编者按:英伟达2024 GTC 大会上周在美国加州召开,星辰天合 CTO 王豪迈在大会现场参与了 GPU 与存储相关的最新技术讨论,继上一篇《GTC 2024 火线评论:GPU 的高效存储利用》之后,这是他发回的第二篇评论文章。
上一篇文章已经提到,随着 AI 集群规模的提升,数据集的大幅增长,势必要面对集群资源的高效利用和安全问题,其中关键之一就是计算资源对于共享资源(如共享文件存储)的安全访问和保护。相比于传统 CPU 集群的共享存储和安全访问,GPU 集群在面对类似问题的挑战是安全+性能。安全访问并不能牺牲性能,特别是在当下刚发布的新一代 GPU 算力和网络平台下,存储带宽面对进一步提高的要求,吃紧的内存带宽和网络传输将进一步承压。

高性能存储安全访问的挑战
在讨论安全问题前,可能还要先牵扯算力集群和存储的网络方案。
众所周知,Nvidia 在 AI 数据中心推崇两个概念,一个是 AI Factory,另一个是 AI Cloud,前者类似于超级计算机的概念,适合单应用场景并推荐 Infiniband 组网方案,后者面临多租户和多样化的计算任务,因此推荐以太网方案。在这个分类下,我们会将以上存储安全访问问题缩小到更广泛 AI Cloud 场景上,因为这类场景相比而言,更急迫的需要解决。 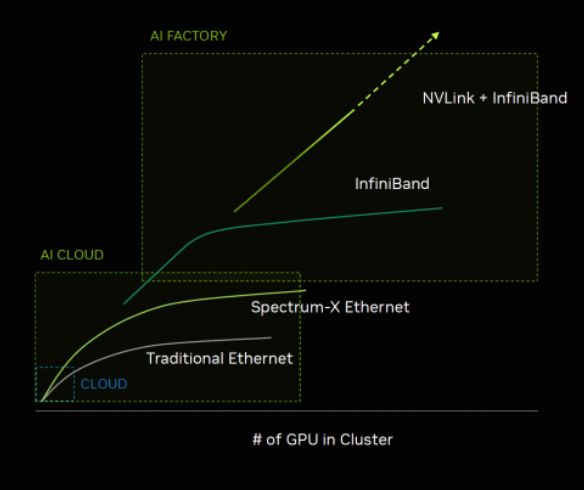
特别是,在当下 GPU 芯片昂贵成本下,即使在非 GPU 虚拟化场景,算力共享和灵活调度都是降低 AI 任务成本的重要手段,但算力平台如何向用户提供安全的数据访问和隔离手段是其中的重中之重。 因此,AI 算力集群需要在 足够性能 下解决控制面和数据面的安全访问挑战:
- 控制面路径的关键操作安全性:管理和配置网络、系统的操作,权限和策略的分配,漏洞和安全缺陷管理等等
数据面的授权访问和外部攻击:数据泄漏、篡改、服务拒绝等攻击
DPU 作为存储访问的信任代理
在以太网组网的 AI Cloud 场景下,Nvidia 提出了引入 DPU 方案来解决上述问题,通过 DPU 提供的代理访问来隔离非信任的主机和可信基础设施,确保 AI Cloud 的数据安全。
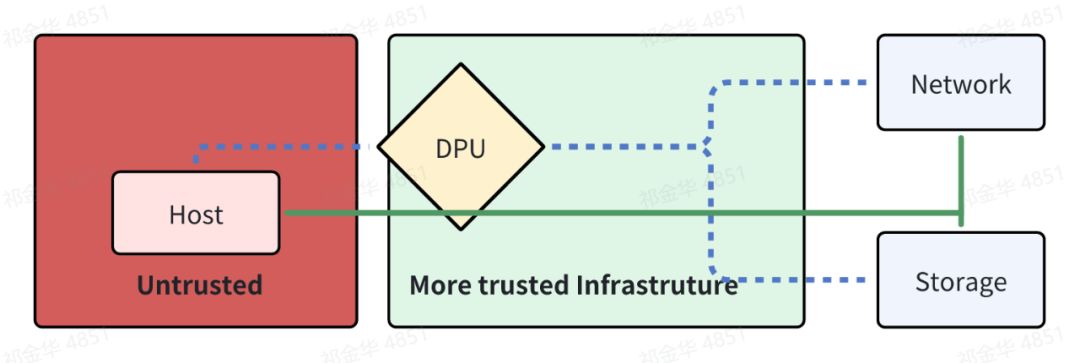
DPU 是一种专用硬件加速器,通常包含 CPU、内存和网络接口,能够在不增加主机侧处理器负担的情况下,执行数据处理任务,包括 Nvidia、Intel、AMD、Marvell 在内的芯片厂商都推出了 DPU 产品。DPU 在安全性上通常可以带来几个好处:
隔离和专用处理能力:DPU 可以作为一个隔离层,将存储和网络操作与主机的 CPU 分离开。这意味着即使主机受到安全威胁,攻击者也难以直接接触到数据传输和存储操作。
