9Proxy数据采集工具Unlock the web with 9Proxy, the top residential proxy provider. Get unlimited bandwidth, affordable prices, and secure HTTPS and Socks5 configurations. https://9proxy.com/?utm_source=blog&utm_medium=csdn&utm_campaign=yan
https://9proxy.com/?utm_source=blog&utm_medium=csdn&utm_campaign=yan
前言
在当今数字化时代,互联网已经成为人们获取信息、开展业务和进行交流的重要平台。然而,随着网络安全和数据隐私的日益重视,网站和网络服务提供商采取了各种手段来保护其资源和用户数据的安全。这其中包括了对爬虫活动的限制和阻碍。
在这样的环境下,使用代理成为了爬虫技术中不可或缺的一部分,它为爬虫提供了重要的匿名性和隐私保护,同时也有助于克服被封禁或限制访问的问题。
今天我们来试用一下数据获取工具:9proxy,看看它能否作为一个稳定的爬虫工具。
为什么我们在获取数据的过程中需要用到数据获取工具
应对反爬虫策略:许多网站会采取反爬虫措施,限制单个IP的访问频率或次数。通过使用数据获取服务,可以轮换多IP来模仿多个用户访问,降低被封禁的风险。 保证稳定性:有些数据获取服务可能存在不稳定的情况,包括IP连接速度慢、IP被找到等问题。通过建立数据获取服务,可以预先准备多个可用的IP地址,确保程序在某个IP不可用时可以快速切换到其他可用IP,提高爬虫程序的稳定性。 提高访问速度:IP池中的多个IP地址可以并发使用,实现多线程或异步请求,从而加快数据获取速度。通过在数据获取服务中保持一定数量的可用IP地址,可以实现更快速的数据抓取。 应对封禁风险:有些网站会根据某些特定的IP地址或IP段进行封禁,如果整个IP池中的IP都被封禁,可以及时更新IP池中的IP地址,避免影响爬虫程序的正常运行。 降低被识别的风险:当爬虫程序使用固定的IP地址进行访问时,容易被网站识别出是爬虫行为。
易用性测试
我们先来9proxy的网站看看。注册、登录后来到主界面,可以看到功能一目了然。
向下翻可以找到客户端下载的按钮
下载、安装完成后自动进入客户端。因为安装包要下载一些组件,安装需要较长的时间。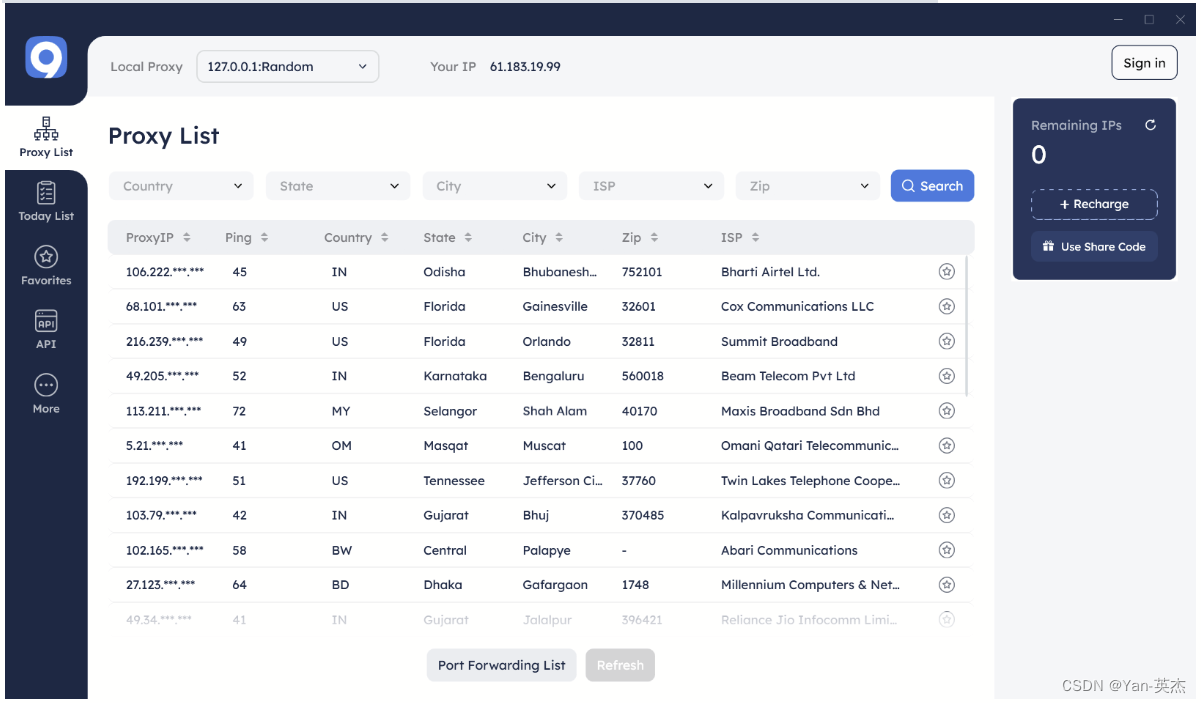
在这里就可以看到我们所有的代理ip,可以看到有不同国家和地区的ip可供使用。切换到API栏目中可以找到代理池的URI,下方有使用的示例。
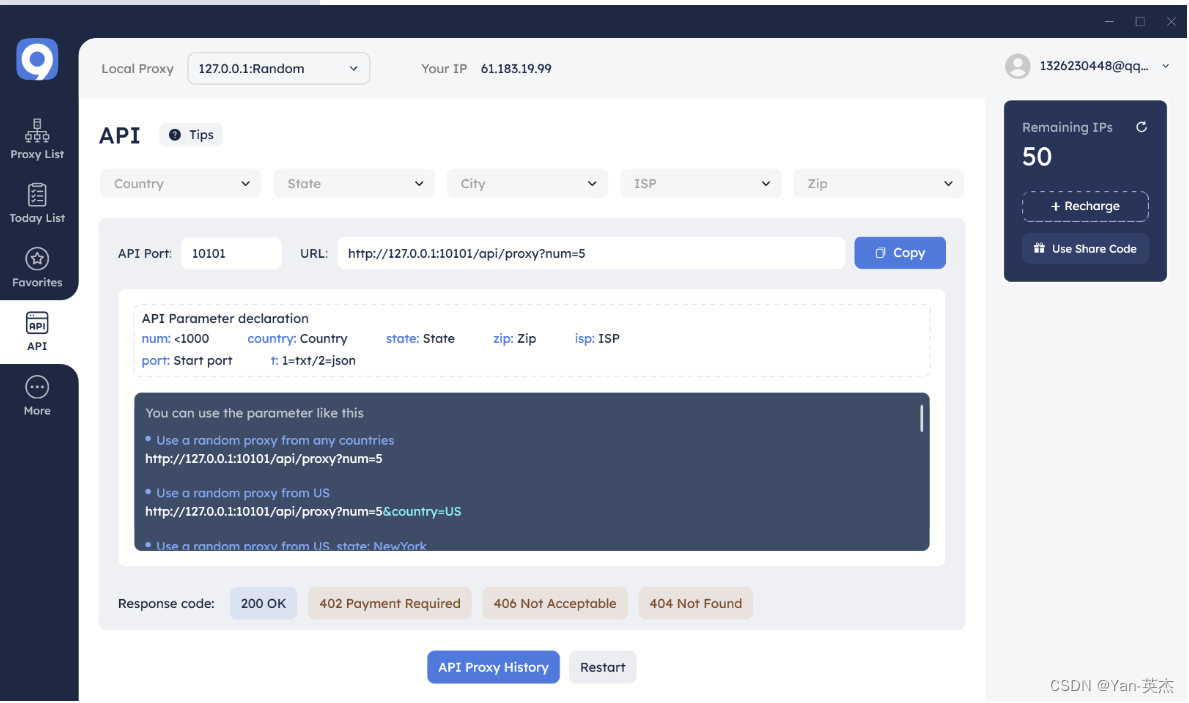
按需求选用对应的即可URI即可连接代理,并通过其发送数据。
性能测试
