| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年4月3日11:13:50 | V0.1 | 宋全恒 | 新建文档 |
简介
安利印象笔记
在阅读这篇博客之前,首先给大家案例一下印象笔记这个应用,楼主之前使用onenote来记录自己的生活的,也记录了许多的内容,但是,有一天自己的同事和自己说了印象笔记这个工具,然后在使用了之后,就发现确实是不错的,包括模板功能啊,大纲,XMind支持,以及剪藏功能,而且在多个终端可以非常方便的同步,而且每个笔记有300M的空间(超级用户),最新的印象笔记也上线了视图功能,让自己非常的方便。
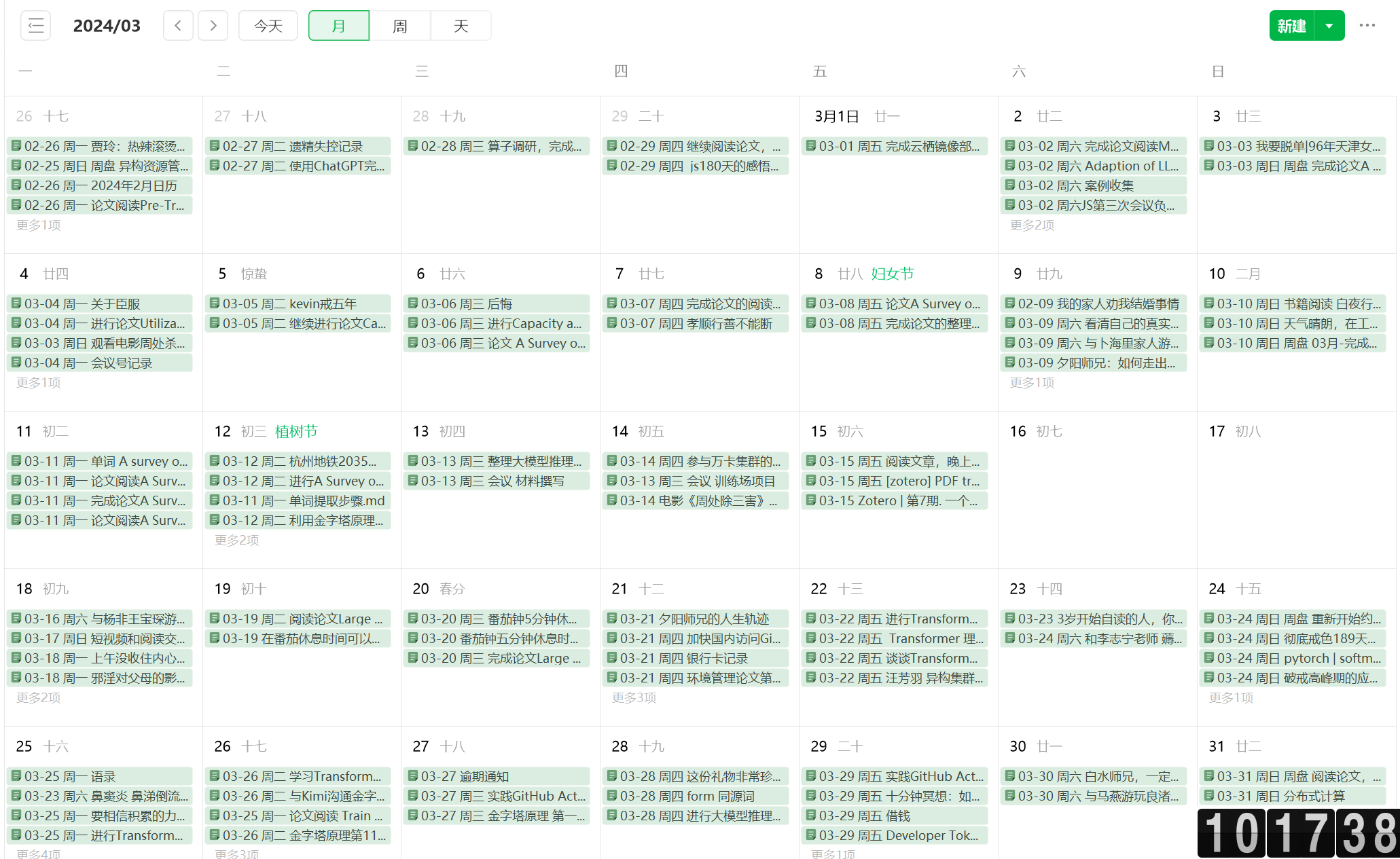
这样让自己的复盘非常的便利,因为自己已经基本养成了周盘、月盘、年盘的习惯了
我们每天都有不同的生活,而生活是需要记录的,当时间过去之后,如果我们忘记了当时的心情,当时的事情也是有些遗憾的事。所以呢,建议大家养成记录的习惯,记录自己的开心和不快,记录自己的挣扎和痛苦,然后通过不断的反省,然后让自己辽阔。因为
痛苦 + 反思 = 进步
这是瑞·达利欧在原则中所说的话。还是很受益的。

问题
印象笔记写了很多年,也有了7000多条记录了,当然不仅仅是自己的日记笔记,也有通过剪藏收集的关于专业的内容,主要是包括
- 专业程序类,
- 戒色修身,改过迁善的文章
- 日记,当然也有许多自己的经历和看法,
主要是比较真实的。都真实的记录了自己的人生过去。然后在使用过程中,自己发现在手机和app端有一个功能那年今日,可以把过去的每一年的今天写的日记给重新显示(手机的助手),可遗憾的是,电脑端没有这个功能。怎么能够在电脑端印象笔记快速的检索出来那年今日的文章呢?
