目录
链接静态库
动态链接
与地址无关的代码
全局偏移表
延迟绑定
共享库
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 嵌入式智能产品开发实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
链接静态库
在一个软件项目中,为了完成特定功能,除了自定义函数,我们还可以使用别人已经封装好的函数库,如C标准库、音视频编解码库等。库函数的使用避免了“造轮子”的重复工作,提高了代码复用率,大大减轻了软件开发的工作量。
库分为静态库和动态库两种。如果我们在项目中引用了库函数,则在编译时,链接器会将我们引用的函数代码或变量,链接到可执行文件里,和可执行程序组装在一起,这种库被称为静态库,即在编译阶段链接的库。动态库在编译阶段不参与链接,不会和可执行文件组装在一起,而是在程序运行时才被加载到内存参与链接,因此又叫作动态链接库。
静态库的本质其实就是可重定位目标文件的归档文件。静态库的制作和使用都很简单,使用AR命令就可以将多个目标文件打包为一个静态库。
以下演绎为了方便起见,我写完代码之后统一采用gcc工具构建,未来针对不同平台的ARM会有不同的工具配置。
我们看下面的程序:
先在ARM-Linux系统中touch 出一个文件(test.c),并使用vim工具进行编辑如下:
// test.cint add (int a, int b)
{return a + b;
}int sub (int a, int b)
{return a - b;
}int mul (int a, int b)
{return a * b;
}int div (int a, int b)
{return a / b;
}再touch出一个main.c文件,代码如下:
// main.c#include <stdio.h>int add(int, int);int main(void)
{int sum = 0;sum = add(1, 2);printf("sum= %d\n", sum);return 0;
}静态库的本质其实就是可重定位目标文件的归档文件。静态库的制作和使用都很简单,使用AR命令就可以将多个目标文件打包为一个静态库。
# gcc -c test.c
# ar rcs libtest.a test.o
# gcc main.c -L. -ltest
# ./a.out
sum = 3
首先,我们将源文件test.c编译生成对应的目标文件test.o,然后使用ar命令将多个目标文件打包成libtest.a,最后在编译main.c时,通过参数指定要链接的静态库及其所在路径就可以了。
编译参数大写的L表示要链接的库的路径,小写的l表示要链接的库名字。链接时库的名字要去掉前后缀,如libtest.a,链接时要指定的库名字为test。
使用ar命令制作静态库时,一些常用的参数介绍如下:
● -c:禁止在创建库时产生的正常消息。
● -r:如果指定的文件已经在库中存在,则替换它。
● -s:无论库是否更新都强制重新生成新的符号表。
● -d:从库中删除指定的文件。
● -o:对压缩文档成员进行排序。
● -q:向库中追加指定文件。
● -t:打印库中的目标文件。
● -x:解压库中的目标文件。
编译器是以源文件为单位编译程序的,链接器在链接过程中逐个对目标文件进行分解组装,这样很容易产生一个问题:如果在一个源文件中我们定义了100个函数,而只使用了其中的1个,那么链接器在链接时也会把这100个函数的代码指令全部组装到可执行文件中,这会让最终生成的可执行文件体积大大增加。
使用readelf命令查看a.out你会发现,虽然我们在main()函数中只调用了add()函数,但是在a.out文件中除了add()函数,sub()、mul()、div()等函数也都链接了进来,这可如何是好呢?
