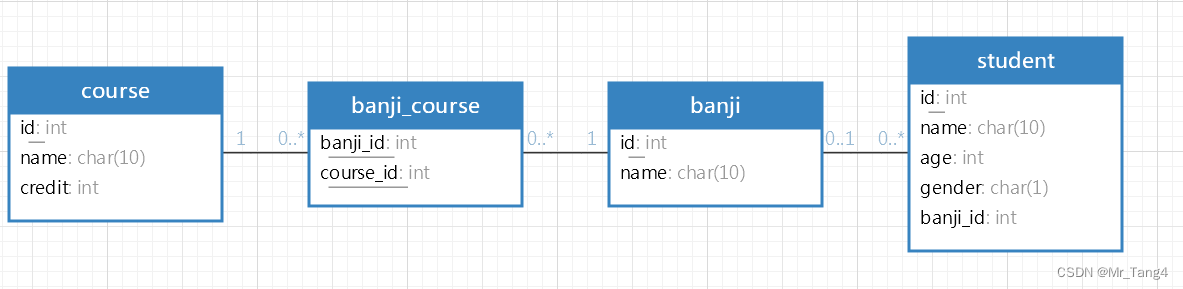
1 多表
学生表、班级表、课程表、班级课程表
关系型数据库: MySql、SqlServer、Oracle
相同的数据出现多次绝不是一件好事,这是关系数据库设计的基础。关系表的设计就是要把信息分解成多个表,一个数据一个表,各表通过某些共同的值互相连接,所以才叫关系数据库。
将数据存储到多个表能更有效的存储,更方便的处理,但这些好处是有代价的:如果数据存储在多个表中,怎么用一条SELECT语句就检索出数据呢?答案是使用:子查询、联结
非关系型数据库: Redis ,MongoDB 速度非常快(日志信息)
可以理解为一个大的Map结构
-- 多对多
-- 班级表
CREATE TABLE banji(id INT PRIMARY KEY AUTO_INCREMENT,`name` CHAR(10) NOT NULL
);INSERT INTO banji(`name`) VALUES ('Java1807'), ('Java1812');-- 学生表
CREATE TABLE student(id INT PRIMARY KEY AUTO_INCREMENT,`name` CHAR(10) NOT NULL,age INT,gender CHAR(1),banji_id INT,FOREIGN KEY(banji_id) REFERENCES banji(id)
);INSERT INTO student(`name`,age,gender,banji_id)
VALUES('张三',23,"男",1),('李四',21,'男',2),('王五',20,'女',1);-- INSERT INTO student(`name`,age,gender,banji_id) VALUES('张三',23,"男",3);-- 课程表
CREATE TABLE course(id INT PRIMARY KEY AUTO_INCREMENT,`name` CHAR(10) NOT NULL,credit INT COMMENT '学分'
);
INSERT INTO course(`name`,credit) VALUES('Java',5),('UI',4),('H5',4);-- 班级课程表
CREATE TABLE banji_course(-- id INT PRIMARY KEY AUTO_INCREMENT,banji_id INT,course_id INT,PRIMARY KEY (banji_id,course_id),-- 联合主键FOREIGN KEY(banji_id) REFERENCES banji(id),FOREIGN KEY(course_id) REFERENCES course(id)
); INSERT INTO banji_course(banji_id, course_id) VALUES(1,1),(1,3),(2,1),(2,2),(2,3);-- 子查询:嵌套查询,一个查询语句是另一个查询语句的条件
-- 查询班级是Java1812班所有学生信息
-- SELECT * FROM student WHERE banji_id = 2;
SELECT id FROM banji WHERE `name`='Java1812';
SELECT * FROM student WHERE banji_id = (SELECT id FROM banji WHERE `name`='Java1807');-- 班级是java1807班或者java1812班所有学生信息SELECT * FROM student WHERE banji_id=1 OR banji_id=2;
SELECT * FROM student WHERE banji_id IN(1,2);
SELECT id FROM banji WHERE `name`='Java1807' OR `name`='Java1812';
-- ① 不行
SELECT * FROM student WHERE banji_id = (SELECT id FROM banji WHERE `name`='Java1807' OR `name`='Java1812');
-- ② 可以 太长
SELECT * FROM student WHERE banji_id = (SELECT id FROM banji WHERE `name`='Java1807') OR
banji_id = (SELECT id FROM banji WHERE `name`='Java1812');
-- ③ OK
