Java线程入门
单核CPU和多核CPU的理解
单核CPU,其实是一种假的多线程,因为在一个时间单元内,也只能执行一个线程的任务。例如:虽然有多车道,但是收费站只有一个工作人员在收费,只有收了费才能通过,那么CPU就好比收费人员。如果有某个人不想交钱,那么收费人员可以把他“挂起”(晾着他,等他想通了,准备好了钱,再去收费)。但是因为CPU时间单元特别短,因此感觉不出来。
如果是多核的话,才能更好的发挥多线程的效率。(现在的服务器都是多核的)
一个Java应用程序java.exe,其实至少有三个线程:main()主线程,gc()垃圾回收线程,异常处理线程。当然如果发生异常,会影响主线程。
为什么需要并行
1.业务需求
有一个HTTP服务器要处理多个客户端的请求。
方式一:为每一个客户端使用一个线程去处理。
方式二:用一个线程处理多个客户端请求,这样我们不得不需要处理客户端之间的调度问题,这样就增加了代码的复杂程度。
当JVM启动的时候,在后台会运行很多线程。运行main方法的主线程,处理GC的GC线程;处理编译的JIT线程。如果在一个串行的程序当中同时去实现这些功能,并且让它们自然的、交替的执行。我们不得不写一个任务切换的框架或者在一个操作中调用不相关的代码。
不用进程,是因为进程太大,一个进程的创建和销毁开销要比线程大得多。
2.性能需要
使用多线程的程序在多核CPU上的性能一般来说会比单线程程序要好些。
把一个任务分割成几部分去同时执行,这会减少总的运行时间。
什么时候不使用并行
除非性能增加很大或者任务分隔足够清晰有足够的开发时间,增加的性能成本大于开发和维护成本,否则不要使用并行。并行程序的复杂性会导致更多的bug。
运行线程,操作系统必须分配内存资源和栈空间然后增加线程调度。如果任务本身运行特别块,反而会降低程序性能。
线程是有限资源,如果太多的线程同时运行,操作系统就要做更多的上下文切换,有时增加一个额外的线程可能降低整体性能 。太多的线程会耗尽进程的内存和地址空间,因为每个线程都需要独立的地址空间。
有关并行的2个重要定律
Amdahl定律(阿姆达尔定律)
加速比=优化前系统耗时/优化后系统耗时
即,所谓加速比,就是优化前的耗时与优化后耗时的比值。加速比越高,表明优化效果越明显。图1.8显示了Amdahl公式的推导过程,其中n表示处理器个数,T表示时间,T1表示优化前耗时(也就是只有1个处理器时的耗时),Tn表示使用n个处理器优化后的耗时。F是程序中只能串行执行的比例。

根据这个公式,如果CPU处理器数量趋于无穷,那么加速比与系统的串行化率成反比,如果系统中必须有50%的代码串行执行,那么系统的最大加速比为2。
注意:根据Amdahl定律,使用多核CPU对系统进行优化,优化的效果取决于CPU的数量以及系统中的串行化程序的比重。CPU数量越多,串行化比重越低,则优化效果越好。仅提高CPU数量而不降低程序的串行化比重,也无法提高系统性能
Gustafson定律(古斯塔夫森)
Gustafson定律也试图说明处理器个数、串行比例和加速比之间的关系,如图1.12所示,但是Gustafson定律和Amdahl定律的角度不同。同样,加速比都定义为优化前的系统耗时除以优化后的系统耗时

可以看到,由于切入角度的不同,Gustafson定律的公式和Amdahl定律的公式截然不同。从Gustafson定律中,我们可以更容易地发现,如果串行化比例很小,并行化比例很大,那么加速比就是处理器的个数。只要你不断地累加处理器,就能获得更快的速度。
并发(Concurrency)和并行(Parallelism)
并发是宏观概念,我分别有任务A和任务B,在一段时间内通过任务间的切换完成了这两个任务,这种情况就可以称之为并发。一个CPU(采用时间片)同时执行多个任务。比如:秒杀、多个人做同一件事。
并行是微观概念,假设CPU中存在两个核心,那么我就可以同时完成任务A、B。同时完成多个任务的情况就可以称之为并行,多个CPU同时执行多个任务。比如:多个人同时做不同的事。
一个并发程序是指能同时执行通常不相关的各种任务。以一个游戏服务器为例子:它通常是有各种组件组成,每种组件都跟外部世界进行着复杂的信息交互。一个组件有可能要处理多个用户聊聊;另外一些可能要处理用户的输入,并把最新状态反馈给用户;其它的用来进行物理计算。这些都是并发处理。并发程序并不需要多核处理器。
相比之下,并行程序是用来解决一个单一任务的。以一个试图预估某支股票价格在下一分钟波动情况的金融组件为例,如果想最快速度的知道标普500中哪知股票应该卖出还是买进,你不能一个一个的计算,而是将这些所有的股票同时计算。这是并行
并发(concurrent)指的是多个程序可以同时运行的现象,更细化的是多进程可以同时运行或者多指令可以同时运行。但这不是重点,在描述并发的时候也不会去扣这种字眼是否精确,并发的重点在于它是一种现象。并发描述的是多进程同时运行的现象。但实际上,对于单核心CPU来说,同一时刻只能运行一个进程。所以,这里的"同时运行"表示的不是真的同一时刻有多个进程运行的现象,这是并行的概念,而是提供一种功能让用户看来多个程序同时运行起来了,但实际上这些程序中的进程不是一直霸占CPU的,而是执行一会停一会。
所以,并发和并行的区别就很明显了。它们虽然都说是"多个进程同时运行",但是它们的"同时"不是一个概念。并行的"同时"是同一时刻可以多个进程在运行(处于running),并发的"同时"是经过上下文快速切换,使得看上去多个进程同时都在运行的现象,是一种OS欺骗用户的现象。
并行和串行:
- 串行:一次只能取得一个任务并执行这一个任务
- 并行:可以同时通过多进程/多线程的方式取得多个任务,并以多进程或多线程的方式同时执行这些任务
- 注意点:
- 如果是单进程/单线程的并行,那么效率比串行更差
- 如果只有单核cpu,多进程并行并没有提高效率
- 从任务队列上看,由于同时从队列中取得多个任务并执行,相当于将一个长任务队列变成了短队列
并发:
- 并发是一种现象:同时运行多个程序或多个任务需要被处理的现象
- 这些任务可能是并行执行的,也可能是串行执行的,和CPU核心数无关,是操作系统进程调度和CPU上下文切换达到的结果
- 解决大并发的一个思路是将大任务分解成多个小任务:
- 可能要使用一些数据结构来避免切分成多个小任务带来的问题
- 可以多进程/多线程并行的方式去执行这些小任务达到高效率
- 或者以单进程/单线程配合多路复用执行这些小任务来达到高效率
同步(synchronous)和异步(asynchronous)
- 同步和异步关注的是消息通信机制。
- 同步,同步执行当调用方法执行完成后并返回结果,才能执行后续代码。
- 异步,和同步相反,调用方不会理解得到结果,而是在调用发出后调用者可用继续执行后续操作,被调用者通过状体来通知调用者,或者通过回掉方法来处理这个调用
临界区
临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。
阻塞(Blocking)和非阻塞(Non-Blocking)
阻塞和非阻塞通常用来形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其它所有需要这个资源的线程就必须在这个临界区中进行等待,等待会导致线程挂起。这种情况就是阻塞。此时,如果占用资源的线程一直不愿意释放资源,那么其它所有阻塞在这个临界区上的线程都不能工作。
非阻塞允许多个线程同时进入临界区
并发级别
- 阻塞,非阻塞(无障碍,无锁,无等待)
- 阻塞当一个线程进入临界区后,其他线程必须等待
- 无障碍(Obstruction-Free)是一种最弱的非阻塞调度,自由出入临界区,无竞争时,有限步内完成操作,有竞争时,回滚数据
- 无锁(Lock-Free),是无障碍的,保证有一个线程可以胜出
- 无等待(Wait-Free)无锁的要求所有的线程都必须在有限步内完成无饥饿的
基本概念:程序、进程、线程
程序(program)是为完成特定任务、用某种语言编写的一组指令的集合。即指一段静态的代码,静态对象。
进程(process)是程序的一次执行过程,或是正在运行的一个程序。是一个动态的过程:有它自身的产生、存在和消亡的过程。——生命周期
- 如:运行中的QQ,运行中的MP3播放器
- 进程作为资源分配的单位,系统在运行时会为每个进程分配不同的内存区域
- 程序是静态的,进程是动态的
线程(thread),进程可进一步细化为线程,是一个程序内部的一条执行路径。若一个进程同一时间并行执行多个线程,就是支持多线程的。线程作为调度和执行的单位,每个线程拥有独立的运行栈和程序计数器(pc),线程切换的开销小。一个进程中的多个线程共享相同的内存单元/内存地址空间à它们从同一堆中分配对象,可以访问相同的变量和对象。这就使得线程间通信更简便、高效。但多个线程操作共享的系统资源可能就会带来安全的隐患。

进程:
正在进行中的程序。其实进程就是一个应用程序运行时的内存分配空间。
进程的缺点:
- CPU每调度一个进程,都要将其上次被执行的情况恢复到CPU和寄存器中去,由于每个进程都有自己的数据段、栈段和代码段,这样的恢复现场工作需要占用大量系统资源。
- 一个进程至少有一个线程在运行,当一个进程中出现多个线程时,就称这个应用程序是多线程应用程序,每个线程在栈区中都有自己的执行空间,自己的方法区、自己的变量。
- jvm在启动的时,首先有一个主线程,负责程序的执行,调用的是main方法。主线程执行的代码都在main方法中。
- 当产生垃圾时,收垃圾的动作,是不需要主线程来完成,因为这样,会出现主线程中的代码执行会停止,会去运行垃圾回收器代码,效率较低,所以由单独一个线程来负责垃圾回收。
线程:
其实就是进程中一个程序执行控制单元,一条执行路径。进程负责的是应用程序的空间的标示。线程负责的是应用程序的执行顺序,存在于进程中,是一个进程的一部分。线程不能单独运行,必须在一个进程之内运行。
线程随机性的原理:
因为cpu的快速切换造成,哪个线程获取到了cpu的执行权,哪个线程就执行。
线程的创建和启动
Java语言的JVM允许程序运行多个线程,它通过java.lang.Thread类来体现。
Thread类的特性
每个线程都是通过某个特定Thread对象的run()方法来完成操作的,经常把run()方法的主体称为线程体
通过该Thread对象的start()方法来启动这个线程,而非直接调用run()
构造器
Thread():创建新的Thread对象
Thread(String threadname):创建线程并指定线程实例名
Thread(Runnabletarget):指定创建线程的目标对象,它实现了Runnable接口中的run方法
Thread(Runnable target, String name):创建新的Thread对象
方法
start方法:
1)、启动了线程;
2)、让jvm调用了run方法。
run方法
线程要运行的代码都统一存放在了run方法中:线程要运行必须要通过类中start方法开启。(启动后,就多了一条执行路径)
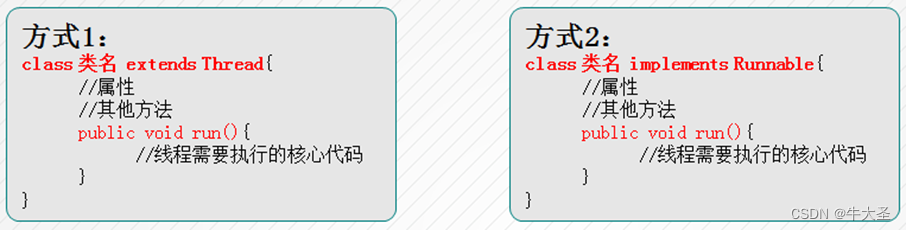
创建线程的两种方式:
JDK1.5之前创建新执行线程有两种方法:
继承Thread类的方式
实现Runnable接口的方式
继承Thread类,extends 于java.lang.Thread,由子类复写run方法。
步骤:
1,定义类继承Thread类;
2,目的是复写run方法,将要让线程运行的代码都存储到run方法中;
3,通过创建Thread类的子类对象,创建线程对象;
4,调用线程的start方法,开启线程,并执行run方法。
public class Thread_01_Thread_Start {public static void main(String [] args) {//Thread():创建新的Thread对象//Thread(String threadname):创建线程并指定线程实例名MyThread myThread1 = new MyThread();//创建线程 Thread():创建新的Thread对象MyThread myThread2 = new MyThread("小王");// 创建线程 Thread(String threadname):创建线程并指定线程实例名// start启动线程,并调用该线程的run方法myThread1.start();//线程名称:Thread-0myThread2.start();//线程名称:小王}
}
//继承Thread类
class MyThread extends Thread {MyThread(String name) {super(name);}MyThread() {super();}//复写run方法@Overridepublic void run() {System.out.println("线程名称:"+Thread.currentThread().getName());//结果为:小王}
}
注意点:
- 如果自己手动调用run()方法,那么就只是普通方法,没有启动多线程模式。
- run()方法由JVM调用,什么时候调用,执行的过程控制都有操作系统的CPU调度决定。
- 想要启动多线程,必须调用start方法。
- 一个线程对象只能调用一次start()方法启动,如果重复调用了,则将抛出以上的异常“IllegalThreadStateException”。
实现Runnable接口
1, 定义类实现Runnable接口。
2,覆盖接口中的run方法,将线程的任务代码封装到run方法中。
3, 通过Thread类创建线程对象,并将Runnable接口的子类对象作为Thread类的构造方法的参数进行传递。
为什么?因为线程的任务都封装在Runnable接口子类对象的run方法中。所以要在线程对象创建时就必须明确要运行的任务。
4,调用线程对象的start方法开启线程。
public class Thread_02_Runnable_Start {public static void main(String [] args) {//Thread(Runnabletarget):指定创建线程的目标对象,它实现了Runnable接口中的run方法//Thread(Runnable target, String name):创建新的Thread对象// 创建线程子类对象MyRunnable myRunnable = new MyRunnable ();// 创建线程thread对象Thread thread1 = new Thread(myRunnable);Thread thread2 = new Thread(myRunnable,"小明");//调用线程对象的start方法开启线程thread1.start();//线程名称:Thread-0thread2.start();//线程名称:小明}
}
//继承Runnable类
class MyRunnable implements Runnable {MyRunnable() {super();}//复写run方法@Overridepublic void run() {System.out.println("线程名称:"+Thread.currentThread().getName());}
}
区别
- 继承Thread:线程代码存放Thread子类run方法中。
- 实现Runnable:线程代码存在接口的子类的run方法。
实现Runnable接口的好处:
将线程的任务从线程的子类中分离出来,进行了单独的封装。按照面向对象的思想将任务的封装成对象。
避免了java单继承的局限性。所以,创建线程的第二种方式较为常用,继承Thread,是可以对Thread类中的方法,进行子类复写的。但是不需要做这个复写动作的话,只为定义线程代码存放位置,实现Runnable接口更方便一些。所以Runnable接口将线程要执行的任务封装成了对象。
多个线程可以共享同一个接口实现类的对象,非常适合多个相同线程来处理同一份资源。
通过继承Thread类的方式,可以完成多线程的建立。但是这种方式有一个局限性,如果一个类已经有了自己的父类,就不可以继承Thread类,因为java单继承的局限性。可是该类中的还有部分代码需要被多个线程同时执行。这时怎么办呢?只有对该类进行额外的功能扩展,java就提供了一个接口Runnable。这个接口中定义了run方法,其实run方法的定义就是为了存储多线程要运行的代码。所以Thread类在描述线程时,内部定义的run方法,也来自于Runnable接口。
Thread类的有关方法
void start(): 启动线程,并执行对象的run()方法run(): 线程在被调度时执行的操作String getName(): 返回线程的名称void setName(String name):设置该线程名称static Thread currentThread(): 返回当前线程。在Thread子类中就是this,通常用于主线程和Runnablestatic void yield():线程让步。暂停当前正在执行的线程,把执行机会让给优先级相同或更高的线程。若队列中没有同优先级的线程,忽略此方法join():当某个程序执行流中调用其他线程的join() 方法时,调用线程将被阻塞,直到加入join 线程的方法执行完为止。低优先级的线程也可以获得执行Static void sleep(long millis):(指定时间:毫秒),令当前活动线程在指定时间段内放弃对CPU控制,使其他线程有机会被执行,时间到后重排队。抛出InterruptedException异常stop(): 强制线程生命期结束,不推荐使用booleanisAlive():返回boolean,判断线程是否还活着
线程的调度
调度策略
时间片

