在平时不知道一有没有遇到过这种情况,我明明创建了索引,但是MySQL为何不用索引呢?为何要进行全索引扫描呢?
一、对索引进行函数操作
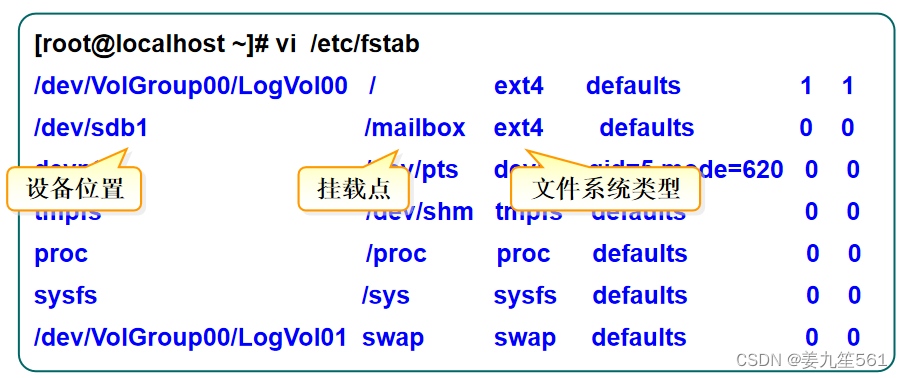
假设现在维护了一个交易系统,其中交易记录表 tradelog 包含交易流水号(tradeid)、交易员id(operator)、交易时间(t_modified)等字段。为了便于描述,我们先忽略其他字段。这个表的建表语句如下:
CREATE TABLE `tradelog` (`id` int(11) NOT NULL,`tradeid` varchar(32) DEFAULT NULL,`operator` int(11) DEFAULT NULL,`t_modified` datetime DEFAULT NULL,PRIMARY KEY (`id`),KEY `tradeid` (`tradeid`),KEY `t_modified` (`t_modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;假设,现在已经记录了从 2016 年初到 2018 年底的所有数据,运营部门有一个需求是,要统计发生在所有年份中 7 月份的交易记录总数。这个逻辑看上去并不复杂,你的 SQL 语句可能会这么写:
SELECT count(*) from tradelog WHERE MONTH(t_modified) = 7;由于 t_modified 字段上有索引,于是你就很放心地在生产库中执行了这条语句,但却发现执行了特别久,才返回了结果。
如果你问 DBA 同事为什么会出现这样的情况,他大概会告诉你:如果对字段做了函数计算,就用不上索引了,这是 MySQL 的规定。
现在你已经学过了 InnoDB 的索引结构了,可以再追问一句为什么?为什么条件是 where t_modified='2018-7-1’的时候可以用上索引,而改成 where month(t_modified)=7 的时候就不行了?
下面是这个 t_modified 索引的示意图。方框上面的数字就是 month() 函数对应的值。
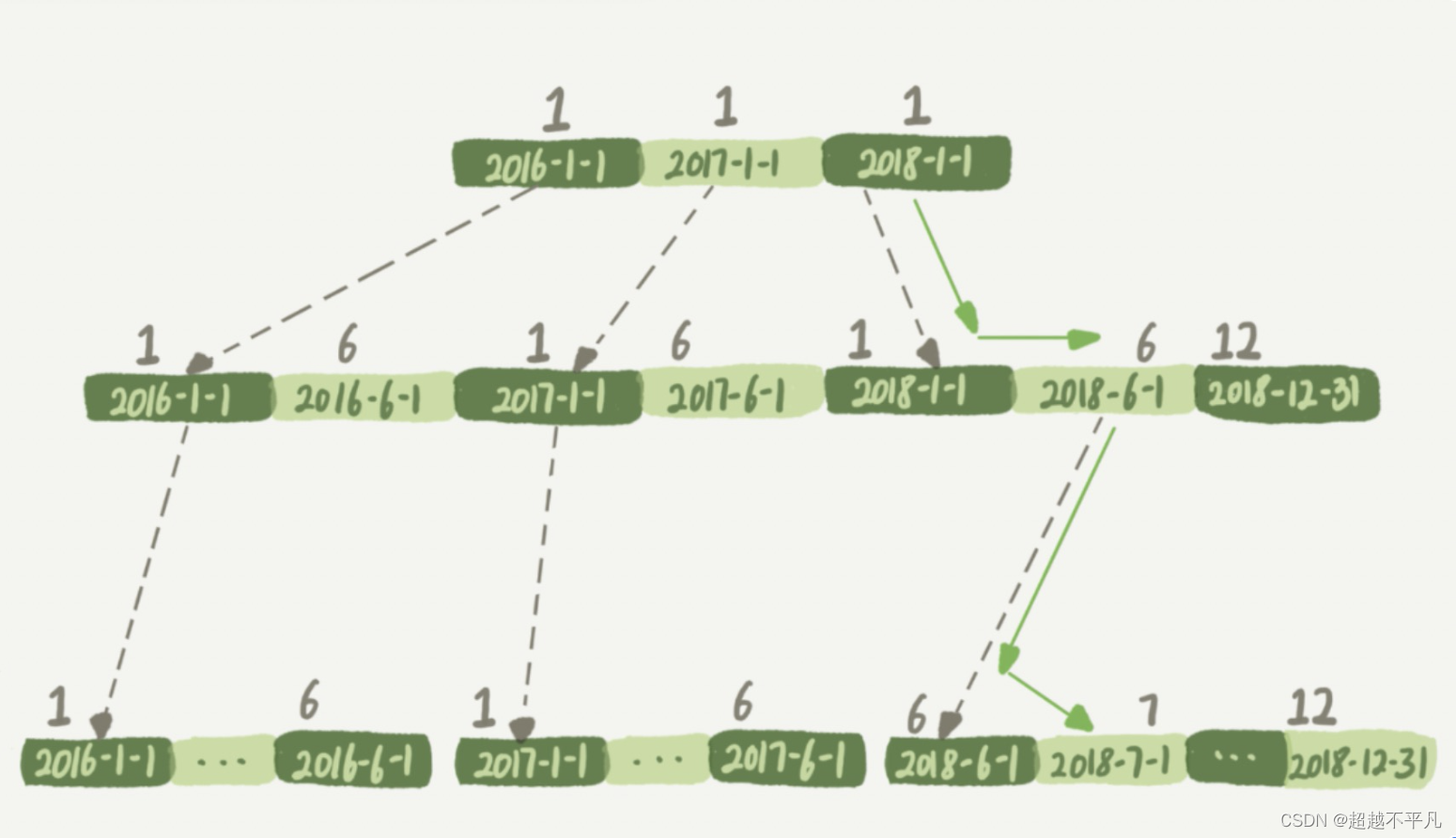
如果你的 SQL 语句条件用的是 where t_modified='2018-7-1’的话,引擎就会按照上面绿色箭头的路线,快速定位到 t_modified='2018-7-1’需要的结果。
实际上,B+ 树提供的这个快速定位能力,来源于同一层兄弟节点的有序性。但是,如果计算 month() 函数的话,你会看到传入 7 的时候,在树的第一层就不知道该怎么办了。
也就是说,对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
需要注意的是,优化器并不是要放弃使用这个索引。
执行计划如下:

key="t_modified"表示的是,使用了 t_modified 这个索引;我在测试表数据中插入了 10 万行数据,rows=99960(思考题:这里为什么是99960呢?),说明这条语句扫描了整个索引的所有值;Extra 字段的 Using index,表示的是使用了覆盖索引。