在之前的时候,自己主要是使用created:这个快捷键智能检索,根据笔记的创建时间来过滤出来那年今日的内容,这样就形成了下面的解决方案:

但是这种方式有问题,第一,就是得每年新增一个这样的搜索,第二就是在查询的时候,必须挨个点击,而我又是一个高级的程序猿,忍受不了这种低效的方式。所以我应该怎么解决这个问题呢?
就是有一天工作的时候突然想到,自己可以接入印象笔记的API吧,然后使用印象笔记的高级检索intitle:04-03这样只要输入今天的日期,就可以检索笔记标题中含有04-03的内容了,哈哈,当时因为这个念头就很兴奋。因为之前没有想到使用API,就一直手动修改,但是7000多条笔记真的修改起来太机械(mechanic),太枯燥了。本篇文章就是记录了使用API批量修改笔记标题的过程的过程。
前提
- 印象笔记的API库,由于楼主最近使用Python,因此,使用Python的印象API,即ever-sdk-python,需要注意的是,只支持Python2.7
- 官方提供的Quciker start可以参考, 关于沙盒 和Evernote API key,如果你是修改自己的笔记,则是不需要的。
- 需要Developer Token,进入该网站生成TOken

- Python SDK参考目录 API Reference,具体如下所示:

代码片段
程序使用Python实现,基本功能是将标题
完成GitHub自托管运行器的实践,发表印象笔记博客
修改成
04-03 完成GitHub自托管运行器的实践,发表印象笔记博客
当然日期,根据笔记的创建日期进行转换
# -*- coding: utf-8 -*-
#
# A simple Evernote API demo script that lists all notebooks in the user's
# account and creates a simple test note in the default notebook.
#
# Before running this sample, you must fill in your Evernote developer token.
#
# To run (Unix):
# export PYTHONPATH=../../lib; python EDAMTest.py
#import hashlib
import binascii
import evernote.edam.userstore.constants as UserStoreConstants
import evernote.edam.type.ttypes as Types
from evernote.edam.notestore.ttypes import NoteFilter, NotesMetadataResultSpecfrom evernote.api.client import EvernoteClient
import codecs# Real applications authenticate with Evernote using OAuth, but for the
# purpose of exploring the API, you can get a developer token that allows
# you to access your own Evernote account. To get a developer token, visit
# https://SERVICE_HOST/api/DeveloperToken.action
#
# There are three Evernote services:
#
# Sandbox: https://sandbox.evernote.com/
# Production (International): https://www.evernote.com/
# Production (China): https://app.yinxiang.com/
#
# For more information about Sandbox and Evernote China services, please
# refer to https://dev.evernote.com/doc/articles/testing.php
# and https://dev.evernote.com/doc/articles/bootstrap.phpfrom datetime import datetimedef get_time_str(timestamp):# 将时间戳转换为datetime对象 # 注意时间戳是毫秒,需要除以1000转换为秒dt_object = datetime.utcfromtimestamp(timestamp / 1000) # 定义日期格式date_format = "%Y-%m-%d %H:%M:%S"# 格式化日期formatted_date = dt_object.strftime(date_format)# 打印结果return formatted_dateimport re
def is_data_prefix_with_space(title):"""检查标题的前六位字符是否符合日期格式(dd-mm)。并且包含一个空格参数:title (str): 需要检查格式的标题字符串。返回:bool: 如果标题的前六位字符符合日期格式,返回 True;否则返回 False。"""# 正则表达式匹配前六位是否为两位数字-两位数字pattern = r'^\d{2}-\d{2} 'if re.match(pattern, title[:6]): # 限制检查的字符串长度为6return Trueif re.match("^\d{2}-\d{2}", title[:5]) and len(title.strip())==5:return Truereturn Falsedef is_data_prefix_without_space(title):"""检查标题的前六位字符是否符合日期格式(dd-mm)。并且包含一个空格参数:title (str): 需要检查格式的标题字符串。返回:bool: 如果标题的前六位字符符合日期格式,返回 True;否则返回 False。"""# 正则表达式匹配前六位是否为两位数字-两位数字pattern = r'^\d{2}-\d{2}'if re.match(pattern, title[:6]): # 限制检查的字符串长度为6return Trueelse:return Falsedef get_title_with_date(title, timestamp_ms):"""将毫秒时间戳转换为日期格式,并与标题拼接,确保标题中的日期后跟有空格。参数:title (str): 需要拼接的标题字符串。timestamp_ms (int): 时间戳,表示自1970年1月1日以来的毫秒数。返回:str: 转换并拼接后的字符串,格式为 "xx-xx title"。"""