论文:https://arxiv.org/abs/2303.00262
代码:https://github.com/VSAnimator/collage-diffusion
文章目录
- Abstract
- Introduction
- Problem Definition and Goals
- 论文其他内容
- 实战
Abstract
基于文本条件的扩散模型能够生成高质量、多样化的图像。然而,文本通常对于所需的目标图像来说是一个模糊的说明,因此需要额外用户友好的控制来进行基于扩散的图像生成。在本文中,我们关注对于具有多个物体的场景,实现对图像输出的精确控制。用户通过定义一个拼贴来控制图像生成:一个文本提示与有序的图层序列相配对,其中每个图层被定义为一个RGBA图像和一个相应的文本提示。我们引入了拼贴扩散,一种拼贴条件的扩散算法,使用户能够同时控制场景中物体的空间排列和视觉属性,并且还能够编辑生成图像的个别组件。为了确保输入文本的不同部分对应于输入拼贴图层中指定的不同位置,拼贴扩散通过使用图层的阿尔法遮罩修改了文本-图像交叉注意力。为了保持文本中未指定的单个拼贴图层的特性,拼贴扩散为每个图层学习了专门的文本表示。
拼贴输入还能够实现基于图层的独特控制,使用户可以对最终输出进行精细的控制:用户可以逐层控制图像的协调,还可以在保持其他物体固定的同时编辑生成图像中的单个物体。拼贴条件的图像生成需要对输入的拼贴进行协调,使物体能够相互配合。关键挑战在于在协调过程中最小化更改输入拼贴中物体的位置和关键视觉属性,同时允许拼贴的其他属性在协调过程中发生变化。通过充分利用图层输入中的丰富信息,拼贴扩散生成的图像在全局上更好地保持所需的物体位置和视觉特征,优于先前的方法。
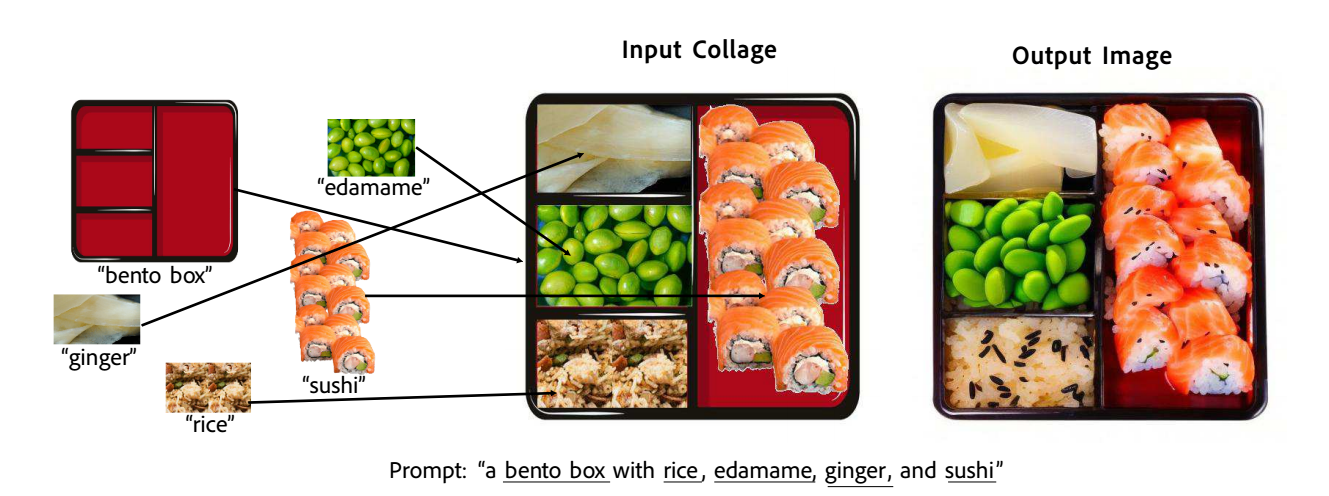
图1:拼贴扩散从包含多个物体的复杂构图中创建全局协调的图像。拼贴被定义为一系列图层,其中每个图层是一个图像-文本对。以拼贴作为输入,拼贴扩散生成一个输出图像,该图像在全局上协调一致,同时保留每个输入图层中物体的位置和关键视觉特征。
Introduction
基于扩散的文本条件图像生成[6, 9, 17, 18, 21, 22]以其看似神奇的能力,从简单的文本提示中生成逼真的图像,引起了广泛的兴趣。然而,文本对于目标图像来说是一个高度模糊的说明,迫使使用流行的文本条件工具的用户花费大量时间来调整提示字符串以获得所需的输出。对于基于扩散的图像生成,提供更精确的控制需求迫切,最近的大量工作提供了新的方式来指定所需的输出:通过草图控制场景构图[3],通过填充用户提供的分割掩模[2, 23],提供用作生成目标的参考图像[14]等。同样,精确规定场景中对象的外观,例如“这个参考照片中的寿司”,而不仅仅是“寿司”,已经导致了基于示例图像进行生成的方法[7, 11, 19]。
在本文中,我们旨在在创建具有特定所需空间排列的物体集合的场景时,为用户提供对图像输出的精确控制。例如,在图1中,“一个装有米饭、毛豆、姜和寿司的便当盒”既没有描述哪些物品放在哪个便当盒中,也没有暗示每个物品的外观。我们的方法很简单:不再依赖于模糊的文本提示,或者强迫用户草绘粗糙的场景形式,而是回归到一种传统且易于创建的表达艺术意图的方式:制作图像拼贴,以同时表达所需的场景布局和场景中物体的外观。