由于在 t_modified 字段加了 month() 函数操作,导致了全索引扫描。为了能够用上索引的快速定位能力,我们可以把 SQL 语句改成基于字段本身的范围查询。
比如,对于 select * from tradelog where id + 1 = 10000 这个 SQL 语句,这个加 1 操作并不会改变有序性,但是 MySQL 优化器还是不能用 id 索引快速定位到 9999 这一行。所以,需要你在写 SQL 语句的时候,手动改写成 where id = 10000 -1 才可以。
二、隐私类型转换
看一下这条 SQL 语句:
select * from tradelog where tradeid = 110717;交易编号 tradeid 这个字段上,本来就有索引,但是 explain 的结果却显示,这条语句需要走全表扫描。你可能也发现了,tradeid 的字段类型是 varchar(32),而输入的参数却是整型,所以需要做类型转换。

优化器执行SQL语句时相当于执行了:
select * from tradelog where CAST(tradid AS signed int) = 110717;也就是说,这条语句触发了我们上面说到的规则:对索引字段做函数操作,优化器会放弃走树搜索功能。
三、隐式字符编码转换
假设系统里还有另外一个表 trade_detail,用于记录交易的操作细节。为了便于量化分析和复现,我往交易日志表 tradelog 和交易详情表 trade_detail 这两个表里插入一些数据。
CREATE TABLE `trade_detail` (`id` int(11) NOT NULL,`tradeid` varchar(32) DEFAULT NULL,`trade_step` int(11) DEFAULT NULL, /*操作步骤*/`step_info` varchar(32) DEFAULT NULL, /*步骤信息*/PRIMARY KEY (`id`),KEY `tradeid` (`tradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;这时候,如果要查询 id=2 的交易的所有操作步骤信息,SQL 语句可以这么写:
select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;执行计划如下

来看下这个结果:
- 第一行显示优化器会先在交易记录表 tradelog 上查到 id=2 的行,这个步骤用上了主键索引,rows=1 表示只扫描一行;
- 第二行 key=NULL,表示没有用上交易详情表 trade_detail 上的 tradeid 索引,进行了全表扫描。
如果你去问 DBA 同学,他们可能会告诉你,因为这两个表的字符集不同,一个是 utf8,一个是 utf8mb4,所以做表连接查询的时候用不上关联字段的索引。这个回答,也是通常你搜索这个问题时会得到的答案。
参照前面的两个例子,你肯定就想到了,字符集 utf8mb4 是 utf8 的超集,所以当这两个类型的字符串在做比较的时候,MySQL 内部的操作是,先把 utf8 字符串转成 utf8mb4 字符集,再做比较。
