目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
(2)目的
(3)结论
(4)主要实现手段
4.1 前置知识
4.2 基于GPU的实现
4.2.1 GPU简介
4.2.2 优化方法
4.2.3 性能评估
4.3 FPGA实现
4.3.1 FPGA架构
4.3.2 优化方法
4.3.3 性能评估
4.4 ASIC实现
(5)实验结果
5.1 比较基准
5.2 GPU性能和能效比分析
5.3 FPGA性能和能效比分析
5.4 ASIC性能和能效比分析
(6)问题记录
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
四、Why:为什么看这篇文献 (方便再次搜索)
五、Summary:文献方向归纳 (方便分类管理)
一、Article:文献出处(方便再次搜索)
(1)作者
- Wesson Altoyan, Juan J. Alonso(斯坦福大学)
(2)文献题目
- Accelerating the Lattice Boltzmann Method
(3)文献时间
- 2023 IEEE Aerospace Conference
(4)引用
- Altoyan, Wesson and Juan J. Alonso. “Accelerating the Lattice Boltzmann Method.” 2023 IEEE Aerospace Conference (2023): 1-20.
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
传统的CFD模拟依赖于纳维-斯托克斯(NS)方程,这些方程虽然能提供准确的模拟结果,但需要付出巨大的计算时间和能源成本。为了降低成本,人们转向数值模型,但这些模型通常需要在准确性和计算资源之间做出妥协。而LBM是一种基于动力学理论的统计方法,它通过在微观层面上平均流体粒子的相互作用来在宏观层面上描述流体行为。LBM通过介观方法恢复NS方程,提供了一种在成本和模型保真度之间取得平衡的方法。
(2)目的
在CFD领域,由于提取复杂任务的细粒度并行性比较困难、内存带宽瓶颈,以及求解器开发人员现在需显式管理复杂内存层次结构等额外负担,计算能力提升放缓。然而,对于需要多次评估的应用,对流体模拟的速度要求仍在不断增加。对于不易并行化的算法,即使使用特定于CFD领域的LBM替代算法在应用到GPU上仍然充满挑战,包括:内存带宽瓶颈,功率限制,功率效率。
-
硬件加速器的局限性:尽管LBM在理论上具有优势,但现有的硬件加速器(如GPU和FPGA)在实现LBM时仍面临性能瓶颈。
-
ASIC加速器的可行性研究:研究者进行了初步研究,评估了一种ASIC加速器的可行性,这种加速器专门为加速基于LBM的模拟而设计。
(3)结论
- 本文提供了LBM在GPU、FPGA和ASIC上的实现细节,包括算法的数学描述、硬件平台的概述、以及优化技术的应用,比较了LBM在不同硬件平台上的性能,包括计算能力、内存带宽、功耗等方面。
- 本文提出了一种专为LBM设计的新型硬件加速器,旨在结合LBM的优越算法性能和定制硬件的能效,实现前所未有的性能-功耗增益。就仿真结果而言,ASIC加速器可能在性能上提供显著提升,相对GPU可能达到33倍的性能改善。
(4)主要实现手段
4.1 前置知识
4.1.1 CFD简介
1970s出现了微处理器,但是CFD比其早30年出现。主要是在二战期间,空气动力学中的NS方程的求解会影响炮弹的爆炸精确度。但由于这些方程比较复杂,除了最简单的情况外,无法进行解析求解。因此,采用数值方法,将问题域离散化并近似求解。CFD用于模拟流体流动的三种主要数值方法如下,它们在准确性、计算资源需求和模拟时间之间进行权衡:
- 直接数值模拟(DNS):高精度模拟方法,它能够模拟流体流动的所有尺度,通过精确计算空间和时间上的流动变化来实现。这种方法提供了非常准确的结果,但代价是极高的计算时间和资源消耗。因此,DNS通常只用于资金充足的科学研究项目。
- 大涡模拟(LES):它在计算成本和准确性之间取得了平衡。LES通过使用数学模型来近似模拟小尺度的湍流,只解决更重要的大尺度湍流问题。这种方法相比于DNS,能够在保持相对较高准确性的同时,显著降低计算成本。
- 雷诺平均纳维-斯托克斯(RANS)模拟:它优先考虑成本节约而不是准确性。使用模型技术来表示所有尺度的湍流,这使得它成为CFD领域中最快和最受欢迎的方法。RANS通过平均化流体的速度和压力等物理量来简化问题,从而减少了计算的复杂性。
4.1.2 LBM简介
尽管完全替代NS方程不可能,但已经出现了适用于特定CFD类别的替代算法。例如,晶格玻尔兹曼方法(LBM)因其离散性、高局部性和显式计算方案,适用于并行处理器,正在逐渐流行。LBM是一种用于模拟流体动力学行为的计算模型。它基于统计力学中的玻尔兹曼方程,通过在离散的格子(lattice)上模拟粒子的分布函数来近似连续介质的宏观流动。LBM的核心思想是将流体视为大量粒子的集合,这些粒子在格子上按照特定的规则移动和碰撞。
LBM是一种高效的DNS方法,能够在相对较低的计算成本下提供高精度。LBM主要针对固定密度的不可压缩流体流动问题,适用于广泛的行业,尤其是非航空航天领域。LBM的优势在于其离散方法的本质,消除了Navier-Stokes所需的离散化步骤,其算法的核心部分是局部的,这限制了不同网格单元之间的同步需求,使得并行计算成为可能。LBM有望将不可压缩流体流动模拟提升到一个新的水平,但具体取决于是否存在一个高度并行且节能的硬件。
tips:
- 不可压缩的流动,也称等容流,理想情况,常用于简化理论分析。它并不意味着流体本身是不可压缩的,而是意味着密度在随着流速移动的一批流体中保持恒定。确切地说, 是流体在一个大时间段后某一时刻的状态或者趋于稳定的状态。
- 通常,气体可压缩地流动,不管气体和空间的初始容积有多大,它都占据整个限制它的任何封闭空间。这一性质是气体所特有的。像液体的情况一样,对气体的缓慢流动采用不可压缩的假设可以获得良好的近似结果。
4.1.3 ASIC简介
相比于GPU,ASIC具有以下优势和劣势:
优势:
-
专门定制:ASIC加速器是为特定应用或问题量身定制的,这意味着它们可以针对特定任务进行优化,从而提供更高的性能和能效。
-
高效率:ASIC加速器通常能够以更低的功耗实现更高的计算效率,因为它们仅包含执行特定任务所需的最小硬件组件。ASIC可以针对数据流和操作进行优化,从而实现高吞吐量和低延迟,这对于数据密集型应用(如CFD模拟)非常重要。ASIC可以设计为具有优化的内存访问模式,减少内存瓶颈,提高数据传输效率。
-
可扩展性:ASIC可以通过多芯片系统实现弱可扩展性,支持更大问题的解决,而性能开销较小。
劣势:
-
灵活性差:与通用的GPU相比,ASIC加速器的灵活性较低。它们不能轻易地重新配置或适应新的任务或算法。一旦ASIC加速器被制造出来,对其进行维护和更新非常困难,因为硬件是固定的。
-
开发成本高/周期长:ASIC的设计、制造和测试过程复杂且成本高昂,这通常使得它们只适用于大规模部署或长期项目。ASIC的开发周期通常较长,从设计到实际部署可能需要数月甚至数年时间。
-
市场支持有限:ASIC加速器可能不会得到广泛的市场支持,因为它们是为特定应用设计的,不像GPU那样有大量的开发者和用户社区。
总的来说,ASIC加速器在特定应用领域提供了性能和能效上的优势,但它们的高成本、长开发周期和差的灵活性限制了它们的广泛应用。相比之下,GPU加速器提供了更高的灵活性和更快的开发周期,但可能在特定任务上的性能不如ASIC。选择哪种加速器取决于应用的具体需求、预算和时间框架。
4.2 基于GPU的实现
4.2.1 GPU简介
