自即日起,灵雀云正式推出大模型 LLMOps 平台 Alauda Machine Learning (简称 AML),AML在整合传统 MLOps 解决方案的基础之上,为大模型/大语言模型场景提供更强大、更易用的功能。灵雀云意在将AML打造成全面覆盖传统 MLOps与LLMOps 场景的全栈式开发运维平台,以满足不同场景下机器学习模型的开发、部署和运维需求,为企业的创新与发展注入强大动力。
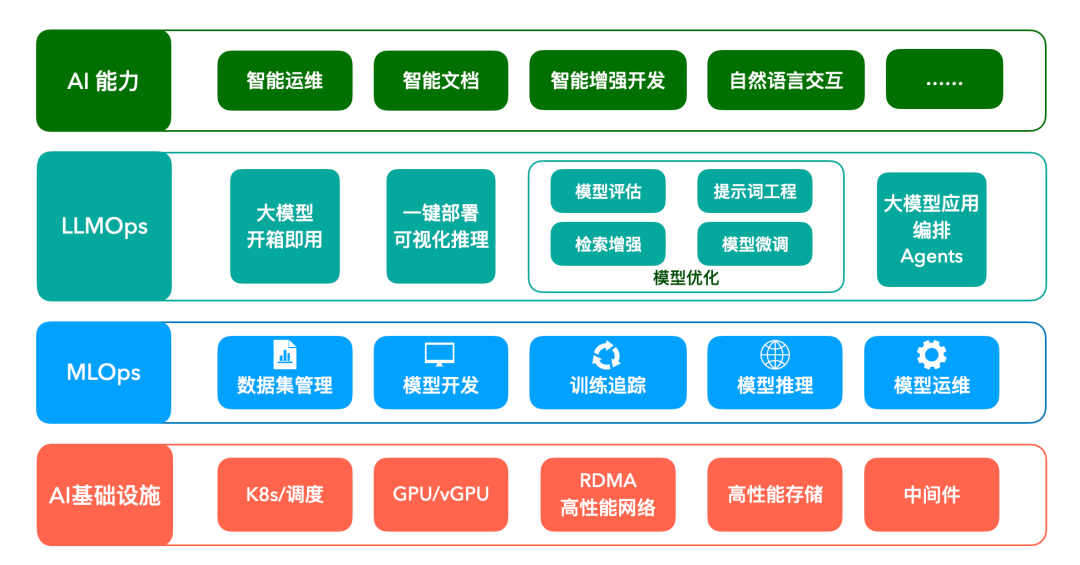
图示:AML产品架构图
引言
在过往的系列文章中,灵雀云已向广大读者深入阐述了RAG、Agent、GPU虚拟化等前沿概念与技术。随着人工智能技术的高速发展,大型语言模型已然成为该领域发展的重要趋势。大模型凭借其强大的学习与泛化能力,在自然语言处理、机器翻译、图像生成等诸多领域均取得了卓越的成就。然而,传统的MLOps工作流在应对大模型时代的挑战时,已显得力不从心。于是,灵雀云归纳并总结了LLMOps的工作流,以更好地适应大模型时代的需求。
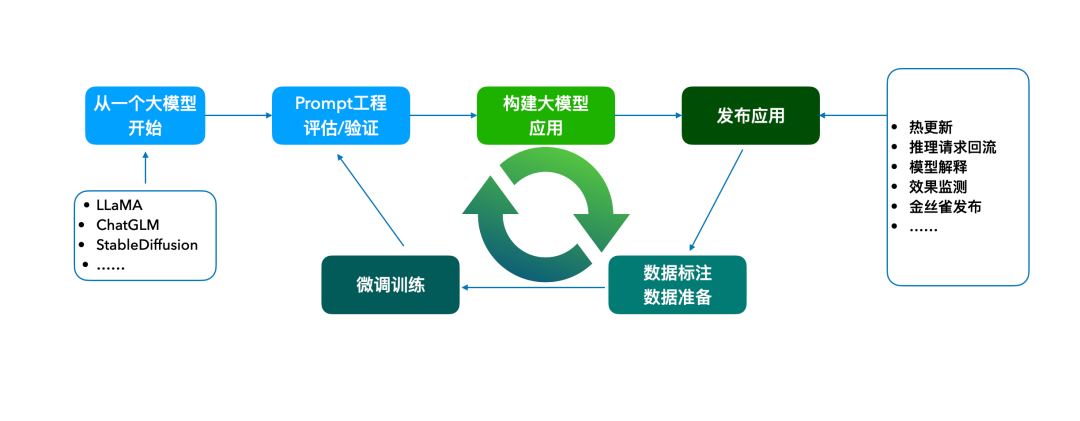
图示:LLMOps的工作流
