导读
深信服科技股份有限公司
简称「深信服」( Sangfor Technologies Inc. ),是一家领先的网络安全和云计算解决方案提供商,致力于为全球客户提供高效、智能、安全的网络和云服务。随着公司业务的不断扩展,也面临着监控和故障定位方面的挑战。本文将介绍深信服如何借助观测云实现全链路可观测性,提高运维效率和安全性。
案例亮点
- 大型门户网站可观测最佳实践
- 借助观测云实现 APM、RUM、基础设施、日志、拨测等全功能一体化全链路可观测体验
- 优化网页卡顿问题,大幅提升用户体验
简单介绍一下贵公司
深信服科技股份有限公司是一家专注于企业级网络安全、云计算、IT基础设施与物联网的产品和服务供应商,在全球设有 50 余个分支机构,公司先后被评为国家级高新技术企业、中国软件和信息技术服务综合竞争力百强企业、下一代互联网信息安全技术国家地方联合工程实验室、广东省智能云计算工程技术研究中心等。 一直以来,深信服十分重视研发和创新,并坚持以“持续创新”的理念,全情投入为用户打造省心便捷的产品,获得了市场的广泛认可。目前,超过 10 万家企业级用户正在使用深信服的产品。
当前面临的挑战
深信服的核心业务涵盖了网络安全、云计算、云服务和 IT 基础设施等多个领域。使用的监控工具有:云平台上的自有云监控和 Zibbix、Prometheus、Grafana 等开源自建的监控体系。随着客户数量的增加和业务复杂性的提高,他们面临以下挑战:
- 监控复杂性:公司的业务涉及多个层面,包括网络、云服务、应用程序等,需要一个全面的监控系统来实时追踪各个层面的性能和状态。
- 性能问题难定位:当出现性能问题或故障时,需要能够快速准确地定位问题的根本原因,以便及时采取措施解决问题。
- 团队生产力:每次出现故障时需要拉起开发、运维、测试协作排查,偶现的故障很难复现,团队生产协作效率低下。
为什么选择观测云
在与市面上的可观测性产品对比以及和观测云团队深入交流之后,决定选择观测云 POC 测试。在 POC 测试期间,观测云产品表现出色。我们能够更好地了解系统的状态,快速定位问题,并采取措施解决。观测云的综合性能监控和安全监控功能为我们的运维团队提供了强大的工具,帮助我们确保系统的稳定性和安全性。我们期待将观测云集成到我们更多的系统和环境中,以持续提高我们的监控和安全性能。
观测云使用现状