抢占式:高优先级的线程抢占CPU
Java的调度方法
同优先级线程组成先进先出队列(先到先服务),使用时间片策略
对高优先级,使用优先调度的抢占式策略
线程的优先级
线程的优先级等级
MAX_PRIORITY:10
MIN _PRIORITY:1
NORM_PRIORITY:5
涉及的方法
getPriority() :返回线程优先值
setPriority(intnewPriority) :改变线程的优先级
说明
线程创建时继承父线程的优先级
低优先级只是获得调度的概率低,并非一定是在高优先级线程之后才被调用
线程的分类
Java中的线程分为两类:一种是守护线程,一种是用户线程。
它们在几乎每个方面都是相同的,唯一的区别是判断JVM何时离开。
守护线程是用来服务用户线程的,通过在start()方法前调用thread.setDaemon(true)可以把一个用户线程变成一个守护线程。
Java垃圾回收就是一个典型的守护线程。
若JVM中都是守护线程,当前JVM将退出。
形象理解:兔死狗烹,鸟尽弓藏
线程的生命周期:
要想实现多线程,必须在主线程中创建新的线程对象。Java语言使用Thread类及其子类的对象来表示线程,在它的一个完整的生命周期中通常要经历如下的五种状态:
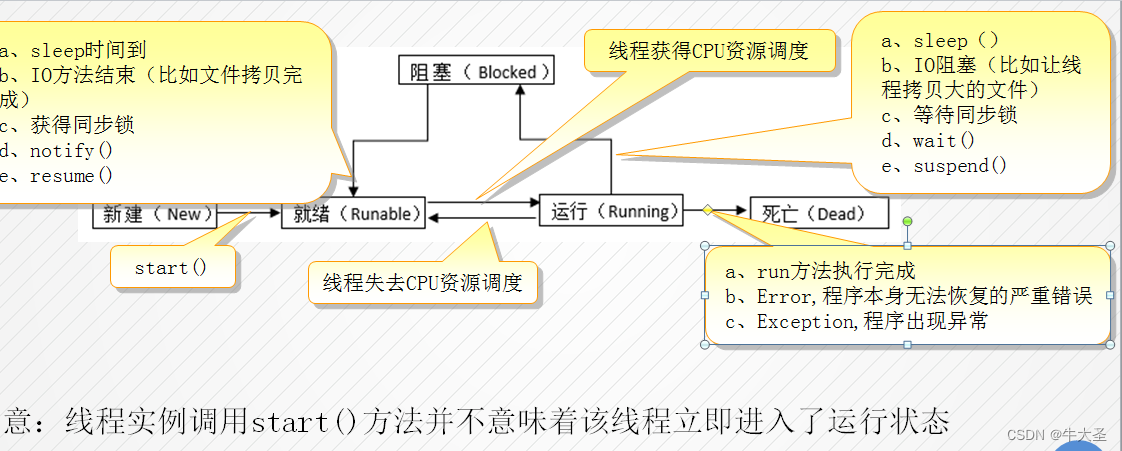
创建:
在程序中用new运算符创建了一个thread类或子类的实例化对象后,新的线程便处于创建状态,此时,他已经有了相应的内存空间,但还未对该线程分配任何资源,所以还处于不可运行的状态。新建一个线程对象可采用线程构造方法来实现,例如:Thread thread = new Thread().
就绪
新建线程对象后,若要执行它,系统就为这个线程分配资源。处于新建状态的线程被start()后,将进入线程队列等待CPU时间片,此时它已具备了运行的条件,只是没分配到CPU,一旦他获得的CPU等资源时,就可以脱离创建他的主线程而独立运行。
运行:
具备执行资格,同时具备执行权;当就绪状态的线程被调用并获得CPU等资源后,便进入了运行状态。此时自动调用该线程对象的run方法。
阻塞
一个人正在执行的线程在某些情况下。如被人为挂起或需要执行耗时的输入/输出操作时,将让出CPU并暂停停止自己的执行,以后还可以恢复运行的状态称为阻塞状态,在可执行状态下,如果发生以下几种情况中的一种,就说明线程进入了阻塞状态。
调用了该线程的sleep()休眠方法
调用了该线程的wait()休眠方法
调用了该线程的 suspend()休眠方法
该线程正在等待I/O流操作完成
阻塞时,线程不能进入排队队列,只有当引起阻塞原因被消除后,线程才可以进入就绪状态。
消亡:
如果一个线程在可执行状态下,运行run()方法后或在调用stop()或destroy()方法或Error,Exception后,就说明线程进入了终止状态,处于这种状态的线程不具有继续运行的能力。
线程的特点:
- 一个进程可以包含多个线程,而一个线程必须有一个进程;
- 线程没有独立的存储空间,而是和所属进程中的其它线程共享存储空间;
- 线程有独立的执行堆栈、程序计数器和局部变量;
- 线程和其所在进程的其它线程同享进程所有的资源;
- 同一进程中的线程采用抢占式独立运行;
- 一个线程可以创建和删除另外一个线程;
- 同一个进程中的多个线程之间可以并发执行;
- 线程的调度管理由进程完成
线程的优点:
易于调度;
开销少。创建线程比创建进程要快,所需开销很少。。
利于充分发挥多处理器的功能。通过创建多线程进程(即一个进程可具有两个或更多个线程),每个线程在一个处理器上运行,从而实现应用程序的并发性,使每个处理器都得到充分运行。
线程安全:
指某个方法、方法库在多线程环境中被调用时,能够正确地处理各个线程的局部变量,使程序功
能正确完成
原子性
是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其它线程干扰。
可见性
是指当一个线程修改了某一个共享变量的值,其他线程是否能够立即知道这个修改。
有序性
指的是在代码顺序结构中,我们可以直观的指定代码的执行顺序, 即从上到下按序执行。但编译器和CPU处理器会根据自己的决策,对代码的执行顺序进行重新排序。优化指令的执行顺序,提升程序的性能和执行速度,使语句执行顺序发生改变,出现重排序,但最终结果看起来没什么变化(单核)。
有序性问题 指的是在多线程环境下(多核),由于执行语句重排序后,重排序的这一部分没有一起执行完,就切换到了其它线程,导致的结果与预期不符的问题。这就是编译器的编译优化给并发编程带来的程序有序性问题。
Happen-Before规则
程序顺序原则:一个线程内保证语义的串行性
volatile规则:
volatile变量的写,先发生于读,这保证了volatile变量的可见性
锁规则:
解锁( unlock)必然发生在随后的加锁( lock)前
传递性:
A先于B, B先于C,那么A必然先于C
线程的start()方法先于它的每一个动作
线程的所有操作先于线程的终结( Thread.join())
线程的中断( interrupt())先于被中断线程的代码
对象的构造方法执行结束先于finalize()方法
多线程:
一个进程中可以多执行路径。一个进程中至少要有一个线程。
CPU个数、核心数、线程数的关系:
CPU个数:是指物理上,即硬件上的核心数;
核心数:是逻辑上的,简单理解为逻辑上模拟出的核心数;算法
线程数:是同一时刻设备能并行执行的程序个数,线程数 = cpu个数 * 核数;
CPU线程数和Java多线程概念:
- 单个CPU线程在同一时刻只能执行单一Java程序,也就是一个线程多线程
- 单个线程同时只能在单个CPU线程中执行并发
- 线程是操做系统最小的调度单位,进程是资源(好比:内存)分配的最小单位app
- Java中的全部线程在JVM进程中,CPU调度的是进程中的线程编辑器
- Java多线程并非因为CPU线程数为多个才称为多线程,当Java线程数大于CPU线程数,操做系统使用时间片机制,采用线程调度算法,频繁的进行线程切换。
IO阻塞时,线程会释放CPU吗?
当线程处于IO操做时,线程是阻塞的,线程由运行状态切换到等待状态。此时CPU会作上下文切换,以便处理其余程序;当IO操做完成后,CPU会收到一个来自硬盘的中断信号,CPU正在执行的线程所以会被打断,回到ready队列。而先前因I/O而waiting的线程随着I/O的完成也再次回到就绪队列,此时CPU可能会选择他执行。
JAVA中并发和并行的概念
- 并行:指两个或多个事件在同一时刻点发生,CPU同时执行;
- 并发:指两个或多个事件在同一时间段内发生,CPU交替执行;spa
- JAVA线程能够同时在多个核上运行吗?(思考)
- 操做系统是基于线程调度的,在同一时刻,JAVA进程中不一样的线程可能会在不一样的核上并行运行。
- 线程是调度的最小单位,而进程是资源(好比:内存)分配的最小单位。
时间片轮起色制
- 时间片轮转法(Round-Robin,RR):
- 根据先进先出原则,排成队列(就绪队列),调度时,将CPU分配给队首进程,让其执行一个时间段(称为:时间片),时间片一般为10-100ms数量级,当执行的时间片用完时,会由计时器发出时钟中断请求,调度程序便据此来中止该进程的执行,并将它排到队列末尾,而后再把CPU从新分配给当前队列的队首进程,同理如此往复。
- 时间片大小取决于:系统对响应时间的要求,就绪队列中进程的数目,系统的处理能力
进程调度
采用此算法的系统,其程序就绪队列每每按进程到达的时间来排序。进程调度程序老是选择就绪队列中的第一个进程,也就是说按照先来先服务原则调度,但一旦进程占用处理机则仅使用一个时间片。在使用一个时间片后,进程尚未完成其运行,它必须释放出处理机给下一个就绪的进程,而被抢占的进程返回到就绪队列的末尾从新排队等待再次运行。
处理器同一个时间只能处理一个任务。处理器在处理多任务的时候,就要看请求的时间顺序,若是时间一致,就要进行预测。挑到一个任务后,须要若干步骤才能作完,这些步骤中有些须要处理器参与,有些不须要(如磁盘控制器的存储过程)。不须要处理器处理的时候,这部分时间就要分配给其余的进程。原来的进程就要处于等待的时间段上。通过周密分配时间,宏观上就象是多个任务一块儿运行同样,但微观上是有前后的,就是时间片轮换。
实现思想
时间片轮转算法的基本思想是,系统将全部的就绪进程按先来先服务算法的原则,排成一个队列,每次调度时,系统把处理机分配给队列首进程,并让其执行一个时间片。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序根据这个请求中止该进程的运行,将它送到就绪队列的末尾,再把处理机分给就绪队列中新的队列首进程,同时让它也执行一个时间片
Java调度机制
全部的Java虚拟机都有一个线程调度器,用来肯定哪一个时刻运行哪一个线程。主要包含两种:抢占式线程调度器和协做式线程调度器。
- 抢占式线程调度: 每一个线程可能会有本身的优先级,可是优先及并不意味着高优先级的线程必定会被调度,而是由CPU随机的选择,所谓抢占式的线程调度,就是说一个线程在执行本身的任务时,虽然任务尚未执行完,可是CPU会迫使它暂停,让其它线程占有CPU的使用权。
- 协做式线程调度: 每一个线程能够有本身的优先级,但优先级并不意味着高优先级的线程必定会被最早调度,而是由cpu时机选择的,所谓协做式的线程调度,就是说一个线程在执行本身的任务时,不容许被中途打断,必定等当前线程将任务执行完毕后才会释放对cpu的占有,其它线程才能够抢占该cpu。
二者对比:
抢占式线程调度不易发生饥饿现象,不易由于一个线程的问题而影响整个进程的执行,可是其频繁阻塞与调度,会形成系统资源的浪费。协做式的线程调度很容易由于一个线程的问题致使整个进程中其它线程饥饿。
总结:
- Java在调度机制上采用的是抢占式的线程调度机制。
- Java线程在运行的过程当中多个线程之间是协做式的。
多线程意义
Java多线程并不是由于cpu线程数为多个才称为多线程,当Java线程数大于cpu线程数,操作系统使用时间片机制,采用线程调度算法,频繁的进行线程切换。在网络上有一个被认为合理的线程数值计算为
- 一般情况:线程数 = cpu个数 * 核数
- 计算密集型:线程数 = 处理器核心数
- IO密集型:线程数 = n*处理器核心数
多线程的存在,不是提高程序的执行速度。其实是为了提高应用程序的使用率。程序的执行其实都是在抢CPU的资源,CPU的执行权。可以提高CPU的使用率。
多个进程是在抢这个资源,而其中的某一个进程如果执行路径比较多,就会有更高的几率抢到CPU的执行权。
我们是不敢保证哪一个线程能够在哪个时刻抢到,所以线程的执行有随机性
问题:
一边玩游戏,一边听音乐是同时进行的吗?
不是。因为单CPU在某一个时间点上只能做一件事情。
而我们在玩游戏,或者听音乐的时候,是CPU在做着程序间的高效切换让我们觉得是同时进行的。
开启多个线程:
开启多个线程是为了同时运行多部分代码。每一个线程都有自己运行的内容。这个内容可以称为线程要执行的任务。
多线程的优点:
- 提高应用程序的响应。对图形化界面更有意义,可增强用户体验。
- 提高计算机系统CPU的利用率
- 改善程序结构。将既长又复杂的进程分为多个线程,独立运行,利于理解和
- 解决了多部分同时运行的问题。
多线程的弊端:
线程太多效率的降低。
其实应用程序的执行都是cpu在做着快速的切换完成的,这个切换是随机的。
什么时候使用多线程
- 当需要多部分代码同时执行的时候,可以使用。
- 程序需要同时执行两个或多个任务。
- 程序需要实现一些需要等待的任务时,如用户输入、文件读写操作、网络操作、搜索等。
- 需要一些后台运行的程序时。
多线程安全问题:
一个线程在执行多条语句时,并运算同一个数据时,在执行过程中,其他线程参与进来,并操作了这个数据。导致到了错误数据的产生。
涉及到两个因素:
- 多个线程在操作共享数据。
- 有多条语句对共享数据进行运算。
原因:这多条语句,在某一个时刻被一个线程执行时,还没有执行完,就被其他线程执行了。
解决安全问题的原理:
对多条操作共享数据的语句,只能让一个线程都执行完,在执行过程中,其他线程不可以参与执行。如何进行多句操作共享数据代码的封装呢?
java中提供的解决方式
同步代码块或者同步方法。
格式:
synchronized(对象) { // 任意对象都可以。这个对象就是锁。
需要被同步的代码;
}
JVM启动时就启动了多个线程:
至少有两个线程可以分析的出来。
1,执行main方法的线程,
该线程的任务代码都定义在main方法中。
2,负责垃圾回收的线程。
System.gc();
生产者和消费者多线程体现(线程间通信问题)
以学生作为资源来实现的
资源类:Student
设置数据类:SetThread(生产者)
获取数据类:GetThread(消费者)
测试类:StudentDemo
代码:
A:最基本的版本,只有一个数据。
//我们在每个线程中都创建了新的资源,而我们要求的时候设置和
//获取线程的资源都应该是同一个,在外界把这个数据创建出来,
//通过构造方法传递给其他类。
public class StudentDemo {public static void main(String[] args) {// 创建资源Student student = new Student();// 设置和获取的类SetThread st = new SetThread(student);GetThread gt = new GetThread(student);// 线程类Thread t1 = new Thread(st);Thread t2 = new Thread(gt);// 启动线程t1.start();t2.start();}
}class Student {String name;int age;
}class SetThread implements Runnable {private Student student;public SetThread(Student student) {this.student = student;}public void run() {student.name = "张三";student.age = 27;}
}class GetThread implements Runnable {private Student student;public GetThread(Student student) {this.student = student;}public void run() {System.out.println(student.name + "----" + student.age);}
}
B:改进版本,给出了不同的数据,并加入了同步机制
/*** 我们在每个线程中都创建了新的资源,而我们要求的时候设置和* 获取线程的资源都应该是同一个,在外界把这个数据创建出来,* 通过构造方法传递给其他类。* 问题(1)多数据情况下,加入了循环判断,给出不同的值,这个时候长生了新的问题* A 同一个数据出现多次:cpu只需要多出一点执行权利就能执行多次* B 姓名年龄不匹配:线程运行的随机性* 线程安全问题:多线程环境,有共享数据,有多条语句操作共享数据* 解决方法 加锁,不同种类的线程都要加锁,而且必须是同一把。*/
public class StudentDemo {public static void main(String[] args) {// 创建资源Student student = new Student();// 设置和获取的类SetThread st = new SetThread(student);GetThread gt = new GetThread(student);// 线程类Thread t1 = new Thread(st);Thread t2 = new Thread(gt);// 启动线程t1.start();t2.start();}
}class Student {String name;int age;
}class SetThread implements Runnable {private Student student;private int x = 1;public SetThread(Student student) {this.student = student;}public void run() {while (true) {synchronized (student) {if (x % 2 == 0) {// 刚到这失去执行权利student.name = "张三";student.age = 27;} else {// 刚到这失去执行权利student.name = "李四";student.age = 30;}x++;}}}
}class GetThread implements Runnable {private Student student;public GetThread(Student student) {this.student = student;}public void run() {System.out.println(student.name + "----" + student.age);}
}
C:等待唤醒机制改进该程序,让数据能够实现依次的出现
wait()
notify()
notifyAll() (多生产多消费)
package com.multithreading;/*** 我们在每个线程中都创建了新的资源,而我们要求的时候设置和* 获取线程的资源都应该是同一个,在外界把这个数据创建出来,* 通过构造方法传递给其他类。* 问题(1)多数据情况下,加入了循环判断,给出不同的值,这个时候长生了新的问题* A 同一个数据出现多次:cpu只需要多出一点执行权利就能执行多次* B 姓名年龄不匹配:线程运行的随机性* 线程安全问题:多线程环境,有共享数据,有多条语句操作共享数据* 解决方法 加锁,不同种类的线程都要加锁,而且必须是同一把。* 问题(2)虽然数据安全了,但是,一次一大片不太好看,怎么一次一个一个输出:* 使用java提供的等待唤醒机制* 为什么这些方法不定义在Thread类中?* 这些方法的调用必须使用锁对象调用,而我们刚才使用的锁对象失任意锁对象。* 所以这些方法必须定义到Object中*/
public class StudentDemo {public static void main(String[] args) {// 创建资源Student student = new Student();// 设置和获取的类SetThread st = new SetThread(student);GetThread gt = new GetThread(student);// 线程类Thread t1 = new Thread(st);Thread t2 = new Thread(gt);// 启动线程t1.start();t2.start();}
}class Student {String name;int age;boolean flag;// 默认无数据,如果为true,说明有数据
}class SetThread implements Runnable {private Student student;private int x = 0;public SetThread(Student student) {this.student = student;}public void run() {while (true) {synchronized (student) {if (student.flag) {try {student.wait();// T1就等待了,立即释放锁,将来醒过来的时候,是从这里醒过来} catch (InterruptedException e) {e.printStackTrace();}}if (x % 2 == 0) {// 刚到这失去执行权利student.name = "张三";student.age = 27;} else {// 刚到这失去执行权利student.name = "李四";student.age = 30;}x++;// 修改标记student.flag = true;// 唤醒线程student.notify();// 唤醒T2}}}
}class GetThread implements Runnable {private Student student;public GetThread(Student student) {this.student = student;}public void run() {while (true) {synchronized (student) {if (!student.flag) {try {student.wait();// T2就等待了,立即释放锁,将来醒过来的时候,是从这里醒过来} catch (InterruptedException e) {e.printStackTrace();}}System.out.println(student.name + "----" + student.age);// 修改标记student.flag = false;// 唤醒线程student.notify();// 唤醒T1}}}
}
D:等待唤醒机制的代码优化。把数据及操作都写在了资源类中/*** 我们在每个线程中都创建了新的资源,而我们要求的时候设置和* 获取线程的资源都应该是同一个,在外界把这个数据创建出来,* 通过构造方法传递给其他类。* 问题(1)多数据情况下,加入了循环判断,给出不同的值,这个时候长生了新的问题* A 同一个数据出现多次:cpu只需要多出一点执行权利就能执行多次* B 姓名年龄不匹配:线程运行的随机性* 线程安全问题:多线程环境,有共享数据,有多条语句操作共享数据* 解决方法 加锁,不同种类的线程都要加锁,而且必须是同一把。* 问题(2)虽然数据安全了,但是,一次一大片不太好看,怎么一次一个一个输出:* 使用java提供的等待唤醒机制* 为什么这些方法不定义在Thread类中?* 这些方法的调用必须使用锁对象调用,而我们刚才使用的锁对象失任意锁对象。* 所以这些方法必须定义到Object中* 最终:* 把student的成员变量给私有化。* 把设置和获取的操作给封装成功能,并加了同步。* 设置或者获取的线程里面只需要调用方法即可。*/
public class StudentDemo {public static void main(String[] args) {// 创建资源Student student = new Student();// 设置和获取的类SetThread st = new SetThread(student);GetThread gt = new GetThread(student);// 线程类Thread t1 = new Thread(st);Thread t2 = new Thread(gt);// 启动线程t1.start();t2.start();}
}class Student {private String name;private int age;private boolean flag;// 默认无数据,如果为true,说明有数据public synchronized void set(String name, int age) {// 如果有数据,就等待if (this.flag) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}// 设置数据this.name = name;this.age = age;// 修改标记this.flag = true;this.notify();}public synchronized void get() {// 如果没有数据,就等待if (!this.flag) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}// 获取数据System.out.println(this.name + "---" + this.age);// 修改数据this.flag = false;this.notify();}
}class SetThread implements Runnable {private Student student;private int x = 0;public SetThread(Student student) {this.student = student;}public void run() {while (true) {if (x % 2 == 0) {// 刚到这失去执行权利student.set("张三", 27);} else {// 刚到这失去执行权利student.set("李四", 30);}x++;}}
}class GetThread implements Runnable {private Student student;public GetThread(Student student) {this.student = student;}public void run() {while (true) {student.get();}}
}
线程同步:
Why线程同步
多个线程执行的不确定性引起执行结果的不稳定
定义同步前提:
1,必须要有两个或者两个以上的线程,才需要同步。
2,多个线程必须保证使用的是同一个锁。
-
同步好处:解决了线程安全问题。
-
同步弊端:相对降低性能,因为判断锁需要消耗资源,产生了死锁。
同步机制解决Java多线程的安全问题
多线程同步依靠的是对象锁机制,synchronized关键字就是利用锁来实现对共享资源的互斥访问。
Java对于多线程的安全问题提供了专业的解决方式:同步机制
同步的范围
1、如何找问题,即代码是否存在线程安全?(非常重要)
(1)明确哪些代码是多线程运行的代码
(2)明确多个线程是否有共享数据
(3)明确多线程运行代码中是否有多条语句操作共享数据
2、如何解决呢?(非常重要)
对多条操作共享数据的语句,只能让一个线程都执行完,在执行过程中,其他线程不可以参与执行。即所有操作共享数据的这些语句都要放在同步范围中
3、切记:
范围太小:没锁住所有有安全问题的代码
范围太大:没发挥多线程的功能。
同步机制中的锁
同步锁机制:
在《ThinkinginJava》中,是这么说的:对于并发工作,你需要某种方式来防止两个任务访问相同的资源(其实就是共享资源竞争)。防止这种冲突的方法就是当资源被一个任务使用时,在其上加锁。第一个访问某项资源的任务必须锁定这项资源,使其他任务在其被解锁之前,就无法访问它了,而在其被解锁之时,另一个任务就可以锁定并使用它了。
synchronized的锁是什么?
- 任意对象都可以作为同步锁。所有对象都自动含有单一的锁(监视器)。,同步方法的锁:静态方法(类名.class)、非静态方法(this),同步代码块:自己指定,很多时候也是指定为this或类名.class
- 一个对象里面如果有多个synchronized方法,某一个时刻内,只要一个线程去调用其中的一个synchronized方法了,其它的线程都只能等待,换句话说,某一个时刻内,只能有唯一一个线程去访问这些synchronized方法
- 锁的是当前对象this,被锁定后,其它的线程都不能进入到当前对象的其它的synchronized方法
- 加个普通方法后发现和同步锁无关
- 换成两个对象后,不是同一把锁了,情况立刻变化。
- 都换成静态同步方法后,情况又变化
- 所有的非静态同步方法用的都是同一把锁——实例对象本身,也就是说如果一个实例对象的非静态同步方法获取锁后,该实例对象的其他非静态同步方法必须等待获取锁的方法释放锁后才能获取锁,可是别的实例对象的非静态同步方法因为跟该实例对象的非静态同步方法用的是不同的锁,所以毋须等待该实例对象已获取锁的非静态同步方法释放锁就可以获取他们自己的锁。
- 所有的静态同步方法用的也是同一把锁——类对象本身,这两把锁是两个不同的对象,所以静态同步方法与非静态同步方法之间是不会有竞态条件的。但是一旦一个静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取锁,而不管是同一个实例对象的静态同步方法之间,还是不同的实例对象的静态同步方法之间,只要它们同一个类的实例对象!
注意:
- 必须确保使用同一个资源的多个线程共用一把锁,这个非常重要,否则就无法保证共享资源的安全
- 一个线程类中的所有静态方法共用同一把锁(类名.class),所有非静态方法共用同一把锁(this),同步代码块(指定需谨慎)
理解同步和锁:
Java用监视器的手段来完成线程的同步。监视器给受保护的资源外面加了一把锁,而这把锁只有一把钥匙,每一个线程只有在得到这把钥匙之后才可以对被保护的资源执行操作,这线程执行操作完成之后,再将这把钥匙交给下一个即将对所要保护资源进行操作的线程,而其他的线程只能等待,直到拿到这把钥匙。
public class Synchronized_0 {private int shareData = 0; final Object lock = new Object();// 定义了一个充当锁的Object对象public static void main(String[] args) {Synchronized_0 test = new Synchronized_0();Thread1 st1 = test.new Thread1();Thread2 st2 = test.new Thread2();st1.start();st2.start();}class Thread1 extends Thread {@Overridepublic void run() {// 对lock对象上锁synchronized (lock) {while (shareData < 10) {try {Thread.sleep(2000);System.err.println("Thread1:" + shareData);shareData++;} catch (InterruptedException e) {e.printStackTrace();}}System.err.println("Thread1");}
}
}class Thread2 extends Thread {@Overridepublic void run() {// 对lock对象上锁synchronized (lock) {while (shareData < 100) { System.out.println("Thread2:while-->shareData-->" + shareData);shareData++;}System.out.println("Thread2:" + shareData);}}}
}
2:两个人争着用一个锁着的方法
public class Synchronized_1{public static void main(String args[]){Synchronized_1 a=new Synchronized_1();Apple c=a.new Apple();synchronized_1A z1=a.new synchronized_1A("小李",c);synchronized_1A z2=a.new synchronized_1A("小王",c);new Thread(z1).start();new Thread(z2).start();}class synchronized_1A implements Runnable{String name;Apple apple;public synchronized_1A(String name ,Apple apple){this.name=name;this.apple=apple;}public void run() {apple.aa(this.name);}}public class Apple{public synchronized void aa(String name) {for(int i=0;i<5;i++){System.out.println(name+"坐在那里吃饭");}}}
}
// 小李坐在那里吃饭
// 小李坐在那里吃饭
// 小李坐在那里吃饭
// 小李坐在那里吃饭
// 小李坐在那里吃饭
// 小王坐在那里吃饭
// 小王坐在那里吃饭
// 小王坐在那里吃饭
// 小王坐在那里吃饭
// 小王坐在那里吃饭两种使用synchronized同步关键字的方式
Java中用关键字synchronized来完成监视器这一角色。
任何时刻那些被多个线程共享的资源的操作应放在同步方法或同步块中完成。
Synchronized: 任何时刻那些被多个线程共享的资源的操作应放在同步方法或同步块中完成。多线程同步依靠的是对象锁机制,
Synchronized关键字就是利用锁来实现对共享资源的互斥访问。
要想实现线程的同步,这些线程必须去竞争一个唯一的共享的对象锁.
同步代码块:
synchronized (对象){
// 需要被同步的代码;
}
非静态方法上锁,需要创建对象进行调用
要想实现线程的同步,这些线程必须去竞争一个唯一的共享的对象锁.
1 定义了一个充当锁的Object对象来解决数据共享的问题;
public class GongXiangDuiXiang_02 {public static void main(String[] args) {Object lock=new Object();//创建一个线程之间竞争使用的对象for(int k=1;k<=3;k++){new Thread111(lock,k).start();}}
}
class Thread111 extends Thread {private Object lock;//同步锁private int id;//线程IDpublic Thread111(Object lock,int id){//构造方法引入竞争对象.this.lock=lock;this.id=id;}public void run() {synchronized (lock) {for(int i=1;i<=3;i++){System.out.println("线程ID"+id+":"+i);}}}
}
2 通过利用类的变量被所有类的实例所共享.在线程类的内部定义一个静态共享资源.
//通过利用类的变量被所有类的实例所共享.在线程类的内部定义一个静态共享资源.
public class GongXiangDuiXiang_01 {public static void main(String[] args) {for(int i=1;i<=3;i++){new Thread11(i).start();}}
}
class Thread11 extends Thread {private int id;//线程IDprivate static Object lock=new Object();//创建一个线程之间竞争使用的对象public Thread11(int id){//构造方法引入竞争对象.this.id=id;
}public void run() {synchronized (lock) {for(int i=1;i<=3;i++){System.out.println("线程ID "+id+" 输出 "+i);}}}
}
线程ID 2 输出 1
线程ID 2 输出 2
线程ID 2 输出 3
线程ID 3 输出 1
线程ID 3 输出 2
线程ID 3 输出 3
线程ID 1 输出 1
线程ID 1 输出 2
线程ID 1 输出 3
3 定义了一个充当锁的Object对象来解决数据共享的问题;
// TODO 定义了一个充当锁的Object对象来解决数据共享的问题;
public class GongXiangDuiXiang {private int shareData = 0; final Object lock = new Object();// 定义了一个充当锁的Object对象public static void main(String[] args) {GongXiangDuiXiang test = new GongXiangDuiXiang();Thread1 st1 = test.new Thread1();Thread2 st2 = test.new Thread2();st1.start();st2.start();}class Thread1 extends Thread {@Overridepublic void run() {// 对lock对象上锁System.err.println("Thread1:");synchronized (lock) {while (shareData < 10) {System.err.println("Thread1:" + shareData);shareData++;}}}}class Thread2 extends Thread {@Overridepublic void run() {// 对lock对象上锁System.out.println("Thread2:" );synchronized (lock) {while (shareData < 30) {System.out.println("Thread2:" + shareData);shareData++;}}}}
}
同步方法
synchronized还可以放在方法声明中,表示整个方法为同步方法。例如:
public synchronized void show (String name){ ….
}
同步方法是用的哪个锁呢?
通过验证,方法都有自己所属的对象this,所以同步方法所使用的锁就是this锁。
当同步方法被static修饰时,这时的同步用的是哪个锁呢?
用的是类名.class
静态方法在加载时所属于类,这时有可能还没有该类产生的对象,但是该类的字节码文件加载进内存就已经被封装成了对象,这个对象就是该类的字节码文件对象。
所以静态加载时,只有一个对象存在,那么静态同步方法就使用的这个对象。这个对象就是 类名.class
静态方法用类名直接调用,非静态创建对象调用
无锁 结果是无序的
public class GongXiangFangFa {public static void main(String[] args) {new Thread1().start();new Thread2().start();}
}
class Counter{public void excute(String threadName){for (int i = 0; i < 5; i++) {System.out.println(threadName+":"+i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
class Thread1 extends Thread{String threadName = "线程1";@Overridepublic void run() {new Counter().excute(threadName);}
}
class Thread2 extends Thread{String threadName = "线程2";@Overridepublic void run() {new Counter().excute(threadName);}
}
有锁 结果是有序的
public class GongXiangFangFa_01 {public static void main(String[] args) {Counter_1 counter1 = new Counter_1();new Thread_1(counter1).start();//每次传过去一个锁的对象new Thread_2(counter1).start();}
}
class Counter_1{public synchronized void excute(String threadName){//每一个类实例都对应一把锁,获得调用该方法的的类实例才能运行,//方法一旦执行就独占此锁,直到方法返回回来。此方法是所有类实例对象所共享的.for (int i = 0; i < 20; i++) {System.out.println(threadName+":"+i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
class Thread_1 extends Thread{String threadName = "线程1";Counter_1 counter;Thread_1(Counter_1 counter){this.counter=counter;}@Overridepublic void run() {counter.excute(threadName);}
}
class Thread_2 extends Thread{String threadName = "线程2";Counter_1 counter;Thread_2(Counter_1 counter){this.counter = counter;}@Overridepublic void run() {counter.excute(threadName);}
}
2:
非静态同步操作方法体
public class GongXiangFangFa_02 {public static void main(String[] args) {Bike bike = new Bike();new PersonThread("小林",bike).start();new PersonThread("小王",bike).start();}
}class Bike{public synchronized void move(String name){非静态方法System.out.println(name+"试图骑自行车");for (int i = 1; i <= 20; i++) {System.out.println(name+":已经运行"+i+"秒");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
class PersonThread extends Thread{String name;Bike bike;PersonThread(String name, Bike bike){this.name = name;this.bike=bike;}@Overridepublic void run() {bike.move(name);}
}
静态同步操作方法体public class GongXiangFangFa_02 {public static void main(String[] args) {PersonThread03 person1 =new PersonThread03("小林");person1.start();PersonThread03 person2 =new PersonThread03("小王");person2.start();}}class Bike03{public static synchronized void move(String name){//静态方法for (int i = 1; i <= 3; i++) {System.out.println(name+":已经运行"+i+"毫秒");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}}class PersonThread03 extends Thread{String name;PersonThread03(String name){this.name = name;}@Overridepublic void run() {Bike03.move(name);//类名直接调用}}
同步代码块和同步方法的区别?
在一个类中只有一个同步,可以使用同步方法。如果有多同步,必须使用同步代码块,来确定不同的锁。所以同步代码块相对灵活一些。
synchronized 用在方法签名上
同步方法使用的锁是this,静态同步方法的锁是该类的字节码文件对象。
当某个线程调用此方法时,会获取该实例的对象锁,方法未结束之前,其他线程只能去等待。当这个方法执行完时,才会释放对象锁。其他线程才有机会去抢占这把锁,去执行方法test,但是发生这一切的基础应当是所有线程使用的同一个对象实例,才能实现互斥的现象。否则synchronized关键字将失去意义。(但是如果该方法为类方法,即其修饰符为static,那么synchronized 意味着某个调用此方法的线程当前会拥有该类的锁,只要该线程持续在当前方法内运行,其他线程依然无法获得方法的使用权!)
synchronized 用在代码块:
synchronized(obj){//todo code here}
同步代码块使用的锁可以是任意对象。
当线程运行到该代码块内,就会拥有obj对象的对象锁,如果多个线程共享同一个Object对象,那么此时就会形成互斥!特别的,当obj == this时,表示当前调用该方法的实例对象。即
| public void test() { synchronized(this) { // todo your code } } | 此时,其效果等同于 public synchronized void test() { // todo your code } |
使用synchronized代码块,可以只对需要同步的代码进行同步,这样可以大大的提高效率。
代码块相比方法有两点优势:
1、可以只对需要同步的使用
2、与wait()/notify()/nitifyAll()一起使用时,比较方便 便
释放锁的操作
- 当前线程的同步方法、同步代码块执行结束。
- 当前线程在同步代码块、同步方法中遇到break、return终止了该代码块、该方法的继续执行。
- 当前线程在同步代码块、同步方法中出现了未处理的Error或Exception,导致异常结束。
- 当前线程在同步代码块、同步方法中执行了线程对象的wait()方法,当前线程暂停,并释放锁。
不会释放锁的操作
- 线程执行同步代码块或同步方法时,程序调用Thread.sleep()、Thread.yield()方法暂停当前线程的执行
- 线程执行同步代码块时,其他线程调用了该线程的suspend()方法将该线程挂起,该线程不会释放锁(同步监视器)。
- 应尽量避免使用suspend()和resume()
死锁
如果有两个或两个以上的线程都访问了多个资源,而这些线程占用了一些资源的同时又在等待其它线程占用的资源,也就是说多个线程之间都持有了对方所需的资源,而又相互等待对方释放的资源。在这种情况下就会出现死锁。
同步的弊端效率低容易死锁,死锁:两个或两个以上的线程在争夺资源的过程中,发生的一种相互等待的现象
要解决死锁就要对线程共享的资源做同步控制。
不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁出现死锁后,不会出现异常,不会出现提示,只是所有的线程都处于阻塞状态,无法继续
解决方法
专门的算法、原则
尽量减少同步资源的定义
尽量避免嵌套同步
同步的嵌套
/*
同步的嵌套是死锁常见情景之一。
*/
class Ticket implements Runnable {private int num = 100;Object obj = new Object();boolean flag = true;public void run() {if (flag) {while (true) {synchronized (obj) {show();}}} else {while (true) {this.show();}}}public synchronized void show() {synchronized (obj) {if (num > 0) {try {Thread.sleep(10);} catch (InterruptedException e) {}System.out.println(Thread.currentThread().getName() + ".....sale...." + num--);}}}
}public class DeadLockDemo_01 {public static void main(String[] args) {Ticket t = new Ticket();// System.out.println("t:"+t);Thread t1 = new Thread(t,"线程A");Thread t2 = new Thread(t,"线程B");t1.start();try {Thread.sleep(10);} catch (InterruptedException e) {}t.flag = false;t2.start();}
}
synchronized同步嵌套死锁:
class Test implements Runnable {private boolean flag;Test(boolean flag) {this.flag = flag;}public void run() {if (flag) {while (true)synchronized (MyLock.locka) {System.out.println(Thread.currentThread().getName() + "..if lock a....");synchronized (MyLock.lockb) {System.out.println(Thread.currentThread().getName() + "..if lock b....");}}} else {while (true)synchronized (MyLock.lockb) {System.out.println(Thread.currentThread().getName() + "..else lock b....");synchronized (MyLock.locka) {System.out.println(Thread.currentThread().getName() + "..else lock a....");}}}}
}class MyLock {public static final Object locka = new Object();public static final Object lockb = new Object();
}public class DeadLockDemo_02 {public static void main(String[] args) {Test a = new Test(true);Test b = new Test(false);Thread t1 = new Thread(a);Thread t2 = new Thread(b);t1.start();t2.start();}
}
线程间通信:
思路:多个线程在操作同一个资源,但是操作的动作却不一样。
- 将资源封装成对象。
- 将线程执行的任务(任务其实就是run方法。)也封装成对象。
同步控制的方法
在同步控制中正确的使用synchronized sleep()、wait()方法和notify()、 notifyAll()方法。
线程调用了sleep()方法,当前线程进入睡眠,但不会释放所占用资源对象的锁。在sleep 时间间隔期满后,线程不一定立即恢复执行(其它线程可能没执行完)。
wait 和 sleep 区别?
1, wait可以指定时间也可以不指定。
sleep必须指定时间。
2,在同步中时,对cpu的执行权和锁的处理不同。
wait:释放执行权,释放锁。
sleep:释放执行权,不释放锁。
sleep()
sleep()是线程的静态方法,线程调用了sleep()方法,当前线程进入睡眠,但不会释放所占用资源对象的锁。在sleep 时间间隔期满后,线程不一定立即恢复执行(其它线程可能没执行完)。
public class WaitNotify {// 创建两个线程之间竞争使用的对象private static Object lock1 = new Object();private static Object lock2 = new Object();ShareThread1 s =new ShareThread1();public static void main(String[] args) {new ShareThread1().start();new ShareThread2().start();}private static class ShareThread1 extends Thread {public void run() {synchronized (lock1) {try {System.out.println("1111111111");Thread.sleep(50);lock1.wait();} catch (InterruptedException e) {e.printStackTrace();}synchronized (lock2) {System.out.println("ShareThread1");}}}}private static class ShareThread2 extends Thread {public void run() {synchronized (lock2) {try {System.out.println("222222222222");Thread.sleep(50);} catch (InterruptedException e) {e.printStackTrace();}synchronized (lock1) {System.out.println("ShareThread2");lock1.notify();}}}}
}
等待唤醒机制:
wait():
wait():调用该方法的线程对象将处于线程等待状态,等待在其它线程中该线程对象调用notify()或notifyAll()方法将自己唤醒。释放所占用资源对象的锁。
线程调用了sleep()方法,当前线程进入睡眠,但不会释放所占用资源对象的锁。在sleep 时间间隔期满后,线程不一定立即恢复执行(其它线程可能没执行完)。
线程调用了它所占用资源对象的wait()时,使当前线程进入等待队列,同时释放所占用资源对象的锁。直到其他线程调用此资源对象上的 notify() 方法或notifyAll() 方法时所有等待资源对象的线程被唤醒。
notify():
唤醒在此对象锁上等待的单个线程。
notifyAll():
唤醒在此对象锁上等待的所有线程。调用notifyAll()方法并不会立即激活某个等待线程。它只能撤销等待线程的中断状态,这样它们就能够在当前线程退出synchronized方法后,与其它线程展开竞争,以争取获得资源对象来执行。
涉及的方法:
wait:将同步中的线程处于冻结状态。释放了执行权,释放了资格。同时将线程对象存储到线程池中。
notify:唤醒线程池中某一个等待线程。
notifyAll:唤醒的是线程池中的所有线程。
注意:
- 这些方法都需要定义在同步中。
- 因为这些方法必须要标示所属的锁。你要知道 A锁上的线程被wait了,那这个线程就相当于处于A锁的线程池中,只能A锁的notify唤醒。
- 这三个方法都定义在Object类中。为什么操作线程的方法定义在Object类中?
因为这三个方法都需要定义同步内,并标示所属的同步锁,既然被锁调用,而锁又可以是任意对象,那么能被任意对象调用的方法一定定义在Object类中。
wait和sleep区别:
分析这两个方法:从执行权和锁上来分析:
wait:可以指定时间也可以不指定时间。不指定时间,只能由对应的notify或者notifyAll来唤醒。
sleep:必须指定时间,时间到自动从冻结状态转成运行状态(临时阻塞状态)。
wait:线程会释放执行权,而且线程会释放锁。
Sleep:线程会释放执行权,但不是不释放锁。
public class WaitNotify_0 {String data="000";PrintThread pt = new PrintThread();public static void main(String[] args) {new WaitNotify_0().pt.start();}private class CounterThread extends Thread{@Overridepublic void run() {System.out.println("...");synchronized (pt) {data="999";System.out.println("11111111111");pt.notify();}}}private class PrintThread extends Thread{@Overridepublic void run() {synchronized (this) {CounterThread ct = new CounterThread();ct.start();try {this.wait();//等待的时候把钥匙放手了把锁打开了} catch (InterruptedException e) {e.printStackTrace();}System.out.println(data);}}}
}
守护线程
主要用于为其他线程的运行提供服务。在调用线程start()前调用setDaemon方法可以将一个线程设置为守护线程,守护线程属于创建它的线程,当创建它的线程结束时该线程也跟着结束。
★考点问题:请写一个延迟加载的单例模式?写懒汉式;当出现多线程访问时怎么解决?加同步,解决安全问题;效率高吗?不高;怎样解决?通过双重判断的形式解决。
//懒汉式:延迟加载方式。
当多线程访问懒汉式时,因为懒汉式的方法内对共性数据进行多条语句的操作。所以容易出现线程安全问题。为了解决,加入同步机制,解决安全问题。但是却带来了效率降低。
为了效率问题,通过双重判断的形式解决。
class Single{private static Single s = null;private Single(){}public static Single getInstance(){ //锁是谁?字节码文件对象;if(s == null){synchronized(Single.class){if(s == null)s = new Single();}}return s;}
}
线程的停止
Thread.stop():
通过stop方法就可以停止线程。但是这个方式过时了。
停止线程:原理就是:让线程运行的代码结束,也就是结束run方法。
怎么结束run方法?一般run方法里肯定定义循环。所以只要结束循环即可。
第一种方式:定义循环的结束标记。
第二种方式:如果线程处于了冻结状态,是不可能读到标记的,这时就需要通过Thread类中的interrupt方法,将其冻结状态强制清除。让线程恢复具备执行资格的状态,让线程可以读到标记,并结束。
终止线程的典型方法
public class TestThreadCiycle implements Runnable {String name;boolean live = true;public TestThreadCiycle(String name) {super();this.name = name;}public void run() {int i = 0;while (live) {System.out.println(name + (i++));}}public void terminate() {live = false;}public static void main(String[] args) {TestThreadCiycle ttc = new TestThreadCiycle("线程A: ");Thread t1 = new Thread(ttc);// 新生状态t1.start();// 就绪状态for (int i = 0; i < 1000; i++) {System.out.println(i);}ttc.terminate();System.out.println("ttc stop!");}
}
挂起(suspend)和继续执行(resume)线程
– suspend()不会释放锁
– 如果加锁发生在resume()之前 ,则死锁发生
---------< java.lang.Thread >----------
interrupt():中断线程。
void interrupt():中断线程的阻塞状态(而非中断线程)。
public void Thread.interrupt() // 中断线程
public boolean Thread.isInterrupted() // 判断是否被中断
public static boolean Thread.interrupted() // 判断是否被中断,并清除当前中断状态
import java.text.SimpleDateFormat;
import java.util.Date;public class Interrupt {public static void main(String[] args) throws InterruptedException {Interrupt1 a= new Interrupt1();a.start();Thread.sleep(1000);a.interrupt();//void interrupt():中断线程的阻塞状态(而非中断线程)。把中断的状态给清除;}
}
class Interrupt1 extends Thread{public void run(){while(true){Date date = new Date();String pattern = "yyyy-MM-dd HH:mm:ss";SimpleDateFormat sdf = new SimpleDateFormat(pattern);String currentTime = sdf.format(date);System.out.println("当前时间:"+currentTime);try {Thread.sleep(5000);// void interrupt():中断线程的阻塞状态} catch (InterruptedException e) {e.printStackTrace();} }}
}
中断while循环的两种方式:
第一种中断while循环
阻塞状态和while在try,这样中断阻塞时候直接把while循环也中断当前时间:2020-09-26 19:34:23import java.text.SimpleDateFormat;
import java.util.Date;public class Interrupt {public static void main(String[] args) throws InterruptedException {Interrupt1 a= new Interrupt1();a.start();Thread.sleep(1000);a.interrupt();//void interrupt():中断线程的阻塞状态(而非中断线程)。把中断的状态给清除;}
}
class Interrupt1 extends Thread{public void run(){try {
while(true){Date date = new Date();String pattern = "yyyy-MM-dd HH:mm:ss";SimpleDateFormat sdf = new SimpleDateFormat(pattern);String currentTime = sdf.format(date);System.out.println("当前时间:"+currentTime);Thread.sleep(5000);// void interrupt():中断线程的阻塞状态}} catch (InterruptedException e) {e.printStackTrace();
java.lang.InterruptedException: sleep interruptedat java.lang.Thread.sleep(Native Method)at com.method.www.Interrupt1.run(Interrupt.java:25)} }
}
第二种中断while循环
public class Interrupt_02 {public static void main(String[] args) throws InterruptedException {Cou a= new Cou();a.start();Thread.sleep(9000); //void sleep(long millis):静态方法,线程1毫秒之后进入阻塞状态,//在指定时间(单位为毫秒)到达之后进入就绪状态。 a.stopa();}
}
class Cou extends Thread{//中断while循环boolean flag=true;public Cou(){super("计数器线程");}public void stopa(){flag=false;}public void run(){try {int i=1;while(flag){System.out.println(this.getName()+":"+i);i++;sleep(3000);}} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread());}
}
线程的基本操作-线程中断
public static void sleep(long millis) throws InterruptedException
public void run(){while(true){if(Thread.currentThread().isInterrupted()){System.out.println("Interruted!");break;}try {Thread.sleep(2000);} catch (InterruptedException e) {System.out.println("Interruted When Sleep");//设置中断状态,抛出异常后会清除中断标记位Thread.currentThread().interrupt();}Thread.yield();}
}
setPriority(int newPriority):更改线程的优先级。
getPriority():返回线程的优先级。
toString():返回该线程的字符串表示形式,包括线程名称、优先级和线程组。
Thread.yield():暂停当前正在执行的线程对象,并执行其他线程。
setDaemon(true):将该线程标记为守护线程或用户线程。将该线程标记为守护线程或用户线程。当正在运行的线程都是守护线程时,Java 虚拟机退出。该方法必须在启动线程前调用。
join
临时加入一个线程的时候可以使用join方法。
当A线程执行到了B线程的join方式。A线程处于冻结状态,释放了执行权,B开始执行。A什么时候执行呢?只有当B线程运行结束后,A才从冻结状态恢复运行状态执行。
public class Join {String data="000";static Join s=new Join();//创建一个对象进行调用,不能用两个,两个static PrintThread pt = s.new PrintThread();static CounterThread ct = s.new CounterThread();public static void main(String[] args) {ct.start();pt.start();}private class PrintThread extends Thread{@Overridepublic void run() {System.out.println("000000000");try {System.out.println(data);ct.join();//当前线程PrintThread等待加入(join)的CounterThread线程完成,才能继续往下执行。 System.out.println("222222222222");System.out.println(data);} catch (InterruptedException e) {e.printStackTrace();}}}private class CounterThread extends Thread{@Overridepublic void run() {System.out.println("1111111111");try {sleep(1000);data="999";} catch (InterruptedException e) {e.printStackTrace();}}}
}
synchronized和lock锁的区别
synchronized内置的java关键字,Lock是一个java类
synchronized无法判断获取锁的状态, Lock可以判断是否获取到了锁
synchronized会自动释放锁,Lock必须要手动释放锁!如果不是释放锁,会产生死锁
synchronized 线程1(获得锁,阻塞),线程2(等待); Lock锁就不一定会等待下去
synchronized 可重入锁,不可以中断的,非公平的; Lock锁,可重入的,可以判断锁,非公平(可自己设置);
synchronized 适合锁少量的代码同步问题,Lock 适合锁大量的同步代码
ReentrantLock与synchronized区别及性能差异?
区别
主要相同点:Lock能完成synchronized所实现的所有功能
主要不同点:Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。
1.新的ReentrantLock的确实现了和同步块相同的语义功能。而对象锁的获得和释放都可以由编码人员自行掌握。
2.使用新的ReentrantLock,免去了为同步块放置合适的对象锁所要进行的考量。
3.使用新的ReentrantLock,最佳的实践就是结合try/finally块来进行。在try块之前使用lock方法,而在finally中使用unlock方法。
同步的实现当然是采用锁了,java中使用锁的两个基本工具是 synchronized 和 Lock。
synchronized使用很方便。比如,需要对一个方法进行同步,那么只需在方法的签名添加一个synchronized关键字。
未同步的方法
public void test() {}
同步的方法
pubilc synchronized void test() {}
synchronized 也可以用在一个代码块上
public void test() {
synchronized(obj) {
System.out.println("===");
}
}
wait()与notify()与notifyAll()
这三个方法都是Object的方法,并不是线程的方法!
wait():释放占有的对象锁,线程进入等待池,释放cpu,而其他正在等待的线程即可抢占此锁,获得锁的线程即可运行程序。而sleep()不同的是,线程调用此方法后,会休眠一段时间,休眠期间,会暂时释放cpu,但并不释放对象锁。也就是说,在休眠期间,其他线程依然无法进入此代码内部。休眠结束,线程重新获得cpu,执行代码。wait()和sleep()最大的不同在于wait()会释放对象锁,而sleep()不会!
notify(): 该方法会唤醒因为调用对象的wait()而等待的线程,其实就是对对象锁的唤醒,从而使得wait()的线程可以有机会获取对象锁。调用notify()后,并不会立即释放锁,而是继续执行当前代码,直到synchronized中的代码全部执行完毕,才会释放对象锁。JVM则会在等待的线程中调度一个线程去获得对象锁,执行代码。需要注意的是,wait()和notify()必须在synchronized代码块中调用。
notifyAll()则是唤醒所有等待的线程。
为了说明这一点,举例如下:
两个线程依次打印"A""B",总共打印10次。
class Consumer1 implements Runnable {@Overridepublic synchronized void run() {int count = 10;while (count > 0) {synchronized (TestSynchronized.obj) {System.out.println("B" + count);count --;TestSynchronized.obj.notify(); // 主动释放对象锁try {TestSynchronized.obj.wait();} catch (InterruptedException e) {e.printStackTrace();}}}}
}
class Produce1 implements Runnable {@Overridepublic void run() {int count = 10;while(count > 0) {synchronized (TestSynchronized.obj) {//System.out.print("count = " + count);System.out.println("A" + count);count --;TestSynchronized.obj.notify();try {TestSynchronized.obj.wait();} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}
//测试类如下:
public class TestSynchronized {public static final Object obj = new Object();public static void main(String[] args) {new Thread( new Produce1()).start();new Thread( new Consumer1()).start();}
}
这里使用static obj作为锁的对象,当线程Produce启动时(假如Produce首先获得锁,则Consumer会等待),打印“A”后,会先主动释放锁,然后阻塞自己。Consumer获得对象锁,打印“B”,然后释放锁,阻塞自己,那么Produce又会获得锁,然后...一直循环下去,直到count = 0.这样,使用Synchronized和wait()以及notify()就可以达到线程同步的目的。
除了wait()和notify()协作完成线程同步之外,使用Lock也可以完成同样的目的。
ReentrantLock 与synchronized有相同的并发性和内存语义,还包含了中断锁等候和定时锁等候,意味着线程A如果先获得了对象obj的锁,那么线程B可以在等待指定时间内依然无法获取锁,那么就会自动放弃该锁。
但是由于synchronized是在JVM层面实现的,因此系统可以监控锁的释放与否,而ReentrantLock使用代码实现的,系统无法自动释放锁,需要在代码中finally子句中显式释放锁lock.unlock();
同样的例子,使用lock 如何实现呢?
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class Consumer2 implements Runnable {private Lock lock;public Consumer2(Lock lock) {this.lock = lock;}public void run() {int count = 10;while( count > 0 ) {try {lock.lock();count --;System.out.println("B" + count);} finally {lock.unlock(); //主动释放锁try {Thread. sleep(91L);} catch (InterruptedException e) {e.printStackTrace();}}}}
}
class Producer2 implements Runnable{private Lock lock;public Producer2(Lock lock) {this.lock = lock;}public void run() {int count = 10;while (count > 0) {try {lock.lock();count --;System. out.println("A" + count);} finally {lock.unlock();try {Thread.sleep(90L);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}
//测试类如下:
public class TestLock {public static void main(String[] args) {Lock lock = new ReentrantLock();Consumer2 consumer = new Consumer2(lock);Producer2 producer = new Producer2(lock);new Thread(consumer).start();new Thread( producer).start();}
}
Synchronized与ReentrantLock性能:
在并发量比较小的情况下,使用synchronized是个不错的选择,但是在并发量比较高的情况下,其性能下降很严重,此时ReentrantLock是个不错的方案。
JUC < java.util.concurrent.locks >
JUC是什么?
JUC是java.util.concurrent包的简称,在Java5.0添加,目的就是为了更好的支持高并发任务。让开发者进行多线程编程时减少竞争条件和死锁的问题!在此包中增加了在并发编程中很常用的实用工具类,用于定义类似于线程的自定义子系统,包括线程池、异步IO 和轻量级任务框架。提供可调的、灵活的线程池。还提供了设计用于多线程上下文中的Collection 实现等
进程与线程的区别:
进程 : 一个运行中的程序的集合; 一个进程往往可以包含多个线程,至少包含一个线程
java默认有几个线程? 两个 main线程 gc线程
线程 : 线程(thread)是操作系统能够进行运算调度的最小单位。
并发与并行的区别:
并发(多线程操作同一个资源,交替执行),CPU一核, 模拟出来多条线程,天下武功,唯快不破,快速交替
并行(多个人一起行走, 同时进行),CPU多核,多个线程同时进行;使用线程池操作
线程有六个状态:
public enum State {// 新生NEW,// 运行RUNNABLE,// 阻塞BLOCKED,// 等待WAITING,//超时等待TIMED_WAITING,//终止TERMINATED;}
wait/sleep的区别:
来自不同的类
wait来自object类, sleep来自线程类
关于锁的释放
wait会释放锁, sleep不会释放锁
使用的范围不同
wait必须在同步代码块中
sleep可以在任何地方睡眠
JUC的结构
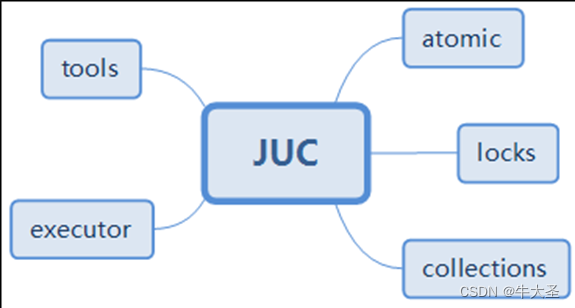
1,tools(工具类):又叫信号量三组工具类:
1)CountDownLatch(闭锁) 是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待
2)CyclicBarrier(栅栏) 之所以叫barrier,是因为是一个同步辅助类,允许一组线程互相等待,直到到达某个公共屏障点 ,并且在释放等待线程后可以重用。
3)Semaphore(信号量) 是一个计数信号量,它的本质是一个“共享锁“。信号量维护了一个信号量许可集。线程可以通过调用 acquire()来获取信号量的许可;当信号量中有可用的许可时,线程能获取该许可;否则线程必须等待,直到有可用的许可为止。 线程可以通过release()来释放它所持有的信号量许可。
2,executor(执行者):
Java里面线程池的顶级接口,但它只是一个执行线程的工具,真正的线程池接口是ExecutorService,里面包含的类有:
1)ScheduledExecutorService 解决那些需要任务重复执行的问题
2)ScheduledThreadPoolExecutor 周期性任务调度的类实现
3,atomic(原子性包):
JDK提供的一组原子操作类,包含有AtomicBoolean、AtomicInteger、AtomicIntegerArray等原子变量类,他们的实现原理大多是持有它们各自的对应的类型变量value,而且被volatile关键字修饰了。这样来保证每次一个线程要使用它都会拿到最新的值。
4,locks(锁包):
JDK提供的锁机制,相比synchronized关键字来进行同步锁,功能更加强大,它为锁提供了一个框架,该框架允许更灵活地使用锁包含的实现类有:
1)ReentrantLock 它是独占锁,是指只能被独自占领,即同一个时间点只能被一个线程锁获取到的锁。
2)ReentrantReadWriteLock 它包括子类ReadLock和WriteLock。ReadLock是共享锁,而WriteLock是独占锁。
3)LockSupport 它具备阻塞线程和解除阻塞线程的功能,并且不会引发死锁。
5,collections(集合类):
主要是提供线程安全的集合, 比如:
1)ArrayList对应的高并发类是CopyOnWriteArrayList,
2)HashSet对应的高并发类是 CopyOnWriteArraySet,
3)HashMap对应的高并发类是ConcurrentHashMap等等
普通的线程代码, 之前都是用的thread或者runnable接口
public class demo01 {public static void main(String[] args) {ThreadDemo threadDemo = new ThreadDemo();threadDemo.start();new Thread(new ThreadDemo2()).start();}
}class ThreadDemo extends Thread{@Overridepublic void run() {System.out.println("普通线程已开启(继承Thread)");}
}
class ThreadDemo2 implements Runnable{@Overridepublic void run() {System.out.println("普通线程已开启(实现Runnable接口)");}
}
程序运行结果:
程序运行结果:

