自动化处理Excel工作簿
(一)批量生产产品出货清单
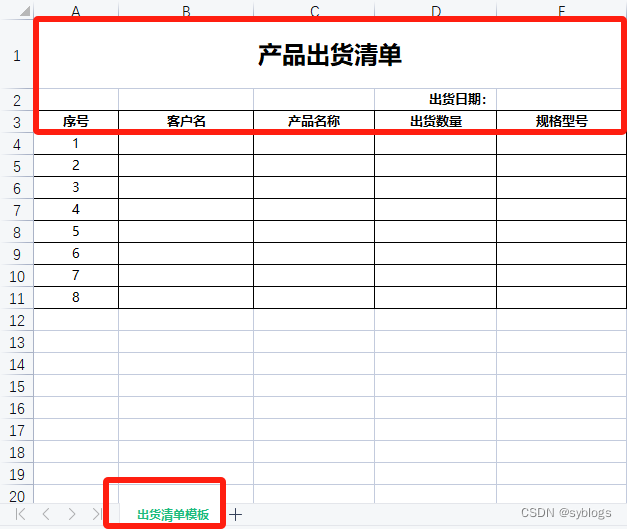
以“出货统计表”为例, 需求:将出货记录按照出货日期分类整理成多张出货清单
“出货统计表数据案例”
“产品出货清单模板”
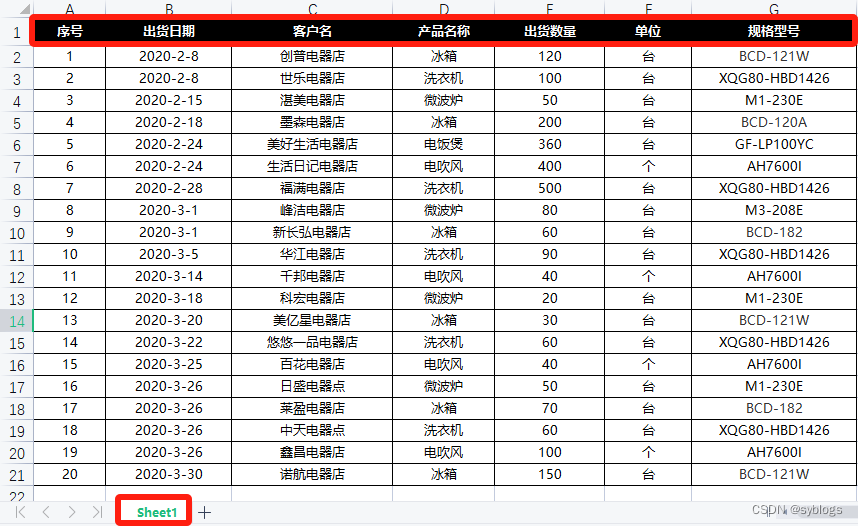
1.提取出货统计表的数据
“Python程序代码”
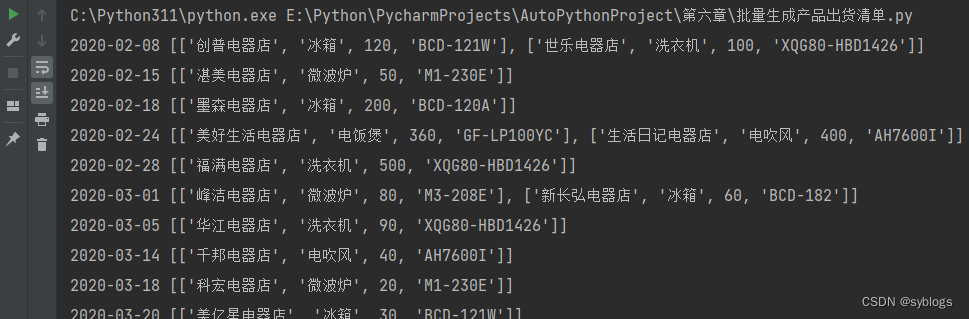
# 使用Python第三方模块openpyxl来操控Excel文件 from openpyxl import load_workbook# 1.0 读取工作簿“xxx.xlsx”中的数据 workbook = load_workbook("D:\\pppp\\第6章\\出货统计表.xlsx") worksheet = workbook["Sheet1"]# 2.0 对工作表中的出货记录按照出货日期进行分类整理,使用字典来组织数据 # 2.1 创建一个空字典data data = {} # 2.2 遍历工作表中数据的第2行到最后一行 for row in range(2, worksheet.max_row + 1):date = worksheet["B" + str(row)].value.date()customer = worksheet["C" + str(row)].valueproduct = worksheet["D" + str(row)].valuenumber = worksheet["E" + str(row)].valuemodel = worksheet["G" + str(row)].valueinfo_list = [customer, product, number, model]# 2.3将出货日期作为键,在遍历到具有相同出货日期的出货记录时,不覆盖原来的键(出货日期),而是将其添加到后面的空列表中,形成嵌套列表data.setdefault(date, [])data[date].append(info_list)# 3.0控制台输出字典的键值对,查看运行效果 for key, value in data.items():print(key, value)“运行效果展示”
2.使用for语句创建产品出货清单
“Python程序代码”
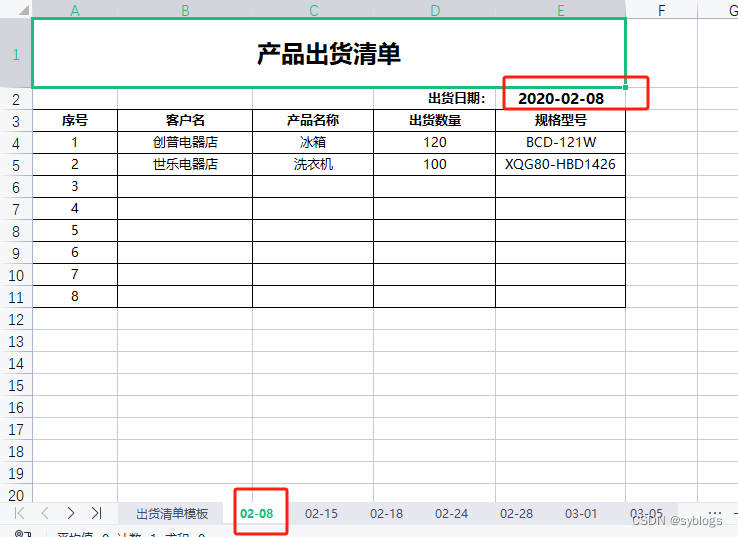
# 4.0 打开工作簿"出货清单模板.xlsx",并读取其中的工作表"出货清单模板" workbook_day = load_workbook("D:\\pppp\\第6章\\出货清单模板.xlsx") worksheet_day = workbook_day["出货清单模板"]# 5.0 按照出货日期遍历字典数据,复制工作表“出货清单模板”并进行重命名,再将出货日期写入出货清单 for date in data.keys():worksheet_new = worksheet_day.copy_worksheet(worksheet_day)worksheet_new.title = str(date)[-5:]worksheet_new.cell(row=2, column=5).value = date# 6.0 从第4行开始逐行填写出货记录i = 4for product in data[date]:worksheet_new.cell(row=i, column=2).value = product[0]worksheet_new.cell(row=i, column=3).value = product[1]worksheet_new.cell(row=i, column=4).value = product[2]worksheet_new.cell(row=i, column=5).value = product[3]i += 1 # 7.0 所有数据填写完毕,另存工作簿 worksheet_day.save("D:\\pppp\\第6章\\产品出货清单.xlsx")“查看工作簿”
3.完整代码
# 使用Python第三方模块openpyxl来操控Excel文件 from openpyxl import load_workbook# 1.0 读取工作簿“xxx.xlsx”中的数据 workbook = load_workbook("D:\\pppp\\第6章\\出货统计表.xlsx") worksheet = workbook["Sheet1"]# 2.0 对工作表中的出货记录按照出货日期进行分类整理,使用字典来组织数据 # 2.1 创建一个空字典data data = {} # 2.2 遍历工作表中数据的第2行到最后一行 for row in range(2, worksheet.max_row + 1):date = worksheet["B" + str(row)].value.date()customer = worksheet["C" + str(row)].valueproduct = worksheet["D" + str(row)].valuenumber = worksheet["E" + str(row)].valuemodel = worksheet["G" + str(row)].valueinfo_list = [customer, product, number, model]# 2.3将出货日期作为键,在遍历到具有相同出货日期的出货记录时,不覆盖原来的键(出货日期),而是将其添加到后面的空列表中,形成嵌套列表data.setdefault(date, [])data[date].append(info_list)# 3.0控制台输出字典的键值对,查看运行效果 for key, value in data.items():print(key, value)# 4.0 打开工作簿"出货清单模板.xlsx",并读取其中的工作表"出货清单模板" workbook_day = load_workbook("D:\\pppp\\第6章\\出货清单模板.xlsx") worksheet_day = workbook_day["出货清单模板"]# 5.0 