在大多数情况下,网站会设置一些防爬虫机制,如IP封禁、验证码验证、访问频率限制等,以防止爬虫对其数据和资源的滥用。如果一个IP地址频繁地访问网站,很可能会被网站识别并封禁,导致无法继续访问所需信息。使用代理可以轻松地规避这种封禁,因为代理服务器会提供不同的IP地址,使得爬虫在访问同一网站时具有多个IP地址可供选择,从而减少了被封禁的风险。接下来我们从匿名性的角度来看一下这个代理池的性能。首先准备一个测试爬虫,它向lumtest发送请求,在响应数据中查看我们发出数据包的地区数据。
import requestsproxy_url = "http://127.0.0.1:10101/api/proxy?num=5"
url = "http://lumtest.com/myip.json"
proxies = {'http': proxy_url, 'https': proxy_url}
# proxies = {}
i = 0
while i < 3:
res = requests.get(url, proxies=proxies, timeout=10)print(res.json()['country'])
i += 1
这个爬虫使用了 requests 库来发送HTTP请求,并尝试通过代理服务器访问指定的URL。它首先定义了代理服务器的URL地址 proxy_url,这个地址指向了本地主机(127.0.0.1)的端口号10101上的一个API,该API可能用于获取代理服务器的IP地址和端口号。然后定义了要访问的URL地址 url,该地址是一个用于测试IP地址的网站,它返回了当前请求的IP地址的相关信息,以JSON格式返回。之后定义了一个 proxies 字典,包含了要使用的代理服务器的信息。在这个例子中,proxies 字典中的 'http' 和 'https' 键分别指定了HTTP和HTTPS请求要使用的代理服务器地址,都设置为了 proxy_url。最后使用一个 while 循环,设置循环次数为10次,用来模拟发送10次HTTP请求。在循环内部,使用 requests.get() 方法发送HTTP GET请求,并传入了要访问的URL地址和代理服务器的信息。如果不需要使用代理服务器,可以注释掉 proxies 参数。使用 res.json() 方法解析返回的JSON数据,然后从中提取出 country 键对应的值,表示请求返回的IP地址所在的国家。打印出获取的国家信息。循环变量 i 自增,直到达到3次循环结束。
可以看到可以随机切换ip,保证了匿名性。
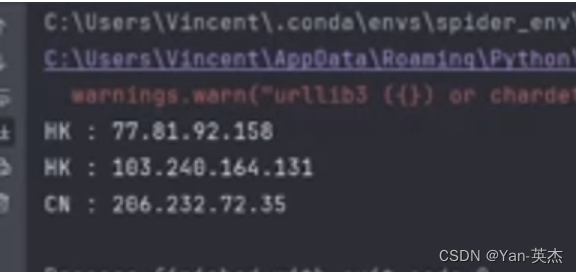
接下来我们尝试在一个真实的爬虫上集成代理池。爬虫如下:
import requests
from bs4 import BeautifulSoup