JUC的volatile 关键字-内存可见性
内存可见性(Memory Visibility)是指当某个线程正在使用对象状态而另一个线程在同时修改该状态,需要确保当一个线程修改了对象状态后,其他线程能够看到发生的状态变化。
可见性错误是指当读操作与写操作在不同的线程中执行时,我们无法确保执行读操作的线程能适时地看到其他线程写入的值,有时甚至是根本不可能的事情。
我们可以通过同步来保证对象被安全地发布。除此之外我们也可以使用一种更加轻量级的volatile 变量。
volatile 关键字
Java提供了一种稍弱的同步机制,即volatile 变量,用来确保将变量的更新操作通知到其他线程。可以将volatile 看做一个轻量级的锁,但是又与锁有些不同:
对于多线程,不是一种互斥关系,不能保证变量状态的“原子性操作”
volatile 关键字:当多个线程进行操作共享数据时,可以保证内存中的数据可见。相较于 synchronized 是一种较为轻量级的同步策略。
注意:1. volatile 不具备“互斥性” 2. volatile 不能保证变量的“原子性”
JUC的原子变量-CAS算法
CAS (Compare-And-Swap) 是一种硬件对并发的支持,针对多处理器操作而设计的处理器中的一种特殊指令,用于管理对共享数据的并发访问。
CAS 是一种无锁的非阻塞算法的实现。
CAS 包含了3 个操作数:
需要读写的内存值V
进行比较的值A
拟写入的新值B
当且仅当V 的值等于A 时,CAS 通过原子方式用新值B 来更新V 的值,否则不会执行任何操作。
原子变量
类的小工具包,支持在单个变量上解除锁的线程安全编程。事实上,此包中的类可将volatile 值、字段和数组元素的概念扩展到那些也提供原子条件更新操作的类。
类AtomicBoolean、AtomicInteger、AtomicLong 和AtomicReference 的实例各自提供对相应类型单个变量的访问和更新。每个类也为该类型提供适当的实用工具方法。
AtomicIntegerArray、AtomicLongArray 和AtomicReferenceArray 类进一步扩展了原子操作,对这些类型的数组提供了支持。这些类在为其数组元素提供volatile 访问语义方面也引人注目,这对于普通数组来说是不受支持的。
核心方法:boolean compareAndSet(expectedValue, updateValue)
java.util.concurrent.atomic 包下提供了一些原子操作的常用类:
AtomicBoolean 、AtomicInteger 、AtomicLong 、AtomicReference
AtomicIntegerArray 、AtomicLongArray
AtomicMarkableReference
AtomicReferenceArray
AtomicStampedReference
JUC的Lock:
多线程在JDK1.5版本升级时,推出一个接口Lock接口。
解决线程安全问题使用同步的形式,(同步代码块,要么同步方法)其实最终使用的都是锁机制。到了后期版本,直接将锁封装成了对象。线程进入同步就是具备了锁,执行完,离开同步,就是释放了锁。
在后期对锁的分析过程中,发现,获取锁,或者释放锁的动作应该是锁这个事物更清楚。所以将这些动作定义在了锁当中,并把锁定义成对象。
所以同步是隐示的锁操作,而Lock对象是显示的锁操作,它的出现就替代了同步。
在之前的版本中使用Object类中wait、notify、notifyAll的方式来完成的。那是因为同步中的锁是任意对象,所以操作锁的等待唤醒的方法都定义在Object类中。
而现在锁是指定对象Lock。所以查找等待唤醒机制方式需要通过Lock接口来完成。而Lock接口中并没有直接操作等待唤醒的方法,而是将这些方式又单独封装到了一个对象中。这个对象就是Condition,将Object中的三个方法进行单独的封装。并提供了功能一致的方法 await()、signal()、signalAll()体现新版本对象的好处。
传统synchronized
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
Lock 接口