按照出货日期遍历字典数据,复制工作表“出货清单模板”并进行重命名,再将出货日期写入出货清单 for date in data.keys():worksheet_new = workbook_day.copy_worksheet(worksheet_day)worksheet_new.title = str(date)[-5:]worksheet_new.cell(row=2, column=5).value = date# 6.0 从第4行开始逐行填写出货记录i = 4for product in data[date]:worksheet_new.cell(row=i, column=2).value = product[0]worksheet_new.cell(row=i, column=3).value = product[1]worksheet_new.cell(row=i, column=4).value = product[2]worksheet_new.cell(row=i, column=5).value = product[3]i += 1 # 7.0 所有数据填写完毕,另存工作簿 workbook_day.save("D:\\pppp\\第6章\\产品出货清单.xlsx")
(二)批量替换工作簿的单元格数据
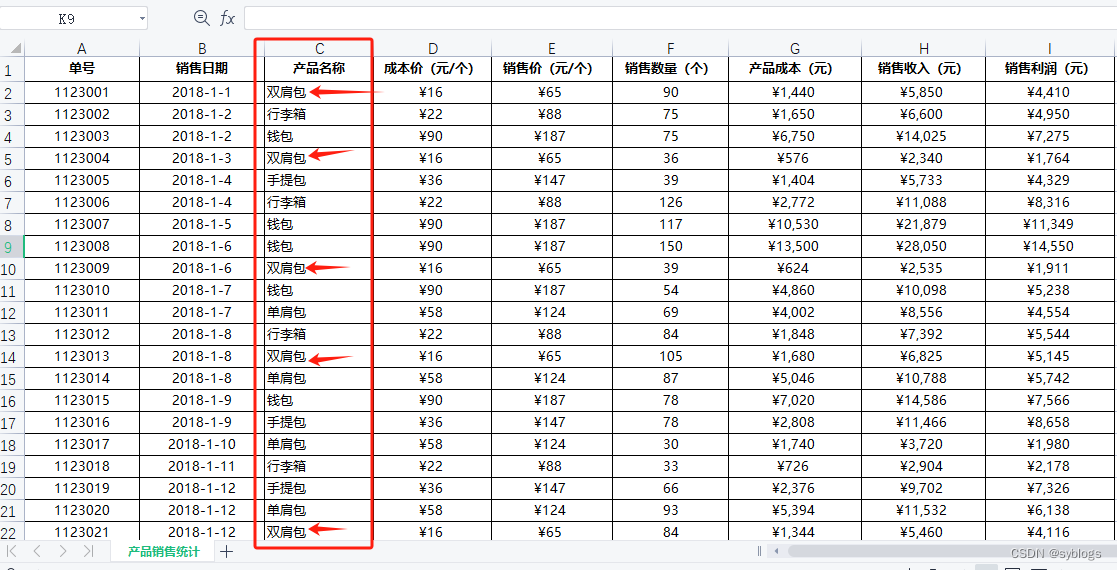
对多个工作簿进行批量单元格数据替换操作。以“月销售统计”为例,将单元格中的数据“背包”替换为“双肩包”
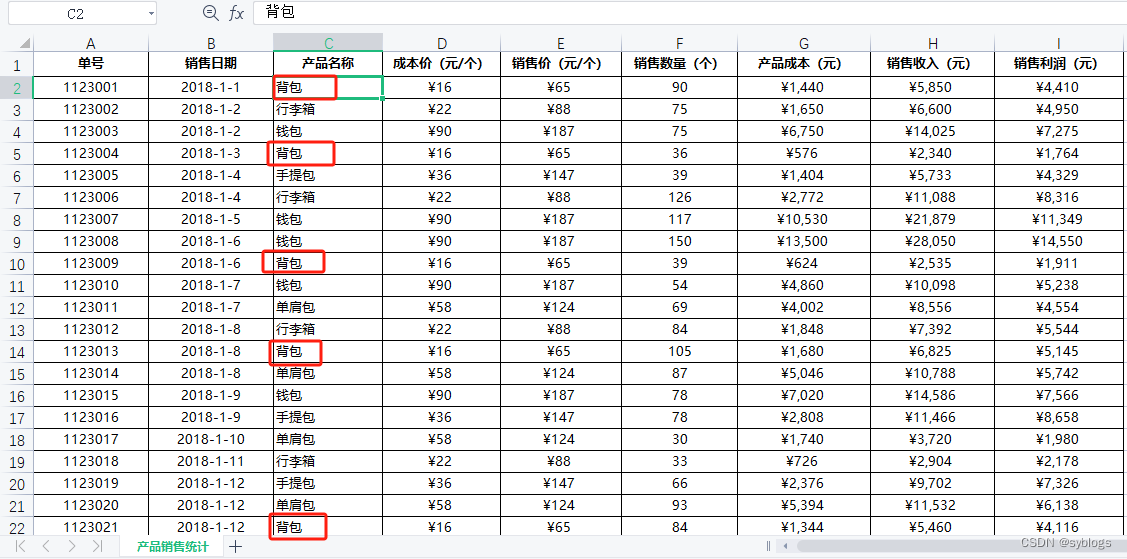
可操控Excel的Python模块很多,例如:
功能 XlsxWriter xlrd
xlwt xlutils openpyxl xlwings 读 × √ × √ √ √ 写 √ × √ √ √ √ 修改 × × × √ √ √ 支持xls格式 × √ √ √ × √ 支持xlsx格式 √ √ √ × √ √ 支持批量操作 × × × × × √
“Python程序代码”
""" 将工作簿中的单元格数据替换为其他内容 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块xlwings来操控Excel文件 import xlwings as xw# 1.0 列出文件夹中的所有工作簿,启动Excel程序窗口,并不新建工作簿 src_folder = Path("D:\\pppp\\第6章\\月销售统计\\") file_list = list(src_folder.glob("*.xlsx")) # visible用于设置Excel程序窗口的可见性;add_book用于设置启动Excel程序窗口后是否新建工作簿 app = xw.App(visible=False, add_book=False)# 2.0 依次打开列表中的文件。