GPU架构:GPU由多个流式多处理器(Streaming Multiprocessors,简称SMs)组成,每个SM包含专用的调度器和硬件资源,能够独立运行。SM内部包含计算核心、寄存器、片上共享内存(on-chip shared memory)和只读L1缓存。GPU的主内存(device memory或global memory)是高带宽的外部存储,通过统一的L2缓存为所有SM提供服务。
CUDA框架:开发者使用CUDA(Compute Unified Device Architecture)框架来实现并行程序,称为kernel,它们由多个线程同时执行。线程组织成网格(grid)和线程块(thread blocks),线程块进一步被分割为warp,每个warp包含32个线程。
kernel的一些关键考量:为了充分利用GPU的并行能力,kernel必须展现出高度的并行性。这通常通过以下关键考虑来实现:
-
线程同步(Thread Synchronization):在不同线程需要操作同一份数据时,为了避免竞争条件(race conditions),需要通过同步调用来确保数据的一致性。然而,线程同步应在必要的情况下谨慎使用,以避免过多的同步导致warp(一组同时执行的线程)中的线程暂停执行,从而降低性能。
-
warp发散(Warp Divergence):由于warp中的线程是lockstep(一种同步机制)的,数据依赖的条件语句会导致warp中的线程序列化执行,从而降低了执行效率。当只有少数指令受到分支条件控制时,编译器可能使用预测执行(predication)技术来减少性能损失。这意味着所有线程无论是否满足条件都会执行计算,然后只有满足条件的线程会将结果写回。
-
占用率(Occupancy):占用率是指在SM上同时执行的线程块数量与理论上SM可以同时执行的最大线程块数量的比例。高占用率有助于调度器隐藏延迟并提高吞吐量。理想情况下,每个SM应该能够同时执行至少三个线程块,但这可能会受到线程块大小或消耗的硬件资源(如寄存器或共享内存)的限制。
4.2.2 优化方法
文中回顾了先前使用GPU实现LBM的研究,包括Ryoo等人和Tölke的工作,他们通过优化内存访问和合并碰撞与流场步骤来提高性能。作者从先前工作中汲取经验,开发了一个高度优化的LBM kernel,使用了双网格方法、SoA(Structure of Arrays)数据结构,并结合了碰撞和流场步骤。此外,还采用了块大小调整、循环展开和常量内存优化等技术。
-
双网格方法(Double-Grid Approach):为了提高性能,作者采用了双网格方法,其中包含两个独立的网格,一个用于存储当前时间步的分布函数(
f_in),另一个用于存储下一个时间步的分布函数(f_out)。这种方法避免了在流场步骤中覆盖数据,从而提高了效率。 -
SoA数据结构(Structure of Arrays):作者使用SoA数据结构来组织数据,这种方式将所有速度方向上的分布函数存储在连续的内存块中,而不是按照每个网格点(AoS,Array of Structures)存储。SoA有助于提高内存访问的连续性和缓存效率。
-
块大小调整(Block Sizing):为了提高占用率(occupancy),减少内存访问延迟,作者对线程块的大小进行了优化。适当的块大小可以确保每个warp中的线程能够连续地访问内存,从而减少内存访问的延迟。
-
内存访问优化(Memory Access Optimization):作者发现push-out方案比pull-in方案在性能上略有优势。push-out方案通过先读取局部速度,然后准备写入全局内存,从而隐藏了更多的通信延迟。
-
循环展开(Loop Unrolling):通过展开循环,减少了寄存器的使用量,提高了占用率,提升了性能。循环展开通过显式展开循环中的指令来减少操作次数,避免了不必要的计算。
-
