1. pprint 库 官方文档
pprint --- 数据美化输出 — Python 3.12.2 文档
pprint — Data pretty printer — Python 3.12.2 documentation
2. 背景
处理JSON文件或复杂的嵌套数据时,使用普通的 print() 函数可能不足以有效地探索数据或调试应用程序。下面通过一个例子说明说明使用 print() 的弊端。
首先,使用 urllib 发出请求以获取数据。这里提供了两组代码,第一组含配置代理部分,第二组代码直接使用 urllib.request.urlopen。
-
代理(英语:Proxy,也称网络代理)是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接:本机 ----代理IP----访问的网站(服务器)。
-
urllib 提供 urllib.request.ProxyHandler() 方法可动态设置代理IP池
需要配置代理时:
import urllib.request
import urllib.parse
import jsonurl = "https://jsonplaceholder.typicode.com/users"# 如果代理网站需要提供用户名和密码,注意密码含有特殊字符时要进行url编码
username = '****'
encoded_password = urllib.parse.quote("****")
proxies ={"https": "****代理网站IP****"
}handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url).read()
result = json.loads(response)
print(result)不需要配置代理时:
from urllib import request
import jsonresponse = request.urlopen("https://jsonplaceholder.typicode.com/users")
json_response = response.read()
users = json.loads(json_response)打印结果(内容较长此处仅截取部分作为展示):

输出结果并不友好,是很长的一堆,不能帮助开发者理解数据的结构。
3. pprint 函数:初阶
