大家好,我是蓝胖子,关于性能分析的视频和文章我也大大小小出了有一二十篇了,算是已经有了一个系列,之前的代码已经上传到github.com/HobbyBear/performance-analyze 接下来这段时间我将在之前内容的基础上,结合自己在公司生产上构建监控系统的经验,详细的展示如何对线上服务进行监控,内容涉及到的指标设计,软件配置,监控方案等等你都可以拿来直接复刻到你的项目里,这是一套非常适合中小企业的监控体系。
在前一节,我们指标这种监控手段完成了机器层级的监控,通过它可以知道机器层面性能的瓶颈在哪里。后续本该讲讲应用层面监控,但是应用监控离不开日志打印,所以今天还是先介绍监控系统的另一种手段,日志监控。
我们会用到Elfk方案进行日志监控,Elfk是Elasticsearch,logstash,filebeat,kibana的缩写,Elasticsearch用于搜索,filebeat和logstash用于日志收集,kibana用于展示。
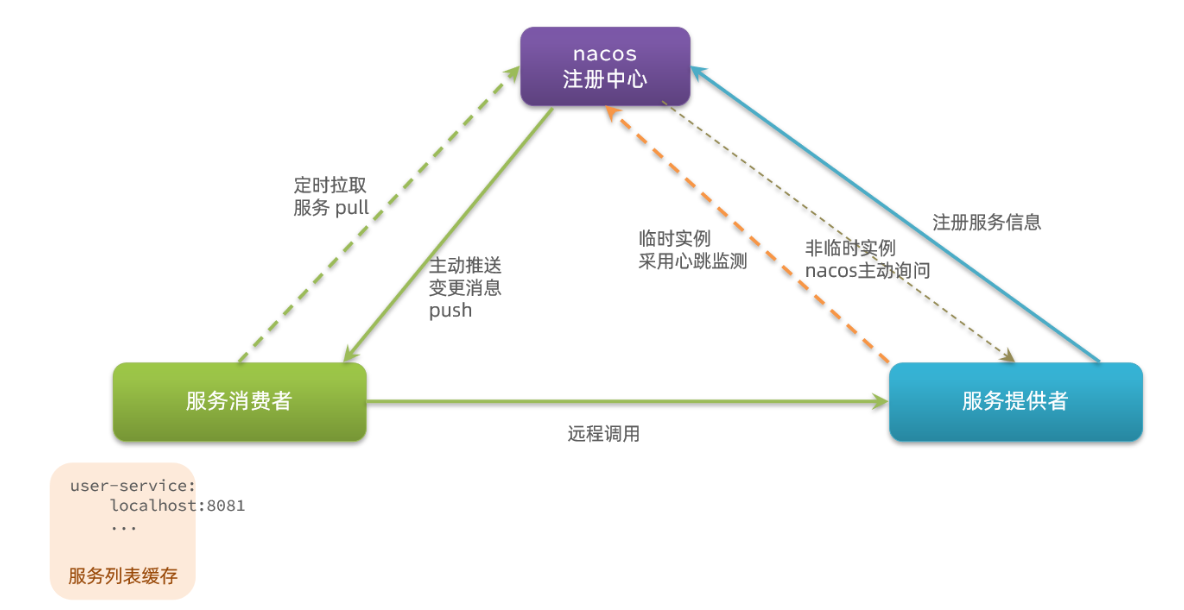
整个日志收集的架构图如下:
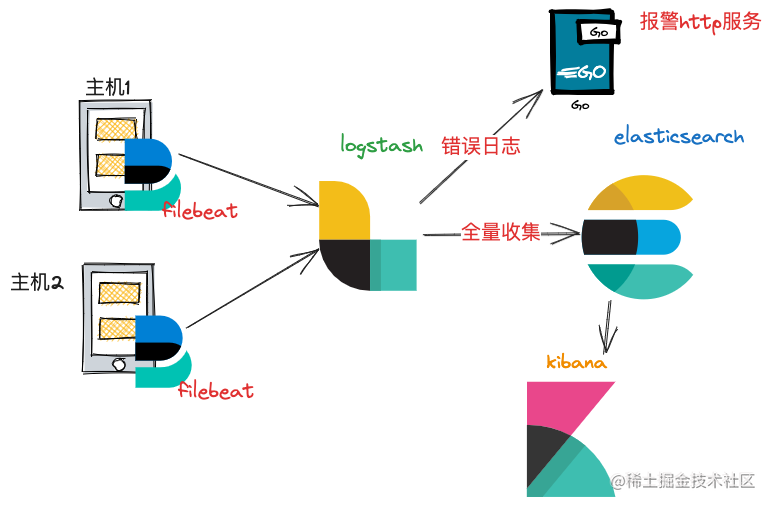
每台运行应用程序的服务器上面,我们都会装上一个filebeat的软件用于日志收集,收集到的日志会发送到logstash里,logstash会全量发往es中,并且将日志等级为error的日志发往报警服务进行报警。
为什么filebeat和logstash同时都有采集日志的功能,不单独使用某一个?因为需要同时将日志输出到多个输出源,filebeat插件只能定义一个输出源,所以采用了logstash,而又因为logstash占用资源比较大,每个物理机都部署一个logstash消耗较大,所以采用物理机部署filebeat, logstash单独部署,做日志过滤,输出的功能。
了解了整个日志采集分析架构后,我们来详细看下日志采集相关的配置文件。
关于kibana和elasticsearch的组件我们不用过多的配置, 需要注意的是filebeat和logstash的配置,它涉及到日志的采集规则。
项目代码已经上传到github
github.com/HobbyBear/easymonitor
下面我们着重来看下filebeat的配置文件。
日志采集配置文件
filebeat.yml 配置
在主机上我们有个filebeat的yml文件,用于对filebeat配置输入输出源以及采集时的资源消耗进行限制。
## filebeat.yml
## 限制单条日志最大字节数
max_bytes: 3145728
## 限制进程最多使用一个cpu核
max_procs: 1
filebeat.config.inputs: enabled: true path: /logconf/*.yml ## 表明将日志发往logstash
output.logstash: hosts: ["logstash:5044"]
我们在使用filebeat进行日志收集时,一定要注意资源的消耗,因为毕竟filebeat和应用程序是在同一台主机上,我们是不该让filebeat对应用程序进行干扰的。所以配置了采集单条日志的最大字节数max_bytes和filebeat能使用的最大cpu核数max_procs为1。