# 正则表达式匹配以 "xx-xx" 开头且后面没有空格的模式match = re.match(r'(\d{2}-\d{2})[^\s]*', title)if match:# 如果标题符合模式,添加空格title = match.group(1) + " " + title[len(match.group(1)):]return title# 将毫秒时间戳转换为秒timestamp = timestamp_ms / 1000.0# 将时间戳转换为datetime对象dt_object = datetime.fromtimestamp(timestamp)# 格式化日期为 "xx-xx" 格式date_str = dt_object.strftime("%02m-%02d")# 拼接标题和日期,中间有一个空格formatted_title = date_str +" " + titlereturn formatted_titledef write_array_to_file(array, filename='success_books.txt'):"""将数组写入文件,每个元素占一行。参数:array (list): 要写入文件的数组。filename (str): 文件名,默认为 'success_books.txt'。"""with open(filename, 'w') as file: # 移除 encoding 参数for item in array:file.write("%s\n" % item)def read_array_from_file(filename='success_books.txt'):"""从文件中读取数组,如果文件不存在则返回空数组。参数:filename (str): 文件名,默认为 'success_books.txt'。返回:list: 从文件中读取的数组,或者空数组(如果文件不存在)。"""try:with open(filename, 'r') as file: # 尝试以只读模式打开文件array = [line.strip() for line in file.readlines()]return arrayexcept OSError:# 如果发生OSError异常(包括FileNotFoundError),返回空数组return []except IOError:# 如果发生其他IOError异常(如权限问题),也返回空数组return []# 请修改为自己的auth_token,这个是楼主的无效的token
auth_token = "S=s43:U=91d3be:E=18ead076f78:C=18e88fae9a8:P=1cd:A=en-devtoken:V=2:H=d0d841403a8c584016c327591d12852"if auth_token == "your developer token":print "Please fill in your developer token"print "To get a developer token, visit " \"https://sandbox.evernote.com/api/DeveloperToken.action"exit(1)# To access Sandbox service, set sandbox to True
# To access production (International) service, set both sandbox and china to False
# To access production (China) service, set sandbox to False and china to True
# 请修改
sandbox = False
china = True# Initial development is performed on our sandbox server. To use the production
# service, change sandbox=False and replace your
# developer token above with a token from
# https://www.evernote.com/api/DeveloperToken.action
client = EvernoteClient(token=auth_token, sandbox=sandbox, china=china)user_store = client.get_user_store()version_ok = user_store.checkVersion("Evernote EDAMTest (Python)",UserStoreConstants.EDAM_VERSION_MAJOR,UserStoreConstants.EDAM_VERSION_MINOR
)
print "Is my Evernote API version up to date? ", str(version_ok)
print ""
if not version_ok:exit(1)note_store = client.get_note_store()# List all of the notebooks in the user's account
notebooks = note_store.listNotebooks()
print "Found ", len(notebooks), " notebooks:"
for notebook in notebooks:success_books=read_array_from_file()if notebook.guid in success_books:continueprint "notebook name:",notebook.name," notebook guid: ", notebook.guidprint "--------------------------------------------------------------"filter = NoteFilter()filter.notebookGuid = notebook.guidresult_spec = NotesMetadataResultSpec()result_spec.includeTitle=Trueresult_spec.includeCreated=Truenotes_metadata_list = note_store.findNotesMetadata(filter, 0, 1000, result_spec)print "totalNotes:", notes_metadata_list.totalNotesfor note in notes_metadata_list.notes:if is_data_prefix_with_space(note.title):continueold_title = note.titlenew_title = get_title_with_date(note.title, note.created)note.title = new_titleprint "Modify title From", old_title.ljust(50, ' '), " To ", new_title.ljust(50, ' ')note_store.updateNote(auth_token, note)print "--------------------------------------------------------------"print "notebook name:",notebook.name,"处理完成"success_books.append(notebook.guid)write_array_to_file(success_books)# # To create a new note, simply create a new Note object and fill in