减少攻击面:DPU 可以控制访问存储资源的路径,允许更精细的访问控制策略,并且限制了潜在的攻击向量。由于主 CPU 不直接处理数据流,攻击者需先破坏 DPU,才能对数据进行篡改或未授权访问,这大大增加了攻击难度。
内置安全功能:许多 DPU 都配备了加密和其他安全功能,如内联数据加密、秘密保护和防火墙服务。这些功能可以在硬件层面提供保护,而不是依赖于可能被破坏的软件。
细粒度的控制:DPU 可以实现对数据访问的精细管理,包括访问控制、监控和日志记录,使系统管理员能够更好地监控和响应安全事件。
提供零信任架构:在 DPU 代理的帮助下,可以实施零信任安全模型,它假定内部网络也不可信,需要严格验证所有请求,这增强了对潜在内部威胁。
值得一提的是:在 Nvidia 发布的《下一代 AI 的新一代网络》白皮书中,提到在 400/800Gb 的网络中,即使无损网络环境中,都很难避免在 AI 的突发流量中性能不受影响。因此在以太网路线上,业界会期望借助于 DPU 算力来实现 RDMA 的拥塞控制,而不是依赖交换机或者 ECN 机制。因此 DPU 可能会是超高以太网网络的必需。
回到计算节点的 GPU 应用对于文件存储访问这个问题,存储客户端目前主要有两种选择:
- 用户态客户端:cuFile(GDS)/S3/SQL/..
内核态客户端:Posix/VFS
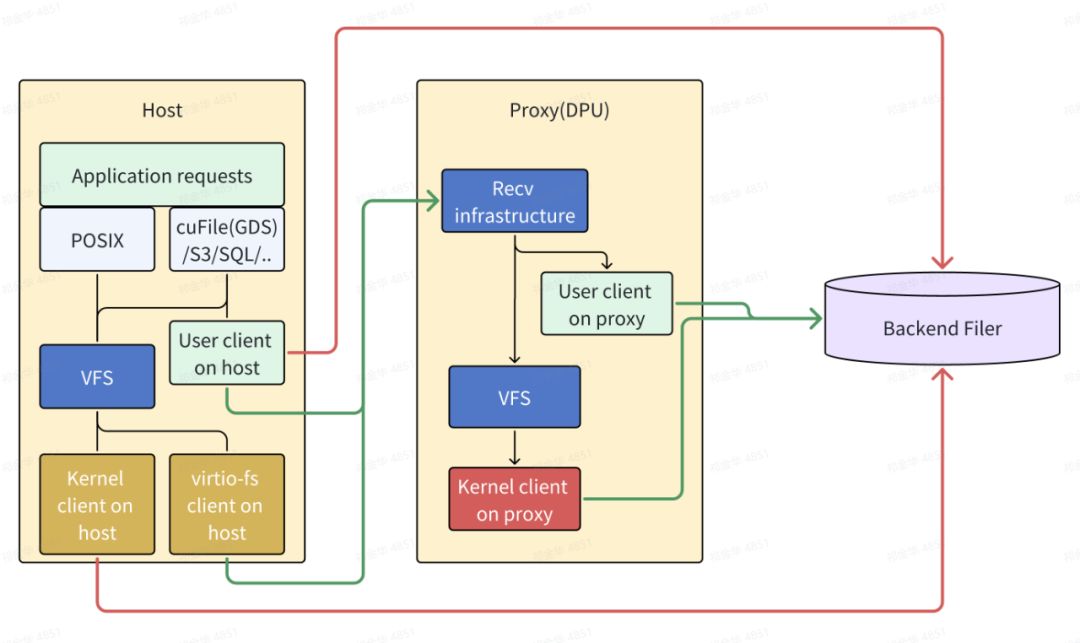
而引入 DPU 来实现安全访问,可以利用业界已有的虚拟化场景的文件协议实现 virtio-fs,virtio-fs 已经有长达十年的发展历程,它可以在这里提供从 Host 到 DPU 的文件代理通道,使得文件存储客户端可以完全运行于 DPU 操作系统。这样的变化,可以用下图来更清晰展示,其中红色的访问路径表示不安全的,绿色表示通过 DPU 的代理访问:
零拷贝问题
从技术角度来讲,引入额外的 DPU 来实现文件存储访问肯定带来额外开销,具体来说有这两个问题:
客户端缓存:在 AI 高性能的存储场景,客户端的内存缓存是必备选择,在当前的大部分 AI 任务中,对于存储的访问成本相对计算延迟仍然较高,缓存命中率非常关键,上一篇提到的 SCADA 实际上就是希望在中间建立通用的框架。但就目前而言,数据在计算节点上的缓存主要由存储客户端提供,例如 GPFS 在内核态实现了自有的缓存机制,Lustre 则更多依赖于 Linux Page Cache 机制。如果将存储客户端运行在 DPU 后,之前 Host 侧 CPU/GPU 的庞大内存也无法被数据缓存利用,DPU 内置的内存相对较小,则势必导致缓存命中率降低,性能大幅下降。因此,DPU 代理方案需要进一步解决该问题。
额外的拷贝成本:在客户端直接访问存储的路径中,通常采用 RDMA 来实现数据零拷贝。增加 DPU 代理访问后,会增加一次 Host 内存到 DPU 的拷贝。