截止目前,已经接入了 3 大 Kubernetes 集群,涉及 7 个 S 级项目和应用。主要接入的语言和框架有 Java、PHP、.NET、Python、Nuxt.js、Vue.js 等,同时还涵盖了 API 网关、数据库、消息队列等中间件产品。覆盖了平台的 APM、RUM、日志、监控、拨测、仪表盘、DataFlux Function 等绝大部分功能。基于目前良好的使用体验,未来还会逐步增加其他应用数据接入。
成功案例
借助观测云实现真正意义上的全链路可观测
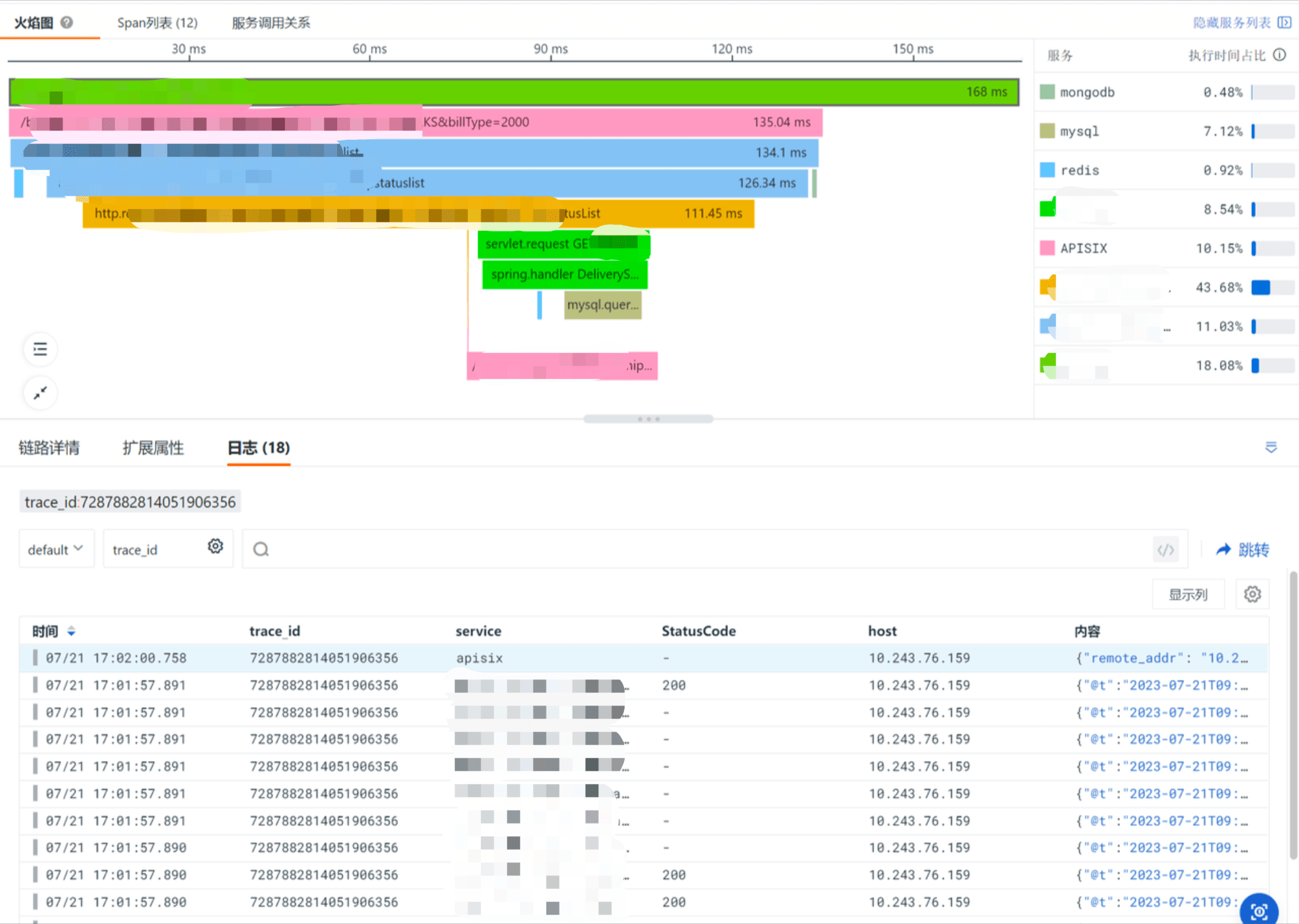
在一个相对复杂的系统中,一个前端的接口请求会经过很多的服务和中间件,比如我们其中的一个系统,由前端发起的 HTTPS 请求,经过 Nginx 路由到网关服务,网关服务到后端服务 A 再调用服务 B,期间还会调用 Redis、Kafka、MySQL 等中间件。整个调用的链路较为复杂,所以我们的基本诉求就是能够实现完整的全链路可观测性,其次出现故障的时候,能够有足够的上下文信息来定位故障。
观测云提供全链路可观测的能力,可以将前端、网关、Nginx、后端服务、中间件等整条链路的信息通过一个 trace_id 全部串起来,这样做的好处是不管哪里出现故障可以快速定位到具体的服务或中间件。下图为服务链路拓扑图,可以查看整个链路的调用情况,点击任一服务的图标可以进入该服务的链路调用详情列表,从而实现快速排障。
