1. Hive是什么
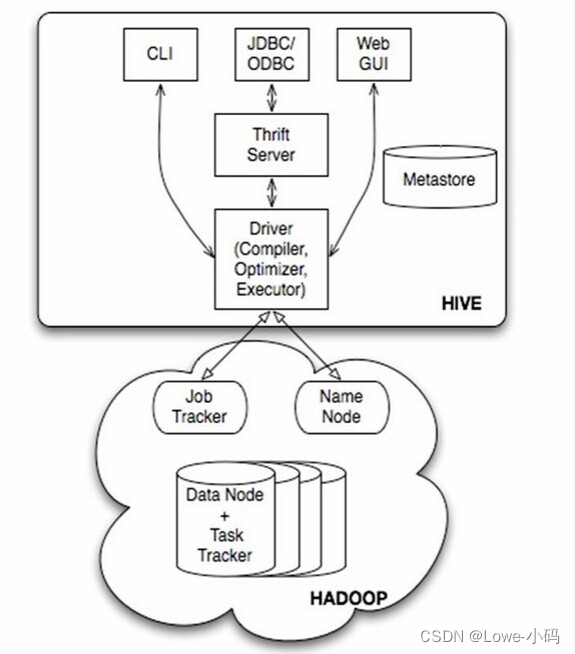
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
2. Hive擅长什么
Hive可以使用HQL(Hive SQL)很方便的完成对海量数据的统计汇总,即席查询和分析,除了很多内置的函数,还支持开发人员使用其他编程语言和脚本语言来自定义函数。
因此,Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即席查询,统计分析。
3. Hive的数据单元
- Databases:数据库。概念等同于关系型数据库的Schema,不多解释;
- Tables:表。概念等同于关系型数据库的表,不多解释;
- Partitions:分区。概念类似于关系型数据库的表分区,没有那么多分区类型,只支持固定分区,将同一组数据存放至一个固定的分区中。
- Buckets (or Clusters):分桶。同一个分区内的数据还可以细分,将相同的KEY再划分至一个桶中,这个有点类似于HASH分区,只不过这里是HASH分桶,也有点类似子分区吧。
4、Hive的数据库和表
1. Hive在HDFS上的默认存储路径
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse.
2. Hive中的数据库(Database)
- 进入Hive命令行,执行show databases;命令,可以列出hive中的所有数据库,默认有一个default数据库,进入Hive-Cli之后,即到default数据库下。
- 使用use databasename;可以切换到某个数据库下,同mysql;
- Hive中的数据库在HDFS上的存储路径为:
${hive.metastore.warehouse.dir}/databasename.db
比如,名为lxw1234的数据库存储路径为:
/user/hive/warehouse/lxw1234.db
- 创建Hive数据库
使用HDFS超级用户,进入Hive-Cli,语法为:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION hdfs_path][WITH DBPROPERTIES (property_name=property_value, ...)];- 修改数据库
修改数据库属性:
ALTER (DATABASE|SCHEMA) database_nameSET DBPROPERTIES (property_name=property_value, …);修改数据库属主:
ALTER (DATABASE|SCHEMA) database_nameSET OWNER [USER|ROLE] user_or_role;- 删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name[RESTRICT|CASCADE];3. Hive中的表(Table)
3.1 查看所有的表
进入Hive-Cli,使用use databasename;切换到数据库之后,执行show tables; 即可查看该数据库下所有的表:
3.2 表的存储路径
默认情况下,表的存储路径为:
${hive.metastore.warehouse.dir}/databasename.db/tablename/
可以使用desc formatted tablename;命令查看表的详细信息,其中包括了存储路径:
Location: hdfs://cdh5/hivedata/warehouse/lxw1234.db/lxw1234
3.3 内部表和外部表
Hive中的表分为内部表(MANAGED_TABLE)和外部表(EXTERNAL_TABLE)。
- 内部表和外部表最大的区别
内部表DROP时候会删除HDFS上的数据;
外部表DROP时候不会删除HDFS上的数据;
- 内部表适用场景:
Hive中间表、结果表、一般不需要从外部(如本地文件、HDFS上load数据)的情况。
- 外部表适用场景:
源表,需要定期将外部数据映射到表中。
- 我们的使用场景:
每天将收集到的网站日志定期流入HDFS文本文件,一天一个目录;
在Hive中建立外部表作为源表,通过添加分区的方式,将每天HDFS上的原始日志映射到外部表的天分区中;
在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
3.4 创建表
创建表的语法选项特别多,这里只列出常用的选项。
其他请参见Hive官方文档:
LanguageManual DDL - Apache Hive - Apache Software Foundation
以一个例子来说吧:
CREATE EXTERNAL TABLE t_lxw1234 (id INT,ip STRING COMMENT ‘访问者IP’,avg_view_depth DECIMAL(5,1),bounce_rate DECIMAL(6,5)) COMMENT ‘lxw的大数据田地-lxw1234.com’PARTITIONED BY (day STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ‘,’STORED AS textfileLOCATION ‘hdfs://cdh5/tmp/lxw1234/';- 关键字EXTERNAL:
表示该表为外部表,如果不指定EXTERNAL关键字,则表示内部表
- 关键字COMMENT
为表和列添加注释
- 关键字PARTITIONED BY
表示该表为分区表,分区字段为day,类型为string
- 关键字ROW FORMAT DELIMITED
指定表的分隔符,通常后面要与以下关键字连用:
FIELDS TERMINATED BY ‘,’ //指定每行中字段分隔符为逗号
LINES TERMINATED BY ‘\n’ //指定行分隔符
COLLECTION ITEMS TERMINATED BY ‘,’ //指定集合中元素之间的分隔符
MAP KEYS TERMINATED BY ‘:’ //指定数据中Map类型的Key与Value之间的分隔符
举个例子:
create table score(name string, score map<string,int>)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ‘\t’COLLECTION ITEMS TERMINATED BY ‘,’MAP KEYS TERMINATED BY ‘:';要加载的文本数据为:
biansutao ‘数学':80,’语文':89,’英语':95
jobs ‘语文':60,’数学':80,’英语':99
- 关键字STORED AS
指定表在HDFS上的文件存储格式,可选的文件存储格式有:
TEXTFILE //文本,默认值
SEQUENCEFILE // 二进制序列文件
RCFILE //列式存储格式文件 Hive0.6以后开始支持
ORC //列式存储格式文件,比RCFILE有更高的压缩比和读写效率,Hive0.11以后开始支持
PARQUET //列出存储格式文件,Hive0.13以后开始支持
- 关键词LOCATION
指定表在HDFS上的存储位置。
四、Hive的视图和分区
4.1 Hive中的视图
和关系型数据库一样,Hive中也提供了视图的功能,注意Hive中视图的特性,和关系型数据库中的稍有区别:
- 只有逻辑视图,没有物化视图;
- 视图只能查询,不能Load/Insert/Update/Delete数据;
- 视图在创建时候,只是保存了一份元数据,当查询视图的时候,才开始执行视图对应的那些子查询;
4.1.1 创建视图
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], …) ][COMMENT view_comment][TBLPROPERTIES (property_name = property_value, …)]AS SELECT …;例如:
CREATE VIEW IF NOT EXISTS v_lxw1234 (url COMMENT ‘url’)COMMENT ‘view lxw1234′AS SELECT url FROM lxw1234WHERE url LIKE ‘http://%’LIMIT 100;4.1.2 删除视图
DROP VIEW IF EXISTS v_lxw1234;4.1.3 修改视图
ALTER VIEW v_lxw1234 ASSELECT url FROM lxw1234 limit 500;4.2 Hive中的表分区
Hive中的表分区比较简单,就是将同一组数据放到同一个HDFS目录下,当查询中过滤条件指定了某一个分区值时候,只将该分区对应的目录作为Input,从而减少MapReduce的输入数据,提高查询效率。
4.2.1 创建分区表
CREATE EXTERNAL TABLE t_lxw1234 (id INT,ip STRING COMMENT ‘访问者IP’,avg_view_depth DECIMAL(5,1),bounce_rate DECIMAL(6,5)) COMMENT ‘lxw的大数据田地-lxw1234.com’PARTITIONED BY (month STRING, day STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ‘,’STORED AS textfile;- 在创建表时候,使用PARTITIONED BY关键字来指定该表为分区表,后面括号中指定了分区的字段和类型,分区字段可以有多个,在HDFS中对应多级目录。
- 比如,上面的表t_lxw1234分区month=’2015-06’,day=’2015-06-15’对应HDFS上的路径为:/user/hive/warehouse/default.db/t_lxw1234/month=2015-06/day=2015-06-15/,当查询中指定了month=’2015-06’ AND day=’2015-06-15’,MapReduce直接从该目录中读取数据,如果只指定了month=’2015-06’,那么MapReduce将/month=2015-06/下所有的子目录都作为Input。
4.2.2 添加分区
- 使用INSERT添加分区:
往分区中追加数据:INSERT INTO TABLE t_lxw1234 PARTITION (month = ‘2015-06′,day = ‘2015-06-15′)SELECT * FROM dual;覆盖分区数据:INSERT overwrite TABLE t_lxw1234 PARTITION (month = ‘2015-06′,day = ‘2015-06-15′)SELECT * FROM dual;- 使用ALTER TABLE添加分区:
ALTER TABLE t_lxw1234 ADD PARTITION (month = ‘2015-06′,day = ‘2015-06-15′) location ‘hdfs://namenode/tmp/lxw1234/month=2015-06/day=2015-06-15/';4.2.3 查看分区对应的HDFS路径
- 使用命令 show partitions t_lxw1234; 查看表的所有分区:
hive> show partitions t_lxw1234;
OK
month=2015-01/day=2015-01-25
month=2015-01/day=2015-01-31
month=2015-02/day=2015-02-15
month=2015-02/day=2015-02-28
month=2015-03/day=2015-03-15
month=2015-03/day=2015-03-31
- 使用desc formatted t_lxw1234 partition (month = ‘2015-01’ , day = ‘2015-01-25′);
查看该分区的详细信息,包括该分区在HDFS上的路径:
Location: hdfs://namenode/user/hive/warehouse/default.db/t_lxw1234/month=2015-01/day=2015-01-25/
4.2.4 删除分区
可以使用 ALTER TABLE t_lxw1234 DROP PARTITION (month = ‘2015-01’, day = ‘2015-01-25’);
删除一个分区;
同内部表和外部表,如果该分区表为外部表,则分区对应的HDFS目录数据不会被删除。
5.Hive SQL的优化
使用分区剪裁、列剪裁
在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤,比如:
SELECT a.idFROM lxw1234_a aleft outer join t_lxw1234_partitioned bON (a.id = b.url);WHERE b.day = ‘2015-05-10′正确的写法是写在ON后面:
SELECT a.idFROM lxw1234_a aleft outer join t_lxw1234_partitioned bON (a.id = b.url AND b.day = ‘2015-05-10′);或者直接写成子查询:
SELECT a.idFROM lxw1234_a aleft outer join (SELECT url FROM t_lxw1234_partitioned WHERE day = ‘2015-05-10′) bON (a.id = b.url)5.1 少用COUNT DISTINCT
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换:
SELECT day,COUNT(DISTINCT id) AS uvFROM lxw1234GROUP BY day可以转换成:SELECT day,COUNT(id) AS uvFROM (SELECT day,id FROM lxw1234 GROUP BY day,id) aGROUP BY day;虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
5.2 是否存在多对多的关联
只要遇到表关联,就必须得调研一下,是否存在多对多的关联,起码得保证有一个表或者结果集的关联键不重复。
如果某一个关联键的记录数非常多,那么分配到该Reduce Task中的数据量将非常大,导致整个Job很难完成,甚至根本跑不出来。
还有就是避免笛卡尔积,同理,如果某一个键的数据量非常大,也是很难完成Job的。
5.3 避免数据倾斜
数据倾斜是Hive开发中对性能影响的一大杀手。
- 症状:
任务迚度长时间维持在99%(或100%);
查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。
本地读写数据量很大。
- 导致数据倾斜的操作:
GROUP BY, COUNT DISTINCT, join
- 原因:
key分布不均匀
业务数据本身特点
这里列出一些常用的数据倾斜解决办法:
- 使用COUNT DISTINCT和GROUP BY造成的数据倾斜:
存在大量空值或NULL,或者某一个值的记录特别多,可以先把该值过滤掉,在最后单独处理:
SELECT CAST(COUNT(DISTINCT imei)+1 AS bigint)
FROM lxw1234 where pt = ‘2012-05-28′
AND imei <> ‘lxw1234′ ;
比如某一天的IMEI值为’lxw1234’的特别多,当我要统计总的IMEI数,可以先统计不为’lxw1234’的,之后再加1.
多重COUNT DISTINCT
通常使用UNION ALL + ROW_NUMBER() + SUM + GROUP BY来变通实现。
- 使用JOIN引起的数据倾斜
关联键存在大量空值或者某一特殊值,如”NULL”
空值单独处理,不参与关联;
空值或特殊值加随机数作为关联键;
不同数据类型的字段关联
转换为同一数据类型之后再做关联