因此, 在执行上面这个语句的时候,需要将被驱动数据表里的字段一个个地转换成 utf8mb4,再做比较。
等同于执行如下SQL
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value; CONVERT() 函数,在这里的意思是把输入的字符串转成 utf8mb4 字符集。这就再次触发了我们上面说到的原则:对索引字段做函数操作,优化器会放弃走树搜索功能。
综上所述:这三种类型其实都是触发了一个规则,平时要避免,提高查询效率。
四、优化器的逻辑
优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的 CPU 资源越少。
扫描行数是怎么判断的?
MySQL 在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。
这个统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。
可以使用 show index 方法,看到一个索引的基数。

MySQL 是怎样得到索引的基数的呢?这里,简单介绍一下 MySQL 采样统计的方法。
为什么要采样统计呢?因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。
采样统计的时候,InnoDB 默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 N/M 的时候,会自动触发重新做一次索引统计。
从图中看到,tradelog 表中有10万行数据,索引统计值(cardinality 列)虽然不够精确,但大体上还是差不多的,选错索引一定还有别的原因。
其实索引统计只是一个输入,对于一个具体的语句来说,优化器还要判断,执行这个语句本身要扫描多少行。
如果选择的事普通索引,那么还需要拿着 ID 进行回表来查询整行数据,这个代价优化器也会计算在内,而如果直接扫描主键索引,是没有额外的代价。优化器会估算这两个代价来进行评估选择。
我们可以通过 analyze table table 命令来重新进行统计。所以在实践中,如果发现explain的结果预估的rows值跟实际情况差距比较大,可以采用这个方法来处理。
往期经典推荐
MySQL索引优化实战宝典-CSDN博客
深入JVM内核揭示Java多态背后的神秘机制-CSDN博客
TiDB内核解密:揭秘其底层KV存储引擎如何玩转键值对_tidb 的key value是如何做到的-CSDN博客
MySQL计数优化探秘:COUNT(*)、COUNT(主键)与索引字段,谁是性能王者?-CSDN博客
MySQL中order by原来是这么工作的-CSDN博客
![[STM32] Keil 创建 HAL 库的工程模板](https://img-blog.csdnimg.cn/img_convert/c8064cca80503da147220eacbfa303ba.png#pic_center)
![[激光原理与应用-77]:基于激光器加工板卡的二次开发软件的系统软硬件架构](https://img-blog.csdnimg.cn/direct/cb9383ef13cc4000a65a8a0204c1d38e.png)