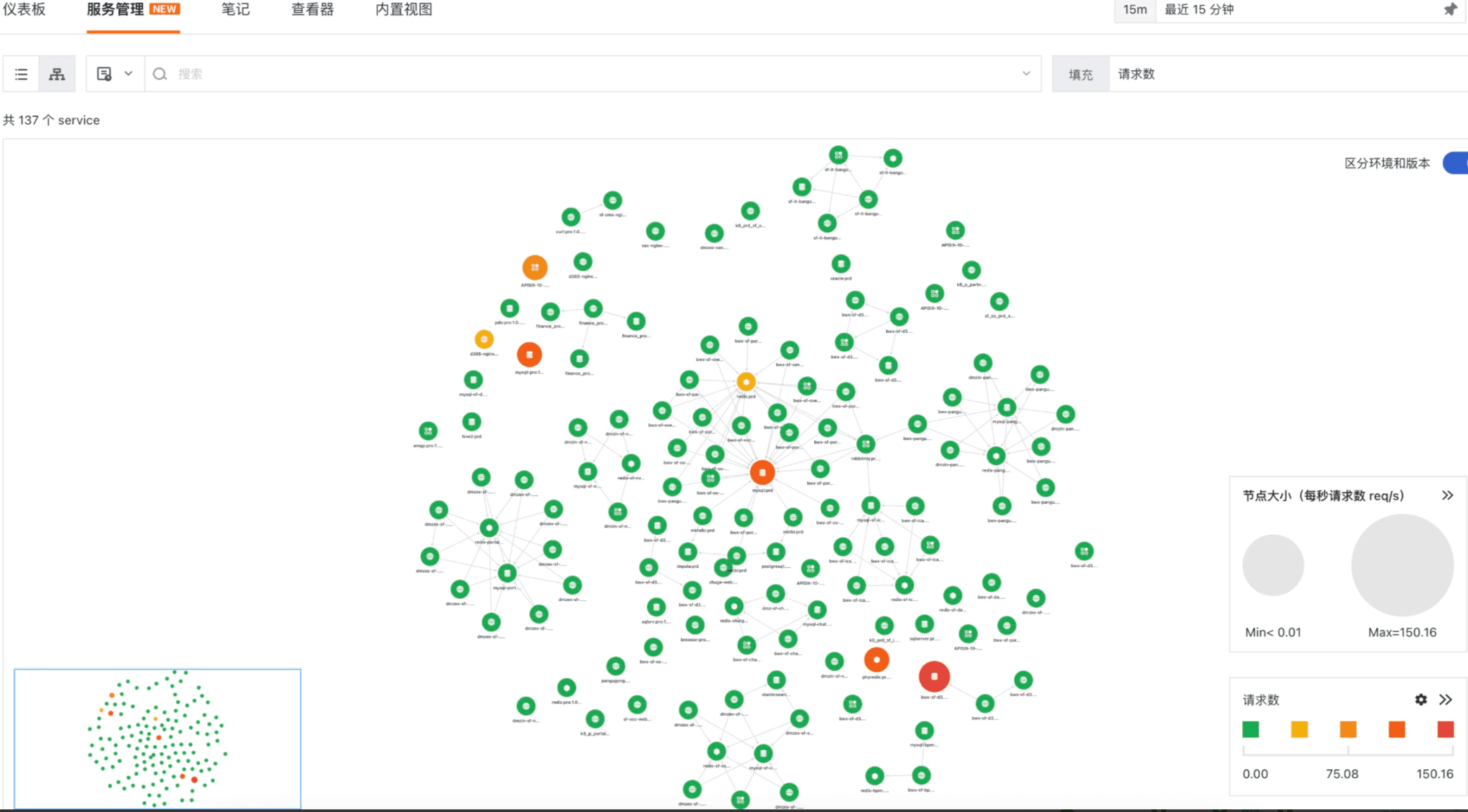
同时也可以在日志上注入 trace_id、span_id 等信息,这样可以实现调用链和日志关联,在出现故障的服务链路中可以快速跳转至相关联的日志,查询日志的上下文,从而实现 RUM-APM-LOG 全链路监测与联动分析。
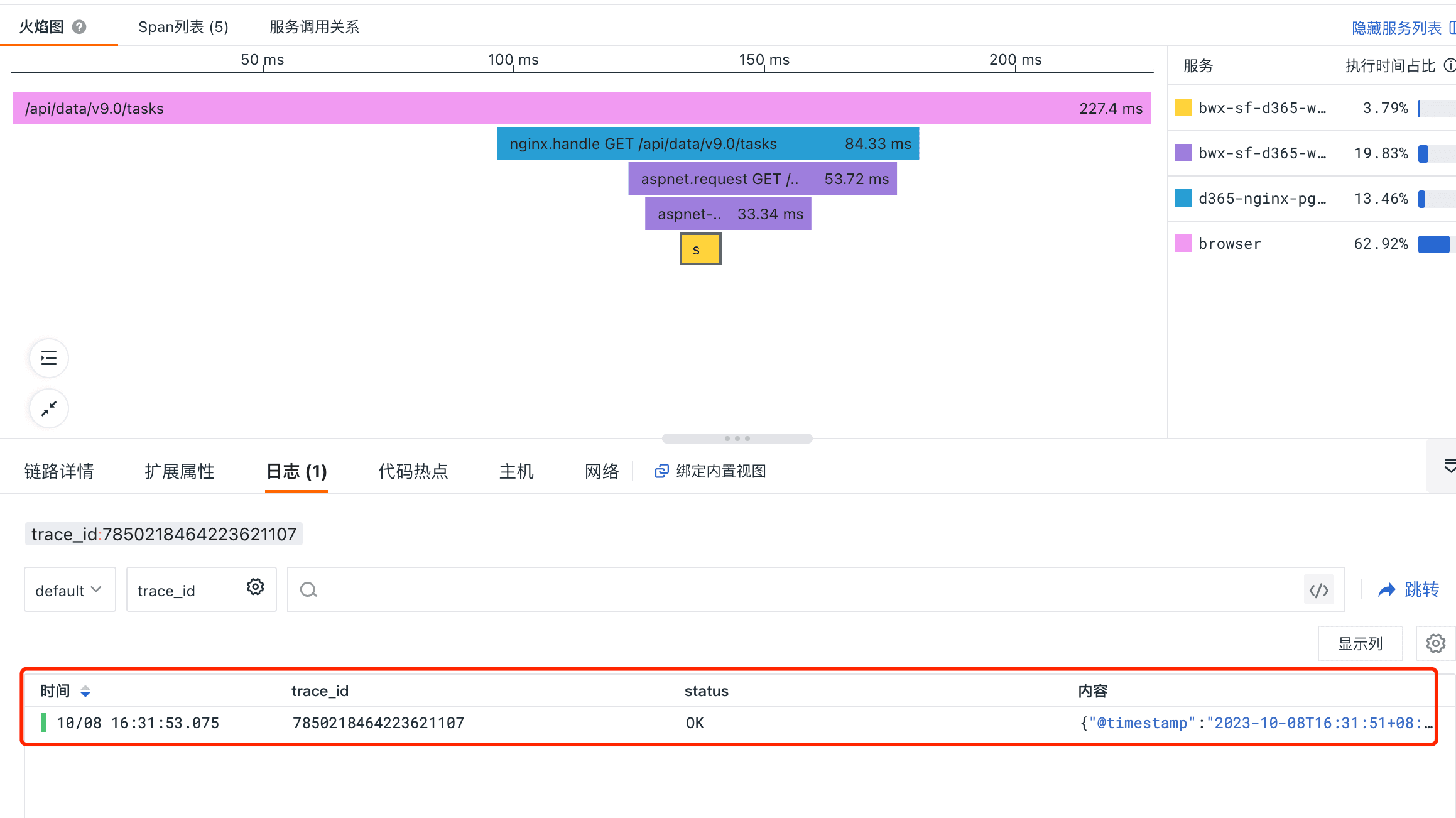
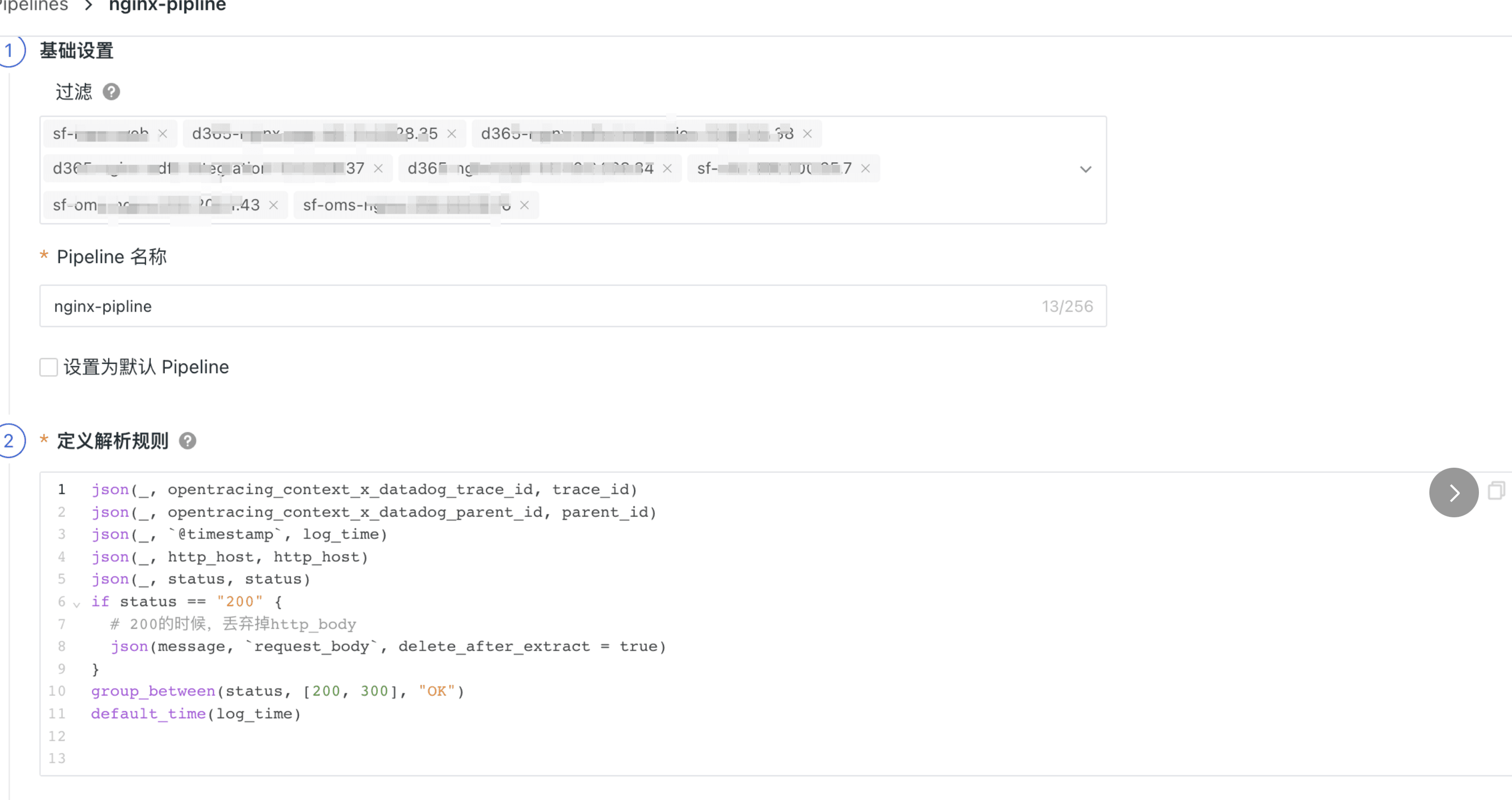
传统的 APM 监测工具都无法保留接口调用的参数,在排查故障的时候,研发和运维往往需要当时接口故障时请求的实际参数来推测复现故障过程,这类上下文信息对我们推广全链路可观测性平台非常重要。但是如果把所有请求接口的参数都进行保留,产生的数据量又非常大,而且一般我们只关注非 200 状态的接口信息。观测云提供的 Pipeline 能力,可以很好的对日志进行解析并过滤掉不需要的日志,我们将接口的 payload 信息打印至 Nginx 日志,并且通过 Pipeline 进行判断只采集非 200 状态的 payload,从而很好的支撑我们故障排查时的诉求。
