引言:
BUZZ作为语音转文字本地话的初级尝试,已经展现出了其独特魅力。然而,当你遇到Whisper STT时,你会发现它堪称语音转文字领域的巅峰之作。今天,我们隆重推荐一款基于fast-whisper开源模型的本地语音识别转文字工具的网页版。它不仅仅是一个简单的工具,更是一个能够让大家共同参与的互动平台,无论是投放在局域网还是公网都毫无压力。
一、Voice Recognition to Text Too (开发者没给起中文名字)
这款工具能够精准识别视频/音频中的人类声音,并将其转化为文字,支持输出json格式、srt字幕带时间戳格式以及纯文字格式。你可以轻松部署它,替代openai的语音识别接口或百度语音识别等,而其准确率几乎与openai官方api接口持平。
项目地址:https://github.com/jianchang512/stt
项目所需要的模型地址:https://github.com/jianchang512/stt/releases/tag/0.0
测试环境:轻量云2C+4G+8M
注意:这货会把模型塞到内存里,低于2G内存只能跑Base模型。
支持语言:中文、英文、法语、德语、日语、韩语、俄语、西班牙语、泰国语、意大利语、葡萄牙语、越南语、阿拉伯和土耳其语。
二、软件使用办法
使用过程简单便捷,只需部署或下载后双击start.exe,即可自动调用本地浏览器打开本地网页。通过拖拽或点击,你可以轻松选择要识别的音频或视频文件,然后选择发声语言、输出文字格式以及所用模型(已内置base模型)。点击开始识别后,识别结果将以所选格式直接展示在当前网页上。
本次以windos为例
1、打开样子如下(windows会启动一个Dos程序)
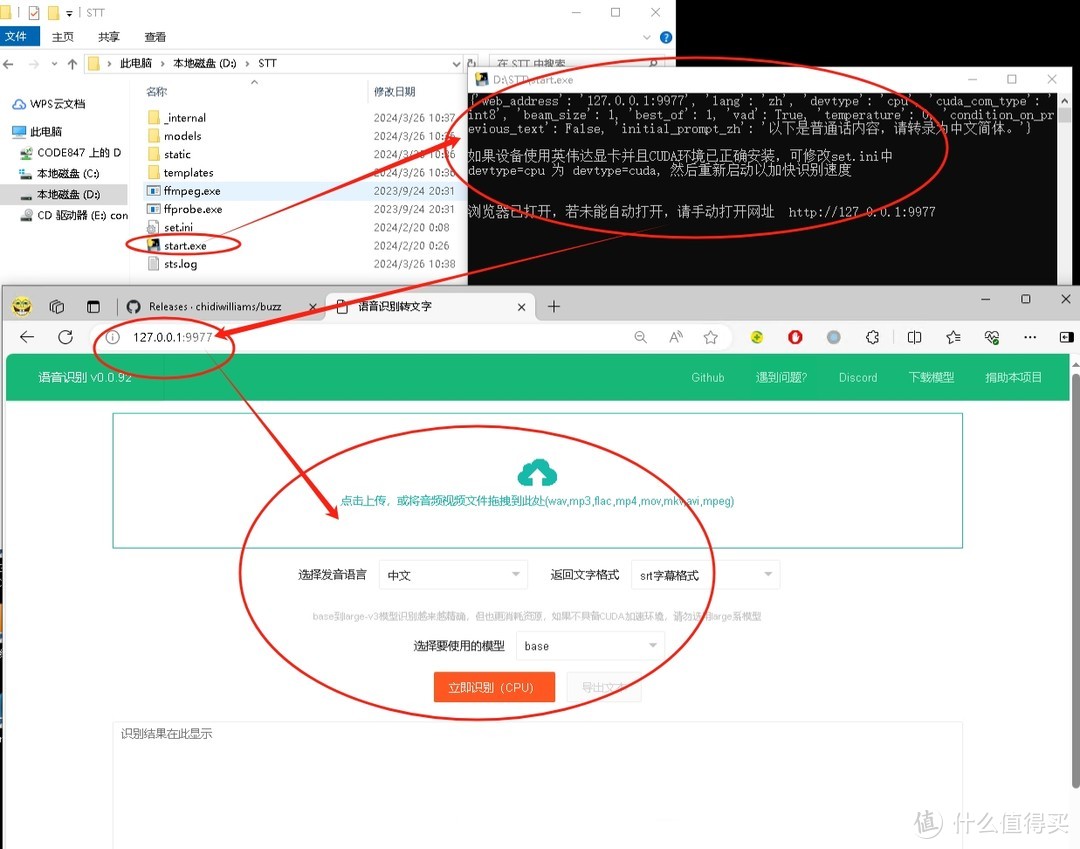
2、测试个MP3
点击上传(可以试听),点击立即识别即可(如果有GPU,会更快)。