pprint 用于以漂亮的方式打印数据,它属于是Python标准库,无需单独安装,使用时只需导入它的pprint() 函数:
from pprint import pprintpprint(result)打印结果(内容较长此处仅截取部分作为展示):

pprint 的输出结果有合适的缩进,能够帮助开发者可视化分析数据结构。如果你想尽可能少地输入,pprint() 有一个别名 pp(),它的行为方式与 pprint 完全相同。
from pprint import pprint, pp# pprint(result)
pp(result)4. pprint 函数:进阶
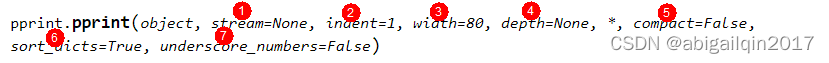
pprint() 将在 stream 上打印 object 的格式化表示形式,indent 等参数用于设置数据结构的格式化形式,即以何种方式被展示。
4.1 参数概述
- stream:一个 file-like object,表示调用 write() 方法时,输出内容被写入的位置(to which the output will be written by calling its write() method)。默认为 sys.stdout,如果 stream 和 sys.stdout 均为 None,则 pprint() 将静默地返回。
- indent:指定要为每个缩进层级添加的缩进量,默认为 1,一个空格字符。
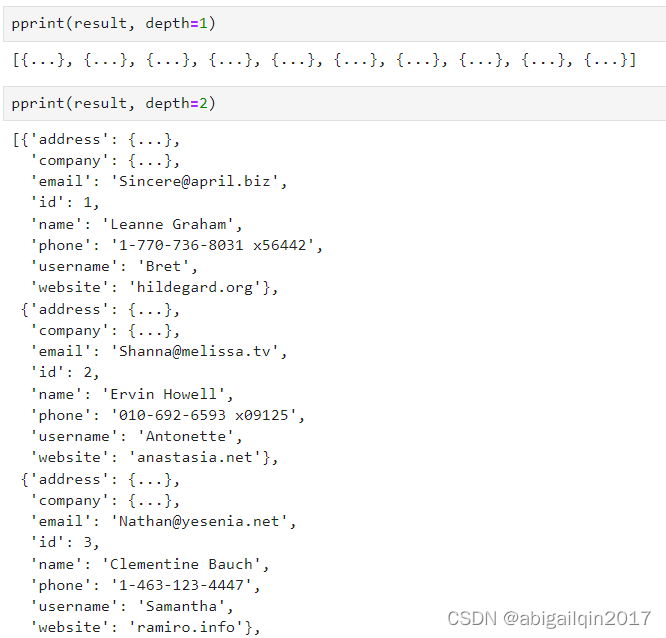
- depth:控制可被打印的缩进层级数量。如果要打印的数据结构层级过深,则其所包含的下一层级将用 ... 替换。 默认对于被格式化对象的层级深度无限制。
- width:指定输出中每行所允许的最大字符数,默认为 80。 如果一个数据结构无法在宽度限制之内被格式化,将显示尽可能多的内容。
- compact:影响长序列(列表、元组、集合等等)的格式化方式。如果 compact 为True,则每个输出行格式化时将在 width 的限制之内尽可能地容纳多个条目。 如果 compact 为 False 则序列的每一项将格式化为单独的行。默认为 False。
- sort_dicts:如果为 True,字典在格式化时将基于键进行排序,否则它们将按插入顺序显示。默认为 True。
- underscore_numbers:如果为 True,整数在格式化时将使用 _ 字符作为千位分隔符,否则不显示下划线。默认为 False。
