内容简介
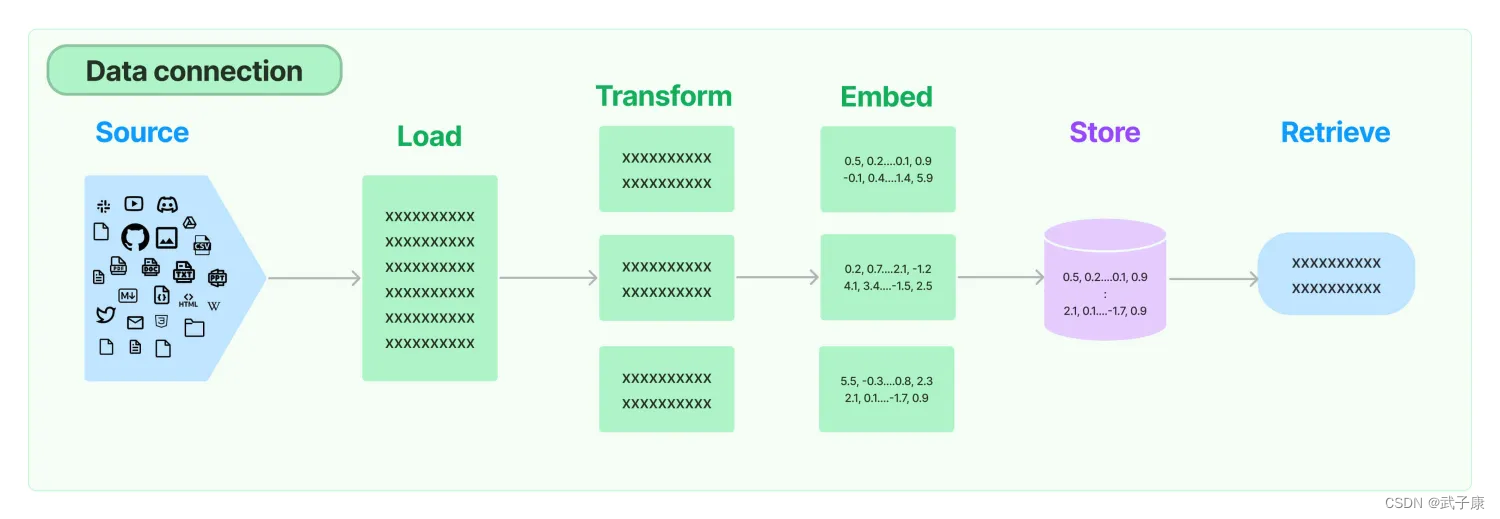
LangChain 中的 “RAG” 指的是 “Retrieval-Augmented Generation”,即检索增强生成。它是一种结合了检索(从大量数据中检索相关信息)和生成(基于检索到的信息生成文本)的技术,旨在改善和增强自然语言生成模型的性能。通过检索相关的信息作为输入,模型能够生成更准确、更丰富和更具相关性的输出。
我们可以将:
- 文本
- 图片
- 网页
等等数据进行向量化存储,使用RAG进行生成,会得到很好的效果。
安装依赖
pip install --upgrade --quiet langchain-core langchain-community langchain-openai
pip install langchain docarray tiktoken
编写代码
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings# Requires:
# pip install langchain docarray tiktokenvectorstore = DocArrayInMemorySearch.from_texts(["harrison worked at kensho", "bears like to eat honey"],embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model="gpt-3.5-turbo",
)
output_parser = StrOutputParser()setup_and_retrieval = RunnableParallel({"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parsermessage = chain.invoke("where did harrison work?")
print(message)
如果你想要流式输出的话(类似打字机的效果),你需要:
# message = chain.invoke("where did harrison work?")
stream = chain.stream("where did harrison work?")
for chunk in stream:print(chunk, end="", flush=True)
运行结果
Harrison worked at Kensho.