官网借助观测云能力优化页面卡顿问题
在没有接入观测云之前,官网存在较为严重的卡顿现象,严重影响用户体验。但是没有具体可量化的数据,不知道哪里慢了,也就无从下手去优化。我们将官网前后端接入观测云 RUM 和 APM 之后,可以通过观测云查看当前性能情,就可以很直观的查看出是哪些接口耗时长,哪些页面加载慢。
发现了问题是第一步,接下来该怎样解决问题。为了解决性能问题,从如下几个方面着手:
1、每天在平台上抓取一部分慢接口让开发团队优化,可以查看具体的链路,根据这条 trace 信息可以定位到是哪些 span 耗时长。可能是 SQL 语句、也可能是自身业务代码逻辑等等,根据定位到的信息再去优化。
2、在平台用户行为分析查看 LCP 指标,针对 LCP 加载时间长的页面进行着重优化。
3、创建自定义拨测任务,全面监测不同地区到官网地址的网络性能、网络质量、网络数据传输稳定性等状况。
在优化了一段时间之后,发现到达一个瓶颈期。大部分接口耗时下去了,但是前端耗时还是较为严重,有很多的 longtask 和 error 数据。后来邀请了观测云的前端技术专家专门做了一期 RUM 知识培训和官网系统诊断,于是又找到了前端的优化方向,具体的优化点有:
1、通过观测云,先看阻塞了页面渲染的文件,试用以下条件搜索,查找出阻塞页面渲染的文件

如果对业务非常重要的资源,改为内联的方式,而非外部脚本;如果对业务不敏感的资源,可以选择 defer 加载或者延迟加载,即脚本放在 body 的后面,加属性 defer 或者 async,防止阻塞页面渲染。
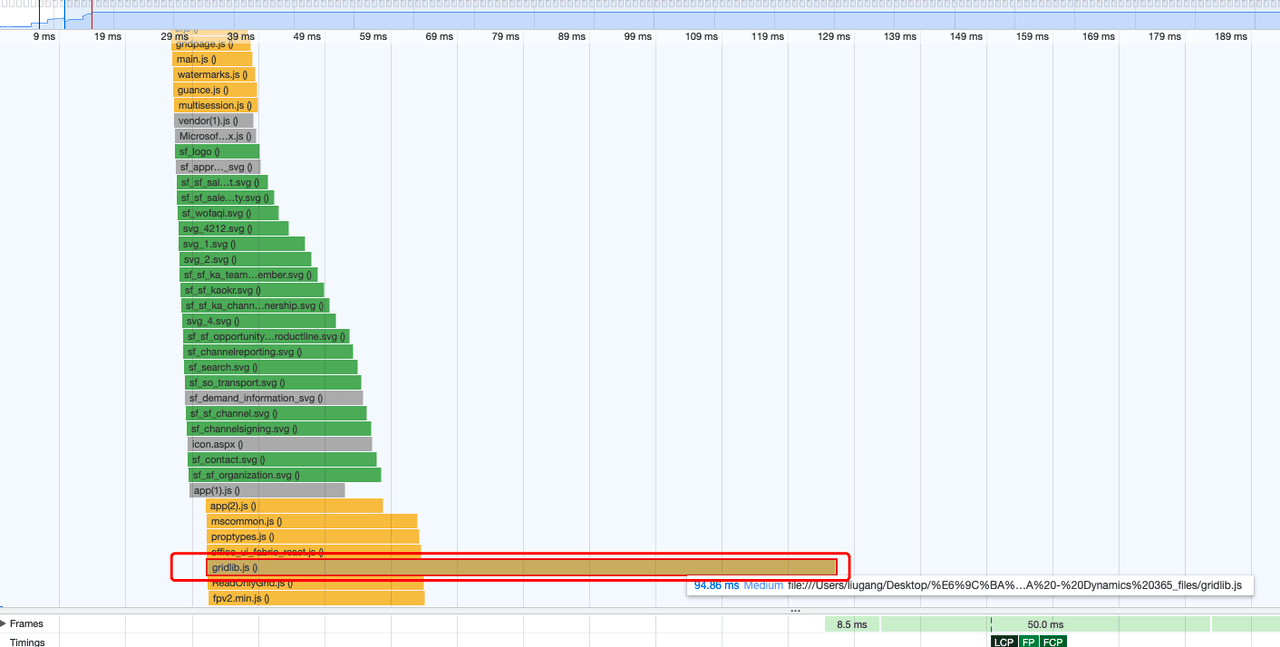
2、网站资源加载的瀑布图
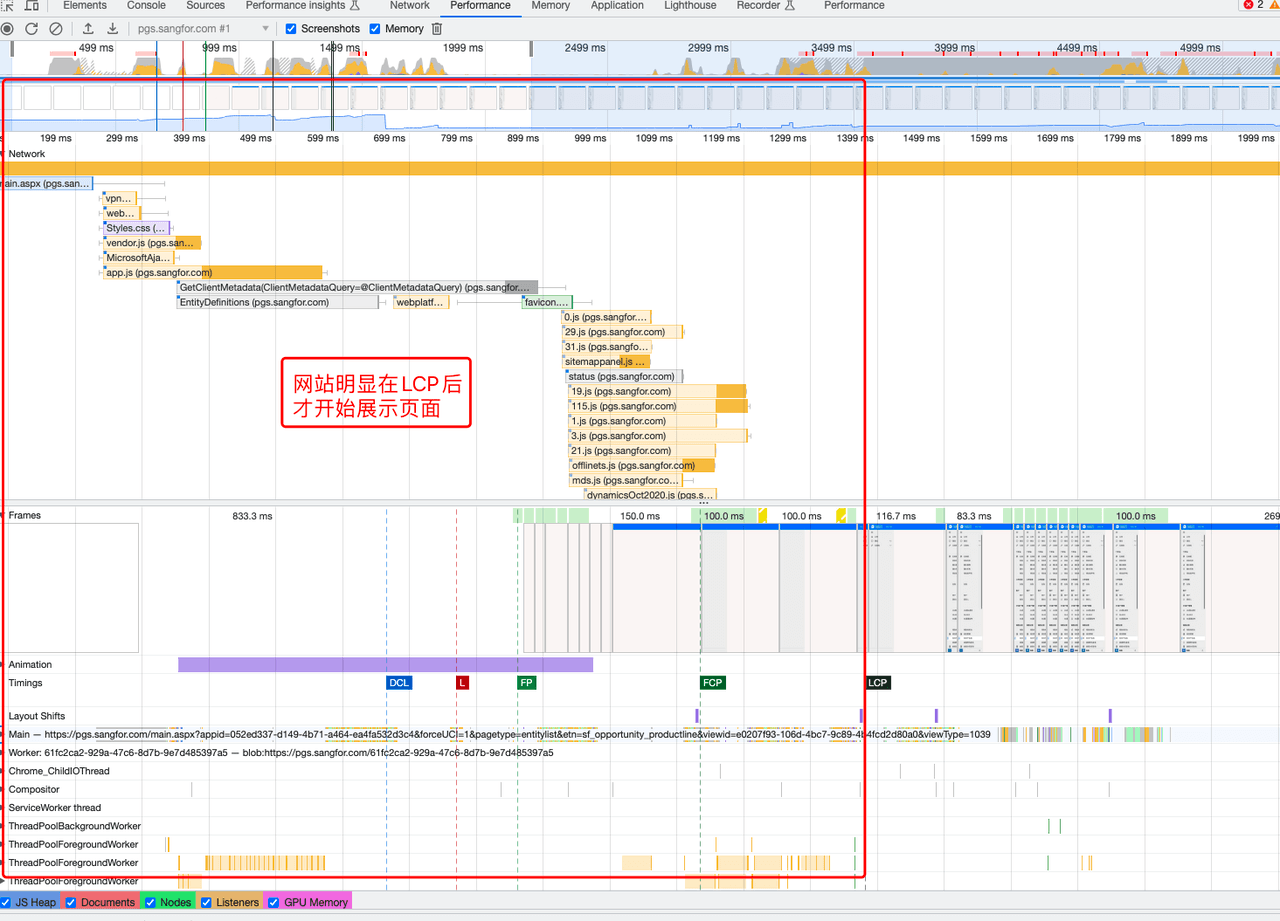
从图中可以得知,首页资源加载多,加载存在延迟,占比约 50% ,累计导致体感慢,弱网环境尤为明显。
具体优化思路为:先整体优化资源加载;优化资源加载中的瓶颈;减少资源体积或者压缩代码;减少资源重复加载等等。
总之,性能优化从来不是一蹴而就的事情,是一个循序渐进的过程。在优化的过程中,我们也借助观测云 RUM 监控发现了很多开发和测试过程中的问题,这样也能提高整个团队的认知和对代码的严谨度,受益颇多。
通过 APISIX 可观测性实现快速排障
APISIX 作为南北向流量 API 网关,承载着从客户端到服务端的全部流量。如果可以实现针对 APISIX 可观测性,那么可以实现很快速的定位到故障。观测云支持 APISIX 的数据接入,APISIX 的 Trace、Logging、Metric 数据可以通过插件的方式上报至 DataKit 及观测云平台,从而实现 APISIX 的可观测性。
| 种类 | 接入方式(插件) |
|---|---|
| Trace | opentelemetry 插件,可用于根据 OpenTelemetry specification 协议规范上报 Tracing 数据。 |
| Logging | file-logger 插件,可用于将日志数据存储到指定位置。console 输出方式,修改访问日志格式 access_logger_format |
| Metric | prometheus 插件,以规定的格式上报指标到 Prometheus 中。 |
在集成 APISIX 的 Trace、Logging、Metric 数据上报之后,开发人员和运维团队更好地了解和监控其应用程序的行为,带来的好处有:
1、快速的问题分析和故障排除。
2、根据 Metric 和 Trace 等信息进行有效的性能优化。
3、配置相应的监控告警规则,当有流量异常时可以尽早识别并扩缩容。
作者|深信服运维技术专家 ——何智杰
观测云技术客户经理——杨文伟