3、测试结果
①基础模型(Base)会有一定的错误,结果如下(软件和buzz一样的)

②small模型会好一些(需要提前下载解压Models里)如下图所示。

扫描结果如下,显然比base好许多(有概率出现繁体中文)

导出结果如下:(繁体+简体)的随缘结果。

总得来说已经很好了,毕竟——免费不是么?
三、为啥推荐这个?
这玩意更令人惊喜的是,整个过程无需联网,完全本地运行,因此你可以放心地将其部署于内网环境。而fast-whisper开源模型提供了base/small/medium/large-v3等多种选择,内置了base模型。从base到large-v3,识别效果逐步提升,但所需的计算机资源也会相应增加(内存)。你可以根据实际需求自行下载并解压到models目录下,轻松实现模型的替换与升级。
如果说Buzz是基础,那么这个可是神器(有网页版~你甚至可以放到公网上耍耍)。如果你有前端能力,可以在templates目录下看到网页,可以随便改改。然后做个个映射即可。
如果需要修改端口:配置文件如下

通过映射本地端口到公网,可以使外网能够直接访问到界面,实现本地和公网的互通使用。然而,这种映射方式存在一定的安全风险,因此在实际操作中需要谨慎对待。

四、其他问题:
1、关于模型
model: 模型名称,对应模型文件在models目录下的位置,可选值如下:
base:对应于models/models--Systran--faster-whisper-base
small:对应于models/models--Systran--faster-whisper-small
medium:对应于models/models--Systran--faster-whisper-medium
large-v3:对应于models/models--Systran--faster-whisper-large-v3
2、关于AIP接口
接口地址: http://127.0.0.1:9977/api
请求方法: POST
请求实例:
Api python请求示例
import requests
# 请求地址
url = "http://127.0.0.1:9977/api"
# 请求参数
file:音视频文件,
language:语言代码,
model:模型,
response_format:text|json|srt
# 返回 code==0 成功,其他失败,msg==成功为ok,其他失败原因,data=识别后返回文字
files = {"file": open("C:/Users/c1/Videos/2.wav", "rb")}
data={"language":"zh","model":"base","response_format":"json"}
response = requests.request("POST", url, timeout=600, data=data,files=files)
print(response.json())
API curl请求实例
参数注释:
@后是文件 如D盘下单简单爱.MP
语言:language 设置为zh中文
服务器ip: 127.0.0.1:9977
输出文件:response.txt
curl -X POST \ -H "Content-Type: multipart/form-data" \ -F "file=@d:\简单爱 - 周杰伦.mp3" \ -F "language=zh" \ -F "model=base" \ -F "response_format=txt" \ http://127.0.0.1:9977/api > response.txt
Windows的Dos环境,直接粘贴

请求会返回结果至response.txt文件(注意,我这里在c:\users\zxl\目录下,自己Curl,注意返回的目录)。由于返回的是是unicode 编码,需要转换。如下图

PS,Windows的Curl 返回的都是unicode编码,需要转换下。
总结:
这款基于fast-whisper开源模型的语音转文字工具,无论是在Windows还是Linux/Mac系统上,都能提供高效、准确的语音识别服务,为您的工作和学习带来极大的便利。
无论是个人使用还是团队协作,这款基于fast-whisper开源模型的本地语音识别转文字工具网页版都将为你带来前所未有的便捷与高效体验。