作者 | ALIREZA SADEGHI
翻译 | Debra Chen
简介
虽然生成式人工智能和ChatGPT带来的沸沸扬扬的炒作令科技界为之一振,但在数据工程领域,2023年仍然是一个令人振奋和充满活力的一年,数据工程生态系统变得更加多样化和复杂化,系统中的所有层面都在不断创新和演进。
随着各种开源工具、框架和解决方案的持续涌现,数据工程师的选择也越来越多!在这样快速变化的环境中,紧跟最新技术和趋势的重要性不言而喻。选择合适的工具来完成合适的工作是一项至关重要的技能,确保在不断变化的数据工程挑战面前保持效率和相关性。
作为一名资深数据工程师和顾问,我一直密切关注着数据工程趋势,我想在2024年初向大家介绍开源数据工程生态系统,包括识别关键的活跃项目和重要工具,让大家在这个充满活力的技术领域中能够做出明智的决策。
为什么要再出一份生态全景图?
为什么我要再出一份数据生态系统全景图呢?虽然有类似的周期性报告,比如著名的MAD Landscape、数据工程现状和Reppoint开源Top25,但我做的这份全景图专注于仅适用于数据平台和数据工程生命周期的开源工具。MAD Landscape提供了对机器学习、人工智能和数据的所有工具和服务的非常全面的概览,包括商业和开源项目,而本报告呈现的生态系统则更全面地展示了MAD中关于数据部分的活跃开源项目。其他报告,比如Reppoint开源Top25和Data50更关注SaaS提供商和创业公司,而本报告则更关注开源项目本身,而非SaaS服务。
像Github的开源现状、Stackoverflow年度调查和OSS Insight报告这样的年度报告和调查也是了解社区中正在使用或趋势的重要来源,但它们涵盖的数据生态系统有限(如数据库和编程语言)。
因此,我出于对开源数据栈的兴趣,便整理了数据工程生态系统中的开源工具和服务。
所以,不多说了,这就是2024年的开源数据工程生态系统:
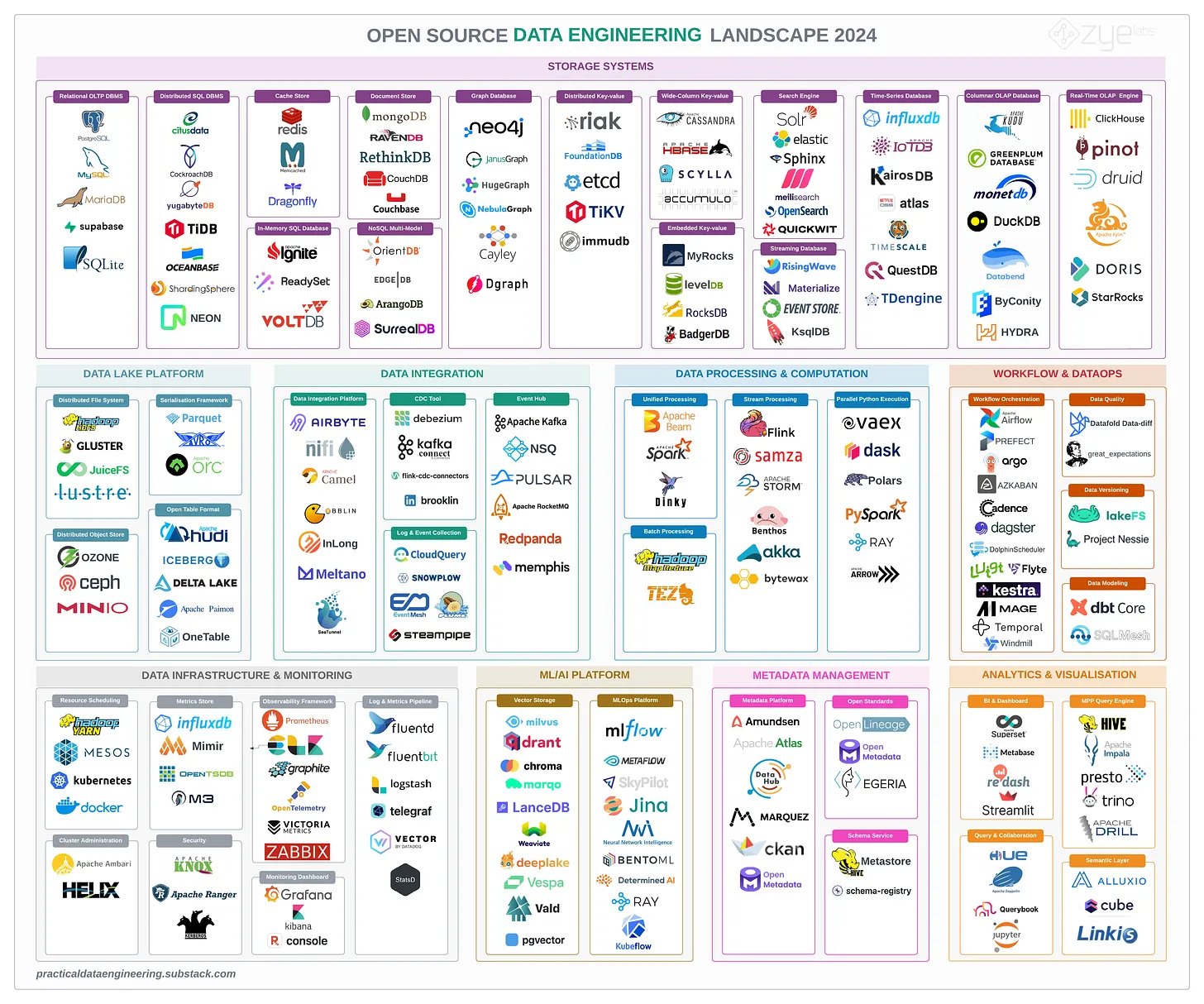
开源数据工程生态系统2024年
工具选择标准
每个类别的可用开源项目显然数目庞大,把每个工具和服务都纳入其中是不现实的。因此,我遵循了以下选择每个类别工具的标准:
- 排除了任何已退休、存档和被放弃的项目。大家很关注的退休项目包括Apache Sqoop、Scribe和Apache Apex,虽然它们仍然可能在一些生产环境中使用。
- 排除了过去一年在Github上完全不活跃的项目,以及在社区中几乎未被提及的项目。比如Apache Pig和Apache Oozie项目。
- 排除了仍然相对较新且在Github上没有获得太多关注(如stars、forks)以及在博客文章、案例展示和在线社区中几乎未被提及的项目。但是一些有前景的项目,如OneTable,已经取得了一些值得注意的进展,并且是基于现有技术构建的。
- 除了机器学习平台和基础设施工具,数据科学、机器学习和人工智能工具被排除在外,因为我只关注与数据工程学科相关的内容。
- 不同类型的存储系统,如关系型OLTP和嵌入式数据库系统都有所列举。因为数据工程学科涉及到处理应用程序和运营系统(BSS)中使用的许多不同的内部和外部存储系统,即使它们不是分析堆栈的一部分。
- 类别的名称尽可能地通用,基于这些工具在数据堆栈中的位置来分门别类。对于存储系统,主要的数据库模型和数据库工作负载(OLTP、OLAP)用于对存储系统进行分组和标记,但是例如“分布式SQL DBMS”也被称为HTAP或可扩展的SQL数据库。
- 一些工具可能属于多个类别。例如,VoltDB既是内存数据库又是分布式SQL DBMS。但是我尽量将它们放在市场上最常识别的类别中。
- 对于某些数据库系统,它们实际所属的类别可能有些模糊。例如,ByConity声称自己是数据仓库解决方案,但是它是建立在被认为是实时OLAP引擎的ClickHouse之上的。因此,目前还不清楚它是否是实时(能够支持亚秒查询)的OLAP系统。
- 并非所有列出的项目都是完全可迁移的开源工具。其中一些项目更像是Open Core而不是开源。在开放核心模型中,不是所有组件都是由主要SaaS提供商提供的完整系统的开源。因此,在决定采用开源工具时,考虑项目有多具有可移植性和真正开源是很重要的。
工具类别概述
在接下来的部分中,我简单讨论下每个类别。
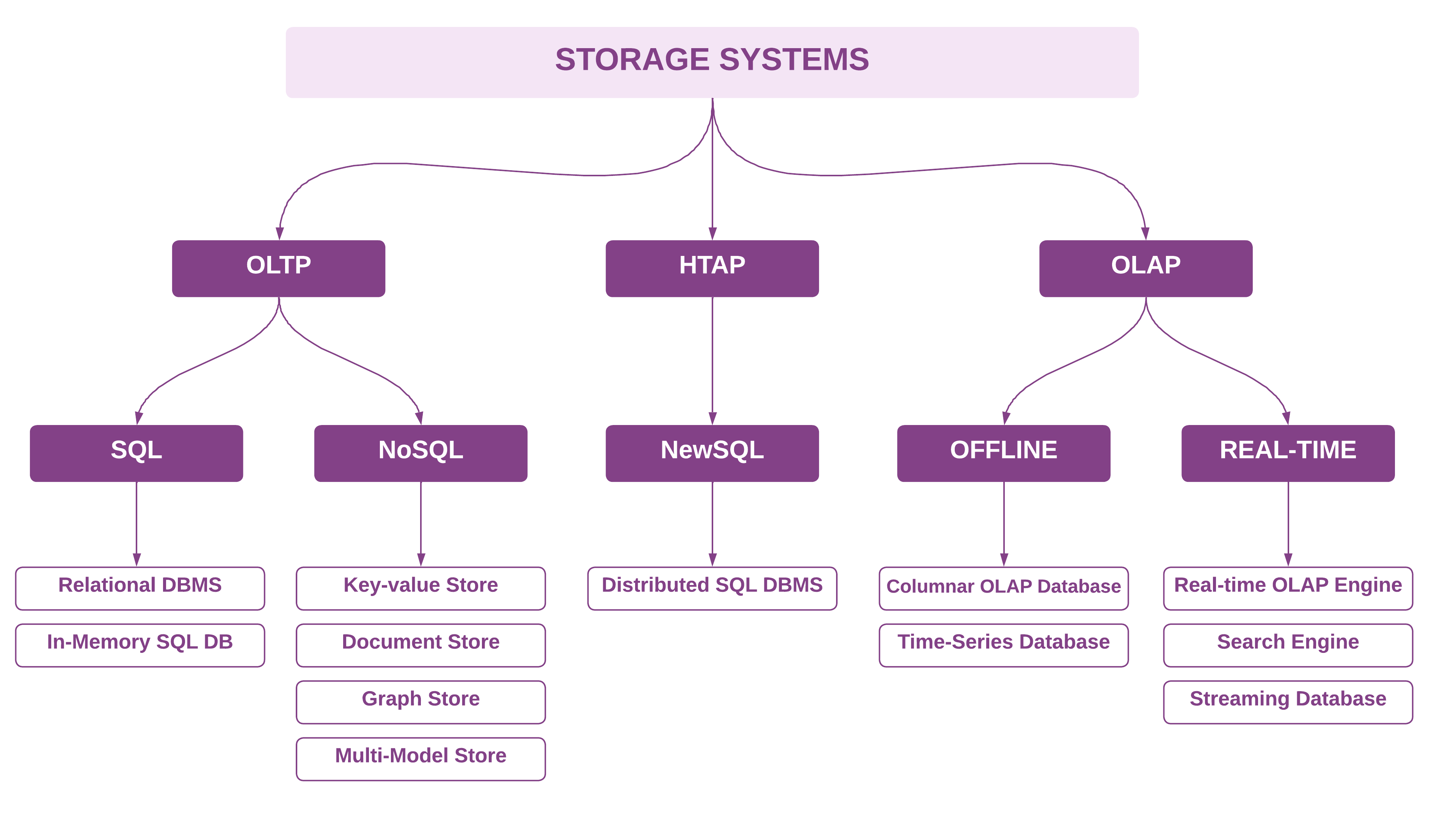
1. 存储系统