实现类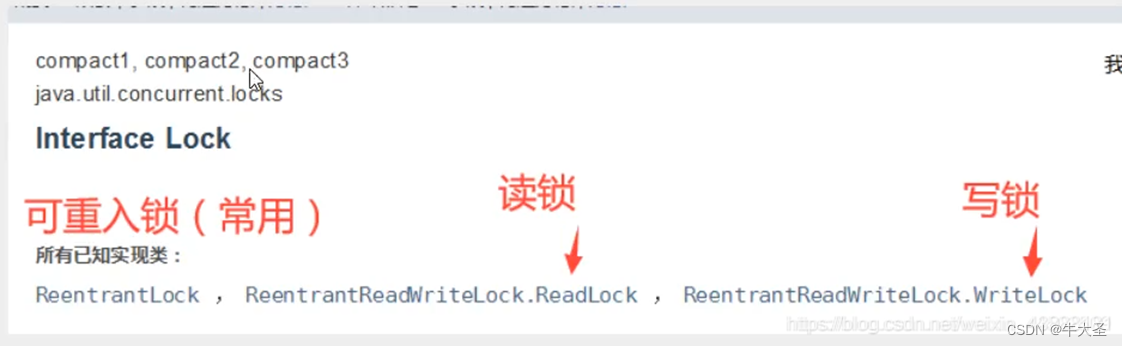
在java.util.concurrent.locks 这个包中提供了Lock接口,该接口的定义如下:
public interface Lock { void lock(); void lockInterruptibly(); boolean tryLock(); boolean tryLock(long time, TimeUnit unit) throw InterruptedException; boolean unlock(); Condition newCondition();
}
这其中的lock方法和unlock方法没有什么好讲的,其实作用和synchronized(lock)差不多。lock方法会阻塞式的等待锁。
lockInterrupitbly()方法中,获取到锁的线程被中断的时候,会抛出中断异常,并释放持有的锁。使用synchronized关键字获取锁的线程是做不到这一点的。
tryLock()方法则不会阻塞,如果没有获取到锁,会立即返回false,不会一直等待。
tryLock(long time, TimeUnit unit)则会在指定的时间段内等待锁。如果没有等到,则返回false。
最后一个方法newCondition(),这个是用于获取Condition对象,该对象用于线程之间的同步,这里我们就不涉及了。
Lock接口的实现类ReentrantLock
同时,Java还提供了Lock接口的实现类ReentrantLock。从名字上就可以看出,这是一个可重入锁。该类的实现,依赖于其中的一个内部抽象类Sync,该类有两个具体的实现NonfairSync和FairSync。一个用于实现非公平锁,一个用于实现公平锁。具体的获取锁和释放锁的逻辑,其实都在Sync类及其两个子类中。
reentrantLock构造器
public ReentrantLock() {sync = new NonfairSync(); //无参默认非公平锁
}
public ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();//传参为true为公平锁
}
公平锁: 十分公平: 可以先来后到,一定要排队
非公平锁: 十分不公平,可以插队(默认)
ReentrantLock是怎样实现可重入的呢?在ReentrantLock中,会有一个变量用来保存当前持有锁的线程对象。(实际上是在Sync对象中持有该变量,为了叙述方便,后面不再详细区分,有兴趣的可以自己看看源码。)
protected final boolean tryAcquire(int acquires) { final Thread current = Thread.currentThread(); //获取当前线程int c = getState(); //获取当前同步状态的值if (c == 0) { //当前同步状态没有被任何线程获取的时候if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; }
}
上面的代码主要是一个if...else...语句。主体的逻辑是:
- 如果当前锁没有给任何线程持有,则直接获取锁(获取锁的方式使用的是compareAndSetState,底层实际上使用的是Compare And Swap(CAS)机制来实实现的)。获取成功则返回true来表示获取锁成功。
- 如果当前锁已经被其他线程持有,那么判断持有锁的线程是否是当前线程,如果是的话,则增加锁的计数,返回true,表示获取锁成功。
- 如果前面两条都没有成功,则返回false,表示获取锁失败。
可重入锁的释放也不是立即直接释放,而是每次减少计数,直到计数为0。如下面的代码所示:
protected final boolean tryRelease(int releases) {int c = getState() - releases;if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();boolean free = false;if (c == 0) {free = true;setExclusiveOwnerThread(null);}setState(c);return free;
}
在实例化ReentrantLock类的时候,可以传入一个boolean类型的参数,用于指定是需要公平锁还是非公平锁(默认是非公平锁)。
通常来说,该类的使用方式如下:
private Lock lock = new ReentrantLock(); // 默认使用非公平锁public void someMethodUsingLock(){......lock.lock();try{......} catch (Exception e){......} finally {lock.unlock();}}
上面的代码中,我们没有将lock.lock()这一行代码放在try中,是因为如果放在try中,并且在执行这一行代码的时候抛出了异常,那么就会进入finally的代码块中,会执行lock.unlock(),但是实际上当前线程可能并没有获取到锁,执行unlock又会抛出异常。
可重入特性实现了,那么公平/非公平又是怎么实现的?公平和非公平在tryLock(long time, TimeUnit unit)这个方法中有不同。我们一直跟踪到具体实现,让我们看看代码:
非公平锁的实现代码
final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;
}
公平锁的实现代码
final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;
}
可以看到,唯一的不同就是一个调用,公平锁在获取锁之前,调用了!hasQueuedPredecessors(),先判断是否有其他的线程已经在排队了。
SaleTicketDemo
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class SaleTicketDemo {public static void main(String[] args) {Ticket ticket = new Ticket();new Thread(()->{for(int i = 0; i < 40; i++) ticket.sale();}, "a").start();new Thread(()->{for(int i = 0; i < 40; i++) ticket.sale();}, "b").start();new Thread(()->{for(int i = 0; i < 40; i++) ticket.sale();}, "c").start();}
}class Ticket {private int ticketNum = 6;// 非公平锁只会输出A private Lock lock = new ReentrantLock();// 公平锁a,b,c轮询输出 private Lock lock = new ReentrantLock(true);private Lock lock = new ReentrantLock(true);public void sale() {lock.lock();try {if (this.ticketNum > 0) {System.out.println(Thread.currentThread().getName() + "购得第" + ticketNum-- + "张票, 剩余" + ticketNum + "张票");}//增加错误的发生几率Thread.sleep(10);} catch (Exception e) {e.printStackTrace();} finally {lock.unlock();}}}
公平锁输出结果