# # attributes such as the note's title.
# note = Types.Note()
# note.title = "Test note from EDAMTest.py"# # To include an attachment such as an image in a note, first create a Resource
# # for the attachment. At a minimum, the Resource contains the binary attachment
# # data, an MD5 hash of the binary data, and the attachment MIME type.
# # It can also include attributes such as filename and location.
# image = open('enlogo.png', 'rb').read()
# md5 = hashlib.md5()
# md5.update(image)
# hash = md5.digest()# data = Types.Data()
# data.size = len(image)
# data.bodyHash = hash
# data.body = image# resource = Types.Resource()
# resource.mime = 'image/png'
# resource.data = data# # Now, add the new Resource to the note's list of resources
# note.resources = [resource]# # To display the Resource as part of the note's content, include an <en-media>
# # tag in the note's ENML content. The en-media tag identifies the corresponding
# # Resource using the MD5 hash.
# hash_hex = binascii.hexlify(hash)# # The content of an Evernote note is represented using Evernote Markup Language
# # (ENML). The full ENML specification can be found in the Evernote API Overview
# # at http://dev.evernote.com/documentation/cloud/chapters/ENML.php
# note.content = '<?xml version="1.0" encoding="UTF-8"?>'
# note.content += '<!DOCTYPE en-note SYSTEM ' \
# '"http://xml.evernote.com/pub/enml2.dtd">'
# note.content += '<en-note>Here is the Evernote logo:<br/>'
# note.content += '<en-media type="image/png" hash="' + hash_hex + '"/>'
# note.content += '</en-note>'# Finally, send the new note to