存储系统是这份生态系统全景图中最大的类别,主要归因于专门的数据库系统近期以来激增。最新的两个流行类别是矢量数据库和流数据库。Materialize和RaisingWave是开源流数据库系统的示例。矢量数据库在存储系统领域也经历了快速增长。我将矢量存储系统放在ML平台部分,因为它们主要用于ML和AI堆栈。分布式文件系统和对象存储也有了它们自己的相关类别,即数据湖平台。
如选择标准部分所述,存储系统根据主要的数据库模型和工作负载进行分组和标记。在最高层面上,存储系统可以分为三个主要类别:OLTP、OLAP和HTAP。它们可以根据SQL vs NoSQL(OLTP引擎)以及离线(非实时)vs 实时(亚秒结果)(OLAP引擎)进一步分类,如下图所示。
2. 数据湖平台
数据湖平台在过去一年持续成熟化,Gartner把数据湖放在了其2023年版的数据管理炒作周期图上。
对于存储层,分布式文件系统和对象存储仍然是服务于本地和基于云的数据湖实施的主要技术基石。尽管HDFS仍然是本地Hadoop集群的主流技术,但Apache Ozone分布式对象存储正在迎头赶上,为本地数据湖存储技术提供了另一种选择。主流商业Hadoop提供商Cloudera现在把Ozone作为其CDP私有云产品的一部分。
数据序列化格式的选择会影响存储效率和处理性能。在Hadoop生态系统中,Apache ORC仍然是列存储的首选,而Apache Parquet已经成为现代数据湖中数据序列化的事实标准。它之所以受欢迎,是因为它体积不大、高效压缩以及与各种处理引擎的广泛兼容性。
2023年的另一个关键趋势是存储和计算层的解耦。许多存储系统现在提供与基于云的对象存储解决方案(如S3)的集成,利用其固有的效率和弹性。这种方法允许数据处理资源独立于存储进行扩展,从而实现成本节省和增强可扩展性。Cockroachdb支持S3作为存储后端,Confluent提供在S3上长期保留Kafka主题数据的服务,进一步说明了这一趋势,突显了数据湖作为经济实惠、长期存储解决方案的不断增长的使用。
2023年最热门的发展之一是开放表格格式的兴起。这些框架实质上充当了一个表格抽象和虚拟数据管理层,位于你的数据湖存储和数据层之上,如下图所示。
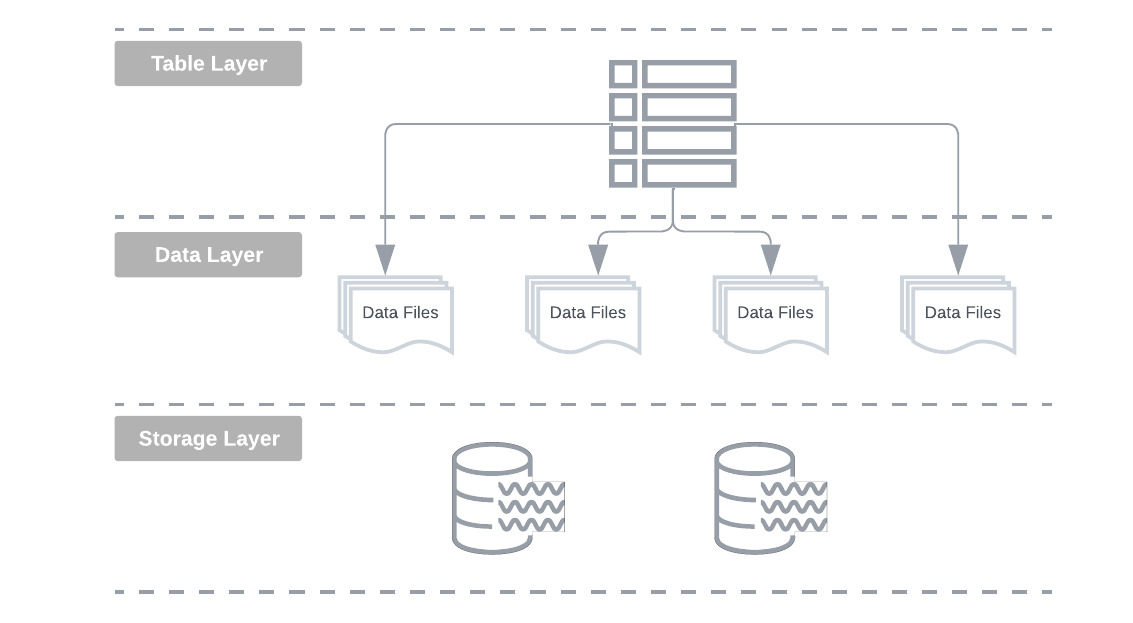
当前,开放表格格式领域三足鼎立:
- Apache Hudi:最初由Uber开发和开源,其主要设计目标是支持近实时数据更新和ACID事务。
- Apache Iceberg:由Netflix的工程团队发起。
- Delta Lake:由Databricks创建和开源,与Databricks平台无缝集成。
在这个赛道的领先SaaS提供商Databricks、Tabular和OneHouse,在2023年获得的融资显示出市场对这个领域的兴趣,以及它们进一步推进数据湖上数据管理的潜力。
此外,现在正在出现一种新的趋势,即统一的数据湖层的出现。OneTable(最近由OneHouse开源)和UniForm(目前是Databricks的非开源产品)是去年宣布的两个领先项目。这些工具超越了单个表格格式,提供了在一个单一框架下使用所有这三个主要竞争者的能力。这让用户能够采用通用格式,同时以其首选格式向处理引擎暴露数据,从而提高了灵活性和敏捷性。
3. 数据集成
2023年的数据集成领域不仅继续由Apache Nifi、Airbyte和Meltano等老牌玩家主导,还出现了一些有前景的工具,例如Apache Inlong和Apache SeaTunnel,它们以其独特的优势提供的的替代方案引人注目。
与此同时,得益于Kafka生态系统的积极发展,流式CDC(变更数据捕获)也进一步成熟。Kafka Connect和Debezium插件已经成为从数据库系统中进行近实时数据捕获的首选,而对于使用Flink作为主要流处理引擎的部署,Flink CDC连接器正在获得越来越多的关注。
除了传统的数据库之外,诸如CloudQuery和Streampipe之类的工具正在简化对API的数据集成,为各种来源的数据提供了方便的解决方案,这反映了与云服务灵活集成的重要性的增长。
在事件和消息中间件领域,虽然有挑战者如Redpanda追赶,但Apache Kafka的地位无人撼动。Redpanda在2023年获得了1亿美元的C轮融资,表明资本对提供低延迟和高吞吐量的替代消息代理的兴趣正在增长。
4. 数据处理与计算
流处理领域在2023年继续升温!Apache Spark和Apache Flink仍然是主导者,但Apache Flink在2023年吸引了一些严肃的关注。AWS和阿里巴巴等云巨头推出了Flink-as-a-service产品,Confluent收购了Immerok并推出了自己的全托管Flink产品,可以看到这一强大引擎背后的动力。
