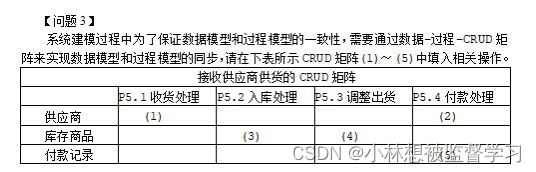
SambaNova——一家总部位于帕洛阿尔托的公司已经筹集了超过10亿美元的风险投资,不会直接向公司出售芯片。相反,它出售其定制技术堆栈的访问权限,该堆栈具有专门为运行最大的人工智能模型而设计的专有硬件和软件。
最近,SambaNova宣布推出了其新型SN40L处理器,该处理器拥有1020亿个晶体管,分布在1040个核心上,能够达到638teraflops运算的速度,采用TSMC的5纳米工艺制造,SN40L最引人注目的特点之一是它的三级存储系统,专为处理与AI工作负载相关的大量数据流而设计。SambaNova声称,仅由八个这样的芯片组成的节点就能够支持高达5万亿个参数的模型。这几乎是OpenAI的GPT-4大型语言模型大小的三倍,并且能够处理高达256,000个tokens的序列长度。该公司声称,与需要数百个芯片的行业标准GPU相比,这代表了总拥有成本的显著降低。
可重构数据流架构是SambaNova芯片的核心,它能够根据不同人工智能模型的需求,动态调整芯片内部的数据通路,实现高效的计算和数据流动。下面我们来详细了解一下这种架构的特点和优势。
1.可重构互连:灵活连接计算、存储和通信单元
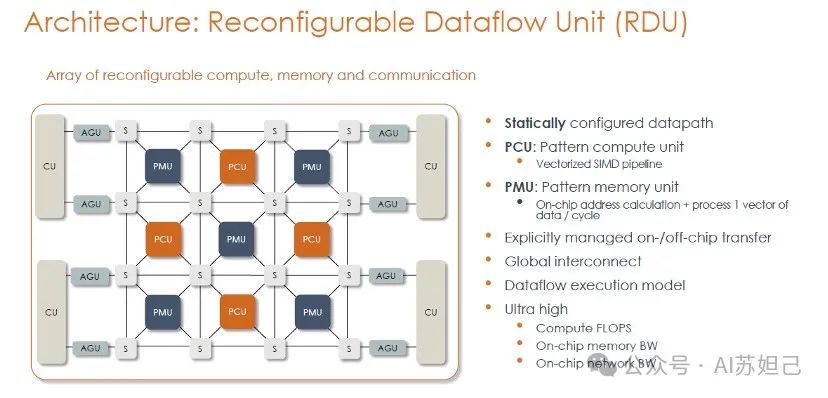
SambaNova芯片包含大量的计算单元(PCU)、存储单元(PMU)和通信交换单元(SCU),它们按阵列平铺排列。计算单元PCU集成了矢量化的单指令多数据(SIMD)流水线,专门用于高效的矩阵/向量计算操作,这是机器学习推理和训练的核心运算。存储单元PMU则是片上SRAM存储器,每个周期可存取一个数据向量,为计算单元流畅输送数据。PMU还集成了地址计算能力,用于高效管理数据访问模式。通信交换单元S负责在整个芯片范围内互连各个单元,构建一个可重配的全局互连网络,支持灵活的数据流传输。除了这些核心单元,图中还标注了控制单元CU和地址生成单元AGU等支持模块。
该架构的关键特点包括:静态配置的数据通路、显式管理芯片内外数据传输、支持数据流执行模型、以及超高的计算能力、存储带宽和网络带宽等。通过可重构互连和数据流执行模型,SambaNova能针对不同的AI模型动态调整硬件资源分配,在单个芯片上构建出高度优化和高效的数据传输通路,最大限度利用硬件能力,实现卓越的AI加速性能。
2.自动探索并确定出一种高度优化的操作映射方案
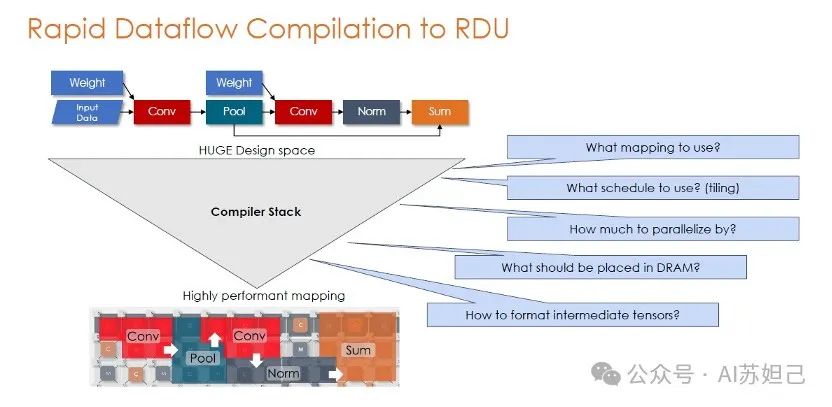
一个典型的深度学习模型由多个操作组成,如卷积(Conv)、池化(Pool)、归一化(Norm)和求和(Sum)等。将这些操作高效映射到RDU芯片上需要解决许多复杂的问题,比如决定最优的操作映射方式、计算并行度、中间数据格式和存储位置等。这构成了一个设计空间极其庞大的组合优化问题。
为了解决这一挑战,SambaNova设计了一个编译器技术栈。编译器需要回答诸如"使用何种映射策略"、"采用何种调度方式"、"并行度是多少"、"中间数据存放在片上还是外部"以及"如何组织中间数据张量格式"等一系列关键问题。
