✨ 1: Qwen1.5-MoE
阿里巴巴一款小型 MoE 模型,只有 27 亿个激活参数,但性能与最先进的 7B 模型(如 Mistral 7B 和 Qwen1.5-7B)相匹配。
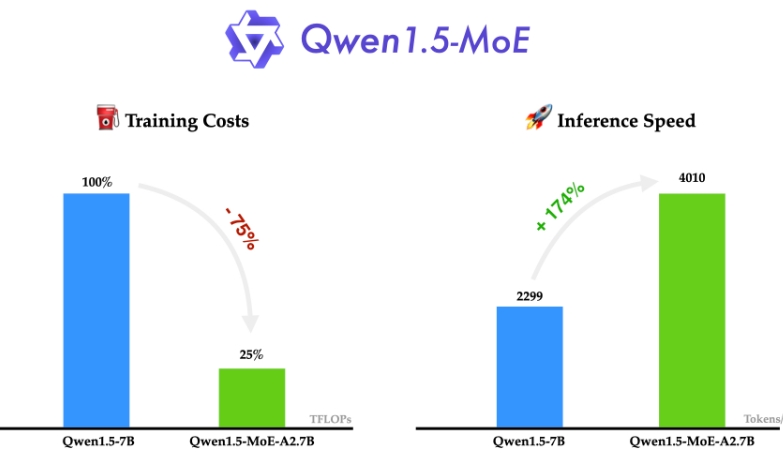
Qwen1.5-MoE是一个使用混合专家模型(Mixture-of-Experts,MoE)架构的尖端人工智能模型。本文简要地用通俗语言解释了Qwen1.5-MoE的功能及其应用场景。
博客: https://qwenlm.github.io/blog/qwen-moe/
HF: https://huggingface.co/Qwen
GitHub:https://github.com/QwenLM/Qwen1.5
地址:https://qwenlm.github.io/blog/qwen-moe/
✨ 2: lmsys
LMSYS Org(由UC伯克利主导)的研究团队正在举行一场前所未有的大语言模型排位赛。

LMSYS Org 是一个开放的研究组织,由加州大学伯克利分校、圣地亚哥分校和卡内基梅隆大学的学生与教师共同创立。该组织致力于通过开发开放数据集、模型、系统和评估工具,让每个人都能访问大型模型。他们的工作涵盖机器学习和系统方面的研究,包括训练大型语言模型并使其广泛可用,同时开发分布式系统来加速模型训练和推理过程。
过去一年,大语言模型在竞技场的排名浮沉:
GPT4 霸榜一整年!刚被opus超过
2023年5月 众多小厂开源选手百花齐放。但后续无力为继纷纷下榜
2023年8月 llama2登场
2023年9月 Claude2登场
2023年12月 GPT1106登场
2024年1月,Mistral登场
2024年3月,Claude3登场
地址:https://lmsys.org/
✨ 3: Grok-1.5
具备更强的推理能力和128,000词元的上下文长度,即将在𝕏平台提供

X AI 发布,Grok-1.5 是一个最新推出的人工智能模型,由xAI公司开发,能够理解长篇幅的文本和进行高级推理。总结它的功能和使用场景如下:
地址:https://x.ai/blog/grok-1.5
✨ 4: SSM-Transformer
AI21推出了首个生产级别的基于Mamba的模型Jamba,这是一个创新的SSM-Transformer混合架构模型

Jamba是由AI21推出的一种创新型混合SSM-Transformer模型,这是世界上第一个基于Mamba的生产级模型。Jamba通过将Mamba结构化状态空间模型(SSM)技术与传统的Transformer架构的元素结合起来,以弥补纯SSM模型固有的局限性。Jamba提供了超长的256K上下文窗口,已经在吞吐量和效率上展示了显著的增益,这只是这种创新混合架构所能带来可能性的开始。值得注意的是,Jamba在其大小级别的各种基准测试上表现出色,匹敌或超越了其他最先进的模型。
地址:https://www.ai21.com/blog/announcing-jamba
✨ 5: Scribble Diffusion
使用 AI 将您的粗略草图变成精致的图像
如果你不会画画,也没有关系! 有了这个工具,只需要画草图,就能帮助你生成一个彩色的图像,而且非常符合你的逻辑哦~ 这个在线工具采用了ControlNet机器学习模型来生成图像,通过大量的图像和文本数据的训练就能生成的高质量的图像!
地址:https://github.com/replicate/scribble-diffusion

更多AI工具,参考国内AiBard123,Github-AiBard123