LLMOps 工作流始于预训练的大模型,是整个流程的基础,模型质量会直接影响业务应用效果。接下来,通过专业的 prompt 设计技巧,对大模型进行多角度、多场景的测试验证,确保满足业务需求。若验证成功,可选择直接发布或构建应用后发布。对于资源丰富的团队,还可对大模型进行微调,利用专业数据集训练以适应特定领域,再进行验证后发布供业务团队使用。
假设发布一个用于药物推荐的问答模型,用户可以直接向模型提问,如“感冒了,应该吃点什么药?”大模型在接收到这类问题时,可能会根据其训练数据直接回复一些药品名称。然而,感冒的症状和病因多种多样,因此,用户需要大模型进行细致的分析并提供针对性的药品推荐。
为了引导大模型从专业的角度思考问题并输出更详细、准确的回答,用户可以优化提示词,例如:“你是一个药学专家,请针对问题中的病情,从不同的病因、症状角度出发,进行用药推荐。问题:我感冒了,应该吃点什么药?”这样的提示有助于模型更深入地分析问题,并给出专业的建议。
如果用户期望大模型的回答更贴近老中医的语言风格,可以利用大量的中医对话文本数据对模型进行微调。这些数据应包含老中医在解答患者问题时的语言习惯和表达方式。经过微调后,再结合prompt工程进行优化,模型最终输出的内容可能如下:
老朽乃一介中药学之老朽,今见尔感冒之疾,愿以老朽所知,为尔指点迷津。感冒之症,或因风邪、或因寒邪、或因热邪,症状亦有不同,需辨证施治,方能药到病除……
AML 对 LLMOps 工作流的每个环节均提供了全面的工具及底层技术支持,接下来本文将深入探究 AML 的具体能力。
模型仓库
LLMOps工作流的首要步骤是准备大模型,这一过程中,模型仓库发挥着关键作用,它不仅为模型提供存储空间,还进行高效管理。在模型仓库中,用户可以轻松查看模型详情、管理文件、控制版本等。值得一提的是,AML自带的模型仓库与HuggingFace模型完全兼容,并支持多种自定义模型格式。AML在交付时,会根据用户要求内置相应模型,实现开箱即用的便捷体验。同时,支持用户自主创建模型仓库,手动上传模型文件,
并在发布推理 API 后,在模型仓库详情中直接查看模型效果。目前支持 transformers 框架文本生成、文本分类、文本到图像类型的模型,后续版本中将不断更新,丰富支持的模型类型。用户也可以通过此功能手动调整prompt 工程以及参数,优化模型效果。
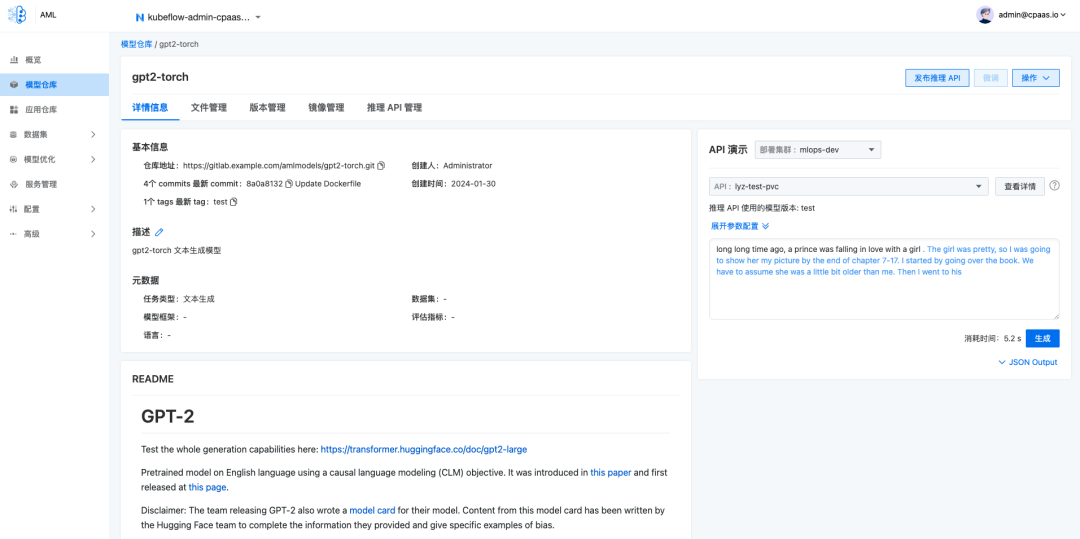
发布推理 API
LLMOps 工作流中的一个关键步骤是模型的推理服务发布,它确保了模型能够高效、稳定地在实际业务场景中运行。
AML 使用 Kserve、Seldon MLServer 和 Triton 作为推理运行时框架,因此,发布的 API 服务均使用统一的 Kserve V2 HTTP REST API 接口协议。也可以通过自定义 preprocessor、postprocesser 完成自定义的格式转换。
模型的推理服务可以通过模型仓库快速将推理 API 发布到已部署 AML 平台的集群中。在边缘集群需要推理服务的场景下,也可以将推理 API 构建成镜像进行发布。推理 API 运行过程中,支持在推理 API 详情中查看运行日志,辅助故障排查,也可以支持模型的版本热更新、自动扩容配置等操作。
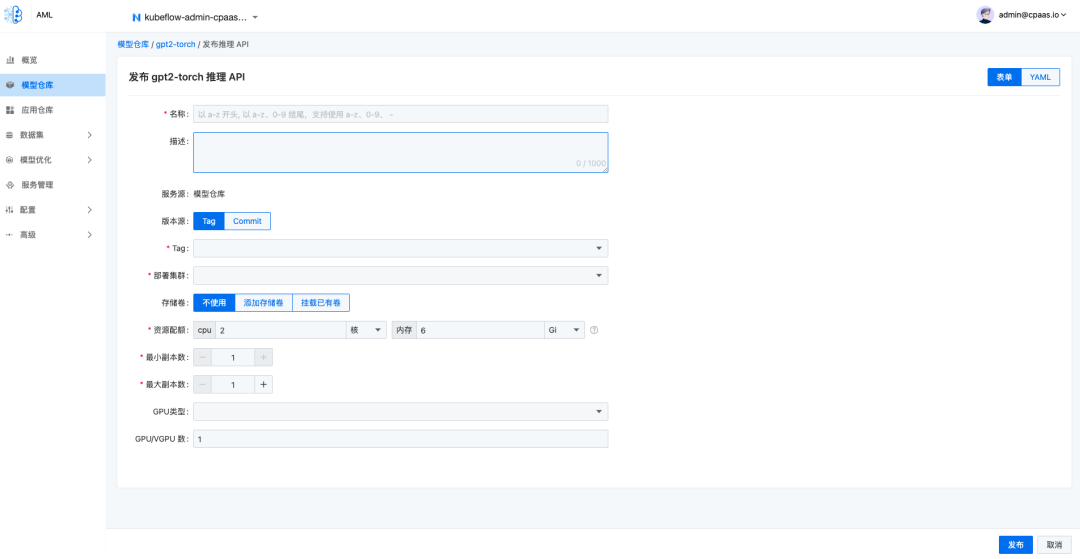
应用仓库