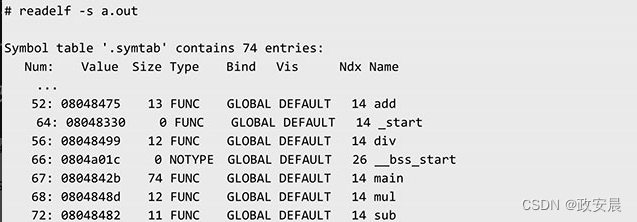
解决这个问题其实很简单:我们在封装函数库时,将每个函数都单独使用一个源文件实现,然后将多个目标文件打包即可。
// add.c
int add(int a, int b)
{return a + b;
}// sub.c
int sub(int a, int b)
{return a - b;
}//mul.c
int mul(int a, int b)
{return a * b;
}//div.c
int div(int a, int b)
{return a / b;
}//main.c#include <stdio.h>
int add(int, int);int main(void)
{int sum;sum = add(1, 2);printf("sum = %d\n", sum);return 0;
}我们将上面的源文件分别编译,打包生成静态库,再去调用库中的add()函数,你会发现,sub()、mul()、div()等函数就不会再链接到可执行文件中了。

C标准库其实就是这么干的:在glibc源码中,你会看到,每一个库函数都是单独使用一个同名的源文件实现的。printf()函数单独定义在printf.c文件中,scanf()函数单独定义在scanf.c文件中,如果你调用了一个printf()函数,则链接器只是将printf()函数的目标文件链接到你的可执行文件中。
通过这种打包形式,可执行文件的体积被大大减少了。
静态链接还会产生另外一个问题。如C标准库里的printf()函数,可能多个程序都调用了它,链接器在链接时就要将printf的指令添加到多个可执行文件中。
在一个多任务环境中,当多个进程并发运行时,你会发现内存中有大量重复的printf指令代码,很浪费内存资源。那么有没有解决的办法呢?肯定是有的,动态链接这时候就开始低调登场了。
动态链接
我们都看到了静态链接的缺点:生成的可执行文件体积较大,当多个程序引用相同的公共代码时,这些公共代码会多次加载到内存,浪费内存资源。尤其对于一些内存配置较低的嵌入式系统,当过多的进程并发运行时,系统就可能因为内存爆满而无法流畅运行。
为了解决这个问题,动态链接对静态链接做了一些优化:对一些公用的代码,如库,在链接期间暂不链接,而是推迟到程序运行时再进行链接。这些在程序运行时才参与链接的库被称为动态链接库。程序运行时,除了可执行文件,这些动态链接库也要跟着一起加载到内存,参与链接和重定位过程,否则程序可能就会报未定义错误,无法运行。
动态链接的好处是节省了内存资源:加载到内存的动态链接库可以被多个运行的程序共享,使用动态链接可以运行更大的程序、更多的程序,升级也更加简单方便。现在主流的软件一般都喜欢采用这种开发方式。在Windows下解压一个软件安装包,你会发现里面有很多.dll后缀的文件,这些文件其实就是动态链接库,需要和可执行文件一起安装到系统中。程序运行前会首先把它们加载到内存,链接成功后程序才能运行。
在Linux环境下也是如此,只不过动态库的文件变成了以.so为后缀。一个软件采用动态链接,版本升级时主程序的业务逻辑或框架不需要改变,只需要更新对应的.dll或.so文件就可以了,简单方便,也避免了用户重复安装卸载软件。以上面的main.c、add.c、sub.c、mul.c、div.c程序为例,我们可以将add.c、sub.c、mul.c、div.c封装成动态库libtest.so,然后在程序运行时动态加载到内存。
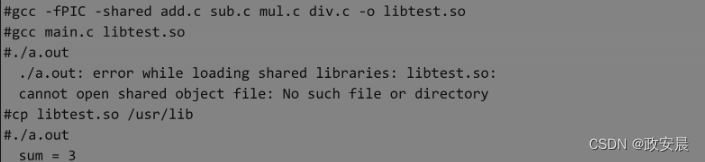
在上面的程序中,可执行文件a.out是采用动态链接生成的,所以在运行a.out之前,libtest.so这个动态链接库要放到/lib、/usr/lib等系统默认的库路径下,否则a.out就会动态链接失败,无法正常运行。
在Linux环境下,当我们运行一个程序时,操作系统首先会给程序fork一个子进程,接着动态链接器被加载到内存,操作系统将控制权交给动态链接器,让动态链接器完成动态库的加载和重定位操作,最后跳转到要运行的程序。
动态链接器在C标准库中实现,是glibc的一部分,主要完成程序运行前的动态链接工作,在可执行文件的.interp段中存放的有动态链接器的加载路径,我们可以通过objdump命令查看。

通过上面的信息可以看到,动态链接器本身也是一个动态库,即/lib/ld-linux.so文件。
动态链接器被加载到内存后,会首先给自己重定位,然后才能运行。像这种自己给自己重定位然后自动运行的行为,我们一般称为自举。
在嵌入式系统中,大家比较熟悉的U-boot也有自举功能,它在系统上电启动后会完成代码的自我复制和重定位操作,然后加载Linux内核镜像运行。
动态链接器解析可执行文件中未确定的符号及需要链接的动态库信息,将对应的动态库加载到内存,并进行重定位操作。这个过程其实和静态链接的重定位过程一样,只不过推迟到了运行阶段而已。重定位结束后,程序中要引用的所有符号都有了地址和定义,动态链接器将控制权交给要执行的程序,跳转到该程序运行。动态链接库在内存空间中的布局如下图所示:
(进程虚拟空间中的动态链接库)
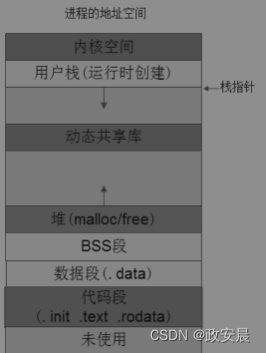
动态链接需要考虑的一个重要问题是加载地址。一个静态链接的可执行文件在运行时,一般加载地址等于链接地址,而且这个地址是固定的。可执行文件是操作系统帮我们创建一个子进程后,第一个被加载到进程空间的文件,此时进程的地址空间一马平川,还未被占用,所以不用考虑地址空间资源的问题。动态链接库加载到内存中的地址则是随机的,因为每一个可执行文件的大小不同,加载到内存后剩余的地址空间也不尽相同,动态链接库的地址要根据进程地址空间的实际空闲情况随机分配。
在这种情况下,动态链接库该如何运行呢?