4.2 参数详解
depth:深度
indent:缩进
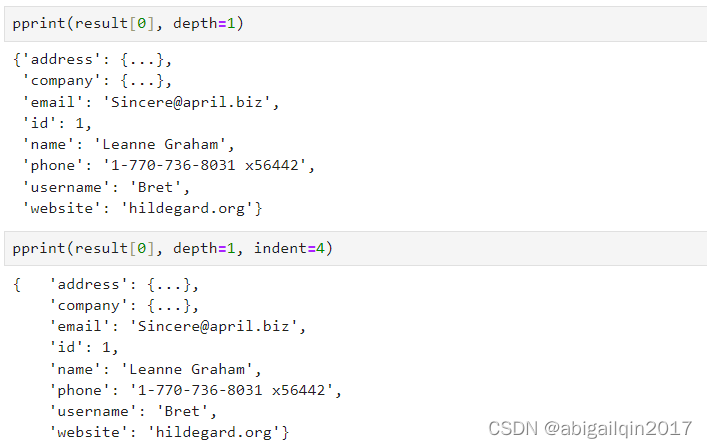
注:在这两个示例中,左花括号 { 被算为第一个键的缩进单位。在第一个示例中,第一个键的开始单引号紧跟在 { 之后,中间没有任何空格,因为缩进默认设置为1。
当存在嵌套时,缩进应用于行内的第一个元素,后续元素与第一个元素对齐。
如果将缩进设置为4,第一个元素将缩进四个字符,而第一个元素的嵌套内容将缩进超过八个字符,它的缩进是从第一个键的末尾开始的。
width:宽度
默认情况下,pprint() 每行最多只能输出80个字符,可以通过传入width参数来自定义此值。
pprint() 将努力将内容放在一行上,如果数据结构的内容超过了这个限制,那么它将在新的一行上打印当前数据结构的每个元素。width 的原则是在保证输出内容的可读性的前提下,尽可能地限制每行的宽度。这可以帮助我们在打印输出时避免过多的换行。
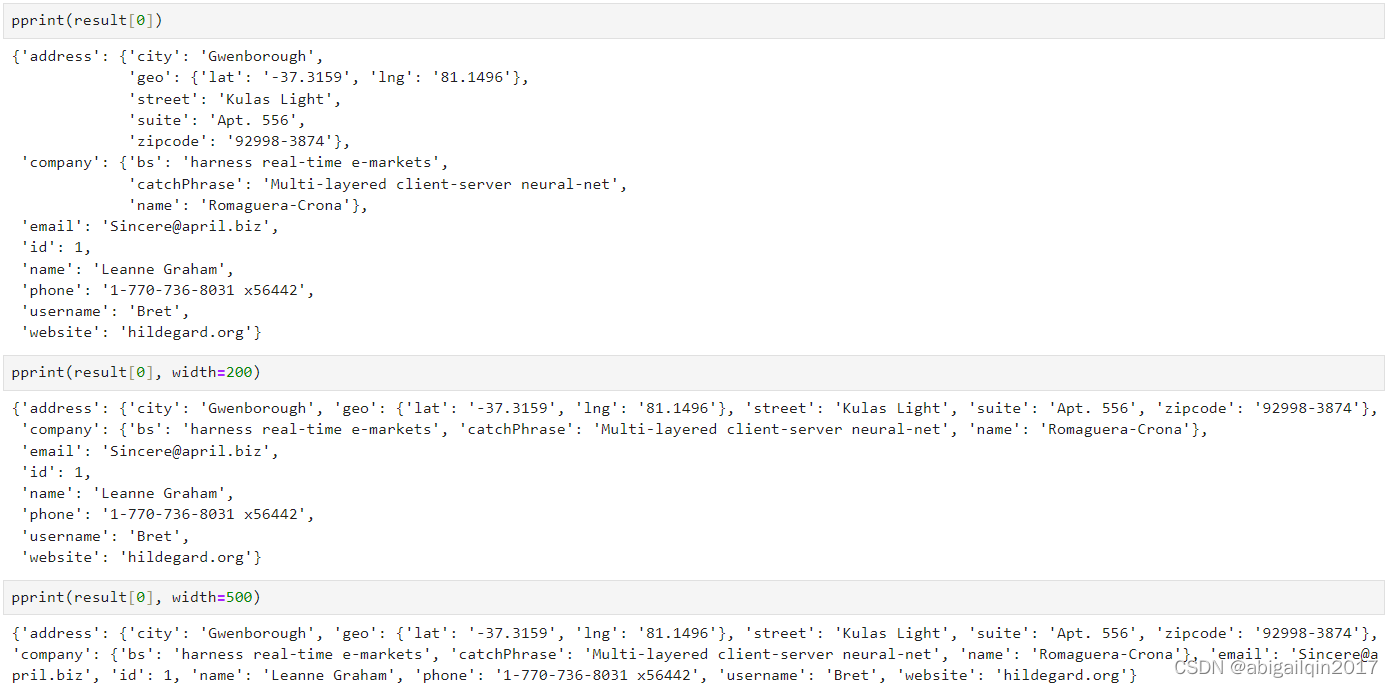
如果将宽度设置为较低的值,例如3,依然会得到美观的结果,这样做的主要效果是:每个数据结构都将在单独的行上显示。
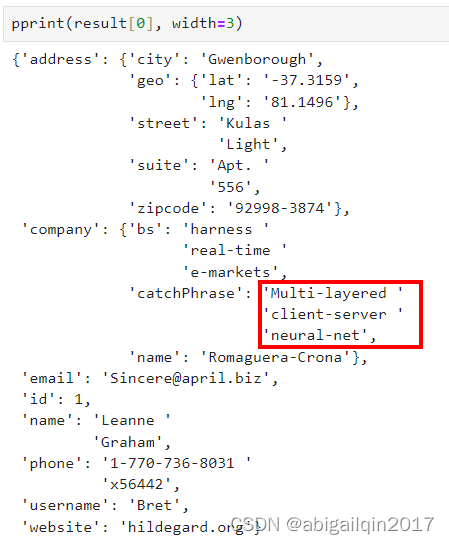
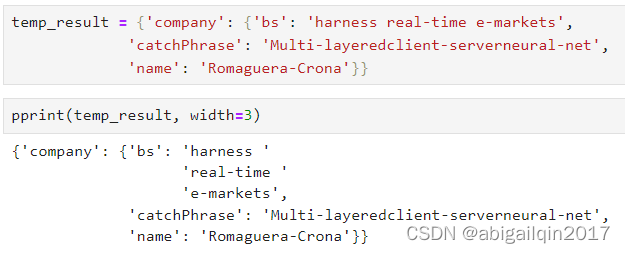
如果需要分割某个字符,pprint 会避免从中间分割字符串,那样会影响阅读,在当前的例子中,pprint 在空格处进行分割。
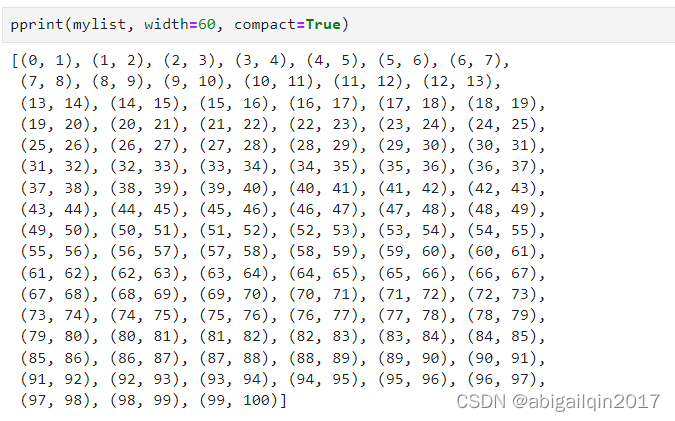
compact:Bool,是否采用紧凑模式
compact 参数则指定了是否使用紧凑模式,如果 compact 为 True,则输出的格式会更加紧凑,否则会更加易读。
from pprint import pprintmylist = [(i, i+1) for i in range(100)]
print(mylist)
pprint(mylist, width=60)
pprint(mylist, width=60, compact=True)

stream:输出位置
默认情况下,pprint() 的输出位置与 print() 相同,具体来说,指向 sys.stdout。不过,可以通过 stream 参数,将其重定向到任何文件对象或 logging 日志对象。