Excel文件打开一个工作簿同时生成一个文件名以“~$”开头的临时文件 for i in file_list:# 跳过这类临时文件if i.name.startswith("~$"):continue# 打开工作不文件workbook = app.books.open(i)# 3.0 批量替换数据# 逐个遍历工作表for j in workbook.sheets:# 以单元格"A2"为起点,从工作表中读取所有数据,存储到变量data中data = j["A2"].expand("table").value# enumerate()是Python的内置函数,用于将一个可遍历的数据对象(如列表、元组、字符串等)组合为一个索引序列,可同时得到数据对象的索引及对应的值# index代表行号(从0开始),而val代表data中的小列表(即一行数据)for index, val in enumerate(data):# 列表中的元素索引是从0开始编号的,要替换的数据位于第3列,即设置2if val[2] == "背包":val[2] = "双肩包"data[index] = val# 将大列表写入工作表,用完成替换的数据覆盖原数据j["A2"].expand("table").value = data# 4.0 使用save()函数保存工作簿workbook.save()# 5.0 使用close()关闭工作簿workbook.close() # 6.0 使用quit()函数退出Excel程序 app.quit()“查看运行结果”
(三)将多个工作表合并为一个工作表
将多个工作簿中的同名工作表快速合并为一个工作表,并保存为一个新的工作簿
1.使用xlwings模块读取多个工作表中的数据
""" 将多个工作簿中的同名工作表快速合并为一个工作表,并保存为一个新的工作簿 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块xlwings来操控Excel文件 import xlwings as xw# 1.0 列出文件夹中的所有工作簿,启动Excel程序窗口,并不新建工作簿 src_folder = Path("D:\\pppp\\第6章\\月销售统计\\") file_list = list(src_folder.glob("*.xlsx")) # visible用于设置Excel程序窗口的可见性;add_book用于设置启动Excel程序窗口后是否新建工作簿 app = xw.App(visible=False, add_book=False)# 2.0 依次打开工作簿,读取指定工作表中的数据,并合并在一起 sheet_name = "产品销售统计" # 用于存放合并数据的列标题。None在Python中表示一个空对象 header = None all_data = [] for i in file_list:if i.name.startswith("~&"):continueworkbook = app.books.open(i)for j in workbook.sheets:if j.name == sheet_name:if header is None:header = j["A1:I1"].valuedata = j["A2"].expand("table").valueall_data = all_data + data# 3.0 使用close()关闭工作簿workbook.close()