AML 应用仓库支持使用 Gradio, Streamlit 开发的大模型应用,以及使用 Docker 定义的任意 AI 应用的版本化管理和自动构建发布。在 LLMOps 的工作流应用构建步骤中,可以在 AML 应用仓库中创建应用,将应用代码上传至应用仓库中进行版本化管理、镜像构建、发布应用。
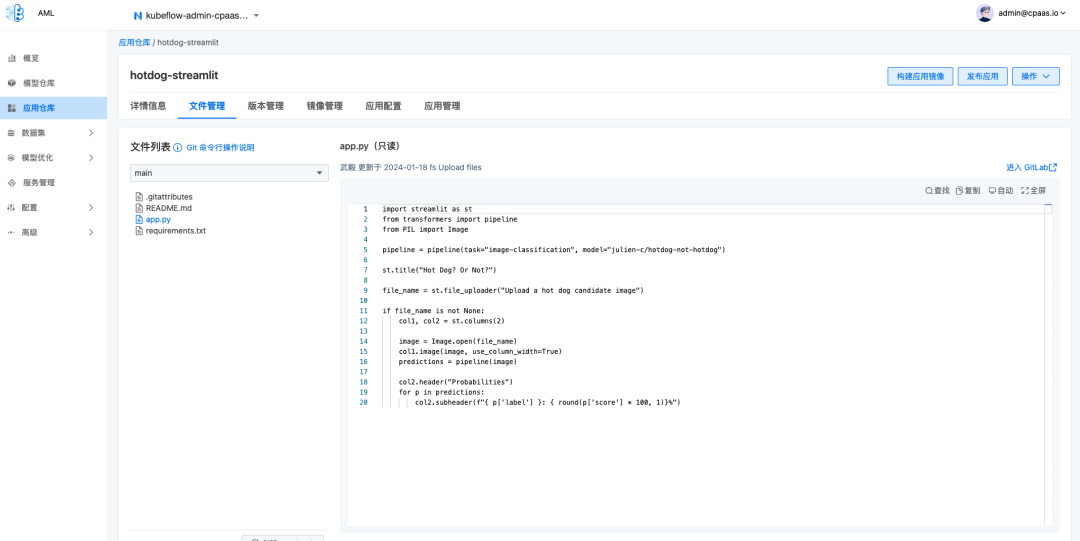
发布应用
在AML应用仓库页面中,支持将应用构建成镜像,并发布应用。由于部分应用需要进行环境变量或保密字典配置,因此支持创建应用配置,并以 Secrets 的方式挂载到应用中。在发布应用时也支持自定义配置环境变量。
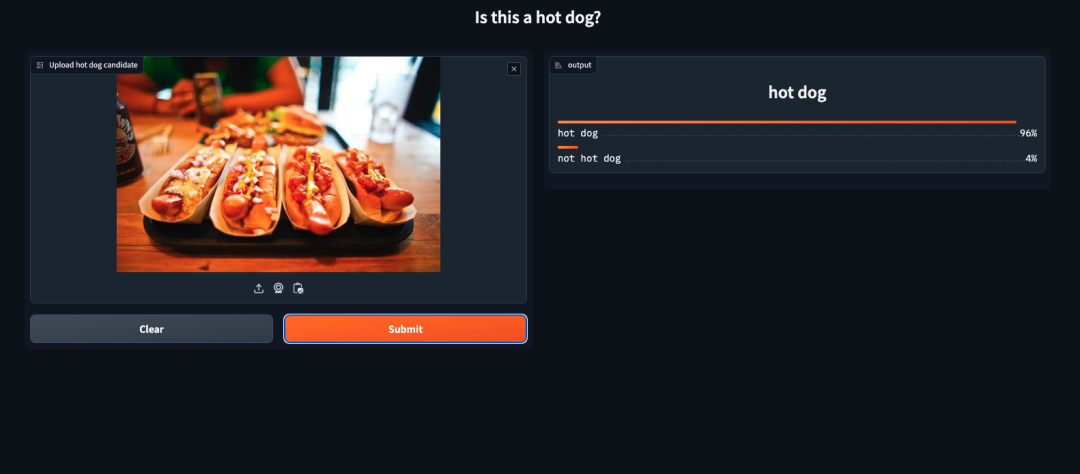
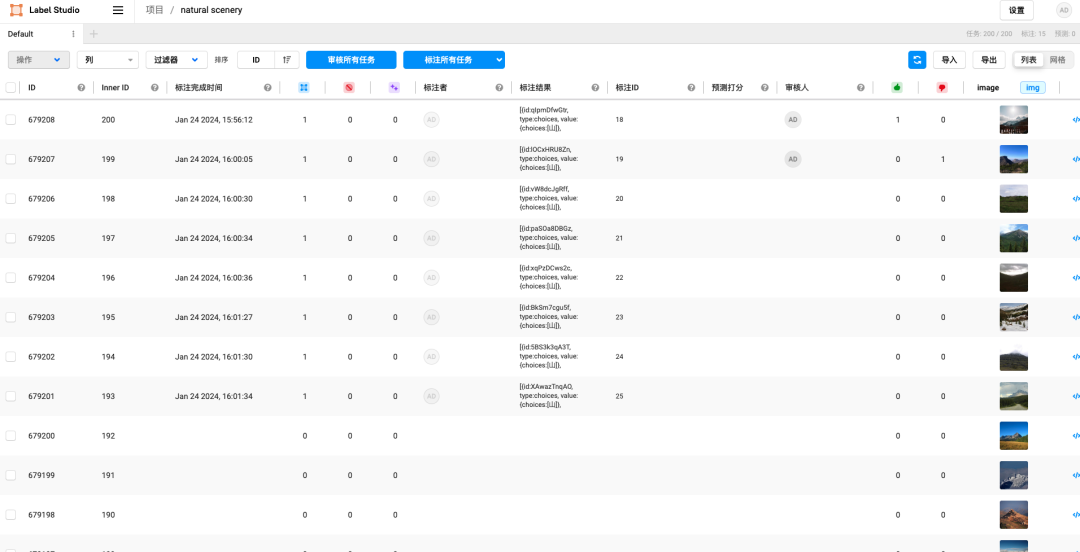
数据标注
AML 集成了 Label Studio 数据标注工具,可对接 S3 存储的各种训练数据类型。并支持多种类型数据和任务的协作标注工作,包含:机器视觉类模型、NLP、语音、音频、视频、对话 AI、Ranking 类模型、时间序列、结构化数据等。
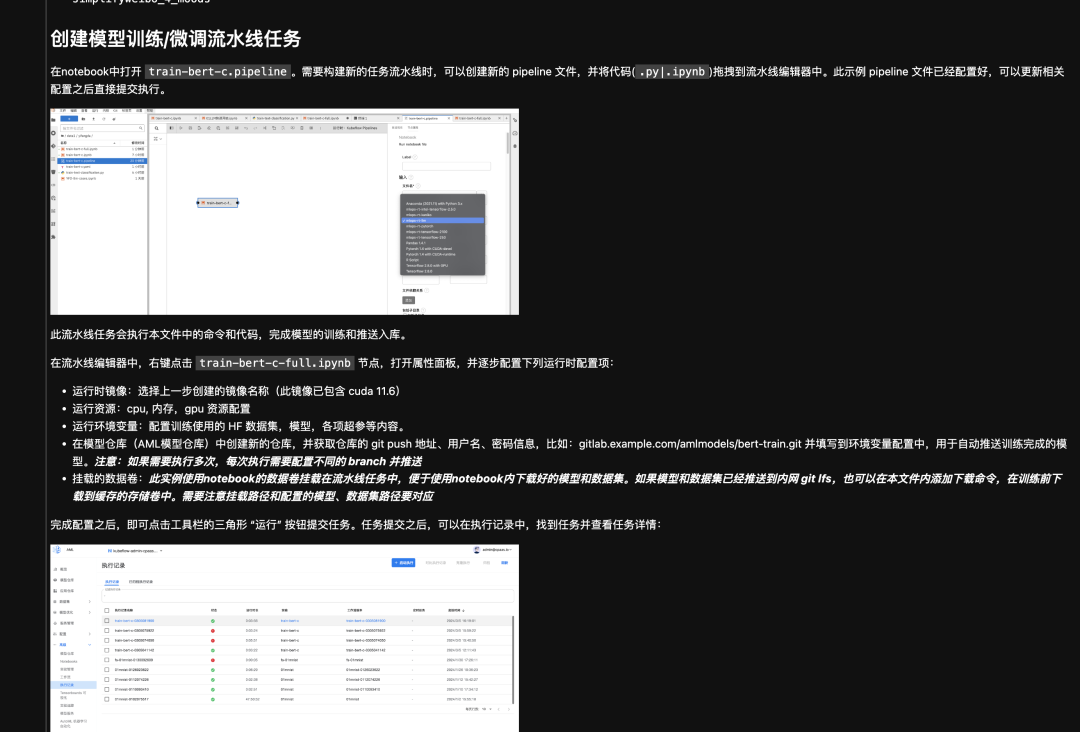
模型微调