with open("output.txt", mode="w") as file_object:pprint(result, stream=file_object)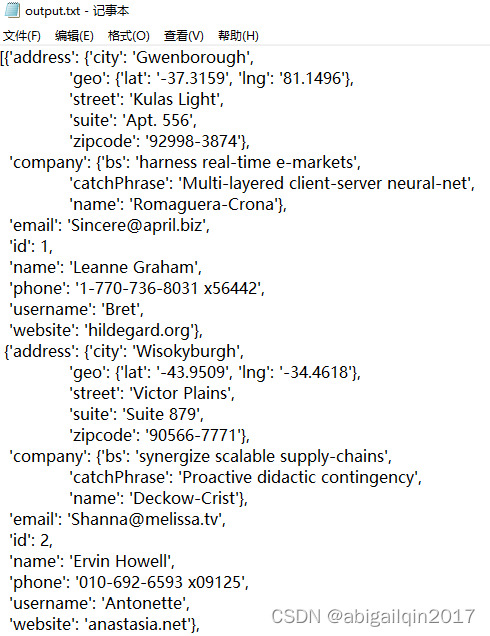
sort_dicts:Bool,字典是否需要排序(keys 首字母按字母表顺序排序)
pprint(result, sort_dicts=False)打印结果:

默认情况下,pprint() 将按字母顺序对键进行排序(sort_dicts = True),这能够保证每次打印时,输出的内容都是一样的。如果将 sort_dicts 设置为 False,字典是无序的,从理论上讲,每次打印时字典的键的顺序可能不同。
underscore_numbers:Bool,长数字是否需要下划线分隔符
注:某些版本直接调用 pprint() 时,使用这个参数有可能报错,后续的版本会解决。
5. pformat() 函数:输出字符串

代码示例-1:
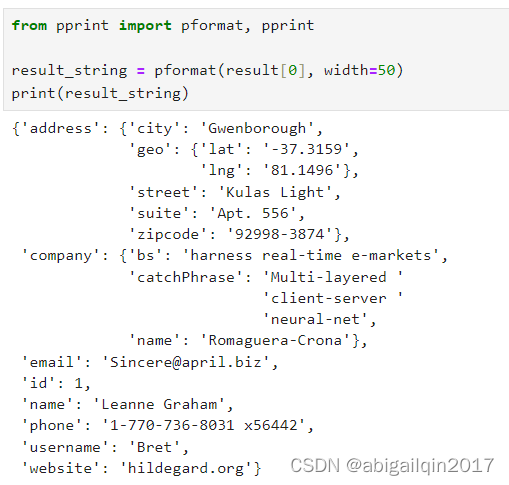
from pprint import pformat, pprintresult_string = pformat(result[0], width=50)
print(result_string)打印结果-1:
代码示例-2
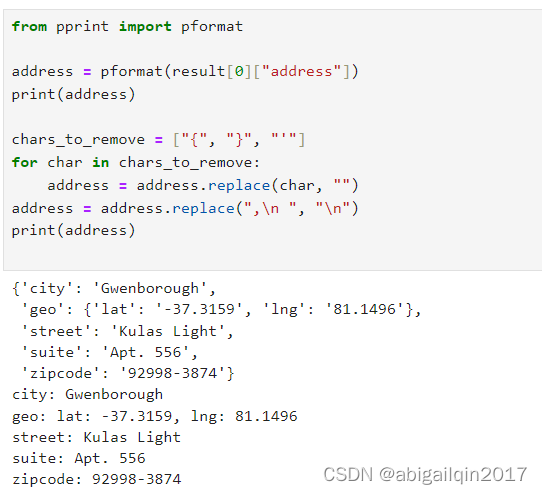
from pprint import pformataddress = pformat(result[0]["address"])
print(address)chars_to_remove = ["{", "}", "'"]
for char in chars_to_remove:address = address.replace(char, "")
address = address.replace(",\n ", "\n")
print(address)打印结果-2:
6. isreadable函数 和 isrecursive 函数
- isreadable 函数:输出布尔值, 表示是否可通过 eval 重构对象值,此函数对于递归对象总是返回 False。
- isrecursive 函数:输出布尔值, 表示 object 是否需要递归的表示。
代码示例:
from pprint import pprint, isreadable, isrecursive# 正常字典
pprint(result[0])