很容易想到的一个方法就是装载时重定位。
在静态链接过程中,每个目标文件中的代码段都被分解组装,起始地址发生了变化,要进行重定位,然后程序才可以运行。类似静态链接的重定位,动态链接库被加载到内存后,目标文件的起始地址也发生了变化,需要重定位。一个可执行文件对动态链接库的符号引用,要等动态链接库加载到内存后地址才能确定,然后对可执行文件中的这些符号修改即可。以上面的例子为例,main()函数调用了add()函数,但add()函数的地址还不确定,等到libtest.so加载到内存后,add()函数的地址才能确定下来。加载器通过动态链接、重定位操作,更新了符号表中add()函数的实际地址,并修正main()函数指令中引用add()函数的地址,然后程序才可以正常运行。
这种装载时重定位操作,虽然解决了可执行文件中对绝对地址的引用问题,但也带来了另外一个问题:对于每个进程,动态库被加载到了内存的不同地址,也只能被进程自身共享,无法在多个进程间共享,无法节省内存,违背了动态库的设计初衷。如果有一种好方法,将我们的动态库设计成无论放到哪里,都可以执行,而且可以被多个进程共享,那么这个问题就迎刃而解了。
与地址无关的代码
如果想让我们的动态库放到内存的任何位置都可以运行,都可以被多个进程共享,一种比较好的方法是将我们的动态库设计成与地址无关的代码。
其实现思路很简单:将指令中需要修改的部分(如对绝对地址符号的引用)分离出来,剩余的部分就和地址无关了,放到哪里都可以执行,而且可以被多个进程共享。需要被修改的指令(符号)和数据在每个进程中都有一个副本,互不影响各自的运行。
先把需要修改的部分放到一边,暂且不谈,我们先讨论动态库中与地址无关的代码部分。与地址无关的代码实现也很简单,编译代码时加上-fPIC参数即可。PIC是Position-Independent Code的简写,即与地址无关的代码。加上-fPIC参数生成的指令,实现了代码与地址无关,放到哪里都可以执行。
![]()
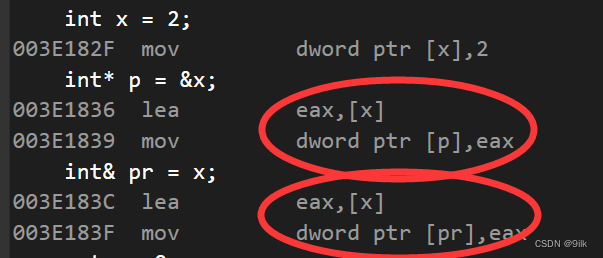
实现PIC需要底层相关的技术支撑,不同的平台有不同的实现方式。实现代码与地址无关,在模块内部,对函数和全局变量的引用要避免使用绝对地址,一般可以使用相对跳转代替。以ARM平台为例,可以采用相对寻址来实现。ARM有多种寻址方式,其中有一种叫相对寻址,以PC为基址,以当前指令和目标地址的差作为偏移量,两者相加的地址即操作数的有效地址。ARM汇编中的B、BL、ADR、ADRL等指令都是采用相对寻址实现的。

在上面的代码中,BLOOP指令其实就等价于:
其中OFFSET为B LOOP当前指令地址与LOOP标号之间的地址偏移。通过这种相对寻址的符号引用,可以做到代码与地址无关:你把这段代码放在内存中的任何位置,它都无须重定位,直接运行即可。
全局偏移表
在动态库的设计中,对于模块内的符号相互引用,我们通过相对寻址很容易实现代码与地址无关。但是当动态库作为第三方模块被不同的应用程序引用时,库中的一些绝对地址符号(如函数名)将不可避免地被多次调用,需要重定位。动态库中的这些绝对地址符号,如何能做到同时被不同的应用程序引用呢?