SELECT * FROM student WHERE banji_id IN (SELECT id FROM banji WHERE `name`='Java1807' OR `name`='Java1812');-- 计算字段使用子查询:班级id 班级名字 班级人数
-- 执行这条查询遵循下面的步骤:
-- 1、从banji表检索班级列表
-- 2、对检索出的每个banji,统计其在student表中的数量
-- 班级id 班级名字 班级人数
-- 数据库 >>> ExcelSELECT id,`name`,(SELECT COUNT(*)FROM student WHERE student.banji_id = banji.id) AS total_count
FROM banji;SELECT id,`name`,(SELECT COUNT(*)FROM studentWHERE student.banji_id=banji.id) AS total_count
FROM banji
ORDER BY `name` DESC;
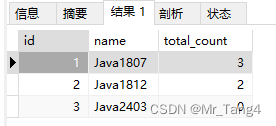
total_count是一个计算字段,它是由括号中的子查询建立的,该子查询对检索出的每个banji执行一次
总结:
1、“=”:要求子查询只有一个结果。 “in”:子查询可以有多个结果。
2、子查询的SELECT语句只能查询单个列,企图检索多个列将返回错误。
3、能嵌套的子查询的数目没有限制,不过在实际使用时由于性能的限制,不能嵌套太多的子查询。
子查询也可以使用下面的连接来实现
2 等值连接
从左表中取出每一条记录,去右表中与所有的记录进行匹配:匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留
笛卡尔积:
由没有联结条件的表关系返回的结果为笛卡尔积。检索出的行的数目将时第一个表中的行数乘以第二个表中的行数。通俗的说就是查询所得的结果行数是两张表行数的乘积。
返回笛卡尔积的联结,也称为叉联结cross join。
-- 笛卡尔积 等值连接
SELECT *
FROM student,banji;SELECT *
FROM student,banji
WHERE student.banji_id=banji.id;
注意:联结查询非常消耗资源,因此应该注意,不要联结不必要的表。联结的表越多,性能下降越厉害。
3 内连接
内连接有两种写法,一种是inner join,另一种是join,这两种写法都是一样的,可以理解为join是inner join的缩写。还可以看出,等值连接和内连接的效果一样,但是开发中建议使用内连接
-- 内连接SELECT *
FROM student INNER JOIN banji;-- 与笛卡尔积效果一样SELECT *
FROM student AS s INNER JOIN banji AS b-- 与等值连接效果一样
ON s.banji_id=b.id;-- 查询的结果也是一张表 分组?? 按班级分组 数数量 刚才的统计班级人数SELECT id, -- 子查询`name`,(SELECT COUNT(*)FROM student WHERE student.banji_id=banji.id) AS total_count
FROM banji;SELECT b.id,b.`name`,COUNT(*) AS total_count -- 内连接结果 作为新表,在新表里用GROUP
FROM student AS s INNER JOIN banji AS b
ON s.banji_id=b.id
GROUP BY b.id;-- 分组SELECT b.id,b.`name`
FROM student AS s INNER JOIN banji AS b
ON s.banji_id=b.id
GROUP BY b.id;-- 分组-- 学生id 学生姓名 班级名称
SELECT s.id AS '学生ID',s.`name` AS '学生姓名',b.`name` AS '班级名称'
FROM student AS s INNER JOIN banji AS b-- 与内连接效果一样
ON s.banji_id=b.id;-- 学生id 学生姓名 班级名称 课程名称 学分
SELECT *
FROM student AS s INNER JOIN banji AS b-- 与内连接效果一样
ON s.banji_id=b.id
INNER JOIN banji_course AS bc
ON b.id=bc.banji_id;-- 内连接
SELECT s.id AS '学生ID',s.`name` AS '学生姓名',b.`name` AS '班级名称',c.`name` AS '课程名称',c.credit AS '学分'