import pandas as pdproxy_url = "http://127.0.0.1:10101/api/proxy?num=5"
proxies = {'http': proxy_url, 'https': proxy_url}def fetch_data(page_number):
url = f"https://sh.lianjia.com/ershoufang/pg{page_number}/"
response = requests.get(url, proxies=proxies)if response.status_code != 200:print("请求失败")return []
soup = BeautifulSoup(response.text, 'html.parser')
rows = []for house_info in soup.find_all("li", {"class": "clear LOGVIEWDATA LOGCLICKDATA"}):
row = {}
row['区域'] = house_info.find("div", {"class": "positionInfo"}).get_text() if house_info.find("div", {"class": "positionInfo"}) else None
row['房型'] = house_info.find("div", {"class": "houseInfo"}).get_text() if house_info.find("div", {"class": "houseInfo"}) else None
row['关注'] = house_info.find("div", {"class": "followInfo"}).get_text() if house_info.find("div", {"class": "followInfo"}) else None
row['单价'] = house_info.find("div", {"class": "unitPrice"}).get_text() if house_info.find("div", {"class": "unitPrice"}) else None
row['总价'] = house_info.find("div", {"class": "priceInfo"}).get_text() if house_info.find("div", {"class": "priceInfo"}) else None
rows.append(row)return rows# 主函数
def main():
all_data = []for i in range(1, 11): # 爬取前10页数据作为示例print(f"正在爬取第{i}页...")
