前言:在现实中我们经常会碰到问题的数据量特别大的情况,无法将所有数据都加载到内存里面,这个时候,更不要说对数据进行处理了,该怎么办呢?
目录
目录
一,位图
拓展1:如果是要我们找出现过两次及两次以上的整形呢?
拓展2:
拓展3:在100G的内存里面找到出现频率最高的字符串。
二,布隆过滤器
1)无限增加位图的大小
2)好的哈希函数
3)布隆过滤器
一,位图
情景假设:现在文件A里面有100G的int类型的有符号整数,我们可以使用的内存只有1G,如何快速的判断某一个整数在不在文件A里面。
因为可使用的内存只有1G,我们可以把100G的内容分批读进内存,这样子就不会导致内存不够了,但是我们该如何保存读到的数据呢?这是一个问题,如果依旧按照原方式存储的话,我们是需要100G的,我们再仔细审题,只需要判断数据在不在就可以了,并且需要把内存压缩空间到极致的话,我们知道内存的最小单位是比特位,比特位刚好有0和1两种状态,这两种状态完全可以代表是否存在,同时每一个比特位代表一个整形(位图)。但是我们需要多少位比特位呢?这取决于有符号整形有多少种组合,答案是2^32种可能。2^32个比特位等于0.5GB(512Mb),也就是说只要512大小的内存我们就可以存储100G里面所有整形的状态。剩下来的内存便可以用来将数据分批读进内存,进行标记比特位。当我们需要进行查询的时候就可以通过相应比特位的状态来判断是否存在。
拓展1:如果是要我们找出现过两次及两次以上的整形呢?
我们的思维要打开,既然一个比特位不够用了,我们不妨多开上几个比特位,通过01,10,11,10等组合不就可以表达出现的次数了,当然这种方法有局限性,如果让我们统计所有次数的话,估计内存消耗会越来越大,因为一个数甚至可能出现超过整形的表达范围,空间消耗自然就大了。
拓展2:字符串等非整形
在实际情况里面,我们可能更多的使用场景是字符串等其他的,我们该怎么处理呢?大家应该学过哈希表吧,哈希表里面有一种思想,自己写一个哈希函数来将所有的非整形家族转化为整形,从而进行映射。大家如果对这个很感兴趣,可以看我的往期博客里面的常用哈希函数,举个例子:字符串都有ascll码值,这个不就是整形吗?我们进行各种处理就行了。
http://t.csdnimg.cn/xXd5W
拓展3:在100G的内存里面找到出现频率最高的字符串。
解决思路:首先利用哈希函数将100G分为200块,这时候必然切分的大小有不同的,有的可能是4,5G,有的可能只有100Mb,这时候有两种可能(全是相同的字符,或者哈希函数并没有切分好,有很多类似的字符串切分在一起了)。我们先不急,仍然按照顺序处理,我们使用map来统计字符串的数目,如果内存超过了500MB,我们就停止继续统计,这时候已经够说明了,这个字符串里面必然有很多不同的类似字符,因为如果全是相同的字符串,只会++map里面的次数统计。我们换一个哈希函数切分,反正不管是什么哈希函数相同的字符串总会被切分到一个块里面,然后继续统计,如果还是大了,就继续切分,直至统计完成。每统计完一个我就将最大的保留下来和上一个或者下一个进行对比,只保留出现次数最多的字符串然后返回即可。
如果找出现次数前十多等类似topK问题也是这种方法解决。
二,布隆过滤器
上面的拓展2提到了哈希函数转化,但是既然是哈希函数转化不可避免的就会产生冲突,我们该怎么在尽量减少内存消耗的前提下包装正确率呢?既然需要减少内存消耗,我们就应该选择位图,不能选择哈希桶或者线性探测法了。那如何保证正确率呢?
1)无限增加位图的大小
这样子虽然说是无限的降低了冲突率,但是空间消耗却大了,因此这并不是最好的办法,我们应该按照数据量的大小来划分空间大小。
2)好的哈希函数
确实有很多大佬提出了各种各样的哈希函数有效降低冲突率,但是除非直接映射冲突还是不可避免。
3)布隆过滤器
上面说了一个好的哈希函数可以降低冲突率,我们能不能多搞几个哈希函数呢?然后一个数在位图中映射好几个位,这几个位分别由不同的哈希函数来映射,只有当这几个位都是1的时候才判断这个元素存在。
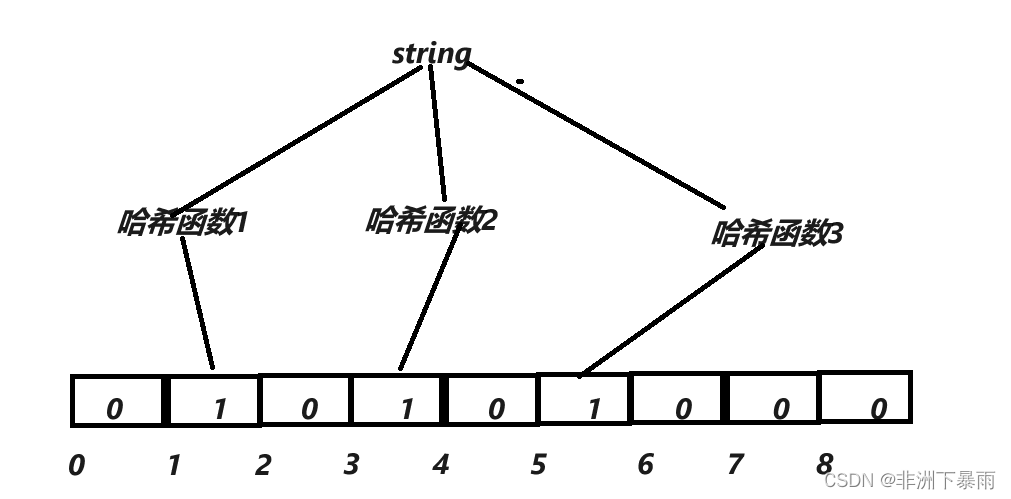
每一个哈希函数的具体实现方法不同,映射位很可能就会不同,这样子哪怕是,string tsring两个的映射方式大概率会不同,自然就不会出现误判了。
但是这种办法只能将原本的冲突率和误判率进一步降低,仍然无法完全避免误判,不过这误判率低了很多,在很多对准确度没那么高要求的场景已经能使用了。
总结:海量数据处理:分批处理+位图等工具


![【源头活水】顶刊解读!IEEE T-PAMI (CCF-A,IF 23.6)2024年46卷第一期 [3]](https://img-blog.csdnimg.cn/img_convert/63f7515172a600914cff18c058e4c9b3.png)