通过分析模型的结构特征,并结合硬件资源的全面考虑,编译器可以自动探索并确定出一种高度优化的操作映射方案。图的下半部分展示了这样一种可能的映射结果,其中不同的操作被高效地排布在RDU的不同单元和互连通路上。
这种快速的数据流编译技术使SambaNova芯片能够针对给定的AI模型,自动生成最优的计算指令和分布式执行策略,充分利用芯片的硬件能力,突破了传统架构的性能瓶颈。该技术与灵活可重构的RDU架构紧密结合,是SambaNova实现卓越加速性能的关键所在。
3.与GPU等传统芯片的对比

英伟达GPU采用的是一种更加传统的架构。GPU由大量的CUDA核心组成,每个CUDA核心包含一些计算单元和有限的寄存器文件。所有CUDA核心通过固定的总线连接到一个共享的大容量但访问延迟更高的GPU内存。这种架构对于一些密集型通用计算是非常高效的,但对于模型越来越复杂、参数越来越多的大规模机器学习任务,就显得数据传输成为了一大瓶颈。
SambaNova的动态可重配置架构可以针对具体的机器学习模型,构建近乎零开销的数据通路,使计算单元和所需数据位于极近的位置。这不仅减少了数据移动开销,还可以最大化芯片资源的利用效率。软件SambaFlow则扮演着对模型进行分析并高效映射到硬件的关键角色。
传统方式下,整个模型需要分解为多个小的 kernel 操作(比如乘法、归一化和 softmax 等),这些操作被逐个发送到 GPU 上执行。GPU 需要重复加载输入数据、执行 kernel、写回结果,并不断在片上存储和外部内存间传输数据,过程中存在大量数据移动开销和内存延迟。
而 SambaNova 芯片的"数据流"方式则将整个模型建模为一个数据流水线,包含乘法(M)、归一化(N)、softmax(S)等操作。通过可重配的互连结构,相关的数据和计算资源被高效组织,模型的各个阶段能够直接在芯片内部流动、计算,消除了大量数据传输和内存访问延迟开销。
4. 灵活性和高性能的完美结合
可重构数据流架构的优势在于,它在提供灵活性的同时,也能够实现高性能的计算。
- 灵活性:通过可重构互连和运行时映射,SambaNova芯片可以灵活适应不同的人工智能模型,不需要为每个模型设计专用的硬件结构。
- 高性能:通过将计算任务映射到最优的硬件资源,并利用数据流图揭示的并行性和局部性,SambaNova芯片可以实现极高的计算效率和性能。
新架构设计的未来展望
可重构数据流架构不仅适用于当前的人工智能模型,也为未来的模型发展提供了充分的支持和灵活性。
- 新的模型结构:通过调整数据流图和映射方式,可重构数据流架构可以快速适应新的模型结构和计算范式。
- 算法创新:可重构数据流架构为算法创新提供了更大的自由度,研究人员可以探索新的计算模式和优化技术。
- 持续演进:随着人工智能技术的不断发展,可重构数据流架构也可以随之演进,通过增加新的计算单元、优化互连拓扑等方式,不断提升性能和效率。
可重构数据流架构代表了人工智能芯片设计的一个重要方向,它通过灵活的硬件结构和智能的编译映射技术,实现了高性能、高效率、高适应性的特点,为人工智能的加速发展提供了强大的动力。