制作拼贴在概念上很简单。用户只需获取所需场景物体的参考图像(例如通过图像搜索或现有生成模型的输出),从这些源图像中分割出物体,使用传统的基于图层的图像编辑界面将它们排列在画布上,并将每个物体与一个文本提示配对。在给定了这个拼贴之后,我们引入了拼贴扩散,一种拼贴条件的扩散算法,生成新颖的、高质量的图像,这些图像既在空间构图和个体物体外观方面忠实于输入拼贴,又在全局协调性和视觉一致性方面展现出代表“合理”现实世界图像的特征。在协调和忠实之间存在固有的权衡:协调涉及更改输入拼贴图层的属性,以便在一致的图像中使物体“配合在一起”,而忠实则涉及保留输入拼贴图层的属性。拼贴扩散中的关键挑战在于在协调输入拼贴的同时限制某些物体属性的变化(空间位置、视觉特征),同时允许其他物体属性的变化(方向、光照、透视、遮挡)。我们通过利用拼贴输入中存在的丰富信息来解决这一挑战,借鉴了以前基于扩散的图像协调、空间控制和外观控制的技术,扩展了每种方法以适应拼贴输入的性能,特别关注逐层控制的机制。
具体而言,我们做出了以下贡献:
• 我们引入了拼贴条件的扩散,其中生成的条件是一组阿尔法合成的RGBA图层,以及描述每个图层内容的文本提示。用户可以在几分钟内创建拼贴,拼贴扩散生成高质量的图像,这些图像既尊重拼贴所描述的场景构图,又尊重拼贴中所包含的对象的外观,即使拼贴由许多图层组成,描述了具有许多对象的复杂场景。
• 我们将先前的基于扩散的控制机制[3, 7]扩展到拼贴条件的扩散背景中,以确保输出图像遵循拼贴所描述的构图(交叉注意力),并保留拼贴每个图层中物体的显著视觉特征(文本反转)。
• 我们说明了拼贴输入如何实现逐层控制机制,使用户可以逐层控制协调-忠实权衡,并使用户能够迭代地优化拼贴扩散生成的图像。
Problem Definition and Goals
我们的目标是生成高质量的、全局协调的图像,以满足用户所需的场景构图,无论是在空间保真度方面(即保留所需物体的位置和大小),还是在外观保真度方面(即保留物体的视觉特征)。在本文中,我们提出用户可以通过拼贴来描述他们的意图。我们首先定义了一个拼贴,然后介绍了基于拼贴的场景构图生成图像的目标。
如图3所示,我们将拼贴C定义如下:1. 完整拼贴文本字符串c,描述要生成的整个图像(例如“一个装有米饭、毛豆、姜和寿司的便当盒”)2. 由n个拼贴“图层”l1、l2、…、ln组成的序列,从后到前排序,每个li具有以下属性:(a) 一个RGBA图像xi(寿司的Alpha掩膜输入图像),带有alpha图层xαi (b) 描述该图层的文本字符串ci,它是c的一个子字符串(例如“寿司”) 给定拼贴C作为输入,我们寻求生成具有以下属性的输出图像x∗c: 1. 全局协调:x∗c是一个全局协调的图像:x∗c具有真实图像的一致性。例如,图1中的输出图像具有场景物体之间一致的透视、光照和遮挡。
空间保真度:x∗c尊重拼贴中指定的场景构图。对于所有图层li,由图层文本ci描述的物体在x∗c的适当区域生成。例如,在图1左侧,“毛豆”、“姜”等都在与输入拼贴中的相同区域的便当盒内生成。
外观保真度:对于所有图层li,除了与图层文本ci匹配之外,x∗c中描绘图层内容的区域与xi共享视觉特征。在图1中,注意输出图像中的“姜”保持切片寿司姜的外观(而不是整个姜),“米饭”呈米饭层相应区域的类似乳白色颜色,而“寿司”有鲑鱼等。
为了实现真实图像的一致性,我们借鉴了以前基于扩散的技术,以限制生成图像的空间布局和单个物体的外观,允许图像的所有其他属性在协调过程中变化。
论文其他内容
略
实战
https://github.com/xddun/collage-diffusion-main
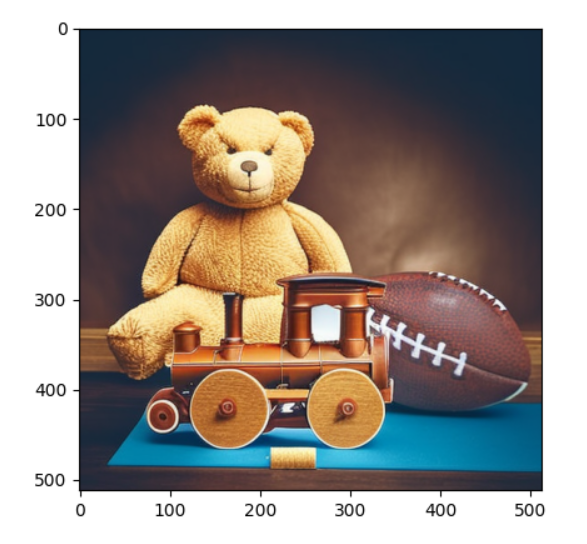
程序本身会检测是否有lora反推的Textual Inversion Embedding文件,没有的话这里ftc就是None。我这里手动全部给了None,但失去这个,这个拼接就不太像话了,效果不太好。