解决这个问题的核心思想其实也很简单:每个应用程序将引用的动态库(绝对地址)符号收集起来,保存到一个表中,这个表用来记录各个引用符号的地址。当程序在运行过程中需要引用这些符号时,可以通过这个表查询各个符号的地址。这个表被称为全局偏移表(Global Offset Table,GOT)。
在一个可执行文件中,其引用的动态库中的绝对地址符号(如函数名)会被分离出来,单独保存到GOT表中,GOT表以section的形式保存在可执行文件中,这个表的地址在编译阶段就已经确定了。
当程序运行需要引用动态库中的函数时,会将动态库加载到内存,根据动态库被加载到内存中的具体地址,更新GOT表中的各个符号(函数)的地址。等下次该符号被引用时,程序可以直接跳到GOT表查询该符号的地址,如果找到要调用的函数在内存中的实际地址,就可以直接跳过去执行了。因为GOT表在可执行文件中的位置是固定不变的,所以程序中访问GOT表的指令也是固定不变的,唯一需要变化的是:动态库加载到内存后,库中的各个函数的位置确定,在GOT表中实时更新各个符号在内存中的真实地址就可以了。
这样做的好处是:在内存中只需要加载一份动态库,当不同的程序运行时,只要修改各自的GOT表,它们引用的符号都可以指向同一份动态库,就可以达到不同程序共享同一个动态库的目标了。动态链接过程中的GOT表如下图所示。
(动态链接过程中的GOT表)

延迟绑定
动态链接通过使用“与地址无关”这一技术,加载到内存任意地址都可以运行。
“与地址无关”这一技术在ARM平台可以使用相对寻址来实现。ARM相对寻址的本质其实就是寄存器间接寻址,只不过基址换成了PC而已,访问效率还是比较低的,包括程序运行之前的动态链接和重定位操作,也会对程序的及时响应和性能造成一定的影响。
我们假设一个软件中有几百个地方使用了动态链接,如果把所有的动态库一次性全部加载到内存并一一对它们进行重定位,会耗费不少的时间。程序中存在大量的if-else分支,并不是所有的指令都能执行到,我们加载到内存的动态库可能根本就没有被调用到,这又会白白浪费内存空间。
基于这个原因,可执行文件一般都采用延迟绑定:程序在运行时,并不急着把所有的动态库都加载到内存中并进行重定位。当动态库中的函数第一次被调用到时,才会把用到的动态库加载到内存中并进行重定位。这样做既节省了内存,又可以提高程序的运行速度,因此得到广泛应用。
我们反汇编前面静态库的a.out,查看main()函数对应的ARM汇编代码。

分析上面的反汇编代码,找到main()函数中调用add的代码部分(第10624行),我们可以看到:调用add的指令跳到了0x104a4<add@plt>处执行。在0x104a4地址处,我们看到这里并不是add()函数实现的地方,而是一个跳转命令,跳到了GOT表中地址为0x2100c的地方。
一般情况下,GOT表中的每一项存放的都是符号的真实地址,但此时因为add第一次被调用,相应的动态库还没有加载到内存中,需要调用动态链接器去加载add的动态库,所以此时大家可以看到GOT表中每一项都是相同的值:0x10490。在0x10490地址处是一个跳转指令,跳转到动态链接器去执行,动态链接器的入口地址保存在GOT表的0x21008~0x2100b处。动态链接器的主要工作就是加载动态库到内存中并进行重定位操作:把add动态库加载到内存中,然后将add的实际地址更新到GOT表中保存add地址的那一项0x2100c地址处。此时在GOT表的0x2100c处保存的不再是默认的动态链接器地址0x10490,而是add()函数加载到内存中的实际地址。等第二次再调用add()函数时,就可以根据GOT表中的实际地址直接跳过去执行了。
延迟绑定的基本流程如下图所示:
(延迟绑定流程)
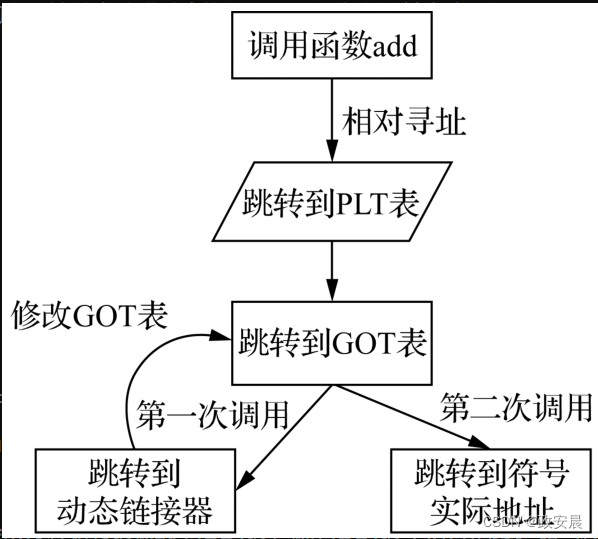
指令代码中每一个使用动态链接的符号<x@plt>,都被保存在过程链接表(Procedure Linkage Table,PLT,以.plt为后缀)中。