在Python生态系统中,数据处理库如Vaex、Dask、polars和Ray可用于利用多核处理器。这些并行执行库进一步拓展了在熟悉的Python环境中分析大规模数据集的可能性。
5. 工作流管理与DataOps
工作流调度的生态可以说是整个生态系统中最丰富的类别,其中既有老牌巨头也有令人兴奋的新秀。
诸如Apache Airflow和Dagster之类的老牌工具仍然很受欢迎,尽管最近社区中关于工作流调度引擎的拆解、重新打包和打包与不打包的辩论异常激烈,但它们仍然是被广泛采用的调度引擎。另一方面,在过去的两年中,GitHub见证了几个令人信服的新兴工具的崛起,它们获得了相当大的关注。Kestra、Temporal、Mage和Windmill都值得关注,它们各自有着独特的优势。无论是专注于无服务器编排,如Temporal,还是分布式任务执行,如Mage,这些新秀都能满足现代数据管道不断发展的需求。
6. 数据基础设施与监控
最近Grafana Labs的调查证实,Grafana、Prometheus和ELK仍然在可观察性和监控领域占据主导地位。Grafana Labs本身一直非常活跃,推出了新的开源工具,如Loki(用于日志聚合)和Mimir(用于长期的Prometheus存储),进一步加强了平台能力。
在集群管理和监控方面,开源工具似乎就不那么热门了。这可能是因为云迁移的趋势减少了对管理大型本地数据平台的需求。虽然Apache Ambari项目曾经因Hadoop集群管理火爆一时,但在2019年Hortonworks和Cloudera合并后几乎被放弃,最近重新燃起的复苏的小火苗又给它的未来带来一丝希望。但是,它的命运是否长久仍然不确定。
至于资源调度和工作负载部署,Kubernetes似乎是首选的资源调度,特别是在基于云的平台上。
7. 机器学习平台
机器学习平台是最活跃的类别之一,其中矢量数据库受到了前所未有的关注。这是一种针对高维数据存储和检索进行优化的专用系统。正如DB-Engines的2023年报告所强调的,矢量数据库成为过去一年中最受欢迎的数据库类别。