all_data += fetch_data(i)
df = pd.DataFrame(all_data)
df.to_excel('lianjia_data.xlsx', index=False)print("数据已保存到 'lianjia_data.xlsx'")if __name__ == "__main__":
main()这个爬虫可以爬取链家网上海二手房页面的房屋信息,并将数据保存到 Excel 文件中。爬虫首先定义了一个名为 proxy_url 的变量,指定了代理服务器的地址。然后创建了一个名为 proxies 的字典,其中包含了代理服务器的信息,这将在后续的请求中使用。之后定义了一个名为 fetch_data(page_number) 的函数,用于爬取指定页数的链家网上海地区二手房信息。在 fetch_data 函数中,构造了要访问的目标URL,然后使用 requests.get() 方法发送HTTP GET请求,传入了代理服务器的信息,并解析返回的HTML内容。然后通过 BeautifulSoup 库解析HTML,提取了房屋信息中的区域、房型、关注、单价和总价等数据,并存储到一个列表中。在主函数 main() 中循环调用 fetch_data() 函数,爬取了前10页的房屋信息,并将结果存储到名为 all_data 的列表中。使用 pandas 库将 all_data 列表中的数据转换为DataFrame,并调用 to_excel() 方法将数据保存到 Excel 文件中。最后,通过 if 条件语句来判断是否作为主程序运行,如果是,则调用 main() 函数。运行一下可以看到结果如下:
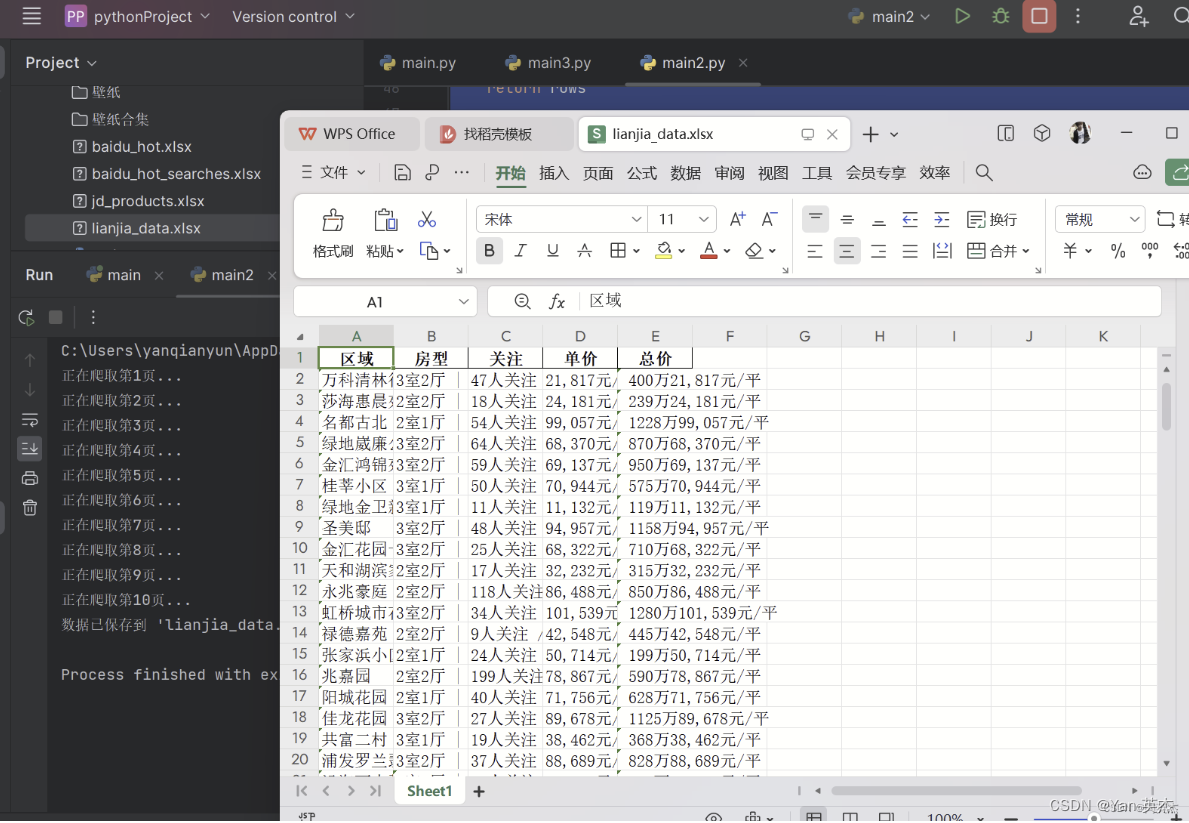
为什么推荐9proxy数据获取工具
- 价格实惠且质量优越,从每个IP开始仅需$0.04。