非公平锁输出结果
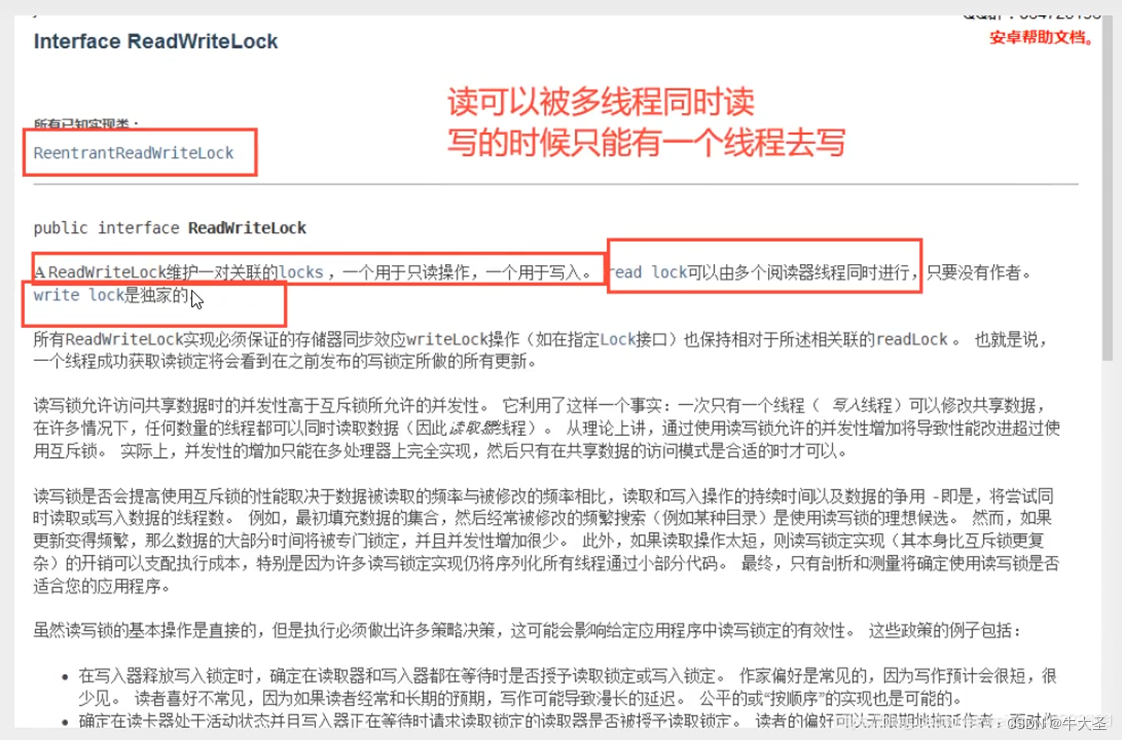
读写锁接口ReadWriteLock
在最开始的一篇文章中,我们已经提到了读写锁,并且说读写锁其实是一个组合锁。我们来看看Java中给出的ReadWriteLock接口:
public interface ReadWriteLock {Lock readLock();Lock writeLock();
}
在Java给出的实现类ReentrantReadWriteLock中,分别实现了ReadLock和WriteLock类。它们的不同在于,在ReadLock的中,获取锁的代码是
public void lock() {sync.acquireShared(1);
}
但是在WriteLock中,获取锁的代码是
public void lock() {sync.acquire(1);
}
从名字上就可以看出,一个是共享锁,一个是排他锁。具体的实现方式,大家可以自己去看看源代码。
乐观读写锁StampedLock
前面我们介绍的这些锁的实现,都是悲观锁,包括上面的ReentrantReadWriteLock。在ReentrantReadWriteLock中,在读的时候是不能写的,在写的时候也是不能读的。
在Java 8中,又引入了另外一种读写锁,StampedLock。这个锁和前面的ReentrantReadWriteLock的不同之处在于,StampedLock中,如果有线程获取了读锁,正在读取数据,另外一个线程可以获取写锁来写数据。 因此这种锁是一种乐观锁(至少在这种情况下是)。但是乐观锁带来的问题是读取的数据可能不一致,因此需要额外的代码来判断。大致的代码如下:
StampedLock stampedLock = new StampedLock();long stamp = stampedLock.tryOptimisticRead(); // 获得一个乐观读锁
....... //读取数据,可能是读取多个数据if (!stampedLock.validate(stamp)) { // 检查乐观读锁后是否有其他写锁发生//说明读取过程中有写入操作,因此可能读取到错误的数据stamp = stampedLock.readLock(); // 获取一个悲观读锁try {...... //重新读取数据} finally {stampedLock.unlockRead(stamp); // 释放悲观读锁}}
小结
Java中提供了一些锁的接口和实现类,包括普通的Lock接口,ReadWriteLock接口,并且提供了相应的实现ReentrantLock,ReentrantReadWriteLock,StampedLock。
JUC的Condition 精准的通知和唤醒线程
Condition是个接口,基本的方法就是await()和signal()方法;
Condition依赖于Lock接口,生成一个Condition的基本代码是lock.newCondition()。
调用Condition的await()和signal()方法,都必须在lock保护之内,就是说必须在lock.lock()和lock.unlock之间才可以使用。
Condition 接口描述了可能会与锁有关联的条件变量。这些变量在用法上与使用Object.wait 访问的隐式监视器类似,但提供了更强大的功能。需要特别指出的是,单个Lock 可能与多个Condition 对象关联。为了避免兼容性问题,Condition 方法的名称与对应的Object 版本中的不同。
Condition 实例实质上被绑定到一个锁上。要为特定Lock 实例获得Condition 实例,请使用其newCondition() 方法。
Conditon中的await()对应Object的wait();
Condition中的signal()对应Object的notify();
Condition中的signalAll()对应Object的notifyAll()。
Condition常见例子(生产者消费者模式(完成加一减一各一次操作)):
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class ConditionTest {public static void main(String[] args) {NewConditionTest a = new NewConditionTest();new Thread(()->{for (int i =0;i<10;i++){a.increment();}},"A").start();new Thread(()->{for (int i =0;i<10;i++){a.decrease();}},"B").start();}}
class NewConditionTest{public int nummber=0;Lock lock = new ReentrantLock();Condition condition = lock.newCondition();public void increment(){lock.lock();try {while(nummber!=0){condition.await();}nummber++;System.out.println(Thread.currentThread().getName()+">>"+nummber);condition.signalAll();}catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}public void decrease(){lock.lock();try {while(nummber!=1){condition.await();}nummber--;System.out.println(Thread.currentThread().getName()+">>"+nummber);condition.signalAll();}catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}
}
运行结果