DOCA SNAP virtio-fs
DPU Secure Storage Zero Copy 会通过 DOCA virtfs-fs SDK 来交付,过去 DOCA 已经提供了 SNAP NVME 能力,即可以通过 DPU 来实现 NVMe over Fabric 的卸载,DOCA SNAP virtfs 会成为新的文件存储访问卸载能力。
DPU 中的 VirtioFS 服务会基于 SPDK(https://spdk.io/) 开发,提供面向不同的文件存储供应商实现统一的抽象,运行在 DPU 中,面向 Host 的 virtio-fs 内核驱动承接请求,并为不同供应商的文件存储客户端根据需要去执行对应请求,未来文件存储供应商可以通过以下方式对接:
用户态文件客户端:如果文件存储直接支持用户态的文件客户端库,SNAP virtio-fs 可以直接通过库链接方式集成使用。
NFS over RDMA:如果文件存储提供标准的 NFS over RDMA 支持,则 SNAP virtio-fs 会直接通过 DPU OS 的 NFS 内核客户端访问,DPU OS 中的 NFS 内核客户端会修改来支持零拷贝。
内核态文件客户端:如果文件存储支持内核态客户端,则可以在 DPU OS 上安装,SNAP virtio-fs 可以执行 POSIX 调用。从 DPU OS Kernel 可以支持将 mkey 传递给 POSIX read()/write() 实现零拷贝。
目前 DPU Secure Storage 项目也需要得到文件存储厂商和 Linux Upstream 的支持,文件存储厂商需要尽快考虑将存储客户端迁移到合适的 DPU 运行环境,并作为 SPDK virtio-fs 的后端,为了实现零拷贝,需要能够支持利用 SPDK 的 memory domain API 来获得 mkey 对应的 Host 内存空间。而为了在 Host OS 上需要进一步加强 virtio-fs 的性能,比如实现多队列能力,支持 GPU 内存等。
XSKY 参与情况
对于国内领先的分布式存储厂商来说,我们同样认为,不仅是 Nvidia BlueField 系列产品可以提供这样的方式,这样的需求应该可以在普遍的 DPU 产品中实现并被利用,有效的提高 DPU 在存储协议上的多样化支持,并带来共享文件存储的安全性所需。
我们也会尽快评估在基于新一代全共享架构(XSEA)的全闪存文件存储,提供面向 AI Cloud 场景的 DPU 访问客户端能力,拥抱快速变化的 AI 基础设施进化。在多样化的 GPU 存储类型的利用上,不管是块存储的 NVMe 卷作为节点内的高速缓存,还是共享文件存储作为 CPU/GPU 内存的全局缓存存储,最终通过基于对象存储的数据湖来统一治理,这些存储类型的需求和定位都跟 XSKY 的产品定位和路线图高度符合。