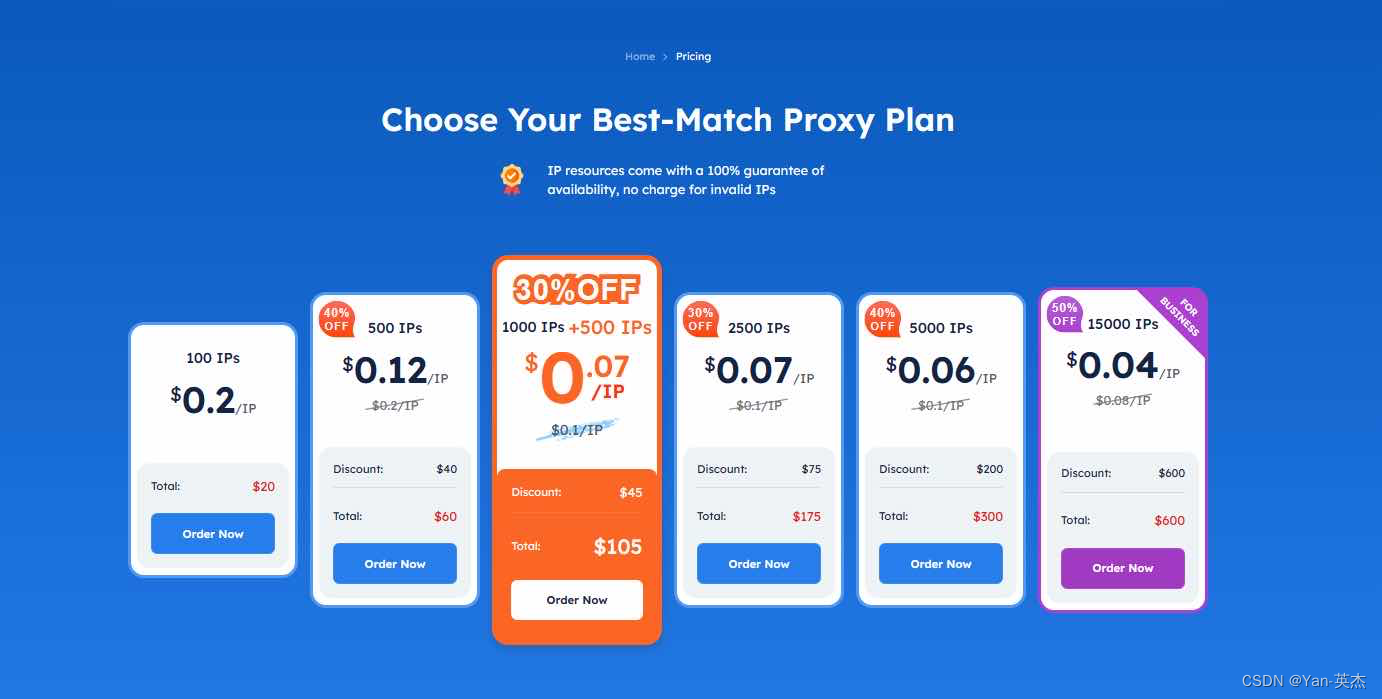
- 无限带宽:与大多数竞争对手按照1GB、2GB等套餐销售不同,按照独立IP出售。对于每个IP,客户可以无限制地下载、上传,数据量不受限制。这样做有很多优点:
帮助客户轻松管理成本。
适用于消耗大量数据的任务。
- 清洁的代理池,与其他方面不共享资源:尽管9Proxy仅提供9M+的代理,听起来似乎不太惊人,但9proxy数据获取工具是清洁的且独特的,无拉黑风险。。
- 数据获取退还政策:数据获取的生命周期不是固定的,有些数据获取可能能活超过24小时,但也有些数据获取很快就会失效。因此,为了保护用户,9Proxy有一个几乎没有其他公司有的数据获取退还政策。在60秒内,如果数据获取失效,客户可以访问“今日列表”来检查并且可以将新的数据获取退还到他们的账户。
- Today List功能:这个功能帮助客户节省费用的另一个方式是在24小时内重新使用已使用的代理。每个人都可以查看“Today List”以查看有哪些数据获取在线,如果有的话,你可以免费使用而不会增加额外的费用。
- 支持SOCKS5/HTTP/HTTPS:增强安全性,提高性能,使连接更快速、可靠。
- 免费试用套餐:9Proxy在特定时间提供免费试用套餐。要体验9Proxy,可直接在主页上发送消息以获取有关这些免费试用套餐的最新信息。
可以看到任务顺利完成。总的来说,代理不仅能够帮助爬虫规避网站的封禁和限制,提供更高的匿名性和隐私保护,还可以帮助爬虫实现地理位置伪装,获取更多有用的数据。因此,在开发和运行爬虫程序时,合理地配置和使用代理是至关重要的一环。朋友们觉得9proxy这款代理如何呢?另外,9proxy目前还有一个计划,为从未使用过9proxy的新用户赠送20个免费代理,如果您有兴趣,请直接联系9proxy,他们会为您的所有问题提供支持和建议。