Evernote using the createNote method
# The new Note object that is returned will contain server-generated
# attributes such as the new note's unique GUID.
#created_note = note_store.createNote(note)# print "Successfully created a new note with GUID: ", created_note.guid代码解读
修改部分
要设置自己的auth_token,并且,不需要使用沙盒并且使用国内印象笔记服务。

程序主题流程

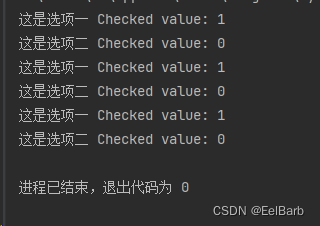
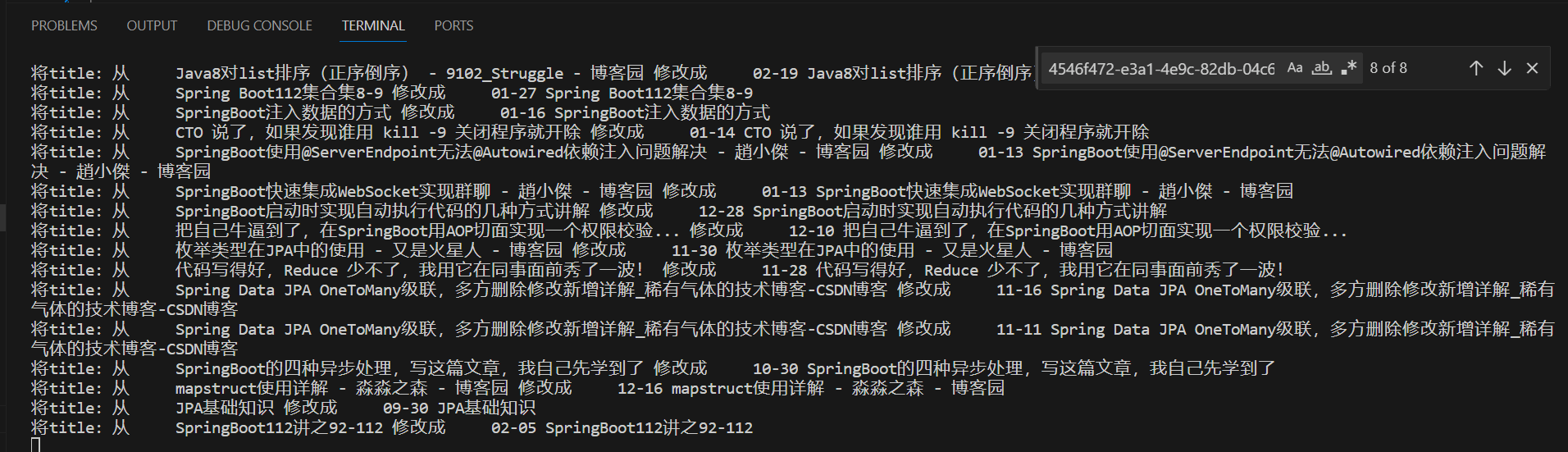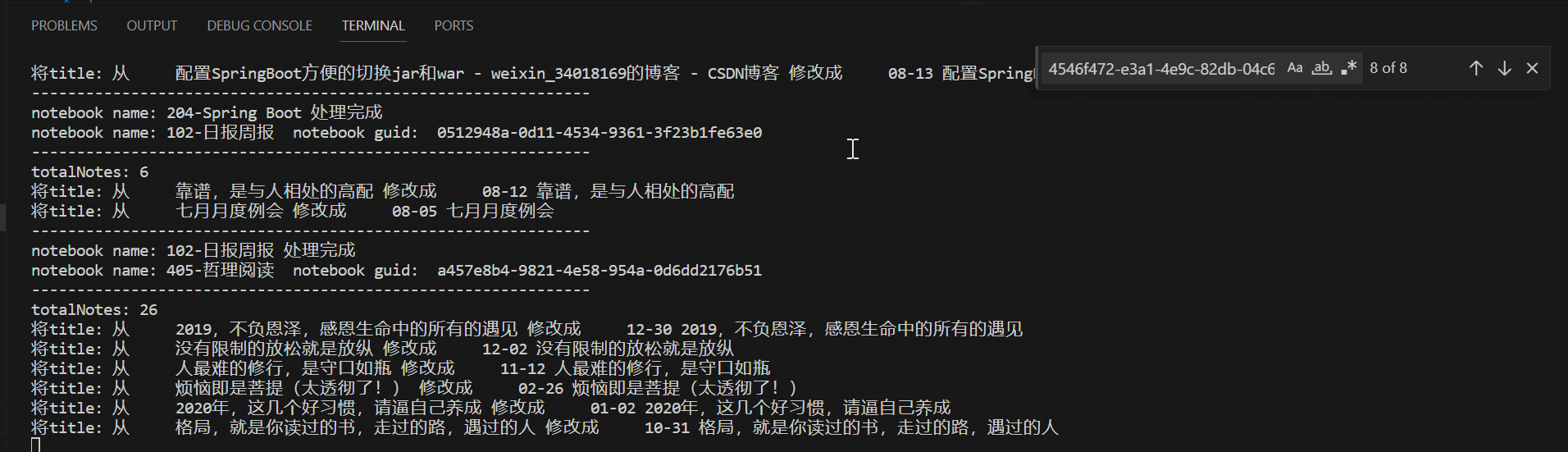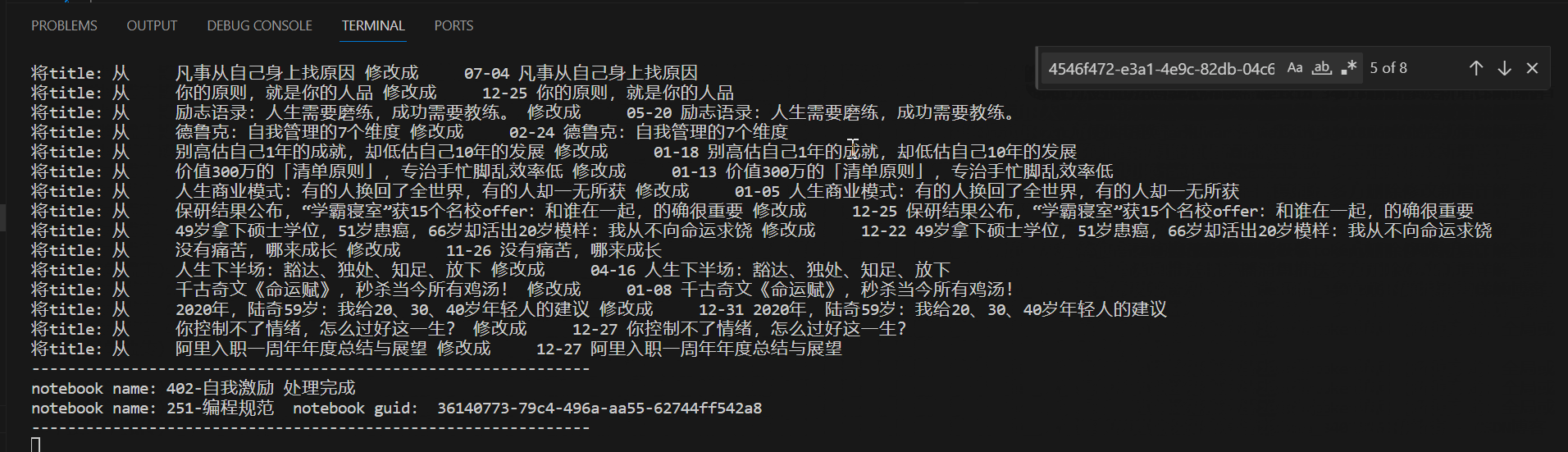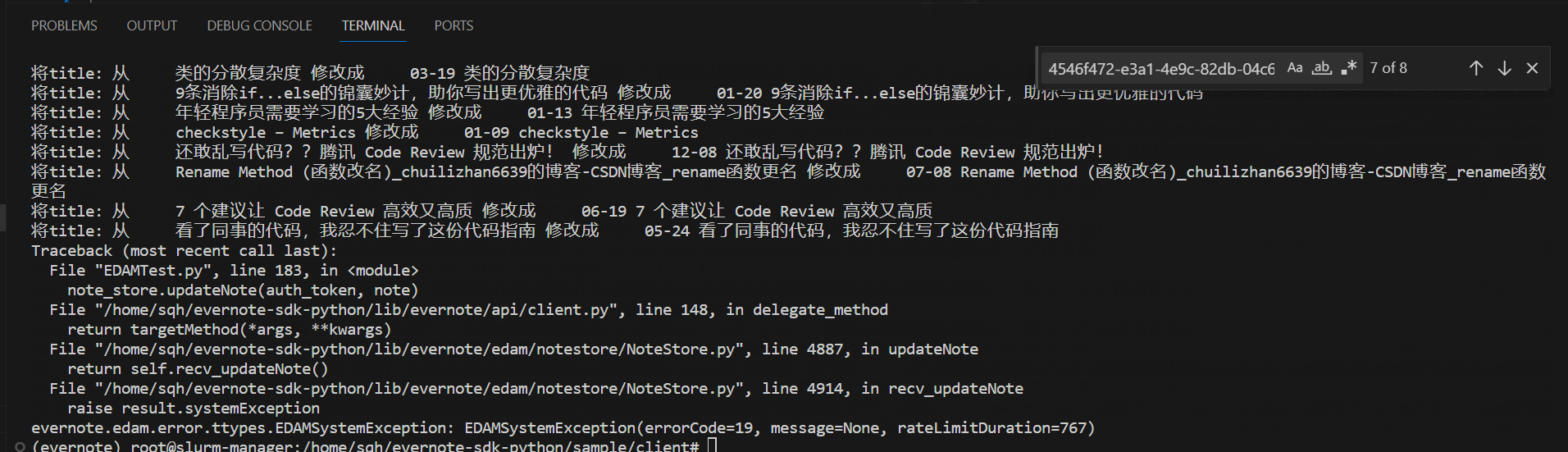
代码执行效果
总结
手动修改,真的太痛苦了,通过程序来解决问题,真香。
通过上述的过程,就可以将所有的笔记标题均修改成包含日期的标题了,这样只要保证以后在写日记或剪藏的时候,手动添加上标题,就可以保持一致性了,这样整体就非常的方便了。轻轻松松可以实现通过intitle:04-03 查询出每年的今天所撰写的笔记。
还是那句话,无论过去每个人多么的痛苦和难以接受,无论现状多么糟糕和难以忍受,但是我们就是踏着那样的道路走到了现在的样子,不抗拒,不抱怨,接纳然后从记录中获取问题,分析问题,然后解决问题,这或许就是成长的样子吧。