常量内存(Constant Memory):使用常量内存来存储预计算的变量,可以轻微提高执行时间。常量内存的使用对于减少寄存器使用量的影响有限,但在某些情况下可以减少中间计算的开销。
作者尝试了一些其他优化方法,例如使用共享内存存储基础索引以减少寄存器使用,但这种方法增加了运行时,因为需要线程同步。另一个例子是重排序指令以减少读-写数据依赖性造成的延迟,尽管减少了寄存器的使用,但实际上增加了运行时间。作者放弃了这些不成功的优化。
4.2.3 性能评估
作者对GPU实现的性能进行了评估,使用了SPEC CPU2006中的470.lbm基准测试。他们发现,比最好的GPU实现方案性能还要高3%。尽管GPU在某些情况下能够提供显著的性能提升,但由于其内存带宽的限制和功耗约束,未来的性能提升可能会受到限制。
4.3 FPGA实现
本质上,FPGA是具有一组固定资源的芯片,可以以各种方式进行连接和重新配置。虽然FPGA不像软件那样灵活,但由于它们高度可定制的设计,通常能够提供优越的性能。
4.3.1 FPGA架构
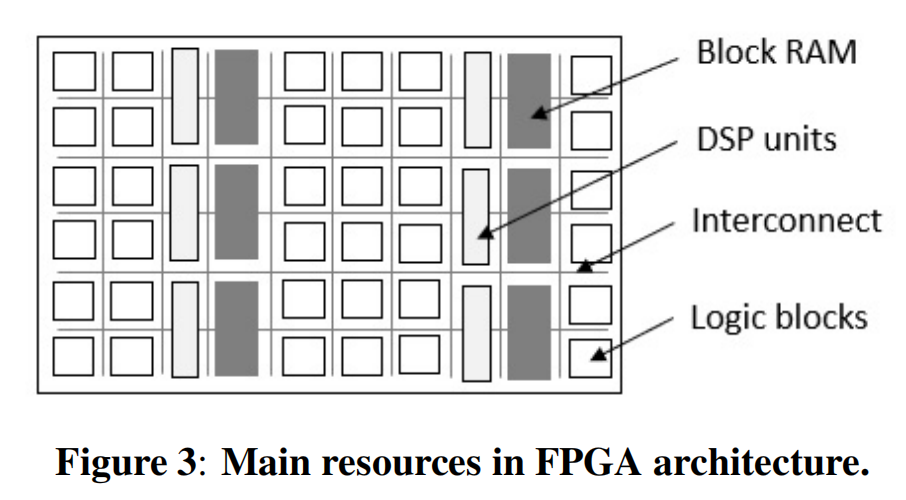
- Block RAM Memory (BRAM): FPGA芯片上包含大量的BRAM,这是一种由SRAM单元组成的内存块。BRAM块通常以列状排列,可以通过链式连接来增加容量,但会增加时钟周期。
- Digital Signal Processing (DSP) Slices: FPGA提供了DSP slice,用于执行高性能的浮点运算。一个或多个DSP切片通常被用来实现单个算术单元,所需的切片数量取决于实现的操作类型和所需的速度与资源使用之间的权衡。
- Configurable Logic Blocks (CLBs): CLB是FPGA的基本构建块,由触发器(Flip-Flops, FFs)和查找表(LUTs)组成。FFs主要用于作为寄存器,而LUTs用于生成函数。FPGA通过存储输入和它们对应的输出在特殊的内存数组(表)中来定义函数,从而可以编程执行任意函数。
- Interconnect Network: FPGA中的硬件资源通过一个由wire和可编程路由开关组成的互连网络连接。这个互连网络与CLBs一起被称为“fabric”,构成了FPGA的主体。
- Super Logic Regions (SLRs): FPGA架构的一个改进是引入了堆叠层,多个相同的硅芯片堆叠在一起以增加容量。这些层通过堆叠硅互连(SSI)技术连接,允许数字信号在SLRs之间通过超长线路(SLLs)传输。
Design Tradeoffs: FPGA设计过程中需要在资源利用、时钟速度、功耗、操作延迟和系统吞吐量之间进行权衡。FPGA设计中的一个关键权衡是在资源利用和时钟频率之间找到平衡。设计可能会因为资源使用密集而导致路由拥塞,从而影响时钟周期和性能。FPGA设计中的一个重要考虑因素是如何平衡资源利用和复制?适度的资源复制可以减少路由拥塞,缩短信号传播时间,但可能会增加功耗;但过度复制可能会导致额外的路由拥堵。为了解决长关键路径问题,FPGA设计采用了流水线方法,将复杂的操作分解成可以在较短周期内完成的较小步骤。这种方法通过重叠连续操作的执行来提高系统吞吐量,但可能会增加操作的延迟。
4.3.2 优化方法
在FPGA实现中,PE为基本的计算单元,每个PE会被分配到mesh的一部分,这部分网格被称为tile,据我理解来看整个网格称为mesh,单个网格单元称为cell。由于网格分割成为tile,在每个tile的边界的cell被称为halo。为了在PE内部高效地管理内存,设计采用了专门的缓冲区来存储"halo"单元(位于计算域边缘的单元),这些单元在流步骤中需要与相邻PE交换数据。每个时间步会执行两个操作,collision和streaming,而halo在执行交换时会使用专门的步骤进行显示管理。具体的优化策略如下:
- In-place Streaming:为了克服GPU带宽瓶颈,FPGA加速器利用其丰富的片上内存(BRAM)来存储整个网格。这种方法采用了single-grid、two-pass的方式,单网格指FPGA的一个PE只维护一份网格数据的拷贝,而GPU通常会维护两份网格数据拷贝以避免就地更新时的数据覆盖问题。two-pass指,为了避免在就地更新过程中覆盖数据,采用了一种两步交换算法(如图4所示)。第一步在网格点内部交换相反方向的速度,第二步将这些速度与目标网格点的速度进行外部交换。为了避免在处理相邻PE的halo cell(位于网格边界的ceel)时发生内存bank冲突,halo cell在碰撞步骤后被存储在专用缓冲区中,并在流步骤之后由目标PE读取。通过In-place Streaming和流水线技术,FPGA实现能够在每个时间步中使用单个网格拷贝来完成LBM的碰撞和流步骤,从而减少了内存访问次数和带宽需求,提高了模拟的性能。

- Exploiting Parallelism(利用并行性):FPGA设计的灵活性允许在两个层面上利用LBM的局部性来实现并行性。首先,在每个时间步内并行运行PE(PE级并行),PE可以独立的运行一个tile。其次,每个PE可以在流步骤中并行处理其速度,使得所有的交换操作可以同时发生。碰撞步骤也可以在所有速度上完全并行化,除了计算宏观属性外。但是,在PE内部同时操作D3Q27中的27个速度,会使用FPGA的大部分资源,因此为了提高PE级的并行性需要在PE内部共享相同的资源,但这样会减少PE的吞吐量(指每个时钟周期更行的cell数)。比如,如果使用同一组资源处理3个速度,吞吐量会减少1倍。
- Memory Management(内存管理):为了在PE内部实现并行执行,必须有足够的内存bank、来同时检索所有27个速度,而不会发生bank冲突。每个PE的tile数组分布在27个内存分区中,每个分区占据一个或多个BRAM块。宏观属性也存储在单独的分区中,以允许在流水线实现中对不同属性的内存访问重叠。
- Lattice Velocities(格子速度):每个PE维护自己的格子速度和权重副本,存储在寄存器中以便于快速检索和最大化性能。为了高效地访问相反的速度,首先存储剩余的无需交换速度,然后是相反的速度对。这样,你在访问相反的速度时只需要移动指针,而不需要进行计算。(我的理解是,速度的存储可能是链式的,所以只需要移动指针访问即可)
- Macroscopic Properties(宏观属性):模拟过程的主要结果是宏观属性,这些属性通常每隔几个时间步被“drained”到DRAM内存中,以保存flow的时间历史记录供后处理。通过将draining与streaming步骤重叠,只要内存传输没有序列化以避免bank冲突,就可以在streaming的掩蔽下完全覆盖draining的延迟。(说实话,没看明白)
总的优化策略是,尽量平衡并行性和时钟频率来实现高性能,然后再将网格尽量最大化(支持实际问题),同时保持可接受的性能水平。如果大量使用同一种类型的资源,即使占用的空间不大也会造成路由拥塞。因此,可以通过降低PE吞吐量来节省资源,然后测试FPGA可容纳的PE数量(LUT使用率超过40%就不能再上升了)。
4.3.3 性能评估
FPGA实现的性能通过在AWS提供的VU9P FPGA上进行测试来评估。测试结果表明,每个cell大小为98k,使用single-PE实现的性能最好。
FPGA在某些情况下能够提供比GPU更高的能效,尤其是在中等大小的网格上。局限性:尽管FPGA提供了高度的可定制性和并行性,但它们在实现LBM时也面临挑战,包括路由拥塞和片上内存限制。此外,FPGA的编程和开发通常比GPU更复杂,需要更多的硬件设计专业知识。
4.4 ASIC实现
ASIC设计的目标是实现高性能和高能效,同时保持合理的芯片面积。设计考虑了处理单元(PE)的数量、每个PE负责的网格大小、以及如何在芯片上布局这些PE以最大化并行性和减少通信延迟。基于ASIC的LBM加速器采用多个PE单元,每个PE处理一个tile,PE由一个晶格玻尔兹曼计算单元(LBU)和SRAM块组成(用于存储片上的整个tile)。网格尺寸固定为64^3,为了设计得到一个高并行度的加速器,考虑以下优化方案:
-
PE数量:ASIC的一个优势是能够在片上存储整个网格,因此,芯片的设计以高内存与计算比为目标。在网格尺寸固定的情况下,PE数目越多,单个PE负责的tile就越小。但过多的PE会导致芯片收益递减,因为会花费大量时间用于halo交换,而没有花费足够的时间使得LBU繁忙。作者得出的结论是,64PE能够在LBU和内存之间取得较好的平衡,这种情况下,60%的面积被分配给内存。
-
芯片布局:PE以正方形形状布局,LBU位于中心,SRAM块围绕LBU形成一个环。为了降低功耗,PE及其组件紧密放置以最小化导线长度。同时,为了避免过于紧凑导致的布线问题,LBU的周长必须足够大,以容纳连接到SRAM块所需的36个数据总线以及与相邻PE交换halo所需的8个数据总线。
-
多芯片解决方案:文档还讨论了一种多芯片解决方案的可能性,该方案可以通过PCIe 6.0互连来支持几乎无限大小的问题,而几乎没有性能开销。
-
工艺节点缩放:作者还考虑了从45纳米工艺节点缩放到16纳米工艺节点的影响,包括面积、电压和功耗的减少。这些缩放假设基于FinFET技术的使用,以及对动态功耗的减少。
-
性能和能效预测:基于上述设计考虑和工艺节点缩放,作者预测了ASIC的性能和能效。预计ASIC能够在1.2 GHz的时钟频率下运行,并在16纳米工艺下实现355瓦的功耗,同时提供显著高于现有GPU解决方案的性能和能效。
(5)实验结果
5.1 比较基准
本文的主要目的是比较LBM在优化后在GPU,FPGA和ASIC上的性能提升,控制变量法,保持GPU和FPGA的性能在未优化前使用相同前的设备,其性能应该是相当的(即等效)。为了保证不同设备之间的等效性,最好是在同一代高端家庭旗舰产品之间进行比较,对于不同技术的设备,如果两代设备共享制造工艺节点且同年发布,则认为两代设备等效。
在本研究中,由于使用的FPGA设备不是旗舰产品,而是通过AWS访问的VUP9 FPGA,具体的比较准则:使用FLOPS(每秒计算次数)= 处理器频率*处理器中可用的浮点算术单元数量,如下:
- FPGA:VUP9,UltraScale+系列,2016年发布,16nm节点,中档FPGA,GLOPS峰值为384,假设时钟频率为250 MHz(FPGA的时钟频率会根据设计和资源消耗而变化)。
- GPU:本文使用了三种GPU设备作为参考来评估描述的硬件加速器。这三种GPU的测试结果都是基于高度优化的LBM内核,性能在537到2,076 MLUPS之间,能效在5到33 MLUPS/W之间。P40和P100的性能是实际测量的,而V100的性能是估计的。
- 以FLOPS衡量时,P40因其与本论文中采用的VUP9 FPGA相当的计算能力(MLUPS)而被选作比较基准,Pascal系列,中档GPU,GLOPS峰值为319,双速率GDDR内存、384位总线宽度和3615 MHz的时钟频率。GPU最大可达带宽为347GB/s,实际带宽为293GB/s(约占84%,通过使用一个简单的内核,读取一个数组的内容并写入另一个是数组测得)。
- P100,以DP单元作为度量时,作为比较基准,16纳米Pascal系列中的顶级产品;
- V100,12纳米Volta系列中的顶级产品。
5.2 GPU性能和能效比分析
性能评估:作者通过计算每个网格单元更新所需的内存访问次数来评估GPU的性能。考虑到每个单元格需要读取和写入27个速度值,总共需要54次8字节的内存访问,作者计算出了GPU的MLUPS(百万格子单元更新每秒)。
功耗测量:作者使用NVIDIA的nvprof profiling工具对每个测试mesh进行功耗测量,并记录了每10毫秒的板载功耗(power consumption)数据。在计算能效比(energy efficiency)时,假设板载能效为85%,记录的功耗降低了15%(说实话,这数据嘛意思,我是昏头了)。但是需要明白以下两个基本概念:
- Power Consumption(功耗):设备在一定时间内使用多少电能的指标,单位w;功耗越高,意味着需要越先进的冷却技术,也即越高的运行成本。
- Energy Efficiency(能效):设备的性能与其消耗的能量之间的关系,可以理解为“用最少的能量做最多的工作”。能效越高,意味着设备在完成特定任务时消耗的能量越少,这通常与更高的性能和更低的运行成本相关。
结果分析:首先作者复现了目前最佳的LBM实现方法,基于D3Q19晶格,性能1,243 SP GFLOPS,在K40c上最大理论带宽为288.4GB/s,理论峰值性能为5,046 SP GLOPS。(K40c:Tesla系列,面向科学计算和高性能计算市场的GPU加速器,特别适用于需要大量浮点计算和并行处理的任务,如流体动力学模拟、分子建模和其他科学计算应用)。
为了等效的原则,在P4000上以单精度运行了D3Q19测试,最大理论带宽为243.3GB/s,理论峰值性能5, 304 SP GLOPS。相比K40c,P4000的带宽减少15%,计算能提高5%,提供1, 279 SP MLUPS,而我们的实现比最优秀的设计还要高3%。(P4000,拥有更多的流处理器和更高的时钟频率,与K40c相比能够提供更高的浮点运算能力)
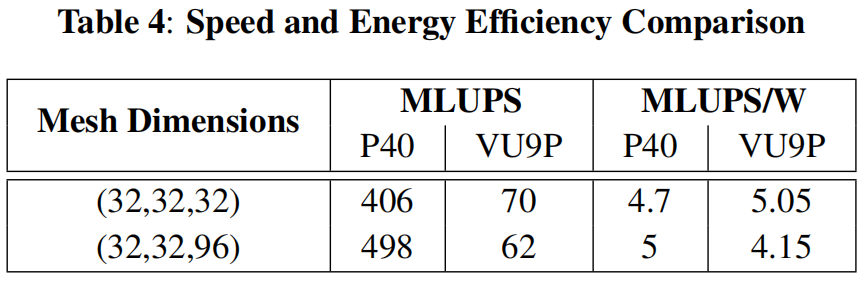
作者在P40上测试了不同大小的网格(128^3、64^3和32^3),并记录了运行时间、带宽、MLUPS,功耗和能效比。结果表明,随着网格大小的减小,运行时间减少,但MLUPS也降低。功耗随着网格大小的减小而降低,但能效比有所提高。此外,相比P40,P100可达到1171MLUPS,能效比最高可达17MULPS/W是P40的3倍,且别P40快2倍。

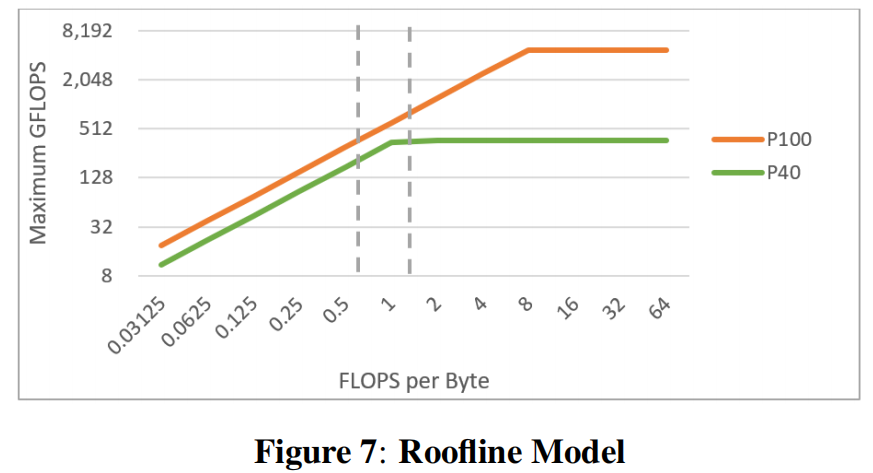
瓶颈分析:采用roofline model来确定程序是否受到内存带宽 或 计算能力的限制。如图7所示P40和P100的roofline示意图,一条平坦和倾斜线的交叉点即为ridge point。该点表示应用程序在该建模硬件上的理想算术强度,即内存带宽与计算能力完美平衡。具体来说:
- ridge point右侧表示计算受限,意味着计算单元无法跟上内存,越靠右,计算单元越饱和,浪费的内存带宽越多。可通过优化计算操作来降低计算强度,减少处理时间,从而引入更多的新数据元素进行处理。
- 一旦算术强度降低到ridge point左侧,优化计算不再有利,因为此时是带宽受限,即内存带宽无法跟上计算单元的速度,在优化计算只会增加计算单元的空闲时间,因为数据传输零率不变。此时需要增加数据带宽,将更多的数据元素传给空闲的内核。
如图7所示,应用作者提出的优化技术后,LBM的算术强度从1.45下降到0.7,即在P40优化前为计算受限,优化后为带宽受限,P100带宽受限更严重。就P40而言:内存带宽在理论峰值时,支持800MLUPS;计算单元在峰值时,支持600MLUPS;经过LBM优化后,计算核心理论上能够产生over 1200MLUPS,内存带宽仍支持800MLUPS。
5.3 FPGA性能和能效比分析
性能测试:作者在不同大小的网格上测试了FPGA加速器的性能,包括12K、32K和98K网格单元,在单个PE加速器上的结果,每个版本运行10,000次迭代,使用OpenCL分析事件以纳秒为单位测量性能。测试结果包括运行时间、频率、MLUPS(百万格子单元更新每秒)和功耗,如表3所示:时钟频率的降低可以解释32k网格单元的实现优于98k,但不能整明32k的优于12k的,即32k mesh大小最优。(为啥,mesh2的参数最好毋庸置疑,但是为啥不能说明比mesh1优呢?)