print(isreadable(result[0]))
print(isrecursive(result[0]))
print('\n')# 递归对象
stuff = ['spam', 'eggs', 'lumberjack', 'knights', 'ni']
stuff.insert(0, stuff)
pprint(stuff)
print(isreadable(stuff))
print(isrecursive(stuff))打印结果:

再举一个递归场景的例子:
from pprint import pprintA = {}
B = {"link": A}
A["link"] = B
print(A)
# {'link': {'link': {...}}}
pprint(A)
# {'link': {'link': <Recursion on dict with id=2747052595392>}}字典 A 存在循环引用,永远无法得到最终结果,因而也无法完成打印。处理这样的数据时,Python 的常规 print() 将缩写输出,pprint() 能够显式地通知用户这是一种递归表示,并提供字典的ID。
7. PrettyPrinter类

除了直接调用 pprint 函数,还可以创建 PrettyPrinter 的实例,该实例具有已定义的默认值,在需要的时候,调用实例的 .pprint() 方法即可。
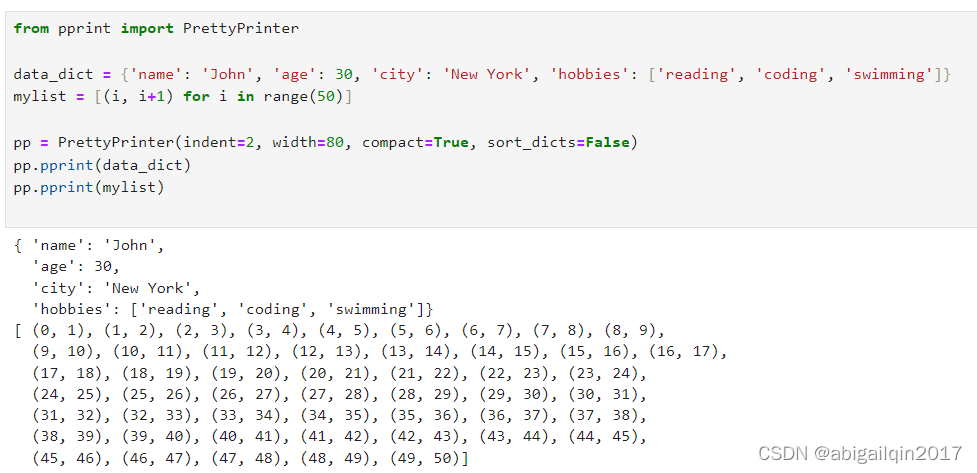
from pprint import PrettyPrinterdata_dict = {'name': 'John', 'age': 30, 'city': 'New York', 'hobbies': ['reading', 'coding', 'swimming']}
mylist = [(i, i+1) for i in range(50)]pp = PrettyPrinter(indent=2, width=80, compact=True, sort_dicts=False)
pp.pprint(data_dict)
pp.pprint(mylist)
打印结果:
8. 参考文档
已解决urllib模块设置代理ip_urllib2.request 设置代理-CSDN博客
Prettify Your Data Structures With Pretty Print in Python – Real Python