集合类不安全
list 不安全
list 不安全
//java.util.ConcurrentModificationException 并发修改异常!
public class ListTest {public static void main(String[] args) {//并发下 arrayList 是不安全的/*** 解决方案* 1. 使用vector解决* 2. List<String> arrayList = Collections.synchronizedList(new ArrayList<>());* 3. List<String> arrayList = new CopyOnWriteArrayList<>();*///copyOnWrite 写入时复制 COW 计算机程序设计领域的一种优化策略//多个线程调用的时候, list, 读取的时候固定的,写入的时候,可能会覆盖//在写入的时候避免覆盖造成数据问题//CopyOnWriteArrayList 比 vector牛逼在哪里//读写分离List<String> arrayList = new CopyOnWriteArrayList<>();for (int i = 0; i < 100; i++) {new Thread(()->{arrayList.add(UUID.randomUUID().toString().substring(0,5));System.out.println(arrayList);},String.valueOf(i)).start();}//安全List<String> arrayList = Collections.synchronizedList(new ArrayList<>());;for (int i = 0; i < 10; i++) {new Thread(()->{arrayList.add( UUID.randomUUID().toString().substring(0,5));System.err.println(arrayList);},String.valueOf(i)).start();}}
}

set 不安全
/*** 同理可证*/
public class SetTest {public static void main(String[] args) {// Set<String> set = new HashSet<>();//如何解决hashSet线程安全问题//1. Set<String> set = Collections.synchronizedSet(new HashSet<>());Set<String> set1 = new CopyOnWriteArraySet<>();for (int i = 0; i < 10; i++) {new Thread(() -> {set1.add( UUID.randomUUID().toString().substring(0, 5));System.out.println(set1);}, String.valueOf(i)).start();}Set<String> set = Collections.synchronizedSet(new HashSet<>());for (int i = 0; i < 10; i++) {new Thread(() -> {set.add( UUID.randomUUID().toString().substring(0, 5));System.err.println(set);}, String.valueOf(i)).start();}}
}
hashSet底层是什么? hashMap
public HashSet() {map = new HashMap<>();
}
// add 的本质就是 map 的 key key是无法重复的
public boolean add(E e) {return map.put(e, PRESENT)==null;
}
private static final Object PRESENT = new Object();//这是一个不变的值
HashMap 不安全
map的基本操作

HashTable、SynchronizedMap、ConcurrentHashMap这三种是实现线程安全的Map。
HashTable:是直接在操作方法上加synchronized关键字,锁住整个数组,粒度比较大;
SynchronizedMap:是使用Collections集合工具的内部类,通过传入Map封装出一个SynchronizedMap对象,内部定义了一个对象锁,方法内通过对象锁实现;
Map<Object, Object> map = Collections.synchronizedMap( new HashMap<>());;for (int i = 0; i < 10; i++) {new Thread(()->{map.put( UUID.randomUUID().toString().substring(0,5),UUID.randomUUID().toString().substring(0,5));System.err.println(map);},String.valueOf(i)).start();}
}
ConcurrentHashMap:使用分段锁(CAS + synchronized相结合),降低了锁粒度,大大提高并发度。
ConcurrentHashMap
1 ConcurrentHashMap默认初始容量为16
2 ConCurrentHashmap如果key或者value为null会抛出空指针异常
3 ConCurrentHashmap 每次扩容是原来容量2倍 在transfer方法里面会创建一个原数组的俩倍的node数组来存放原数据。
4 ConCurrentHashmap的数据结构在java1.8中,它是一个数组+链表+红黑树的数据结构。
5 存储在ConCurrentHashmap中每个节点是什么样的,有哪些变量
它是实现Map.Entry<K,V>接口。里面存放了hash,key,value,以及next节点。它的value和next节点是用volatile进行修饰,可以保证多线程之间的可见性。
6 ConCurrentHashmap的put过程是怎样的?
整体流程跟HashMap比较类似,大致是以下几步:
如果桶数组未初始化,则初始化;
如果待插入的元素所在的桶为空,则尝试把此元素直接插入到桶的第一个位置;
如果正在扩容,则当前线程一起加入到扩容的过程中;
如果待插入的元素所在的桶不为空且不在迁移元素,则锁住这个桶(分段锁);
如果当前桶中元素以链表方式存储,则在链表中寻找该元素或者插入元素;
如果当前桶中元素以红黑树方式存储,则在红黑树中寻找该元素或者插入元素;
如果元素存在,则返回旧值;
如果元素不存在,整个Map的元素个数加1,并检查是否需要扩容;
添加元素操作中使用的锁主要有(自旋锁 + CAS + synchronized + 分段锁)。
7 java1.8中ConCurrentHashmap节点是尾插还是头插?
尾插法,见上述put方法。
8 java1.8中,ConCurrentHashmap什么情况下链表才会转换成红黑树进行存储?
链表长度大于8。数组长度大于64。从put源码和以下源码可以看出:并非一开始就创建红黑树结构,如果当前Node数组长度小于阈值MIN_TREEIFY_CAPACITY,默认为64,先通过扩大数组容量为原来的两倍以缓解单个链表元素过大的性能问题。
9 java1.8中,ConCurrentHashmap的get过程是怎样的?
计算 hash 值
根据 hash 值找到数组对应位置: (n - 1) & h
根据该位置处节点性质进行相应查找
如果该位置为 null,那么直接返回 null 就可以了
如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法如果以上 3 条都不满足,那就是链表,进行遍历比对即可
10 java1.8中,ConCurrentHashmap是如何计算它的size大小的?
对于size的计算,在扩容和addCount()方法就已经有处理了,可以注意一下Put函数,里面就有函数。
11 ConcurrentHashMap有哪些构造函数?
一共有五个,作用及代码如下:
//无参构造函数public ConcurrentHashMap() {}//可传初始容器大小的构造函数public ConcurrentHashMap(int initialCapacity) {if (initialCapacity < 0)throw new IllegalArgumentException();int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?MAXIMUM_CAPACITY :tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));this.sizeCtl = cap;}//可传入map的构造函数public ConcurrentHashMap(Map<? extends K, ? extends V> m) {this.sizeCtl = DEFAULT_CAPACITY;putAll(m);}//可设置阈值和初始容量public ConcurrentHashMap(int initialCapacity, float loadFactor) {this(initialCapacity, loadFactor, 1);}//可设置初始容量和阈值和并发级别public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)throw newif (initialCapacity < concurrencyLevel) // Use at least as many binsinitialCapacity = concurrencyLevel; // as estimated threadslong size = (long)(1.0 + (long)initialCapacity / loadFactor);int cap = (size >= (long)MAXIMUM_CAPACITY) ?MAXIMUM_CAPACITY : tableSizeFor((int)size);this}
12 ConcurrentHashMap使用什么技术来保证线程安全?
jdk1.7:Segment+HashEntry来进行实现的;
jdk1.8:放弃了Segment臃肿的设计,采用Node+CAS+Synchronized来保证线程安全;
13 ConcurrentHashMap的get方法是否要加锁,为什么?
不需要,get方法采用了unsafe方法,来保证线程安全。
14 ConcurrentHashMap迭代器是强一致性还是弱一致性?HashMap呢?
弱一致性,HashMap强一直性。
ConcurrentHashMap可以支持在迭代过程中,向map添加新元素,而HashMap则抛出了ConcurrentModificationException,因为HashMap包含一个修改计数器,当你调用他的next()方法来获取下一个元素时,迭代器将会用到这个计数器。
15 ConcurrentHashMap1.7和1.8的区别
jdk1.8的实现降低锁的粒度,jdk1.7锁的粒度是基于Segment的,包含多个HashEntry,而jdk1.8锁的粒度就是Node
数据结构:jdk1.7 Segment+HashEntry;jdk1.8 数组+链表+红黑树+CAS+synchronized
常用的辅助类
CountDownLatch