对比GPU:尽管FPGA加速器在某些情况下提供了比GPU更高的能效,但其性能仍然低于高端的GPU。比如P100的能效比为17MLUPS/W,是VUP9的3倍,但考虑到P100的峰值性能超过我们的12倍,这样的性能仍然是令人满意的。
多PE设计考量:作者还讨论了多处理单元设计的可行性,包括资源共享的开销和多PE解决方案的潜在优势。然而,作者得出结论,对于LBM来说,单PE FPGA设计更为合适,因为它提供了更好的性能和能效平衡。在相同的实现下,多PE会花时间对halo单元的交换管理需要额外的时间延迟。
进一步优化:尽管在GPU和FPGA上已经进行了大量优化工作,但作者认为仍有进一步改进的空间。例如,通过算法增强来完全重叠流和碰撞步骤,以及使用手工制作的RTL代码代替HLS(高级综合语言)可能会进一步提高FPGA的性能。
5.4 ASIC性能和能效比分析
作者基于45纳米工艺节点的资源和特性,对ASIC进行了初步设计,并计划将其缩放到16纳米工艺节点。其中,ASIC的总面积是估算得到的,考虑了PE浮点单元,内存块,总线等部件。此外,作者预测了ASIC在运行时的总功耗,包括内存访问和计算操作的能量消耗。这些估计基于每个操作的能量消耗和操作的频率。
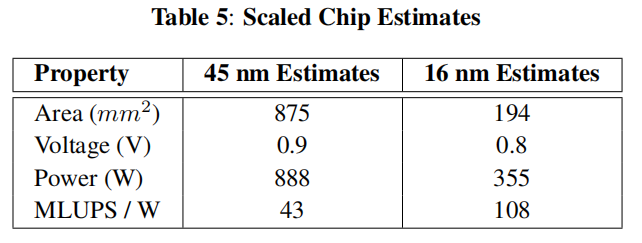
作者预计ASIC能够在1.2 GHz的时钟频率下运行,ASIC加速器在64^3的mesh大小下,实验结果如表5所示,能提供38, 400 MLUPS,基于16nm技术,尺寸约为194mm^2,1.2GHz下功率355w,ASIC加速器比P100(16nm的顶级GPU)性能高33倍,能效方比面都比其高6倍。(以上数据并非根据芯片实测得到,而是通过计算仿真等方式得到)

(6)问题记录
有个问题,emmm我还没明白,文中提到的line,family怎么理解,比如GP102 line的P40,GP100 line的P100,ultraScale+ family的VUP9,但是系列一般是用series,架构用architecture,我理解的是架构是基础,在这基础上,面向不同领域做出的优化称之为系列。比如Zen3架构,系列有桌面处理器ryzen和服务器处理器EPYC。但是文中的这个line和family怎么翻译或者理解,我的脑瓜子是嗡嗡的。
作者如何在捕获最大的算术强度后,获得带宽有限的性能的最高上限?作者采用式16进行计算,*2是因为带宽必须支持将数据传输到计算单元以及将结果传输会内存,理解下来应该是整个mesh所有的字节数(数据的搬运是从内存到计算单元,再从计算单元搬回去?)。作者假设阻塞和缓存开销不计,即在当前时间步重复访问相同的数据元素不会产生额外开销,以此捕获可能的最大的算术强度。公式16表达的是一个字节的数据需要花费多少浮点操作,即算术强度。或者说作者是根据算术强度的值,来判断模拟的性能瓶颈(计算值作为roofline的横坐标?flops/byte)。如果算术强度很高,意味着计算需求大于内存带宽,系统可能是计算限制的;如果算术强度较低,意味着内存带宽可能是限制性能的瓶颈。
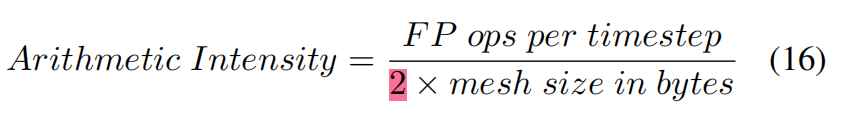
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
挺好的,收获颇丰,缺点是还是关于宏观,不够细节,一些具体的实现手段,并未着墨过多,知道了这种优化方式的作用,但并不知道如何实现。说实话看了这么久,具体是如何针对LBM进行加速的,即更确切的加速模式还是比较模糊,需要进一步的深耕或许会有所悟。
四、Why:为什么看这篇文献 (方便再次搜索)
用于课题了解:
- 了解CFD的大致背景
- 了解LBM的基本知识,及在不同的平台上优化手段、性能表现
五、Summary:文献方向归纳 (方便分类管理)
- LBM accelerator