2.新建工作簿存放合并后的数据
# 4.0 创建一个新的工作簿来存储这些数据 new_workbook = xw.Book() new_worksheet = new_workbook.sheets.add(sheet_name) new_worksheet["A1"].value = header new_worksheet["A2"].value = all_data # 使用工作表对象函数autofit()自动调整工作表的列宽和行高 new_worksheet.autofit() new_workbook.save(src_folder / "上半年产品销售统计表.xlsx") new_workbook.close()# 6.0 使用quit()函数退出Excel程序 app.quit()
3.完整代码
""" 将多个工作簿中的同名工作表快速合并为一个工作表,并保存为一个新的工作簿 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块xlwings来操控Excel文件 import xlwings as xw# 1.0 列出文件夹中的所有工作簿,启动Excel程序窗口,并不新建工作簿 src_folder = Path("D:\\pppp\\第6章\\月销售统计\\") file_list = list(src_folder.glob("*.xlsx")) # visible用于设置Excel程序窗口的可见性;add_book用于设置启动Excel程序窗口后是否新建工作簿 app = xw.App(visible=False, add_book=False)# 2.0 依次打开工作簿,读取指定工作表中的数据,并合并在一起 sheet_name = "产品销售统计" # 用于存放合并数据的列标题。None在Python中表示一个空对象 header = None all_data = [] for i in file_list:if i.name.startswith("~&"):continueworkbook = app.books.open(i)for j in workbook.sheets:if j.name == sheet_name:if header is None:header = j["A1:I1"].valuedata = j["A2"].expand("table").valueall_data = all_data + data# 3.0 使用close()关闭工作簿workbook.close()# 4.0 创建一个新的工作簿来存储这些数据 new_workbook = xw.Book() new_worksheet = new_workbook.sheets.add(sheet_name) new_worksheet["A1"].value = header new_worksheet["A2"].value = all_data # 使用工作表对象函数autofit()自动调整工作表的列宽和行高 new_worksheet.autofit() new_workbook.save(src_folder / "上半年产品销售统计表.xlsx") new_workbook.close()# 6.0 使用quit()函数退出Excel程序 app.quit()