Java 5.0 在java.util.concurrent 包中提供了多种并发容器类来改进同步容器的性能。
countDownLatch 一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。是多线程控制的一种工具,它被称为 门阀、 计数器或者 闭锁。这个工具经常用来用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。
闭锁可以延迟线程的进度直到其到达终止状态,闭锁可以用来确保某些活动直到其他活动都完成才继续执行:
确保某个计算在其需要的所有资源都被初始化之后才继续执行;
确保某个服务在其依赖的所有其他服务都已经启动之后才启动;
等待直到某个操作所有参与者都准备就绪再继续执行。
认识 CountDownLatch
CountDownLatch 能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。它相当于是一个计数器,这个计数器的初始值就是线程的数量,每当一个任务完成后,计数器的值就会减一,当计数器的值为0时,表示所有的线程都已经任务了,然后在CountDownLatch上等待的线程就可以恢复执行接下来的任务。
测试
//计数器
public class CountDownLatchTest{public static void main(String[] args) throws InterruptedException {//相当于计数器CountDownLatch countDownLatch = new CountDownLatch(5);//计数器总数是5,当减少为0,任务才继续向下执行for (int i = 1; i <6 ; i++) {new Thread(()->{System.out.println(Thread.currentThread().getName()+"==>start");countDownLatch.countDown();}).start();}countDownLatch.await();System.out.println("main线程继续向下执行");}
}
结果:
原理:
countDownLatch.countDown(); //数量减1
countDownLatch.await();// 等待计数器归零,然后再向下执行
每次有线程调用countDown()数量-1,假设计数器变为0,countDownLatch.await();就会被唤醒,继续执行
CountDownLatch 的使用
CountDownLatch提供了一个构造方法,你必须指定其初始值,还指定了countDown方法,这个方法的作用主要用来减小计数器的值,当计数器变为0时,在CountDownLatch上await的线程就会被唤醒,继续执行其他任务。当然也可以延迟唤醒,给CountDownLatch加一个延迟时间就可以实现。
其主要方法如下
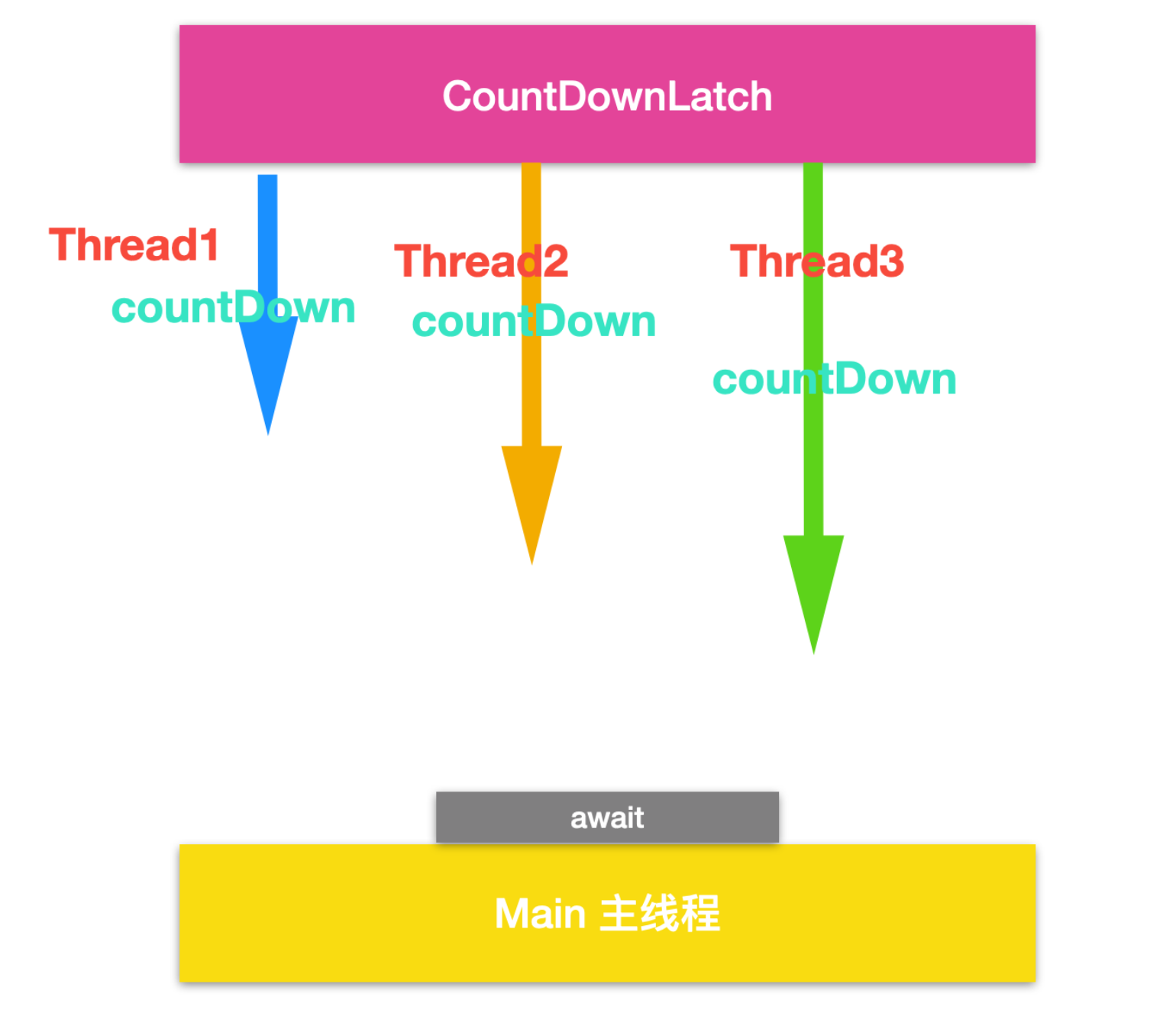
CountDownLatch 应用场景
典型的应用场景就是当一个服务启动时,同时会加载很多组件和服务,这时候主线程会等待组件和服务的加载。当所有的组件和服务都加载完毕后,主线程和其他线程在一起完成某个任务。
CountDownLatch 还可以实现学生一起比赛跑步的程序,CountDownLatch 初始化为学生数量的线程,鸣枪后,每个学生就是一条线程,来完成各自的任务,当第一个学生跑完全程后,CountDownLatch 就会减一,直到所有的学生完成后,CountDownLatch 会变为 0 ,接下来再一起宣布跑步成绩。
顺着这个场景,你自己就可以延伸、拓展出来很多其他任务场景。
CountDownLatch 用法
下面我们通过一个简单的计数器来演示一下 CountDownLatch
import java.util.concurrent.CountDownLatch;public class CountDownLatchTest02 {public static void main(String[] args) {CountDownLatch latch = new CountDownLatch(5);Increment increment = new Increment(latch);Decrement decrement = new Decrement(latch);new Thread(increment).start();new Thread(decrement).start();}
}class Decrement implements Runnable {CountDownLatch countDownLatch;public Decrement(CountDownLatch countDownLatch){this.countDownLatch = countDownLatch;}@Overridepublic void run() {try {for(long i = countDownLatch.getCount();i > 0;i--){Thread.sleep(1000);System.out.println("countdown");this.countDownLatch.countDown();}} catch (InterruptedException e) {e.printStackTrace();}}
}
class Increment implements Runnable {CountDownLatch countDownLatch;public Increment(CountDownLatch countDownLatch){this.countDownLatch = countDownLatch;}@Overridepublic void run() {try {System.out.println("await");countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Waiter Released");}
}
在main方法中我们初始化了一个计数器为5的CountDownLatch,在Decrement方法中我们使用countDown执行减一操作,然后睡眠一段时间,同时在Increment类中进行等待,直到Decrement中的线程完成计数减一的操作后,唤醒Increment类中的run方法,使其继续执行。
下面我们再来通过学生赛跑这个例子来演示一下CountDownLatch的具体用法
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class CountDownLatchTest03{CountDownLatch stopLatch = new CountDownLatch(1);CountDownLatch runLatch = new CountDownLatch(10);public void waitSignal() throws Exception{System.out.println("选手" + Thread.currentThread().getName() + "正在等待裁判发布口令");stopLatch.await();System.out.println("选手" + Thread.currentThread().getName() + "已接受裁判口令");Thread.sleep((long) (Math.random() * 10000));System.out.println("选手" + Thread.currentThread().getName() + "到达终点");runLatch.countDown();}public void waitStop() throws Exception{Thread.sleep((long) (Math.random() * 4000));System.out.println("裁判"+Thread.currentThread().getName()+"即将发布口令");stopLatch.countDown();System.out.println("裁判"+Thread.currentThread().getName()+"已发送口令,正在等待所有选手到达终点");runLatch.await();System.out.println("所有选手都到达终点");System.out.println("裁判"+Thread.currentThread().getName()+"汇总成绩排名");}public static void main(String[] args) {ExecutorService service = Executors.newCachedThreadPool();CountDownLatchTest03 studentRunRace = new CountDownLatchTest03();for (int i = 0; i < 10; i++) {Runnable runnable = () -> {try {studentRunRace.waitSignal();} catch (Exception e) {e.printStackTrace();}};service.execute(runnable);}try {studentRunRace.waitStop();} catch (Exception e) {e.printStackTrace();}service.shutdown();}
}
下面我们就来一起分析一下 CountDownLatch 的源码
CountDownLatch 源码分析
CountDownLatch 使用起来比较简单,但是却非常有用,现在你可以在你的工具箱中加上 CountDownLatch 这个工具类了。下面我们就来深入认识一下 CountDownLatch。
CountDownLatch 的底层是由 AbstractQueuedSynchronizer 支持,而 AQS 的数据结构的核心就是两个队列,一个是同步队列(sync queue),一个是条件队列(condition queue)。
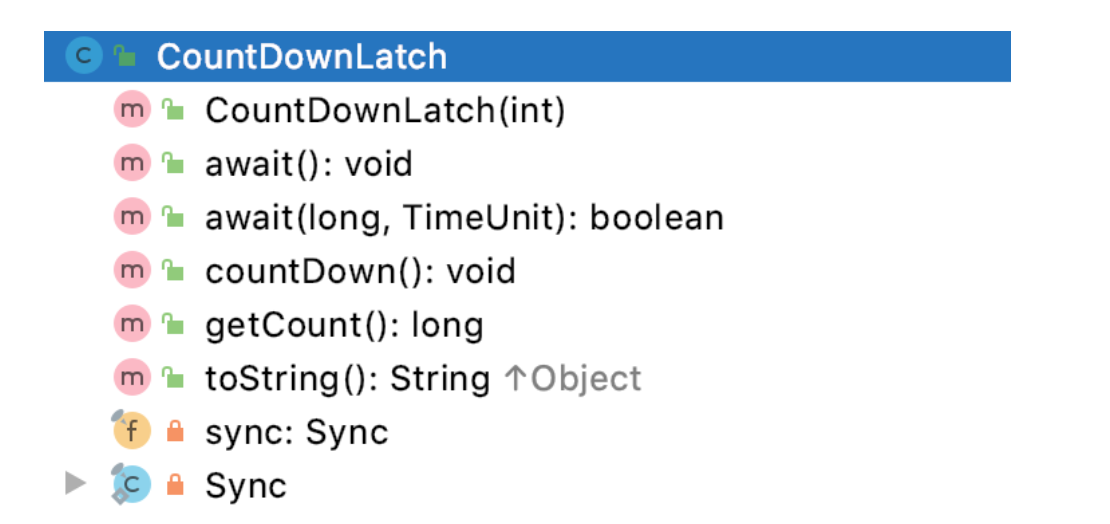
Sync 内部类
CountDownLatch 在其内部是一个Sync,它继承了AQS抽象类。
private static final class Sync extends AbstractQueuedSynchronizer{...}
CountDownLatch其实其内部只有一个sync属性,并且是final的
private final Sync sync;
CountDownLatch只有一个带参数的构造方法
public CountDownLatch(int count) {if (count < 0) throw new IllegalArgumentException("count < 0");this.sync = new Sync(count);
}
也就是说,初始化的时候必须指定计数器的数量,如果数量为负会直接抛出异常。
然后把 count 初始化为Sync内部的count,也就是
Sync(int count) {setState(count);
}
注意这里有一个setState(count),这是什么意思呢?见闻知意这只是一个设置状态的操作,但是实际上不单单是,还有一层意思是state的值代表着待达到条件的线程数。这个我们在聊countDown方法的时候再讨论。
getCount()方法的返回值是getState()方法,它是AbstractQueuedSynchronizer中的方法,这个方法会返回当前线程计数,具有volatile读取的内存语义。
// ---- CountDownLatch ----
int getCount() {return getState();
}
// ---- AbstractQueuedSynchronizer ----
protected final int getState() {return state;
}
tryAcquireShared() 方法用于获取·共享状态下对象的状态,判断对象是否为 0 ,如果为 0 返回 1 ,表示能够尝试获取,如果不为 0,那么返回 -1,表示无法获取。
protected int tryAcquireShared(int acquires) {return (getState() == 0) ? 1 : -1;
}
// ---- getState() 方法和上面的方法相同 ----
这个 共享状态 属于 AQS 中的概念,在 AQS 中分为两种模式,一种是 独占模式,一种是 共享模式。
• tryAcquire 独占模式,尝试获取资源,成功则返回 true,失败则返回 false。
• tryAcquireShared 共享方式,尝试获取资源。负数表示失败;0 表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared() 方法用于共享模式下的释放
protected boolean tryReleaseShared(int releases) {// 减小数量,变为 0 的时候进行通知for (;;) {int c = getState();if (c == 0)return false;int nextc = c - 1;if (compareAndSetState(c, nextc))return nextc == 0;}
}
这个方法是一个无限循环,获取线程状态,如果线程状态是 0 则表示没有被线程占有,没有占有的话那么直接返回 false ,表示已经释放;然后下一个状态进行 - 1 ,使用 compareAndSetState CAS 方法进行和内存值的比较,如果内存值也是 1 的话,就会更新内存值为 0 ,判断 nextc 是否为 0 ,如果 CAS 比较不成功的话,会再次进行循环判断。
如果 CAS 用法不清楚的话,读者朋友们可以参考这篇文章 告诉你一个 AtomicInteger 的惊天大秘密!
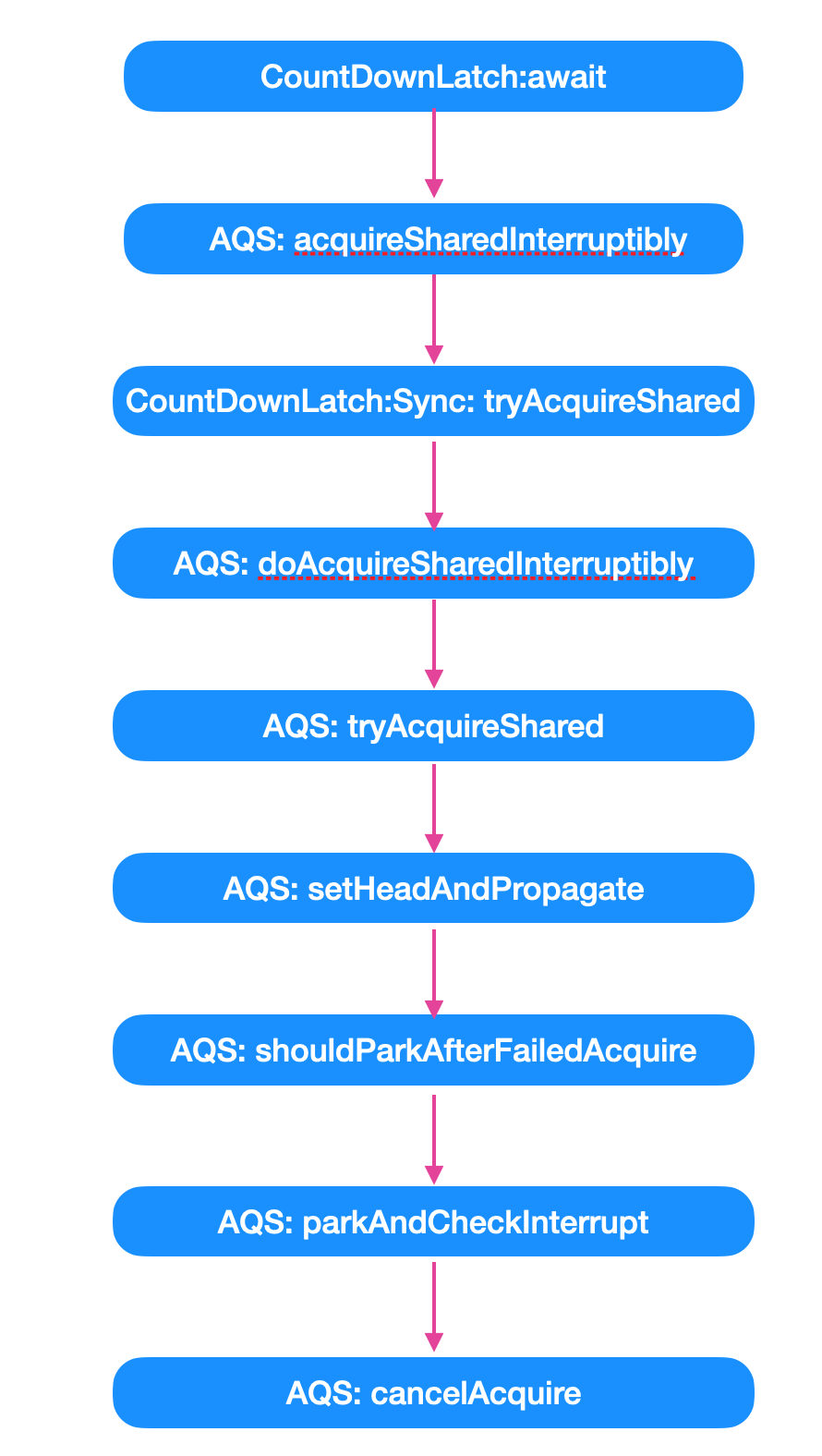
await 方法
await()方法是CountDownLatch一个非常重要的方法,基本上可以说只有countDown和await方法才是CountDownLatch的精髓所在,这个方法将会使当前线程在CountDownLatch计数减至零之前一直等待,除非线程被中断。
CountDownLatch中的await方法有两种,一种是不带任何参数的await(),一种是可以等待一段时间的await(long timeout, TimeUnit unit)。下面我们先来看一下 await() 方法。
public void await() throws InterruptedException {sync.acquireSharedInterruptibly(1);
}
public boolean await(long timeout, TimeUnit unit)throws InterruptedException {return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
}
await方法内部会调用acquireSharedInterruptibly方法,这个acquireSharedInterruptibly是AQS中的方法,以共享模式进行中断。
public final void acquireSharedInterruptibly(int arg)throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();if (tryAcquireShared(arg) < 0)doAcquireSharedInterruptibly(arg);
}
可以看到,acquireSharedInterruptibly 方法的内部会首先判断线程是否中断,如果线程中断,则直接抛出线程中断异常。如果没有中断,那么会以共享的方式获取。如果能够在共享的方式下不能获取锁,那么就会以共享的方式断开链接。
private void doAcquireSharedInterruptibly(int arg)throws InterruptedException {final Node node = addWaiter(Node.SHARED);try {for (;;) {final Node p = node.predecessor();if (p == head) {int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCreturn;}}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())throw new InterruptedException();}} catch (Throwable t) {cancelAcquire(node);throw t;}
}
这个方法有些长,我们分开来看
• 首先,会先构造一个共享模式的 Node 入队
• 然后使用无限循环判断新构造 node 的前驱节点,如果 node 节点的前驱节点是头节点,那么就会判断线程的状态,这里调用了一个 setHeadAndPropagate ,其源码如下
• private void setHeadAndPropagate(Node node, int propagate) {
• Node h = head; // Record old head for check below
• setHead(node);
• /*
• * Try to signal next queued node if:
• * Propagation was indicated by caller,
• * or was recorded (as h.waitStatus either before
• * or after setHead) by a previous operation
• * (note: this uses sign-check of waitStatus because
• * PROPAGATE status may transition to SIGNAL.)
• * and
• * The next node is waiting in shared mode,
• * or we don't know, because it appears null
• *
• * The conservatism in both of these checks may cause
• * unnecessary wake-ups, but only when there are multiple
• * racing acquires/releases, so most need signals now or soon
• * anyway.
• */
• if (propagate > 0 || h == null || h.waitStatus < 0 ||
• (h = head) == null || h.waitStatus < 0) {
• Node s = node.next;
• if (s == null || s.isShared())
• doReleaseShared();
• }
• }
首先会设置头节点,然后进行一系列的判断,获取节点的获取节点的后继,以共享模式进行释放,就会调用 doReleaseShared 方法,我们再来看一下 doReleaseShared 方法
private void doReleaseShared() {/** Ensure that a release propagates, even if there are other* in-progress acquires/releases. This proceeds in the usual* way of trying to unparkSuccessor of head if it needs* signal. But if it does not, status is set to PROPAGATE to* ensure that upon release, propagation continues.* Additionally, we must loop in case a new node is added* while we are doing this. Also, unlike other uses of* unparkSuccessor, we need to know if CAS to reset status* fails, if so rechecking.*/for (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;if (ws == Node.SIGNAL) {if (!h.compareAndSetWaitStatus(Node.SIGNAL, 0))continue; // loop to recheck casesunparkSuccessor(h);}else if (ws == 0 &&!h.compareAndSetWaitStatus(0, Node.PROPAGATE))continue; // loop on failed CAS}if (h == head) // loop if head changedbreak;}
}
这个方法会以无限循环的方式首先判断头节点是否等于尾节点,如果头节点等于尾节点的话,就会直接退出。如果头节点不等于尾节点,会判断状态是否为 SIGNAL,不是的话就继续循环 compareAndSetWaitStatus,然后断开后继节点。如果状态不是 SIGNAL,也会调用 compareAndSetWaitStatus 设置状态为 PROPAGATE,状态为 0 并且不成功,就会继续循环。
也就是说 setHeadAndPropagate 就是设置头节点并且释放后继节点的一系列过程。
- 我们来看下面的 if 判断,也就是 shouldParkAfterFailedAcquire(p, node) 这里
if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())throw new InterruptedException();
如果上面 Node p = node.predecessor() 获取前驱节点不是头节点,就会进行 park 断开操作,判断此时是否能够断开,判断的标准如下
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws = pred.waitStatus;if (ws == Node.SIGNAL)return true;if (ws > 0) {do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else {compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false;
}
这个方法会判断 Node p 的前驱节点的结点状态(waitStatus),节点状态一共有五种,分别是
- CANCELLED(1):表示当前结点已取消调度。当超时或被中断(响应中断的情况下),会触发变更为此状态,进入该状态后的结点将不会再变化。
- SIGNAL(-1):表示后继结点在等待当前结点唤醒。后继结点入队时,会将前继结点的状态更新为 SIGNAL。
- CONDITION(-2):表示结点等待在 Condition 上,当其他线程调用了 Condition 的 signal() 方法后,CONDITION状态的结点将从等待队列转移到同步队列中,等待获取同步锁。
- PROPAGATE(-3):共享模式下,前继结点不仅会唤醒其后继结点,同时也可能会唤醒后继的后继结点。
- 0:新结点入队时的默认状态。
如果前驱节点是 SIGNAL 就会返回 true 表示可以断开,如果前驱节点的状态大于 0 (此时为什么不用 ws == Node.CANCELLED ) 呢?因为 ws 大于 0 的条件只有 CANCELLED 状态了。然后就是一系列的查找遍历操作直到前驱节点的 waitStatus > 0。如果 ws <= 0 ,而且还不是 SIGNAL 状态的话,就会使用 CAS 替换前驱节点的 ws 为 SIGNAL 状态。
如果检查判断是中断状态的话,就会返回 false。
private final boolean parkAndCheckInterrupt() {LockSupport.park(this);return Thread.interrupted();
}
这个方法使用 LockSupport.park 断开连接,然后返回线程是否中断的标志。
- cancelAcquire() 用于取消等待队列,如果等待过程中没有成功获取资源(如timeout,或者可中断的情况下被中断了),那么取消结点在队列中的等待。
private void cancelAcquire(Node node) {if (node == null)return;node.thread = null;Node pred = node.prev;while (pred.waitStatus > 0)node.prev = pred = pred.prev;Node predNext = pred.next;node.waitStatus = Node.CANCELLED;if (node == tail && compareAndSetTail(node, pred)) {compareAndSetNext(pred, predNext, null);} else {int ws;if (pred != head &&((ws = pred.waitStatus) == Node.SIGNAL ||(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&pred.thread != null) {Node next = node.next;if (next != null && next.waitStatus <= 0)compareAndSetNext(pred, predNext, next);} else {unparkSuccessor(node);}node.next = node; // help GC}
}
所以,对 CountDownLatch 的 await 调用大致会有如下的调用过程。
一个和await重载的方法是await(long timeout, TimeUnit unit),这个方法和await最主要的区别就是这个方法能够可以等待计数器一段时间再执行后续操作。
countDown方法
countDown是和await同等重要的方法,countDown用于减少计数器的数量,如果计数减为0的话,就会释放所有的线程。
/*** Decrements the count of the latch, releasing all waiting threads if* the count reaches zero.** <p>If the current count is greater than zero then it is decremented.* If the new count is zero then all waiting threads are re-enabled for* thread scheduling purposes.** <p>If the current count equals zero then nothing happens.*/
public void countDown() {sync.releaseShared(1);
}
这个方法会调用 releaseShared 方法,此方法用于共享模式下的释放操作,首先会判断是否能够进行释放,判断的方法就是 CountDownLatch 内部类 Sync 的 tryReleaseShared 方法
/*** Releases in shared mode. Implemented by unblocking one or more* threads if {@link #tryReleaseShared} returns true.** @param arg the release argument. This value is conveyed to* {@link #tryReleaseShared} but is otherwise uninterpreted* and can represent anything you like.* @return the value returned from {@link #tryReleaseShared}*/
public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;
}
// ---- CountDownLatch ----protected boolean tryReleaseShared(int releases) {// Decrement count; signal when transition to zerofor (;;) {int c = getState();if (c == 0)return false;int nextc = c-1;if (compareAndSetState(c, nextc))return nextc == 0;}}
}
tryReleaseShared 会进行 for 循环判断线程状态值,使用 CAS 不断尝试进行替换。
如果能够释放,就会调用 doReleaseShared 方法
/*** Release action for shared mode -- signals successor and ensures* propagation. (Note: For exclusive mode, release just amounts* to calling unparkSuccessor of head if it needs signal.)*/
private void doReleaseShared() {/** Ensure that a release propagates, even if there are other* in-progress acquires/releases. This proceeds in the usual* way of trying to unparkSuccessor of head if it needs* signal. But if it does not, status is set to PROPAGATE to* ensure that upon release, propagation continues.* Additionally, we must loop in case a new node is added* while we are doing this. Also, unlike other uses of* unparkSuccessor, we need to know if CAS to reset status* fails, if so rechecking.*/for (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;if (ws == Node.SIGNAL) {if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue; // loop to recheck casesunparkSuccessor(h);}else if (ws == 0 &&!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue; // loop on failed CAS}if (h == head) // loop if head changedbreak;}
}
可以看到,doReleaseShared其实也是一个无限循环不断使用CAS尝试替换的操作。
总结
本文是 CountDownLatch的基本使用和源码分析,CountDownLatch就是一个基于 AQS 的计数器,它内部的方法都是围绕 AQS 框架来谈的,除此之外还有其他比如 ReentrantLock、Semaphore 等都是 AQS 的实现,所以要研究并发的话,离不开对 AQS 的探讨。CountDownLatch 的源码看起来很少,比较简单,但是其内部比如await方法的调用链路却很长,也值得花费时间深入研究。
cyclicBarrier