过程链接表其实就是一个跳转指令,它无法单独工作,要和GOT表相关联,协同工作。当程序中引用某个符号时,就会从过程链接表跳转到GOT表,跳到GOT表中对应的项。
如当程序中第一次引用<printf@plt>符号时,会跳到GOT表的0x21010处。在0x21010处,存放的是动态链接库的地址0x10490;
动态链接库加载printf()函数到内存,然后会将printf()函数在内存中的实际地址保存在0x21010处,再将控制权交给printf()函数执行。
等程序第二次调用printf()函数时,再次通过PLT表跳到GOT表的0x21010处,因为此时该地址上保存的是printf()函数在内存中的实际地址,所以就可以直接跳转过去执行了。
过程链接表PLT本质上是一个数组,每一个在程序中被引用的动态链接库函数,都在数组中对应其中一项,跳转到GOT表中的对应项。
PLT表中有两个特殊项,PLT[0]会关联到动态链接器的入口地址,而PLT[1]则会关联到初始化函数:
__libc_start_main(),该函数会初始化C语言运行的进本环境;
调用main()函数,等main()函数运行结束时,再根据main()函数的返回值做相应的处理;
负责main()函数运行结束后的清理工作。
C标准库其实就是以动态共享库的封装形式保存在Linux系统中的。
不同的应用程序都会调用printf() 函数,当它们在内存中运行时,只需要加载一份printf()函数代码到内存就可以了。
各个应用程序在引用printf这个符号时,就会启动动态链接器,将这份代码映射到各自进程的地址空间,更新各自GOT表中printf()函数的实际地址,然后通过查询GOT表找到printf()函数在内存中的实际地址,就可通过间接访问跳转执行。
共享库
现在大多数软件都是采用动态链接的方式开发的,不仅可以节省内存空间,升级维护也比较方便。在发布软件包时,可执行文件及其依赖的动态链接共享库被一起打包发布,如果你依赖的是系统默认自带的共享库,如C标准库,则不需要跟软件一起打包。
程序安装时:
可执行文件会复制到Linux系统的默认路径下,如/bin、/sbin、/usr/bin、/usr/sbin、/usr/local/bin等,这些路径由环境变量PATH管理和维护。可执行文件依赖的共享库一般要放到库的默认路径下面,如/lib、/usr/lib等。当程序运行时,动态链接器首先被加载到内存运行,动态链接器会分析可执行文件,从可执行文件的.dynamic段中查询该程序运行需要依赖的动态共享库,然后到库的默认路径下查找这些共享库,加载到内存中并进行动态链接,链接成功后将CPU的控制权交给可执行程序,我们的程序就可以正常运行了。
动态链接器在查找共享库的过程中,除了到系统默认的路径(/lib、/usr/lib)下查找,也会到用户指定的一些路径下去查找,用户可以在/etc/ld.so.conf文件中添加自己的共享库路径。为减少每次查找文件的时间消耗,/etc/ld.so.conf修改后,我们也可以使用ldconfig命令生成一个缓存/etc/ld.so.chche以提高查找效率。每当我们新增、删除或修改共享库的路径时,使用ldconfig更新一下缓存就可以了。
系统中的所有程序在运行时,都会按照上面的这种方式查找共享库。有时候我们也可以使用LD_LIBRARY_PATH环境变量临时改变共享库的查找路径,而不会影响系统中的其他应用程序。我们可以将多个共享库的路径添加到这个环境变量中,各个路径用冒号隔开。
![]()
现在,通过前面文章的学习,咱们对程序的编译、链接、安装、运行和动态链接等基本流程有了一个系统的认识。
作为一名嵌入式工程师,政安晨觉得把前面几篇文章的知识掌握就已经足够了:有了这些理论基础,再去分析嵌入式系统中一些比较难理解的知识点,就不会感到那么吃力和困难了,因为你会发现其实很多道理都是相通的。