(四)将一个工作表拆分为多个工作簿
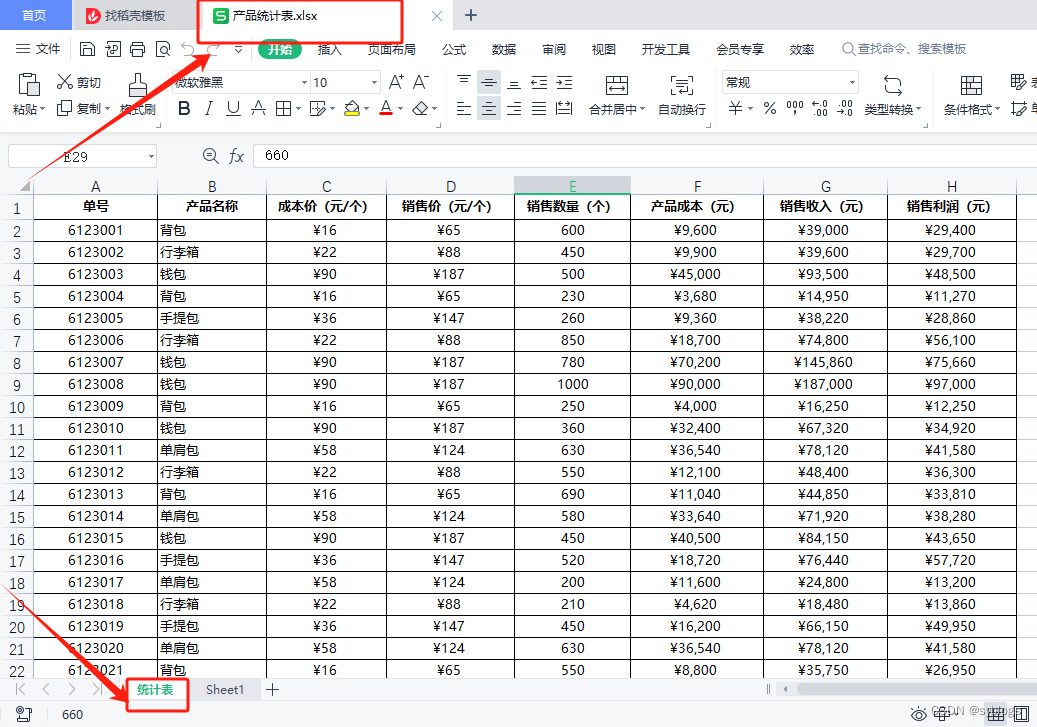
Eg:以工作簿“产品统计表.xlsx”中的工作表"统计表"为例
“Python程序代码”
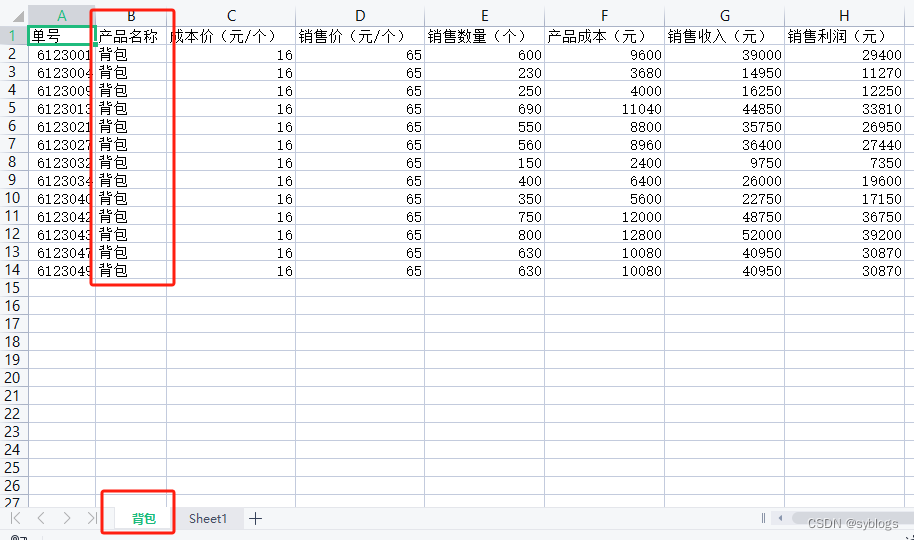
""" 将一个工作表拆分为多个工作簿。 需求:按照产品名称将工作表中的数据分类整理到不同的工作簿中。 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块xlwings来操控Excel文件 import xlwings as xw# 1.O 设置相关的文件和文件夹路径 src_file = Path("D:\\pppp\\第6章\\产品统计表.xlsx") des_folder = Path("D:\\pppp\\第6章\\拆分后的产品统计表\\") if not des_folder.exists():des_folder.mkdir(parents=True)# 2.0 打开工作簿,读取工作表中的数据 app = xw.App(visible=False, add_book=False) workbook = app.books.open(src_file) worksheet = workbook.sheets["统计表"] header = worksheet["A1:H1"].value data1 = worksheet.range("A2").expand("table").value# 3.0 按照产品名称对读取的数据进行分类 # 创建一个空字典data2 data2 = dict() # 设置循环次数,即读取数据的行数 for i in range(len(data1)):# 产品名称位于整个数据的第2列product_name = data1[i][1]if product_name not in data2:data2[product_name] = []data2[product_name].append(data1[i])# 4.0新建工作簿,保存分类后的数据 for k, v in data2.items():new_workbook = app.books.add()new_worksheet = new_workbook.sheets.add(k)new_worksheet["A1"].value = headernew_worksheet["A2"].value = vnew_worksheet.autofit()new_workbook.save(des_folder / f"{k}.xlsx")new_workbook.close()# 5.0 使用quit()函数退出Excel程序 app.quit()“运行结果展示”