FROM student AS s INNER JOIN banji AS b-- 与内连接效果一样
ON s.banji_id=b.id
INNER JOIN banji_course AS bc
ON b.id=bc.banji_id
INNER JOIN course AS c
ON bc.course_id=c.id
ORDER BY s.id;
-- 把inner join之后查询的结果当成一张表来使用, 在这个结果集里面根据班级id统计每个班级下面学生数量。
-- 等值连接(没有WHERE 就是笛卡尔积)
SELECT s.id AS '学生ID',s.`name` AS '学生姓名',b.`name` AS '班级名称',c.`name` AS '课程名称',c.credit AS '学分'
FROM student s,banji b,banji_course bc,course c
WHERE s.banji_id=b.id AND b.id=bc.banji_id AND bc.course_id=c.id
ORDER BY s.id;
总结:多表查询主要是注意下面两点
1、整个查询涉及到几张表,涉及到几张表就连接这几张表。
2、如果涉及到这几张表的关系搞不清楚,画一下ER图,弄清楚表和表之间的关系(就是根据外键建立的关系)
4 inner join on、left join on、right join on区别
inner join on 只有左右两个表有关联的才查询出来
left join on 左表中都显示出来,右表没有显示空
right join on 右表都显示,左表没有显示空
左连接,也成为左外连接:从左表那里返回所有的行,即使在右表中没有匹配的行.left join on
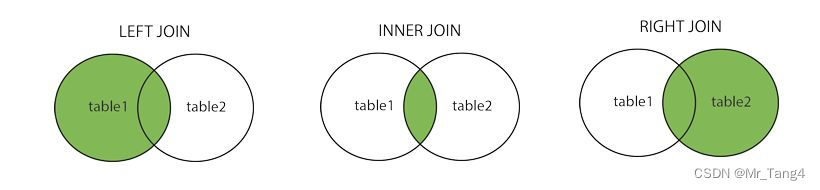
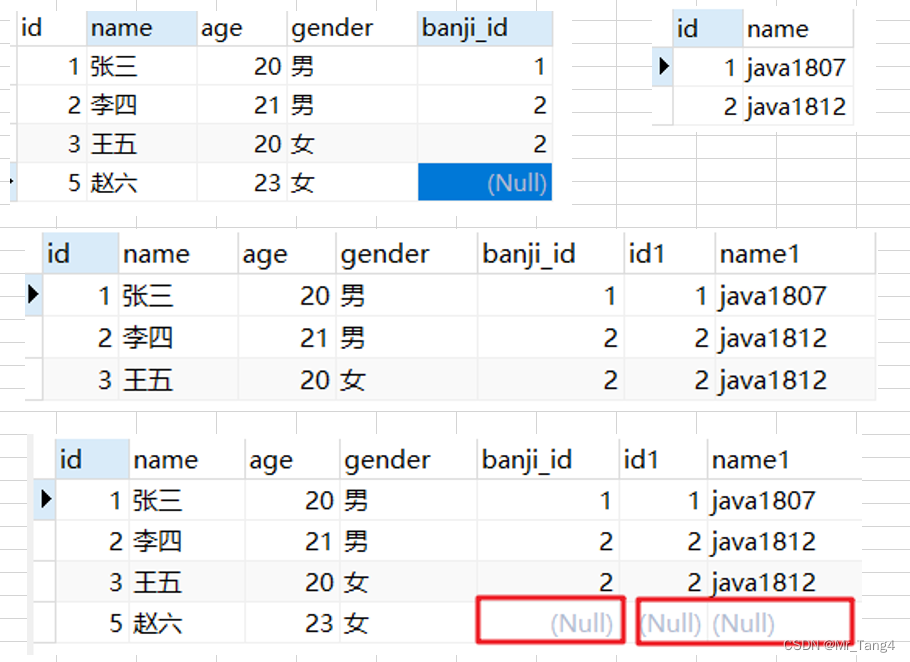
-- inner join on、left join on、right join on区别SELECT *
FROM student AS s INNER JOIN banji AS b
ON s.banji_id=b.id;SELECT *
FROM student AS s LEFT JOIN banji AS b
ON s.banji_id=b.id;SELECT *
FROM student AS s RIGHT JOIN banji AS b
ON s.banji_id=b.id;
5 模糊查找
语法形式:字段 like '要查找字符'
说明:
1、like模糊查找用于对字符类型的字段进行字符匹配查找。
2、要查找的字符中,有两个特殊含义的字符:% , _:
2.1: %含义是:代表0或多个的任意字符
2.2: _含义是:代表1个任意字符
3、语法:like '%关键字%'
SELECT * FROM student WHERE `name` LIKE '张%'; -- 以张开头
SELECT * FROM student WHERE `name` LIKE '张_'; -- 以张开头,而且名字是两个字
SELECT * FROM student WHERE `name` LIKE '%张%'; -- 名字里面只要有张就可以
注意: NULL
通配符%看起来像是可以匹配任何东西,但有个例外,这就是NULL,
SELECT * FROM student WHERE `name` LIKE '%';
不会匹配name为NULL的行
-- 模糊查找
SELECT * FROM student WHERE `name` = '张三';
SELECT * FROM student WHERE `name` LIKE '%张%';
SELECT * FROM student WHERE `name` LIKE '张%';
SELECT * FROM student WHERE `name` LIKE '张_';
SELECT * FROM student WHERE `name` LIKE '%张';
SELECT * FROM student WHERE `name` LIKE '%';-- 把id是1的学生,名字改为:张三,age:24,gender:女UPDATE student SET age = 24,name='张三三' WHERE id=1;
注意:(也是面试题)
SQL的通配符很有用,但这种功能是有代价的,即通配符搜索要消耗更长的处理时间,使用通配符的技巧:
1、不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
2、在确实需要使用通配符时,也尽量不要把它们用在搜索模式的开始处 '%张'。把通配符置于开始处,搜索起来是最慢的。