MLOps工具在高效扩展ML项目方面也发挥着越来越重要的作用,确保ML应用程序生命周期管理的顺利运行。随着ML部署的复杂性和规模不断增长,MLOps工具已成为简化ML模型开发、部署和监控的不可或缺的工具。
8. 元数据管理
近年来,元数据管理已经成为关注焦点,这是由于对数据进行管理和访问的需求不断增长。然而,缺乏全面的元数据管理平台促使像Netflix、Lyft、Airbnb、Twitter、LinkedIn和Paypal等科技巨头构建自己的解决方案。
这些努力为开源社区带来了一些显著的变化。像Amundsen(来自Lyft)、DataHub(来自LinkedIn)和Marquez(来自WeWork)这样的工具是自主开发的解决方案,都已经开源并正在积极开发和贡献。
至于架构管理,这个领域仍然有些停滞不前。Hive Metastore仍然是许多人的首选解决方案,因为目前没有替代的开源解决方案来取代它。
9. 分析与可视化
在商业智能(BI)和可视化领域,Apache Superset是最活跃和受欢迎的开源替代方案,与许可的SaaS BI解决方案相比,它的表现更为出色。
对于分布式和大规模并行处理(MPP)引擎,一些专家认为大数据已经过时,大多数公司不需要大规模的分布式处理,而是选择单个强大的服务器来处理其数据量。
尽管有这种说法,但分布式大规模并行处理(MPP)引擎,如Apache Hive、Impala、Presto和Trino,在大型数据平台中仍然非常普遍,特别是对于拥有PB级数据的情况。
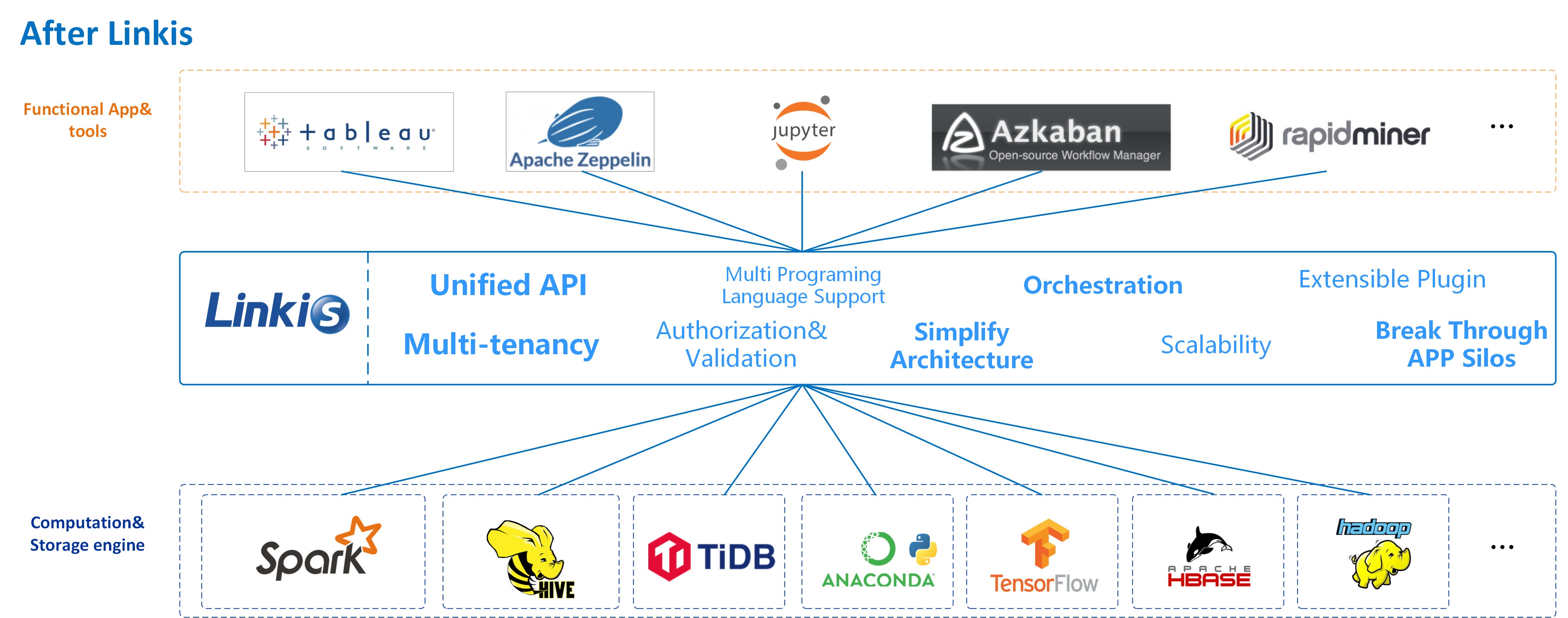
除了传统的MPP引擎之外,统一执行引擎是另一个获得关注的趋势。诸如Apache Linkis、Alluxio和Cube之类的引擎为上层应用程序和底层引擎之间提供了查询和计算中间件。
结论
对开源数据工程生态系统的探索是我们对不断变动而充满活力的数据工程世界的一瞥。虽然这份全景图中各个类别涵盖了表现突出的工具和技术,但这个生态系统仍在迅速发展,不断涌现新的解决方案。
注意,这不是一个详尽的列表,而“最佳”的工具最终取决于你的具体需求和用例。如果我漏掉了任何值得注意的好工具,欢迎随时分享给我。
本文由 白鲸开源科技 提供发布支持!