加法计数器
public class CyclicBarrierTest {public static void main(String[] args) {/*** 集齐77个龙珠召唤神龙,召唤龙珠的线程*/ CyclicBarrier cyclicBarrier = new CyclicBarrier(7, ()->{System.out.println("召唤神龙成功! ");});for (int i = 0; i < 7; i++) {int temp = i;//lambda 能拿到i吗new Thread(()->{System.out.println(Thread.currentThread().getName() + "收集" + temp + "个龙珠");try {cyclicBarrier.await();} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();}}).start();}}
}
运行结果:

Semaphore
public class SemaphoreTest {public static void main(String[] args) {Semaphore semaphore = new Semaphore(3);for (int i = 0; i < 6; i++) {int temp = i;new Thread(()->{try {semaphore.acquire(); //获取System.out.println(temp + "号车抢到车位");TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();} finally {semaphore.release(); //释放System.out.println(temp + "号车离开车位");}}).start();}}
}
运行结果:

原理:
semaphore.acquire(); //获取信号量,假设如果已经满了,等待信号量可用时被唤醒
semaphore.release(); //释放信号量
作用: 多个共享资源互斥的使用!并发限流,控制最大的线程数
新增线程创建方式
新增方式一:实现Callable接口
Java 5.0 在java.util.concurrent 提供了一个新的创建执行线程的方式:Callable 接口。
Callable 接口类似于Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是Runnable不会返回结果,并且无法抛出经过检查的异常
创建执行线程的方式三:实现Callable接口。相较于实现Runnable接口的方式,方法可以有返回值,并且可以抛出异常。执行Callable方式,需要FutureTask实现类的支持,用于接收运算结果。FutureTask是Future接口的实现类。Callable 需要依赖FutureTask ,FutureTask 也可以用作闭锁。
Future接口
可以对具体Runnable、Callable任务的执行结果进行取消、查询是否完成、获取结果等。
FutrueTask是Futrue接口的唯一的实现类。FutureTask 同时实现了Runnable, Future接口。它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值

可以有返回值。可以抛出异常。方法不同, run() => call()

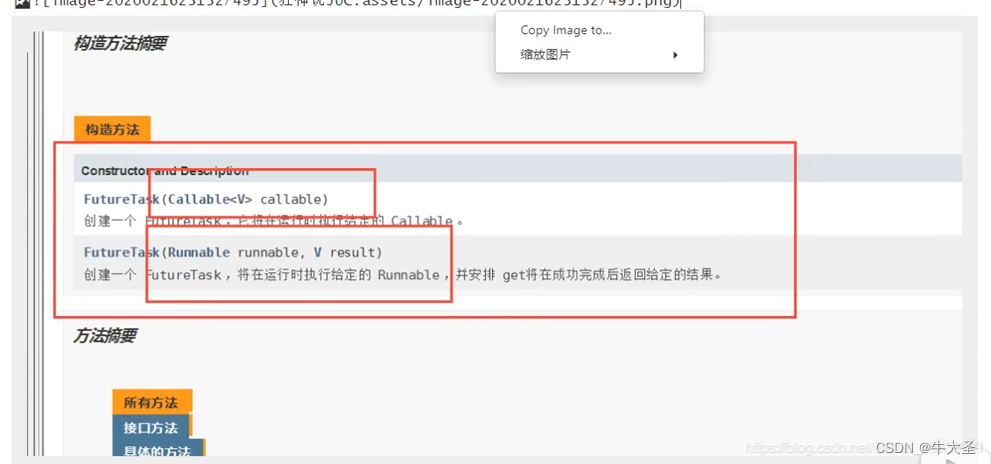
public class CallableTest {public static void main(String[] args) throws ExecutionException, InterruptedException {FutureTask<Integer> futureTask = new FutureTask<>(new MyThread());new Thread(futureTask,"a").start();System.out.println(futureTask.get());}
}
class MyThread implements Callable<Integer> {@Overridepublic Integer call() throws Exception {System.out.println("call()方法被调用了");return 1024;}
}
新增方式二:使用线程池
线程池可以解决两个不同问题:由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。
背景:经常创建和销毁、使用量特别大的资源,比如并发情况下的线程,对性能影响很大。
思路:提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。类似生活中的公共交通工具。
好处:
- 提高响应速度(减少了创建新线程的时间)。
- 降低资源消耗(重复利用线程池中线程,不需要每次都创建)。
- 便于线程管理。
- corePoolSize:核心池的大小。
- maximumPoolSize:最大线程数。
- keepAliveTime:线程没有任务时最多保持多长时间后会终止。
JDK 5.0起提供了线程池相关API:ExecutorService和ExecutorsExecutorService:真正的线程池接口。常见子类ThreadPoolExecutorvoid execute(Runnable command) :执行任务/命令,没有返回值,一般用来执行Runnable<T> Future<T> submit(Callable<T> task):执行任务,有返回值,一般又来执行Callablevoid shutdown() :关闭连接池
为了便于跨大量上下文使用,此类提供了很多可调整的参数和扩展钩子(hook)。但是,强烈建议程序员使用较为方便的Executors 工厂方法:Executors:工具类、线程池的工厂类,用于创建并返回不同类型的线程池Executors.newCachedThreadPool():创建一个可根据需要创建新线程的线程池(无界线程池,可以进行自动线程回收)Executors.newFixedThreadPool(n); 创建一个可重用固定线程数的线程池Executors.newSingleThreadExecutor() :创建一个只有一个线程的线程池Executors.newScheduledThreadPool(n):创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
它们均为大多数使用场景预定义了设置。(4)线程组
/*** @author 牛晨洋* 线程组:把多个线程组合到一起* 他可以对一批线程进行分类管理,java允许程序对线程组进行控制*/
public class ThreadGroupDemo {public static void main(String[] args) {method1();// 我们如何修改线程所在的组?// 创建一个线程组的时候,把其他线程的组指定为我们自己新建的线程组// method2();// t1.start();// t2.start();}private static void method1() {MyRunnable my = new MyRunnable();Thread t1 = new Thread(my, "张三");Thread t2 = new Thread(my, "李四");// 我不知道他们属于哪个线程组,但是想知道// 线程中的方法:public final ThreadGroup getThreadGroup()ThreadGroup tg1 = t1.getThreadGroup();ThreadGroup tg2 = t2.getThreadGroup();// 线程组里面的方法: public final string getName()String name1 = tg1.getName();String name2 = tg2.getName();t1.start();t2.start();System.out.println(name1);System.out.println(name2);// 通过测试我们知道:线程默认是属于main线程组// 通过测试,默认情况下,所有线程都属于一个组System.out.println(Thread.currentThread().getThreadGroup().getName());}private static void method2() {// ThreadGrop(String name);ThreadGroup tg = new ThreadGroup("这是一个新的组");MyRunnable my = new MyRunnable();// Thread(ThreadGrop group, Runnable target, String name)Thread t1 = new Thread(tg, my, "张三");Thread t2 = new Thread(tg, my, "李四");t1.start();t2.start();System.out.println(t1.getThreadGroup().getName());System.out.println(t2.getThreadGroup().getName());// 通过组名设置后台线程,标识该组的线程都是后台线程tg.setDaemon(true);}
}class MyRunnable implements Runnable {public void run() {for (int i = 0; i < 10; i++) {System.out.println(Thread.currentThread().getName() + ":" + i);}}
}
(5)线程池
/*** 线程池的好处线程池里的每一个线程代码结束后,并不会死亡,而是再次回到线程池中成为空闲状态,等待下一个对象来使用* 如何实现线程的代码:* A 创建一个线程池对象,控制要创建的几个线程对象。* public static ExectorService new FixedThreadpool (int nThreads);* B 这种线程池的线程可以执行:* 可以执行Runnable对象或者Callable对象代表的线程* 做一个实现Runnable的接口* C 调用方法如下:* Future<?> submit (Runnable task)* <T> Future<T> submit (Callable<T> task)* D 可以结束:**/
public class ThreadGroupDemo {public static void main(String[] args) {// 创建一个线程池对象,控制要创建的几个线程对象。// public static ExectorService new FixedThreadpool (int nThreads);ExecutorService pool = Executors.newCachedThreadPool();// 可以执行Runnable对象或者Callable 对象代表的线程pool.submit(new MyRunnable());pool.submit(new MyRunnable());// 结束线程池pool.shutdown();}
}class MyRunnable implements Runnable {public void run() {for (int i = 0; i < 10; i++) {System.out.println(Thread.currentThread().getName() + ":" + i);}}
}
(6)多线程实现的第三种方案
案例1:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;/*** 线程池的好处线程池里的每一个线程代码结束后,并不会死亡,而是再次回到线程池中成为空闲状态,等待下一个对象来使用* 如何实现线程的代码:* A 创建一个线程池对象,控制要创建的几个线程对象。* public static ExectorService new FixedThreadpool (int nThreads);* B 这种线程池的线程可以执行:* 可以执行Runnable对象或者Callable对象代表的线程* 做一个实现Runnable的接口* C 调用方法如下:* Future<?> submit (Runnable task)* <T> Future<T> submit (Callable<T> task)* D 可以结束:**/
public class ThreadGroupDemo {public static void main(String[] args) {// 创建一个线程池对象,控制要创建的几个线程对象。// public static ExectorService new FixedThreadpool (int nThreads);ExecutorService pool = Executors.newCachedThreadPool();// 可以执行Runnable对象或者Callable 对象代表的线程Future<Integer> f1 = pool.submit(new MyCallable(100));Future<Integer> f2 = pool.submit(new MyCallable(100));Integer i1 = null;Integer i2 = null;try {i1 = f1.get();i2 = f2.get();} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}System.out.println(i1);System.out.println(i2);// 结束线程池pool.shutdown();}
}
案例2:
/*** 匿名内部类的格式:* new 类名或者接口名(){* 重写方法* }* 本质:是该类或者接口的子类对象。**/
public class ThreadDemo {public static void main(String[] args) {// 继承Thread类来实现多线程new Thread() {@Overridepublic void run() {for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName() + ":" + i);}}}.start();// 实现Runnable接口来实现多线程new Thread(new Runnable() {public void run() {for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName() + ":" + i);}}}).start();// 结合new Thread(new Runnable() {public void run() {for (int i = 0; i < 100; i++) {System.out.println("实现:" + i);}}}) {@Overridepublic void run() {for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName() + ":" + i);}}}.start();}
}
案例3:
定时器:可以让我们在指定的时间做某件事情,还可以重复的做某件事情。
import java.util.Timer;
import java.util.TimerTask;/*** 定时器:可以让我们在指定的时间做某件事情,还可以重复的做某件事情。* 依赖Timer和TimerTask这两个类:* Timer:定时* public Timer()* public void schedule (TimerTask task, long delay)* public void schedule (TimerTask task, long delay, long period)* public void cancel()* TimerTask:任务**/
public class TimerDemo2 {public static void main(String[] args) {// 创建定时器对象Timer timer = new Timer();// 三秒后执行任务,如果不成功,每隔两秒再继续timer.schedule(new MyTask2(), 3000, 2000);}
}
class MyTask2 extends TimerTask {@Overridepublic void run() {System.out.println("beng,爆炸了");}
}
package com.multithreading;import java.io.File;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
在指定的时间删除我们指定的目录
/** 在指定的时间删除我们指定的目录 **/
public class TimerDemo2 {public static void main(String[] args) throws ParseException {// 创建定时器对象Timer timer = new Timer();// 三秒后执行任务,如果不成功,每隔两秒再继续// timer.schedule(new MyTask2(), 3000, 2000);Date date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2018-01-22 16:30:00");timer.schedule(new MyTask2(), date);}
}class MyTask2 extends TimerTask {@Overridepublic void run() {File fileFolder = new File("D:\\360安全浏览器下载\\快剪辑视频");deleteFolder(fileFolder);}// 递归删除目录public void deleteFolder(File fileFolder) {File[] fileArray = fileFolder.listFiles();if (fileArray != null) {for (File files : fileArray) {if (files.isDirectory()) {deleteFolder(files);} else {System.out.println(files.getName() + ":" + files.delete());}}System.out.println(fileFolder.getName() + ":" + fileFolder.delete());}}
}
一些问题
1:多线程有几种实现方案,分别是哪几种?
两种。继承Thread类,实现Runnable接口,扩展一种:实现Callable接口。这个得和线程池结合。
3:启动一个线程是run()还是start()?它们的区别?
start();
run():封装了被线程执行的代码,直接调用仅仅是普通方法的调用
start():启动线程,并由JVM自动调用run()方法
4:sleep()和wait()方法的区别
sleep():必须指时间;不释放锁。
wait():可以不指定时间,也可以指定时间;释放锁。
2:同步有几种方式,分别是什么?
两种。同步代码块,同步方法
5:为什么wait(),notify(),notifyAll()等方法都定义在Object类中
因为这些方法的调用是依赖于锁对象的,而同步代码块的锁对象是任意锁。而Object代码任意的对象,所以,定义在这里面。
JUnit
JUnit是一个Java语言的单元测试框架,逐渐成为xUnit家族中为最成功的一个。
JUnit 是JAVA语言标准测试库,多数Java的开发环境(如:Eclipse)都已经集成了JUnit作为单元测试的工具。
JUnit3的要求:
测试用例需扩展junit.framework.TestCast
测试方法命名规则:test目标方法名(),如:testAdd()
测试方法命名:
JUnit3:测试方法命名规则public void test+目标方法名()
import junit.framework.TestCase;// JUnit3:测试方法命名规则public void test+目标方法名()
public class TestAddOperation extends TestCase {public void setUp() throws Exception {}public void tearDown() throws Exception {}// 测试AddOperation 类的add方法public void testAdd() {// 输入值int x = 3;int y = 5;AddOperation instance = new AddOperation();int expResult = 8;// 预期结果int result = instance.add(x, y);// 获取实际结果// 通过断言判断实际结果和预期结果的差异,前者为预期后者为实际assertEquals(expResult, result);}
}class AddOperation {public int add(int x, int y) {int a = x + y;return a;}
}
JUnit4采用注解实现,需要JDK1.5及以上版本
import org.junit.Test;//JUnit4采用注解实现,需要JDK1.5及以上版本
public class Text00 {@Testpublic void cc() {System.out.println("1111");}@Testpublic void ccc() {System.out.println("1122211");}
}
JUnit4支持多种注解来简化测试类的编写
@BeforeClass 注解:在所有方法执行之前执行。方法是静态的
@Before 注解:与junit3.x中的setUp()方法功能一样,在每个测试方法之前执行。
@Test注解:当前测试方法。
@After 注解:与junit3.x中的tearDown()方法功能一样,在每个测试方法之后执行。
@AfterClass 注解:在所有方法执行之后执行。方法是静态的
@Ignore:临时禁止一个测试的方法是通过注释掉它或者改变命名约定,这样测试运行机就无法找到它
JUnit4的单元测试用例执行顺序为:
@BeforeClass -> @Before -> @Test -> @After -> @AfterClass; 。
每一个测试方法的调用顺序为:
@Before -> @Test -> @After;
断言:
表示程序运行的真实结果与所以期望的结果是否一致。
assertXxx()方法,Xxx表示相应的断言方法,如assertEquals()、assertTrue()等。
import static org.junit.Assert.assertEquals;
import org.junit.After;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Ignore;
import org.junit.Test;public class AAAA {@Ignore// @Ignore放在所有Text上只能输出@BeforeClass和AfterClass下的语句@Testpublic void cc1() {System.out.println("@Test02");}@Testpublic void cc6() {int a = 5;assertEquals(5, a);System.out.println("@Test01");}@Testpublic void cc7() {int b = 6;assertEquals(6, b);System.out.println("@Test03");}@Afterpublic void cc2() {System.out.println("@After");}@Beforepublic void cc3() {System.out.println("@Before");}@BeforeClasspublic static void cc4() {System.out.println("@BeforeClass");}@AfterClasspublic static void cc5() {System.out.println("@AfterClass");}
}
JUnit4拓展
参数化测试:可一次性为目标方法提供多组输入数据和预期结果来提高测试的效率。
import static org.junit.Assert.assertEquals;import org.junit.After;
import org.junit.Before;
import org.junit.Test;public class TestCalculator {int i = 1;Calculator calc = new Calculator();@Beforepublic void setUp() throws Exception {System.out.println("测试前初始值置零! " + i);calc.clear();}@Afterpublic void tearDown() throws Exception {System.out.println("测试后......" + calc.getResult());}@Test // 加法public void add() {calc.add(2);calc.add(3);int result = calc.getResult();assertEquals(5, result);}@Test // 减法public void subtract() {calc.add(10);calc.subtract(2);int result = calc.getResult();assertEquals(8, result);}@Test // 除法public void divide() {calc.add(8);calc.divide(2);assert calc.getResult() == 4;}@Test(expected = ArithmeticException.class)public void divideByZero() {calc.divide(0);}// 乘法
// @Ignore("not Ready Yet Test Multiply")@Testpublic void multiply() {calc.add(10);calc.multiply(10);int result = calc.getResult();assertEquals(100, result);}
}public class Calculator{//存数运算结果的静态变量private static int result;//加法public void add(int n){result = result + n;}//减法,public void subtract(int n){result = result - n;}//乘法,此方法尚未实现public void multiply(int n){result = result * n;}//除法public void divide(int n){result = result / n;}public void clear() {result=0;}public int getResult() {return result;}public void square(int param) {result=param;}}
测试集:提供将多个单元测试类组合成一测试集的能力。
import org.junit.runner.RunWith;
import org.junit.runners.Suite;@RunWith(Suite.class)
@Suite.SuiteClasses({TestCalculator.class,TestSquare.class,Text00.class})
public class TestAllCalculator{}