大模型微调是使用专业领域的数据集对大模型进行进一步的训练,使其成为领域专家,在执行下游任务时,模型可以针对问题进行更专业的回答。AML提供了大模型微调的流程指导,包括:运行时镜像的构建、模型的下载、创建流水线任务等方法,帮助用户在模型仓库中快速启动微调任务。
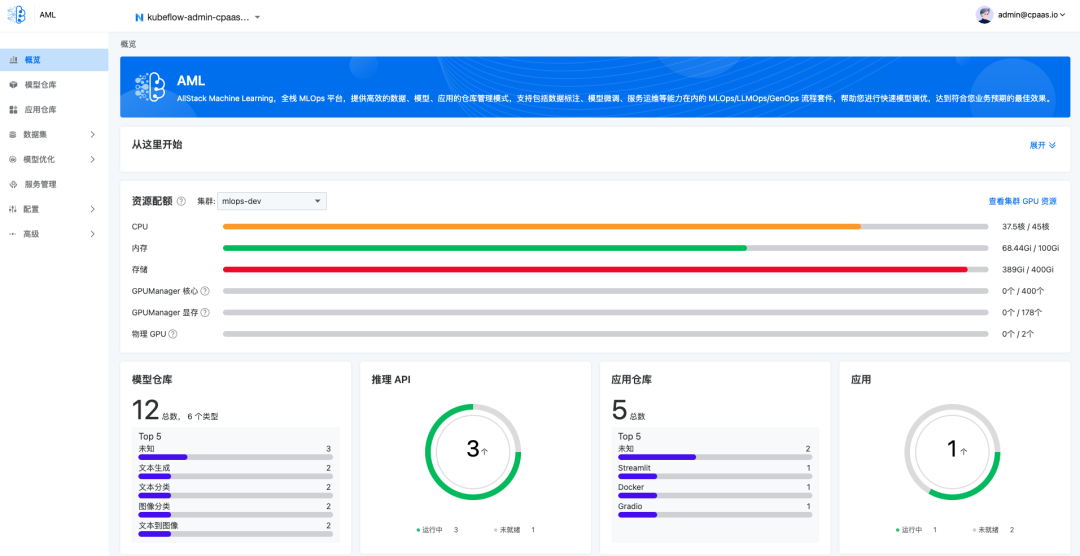
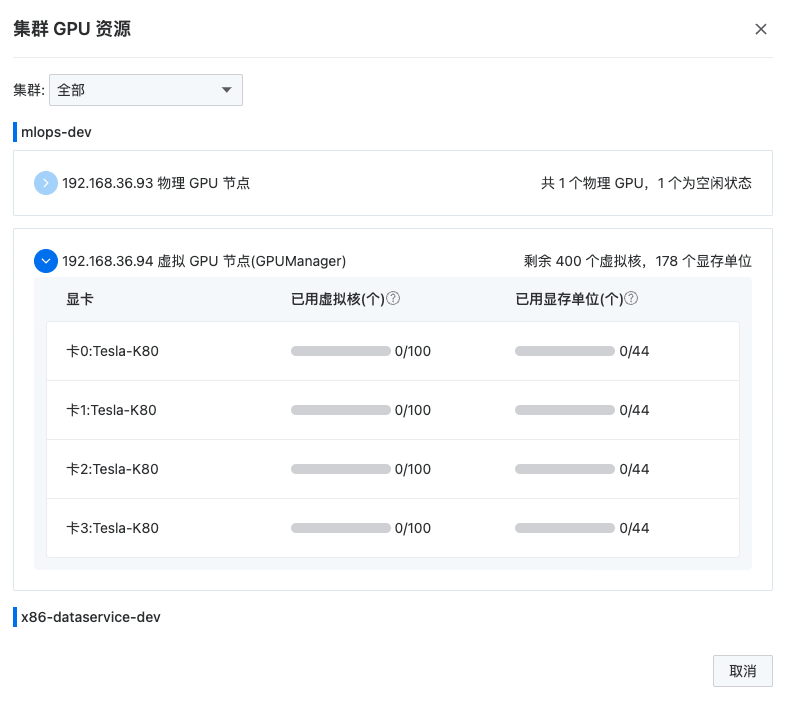
资产可视化
AML的概览页作为可视化的数据看板,清晰展示了用户资产统计信息。若ACP项目管理对AML平台命名空间设置了资源配额,概览页亦直观呈现配额与用量数据。同时,用户可便捷查看各集群中物理及虚拟GPU资源的使用情况,实现全面监控与高效管理。
结尾
AML v1.0 版本现已发布,全面涵盖上述各项功能及操作,满足基本的LLMOps场景需求。未来,灵雀云将致力于对LLMOps工作流中的其他关键环节进行持续迭代和优化,例如推出支持数据预览的数据集仓库、提供多样化的prompt方案、完善RAG和Agent功能,以及简化模型微调操作等。欢迎对AML及LLMOps工作流感兴趣的用户联系我们,扫描下方二维码,预约demo演示,共同探索更多可能性!