在filebeat.yml 配置里,说明了输入源filebeat.config.inputs 匹配规则是在 logconf目录下的所有yml后缀的文件 里定义的。所以接下来看看logconf目录下的文件。
api.yml 配置
logconf目录下我们写了一个示例api.yml
### api.yml
- type: log tail_files: true paths: - /logs/api*.log fields: log_type: project1
api.yml 配置表面filebeat会收集logs目录下的所有以api开头的log,并且将这些记录都加上一个log_type字段表明记录是哪个项目组或者说产品线的。
filebeat基本就是将日志原封不动的发往了logstash,真正对日志的过滤操作是在logstash里做的。
logstash 配置文件
由于logstash配置文件涉及到日志分析,我这里粘贴下日志的格式,方便后续理解filter相关配置。
{"level":"error","msg":"This is a first log.","time":"2023-07-14T21:56:23.078+08:00","uid":2231}
特别注意: 由于要对日志进行收集分析,最好还是将日志格式打印成json的格式,这便于我们后续的分析操作。
紧接着来看下logstash的配置文件,logstash的配置文件分为3部分,分别是input,filter,output 。
完整配置文件如下:
input { beats { port => 5044 }
}
filter { json { source => "message" target => "parsed_json" }
if [parsed_json][uid] { mutate { add_field => { "uid" => "%{[parsed_json][uid]}" } }
}
mutate { add_field => { "time" => "%{[parsed_json][time]}" } add_field => { "level" => "%{[parsed_json][level]}" } }
date { match => ["time", "yyyy-MM-dd'T'HH:mm:ss.SSSZ"] target => "@timestamp" } mutate { remove_field => [ "parsed_json","time" ] }
}
output { stdout { codec => rubydebug } elasticsearch { hosts => ["http://elasticsearch:9200"] index => "easymonitor-%{[fields][log_type]}-%{+yyyy.MM.dd}" } if [level] == "error" { http { http_method => "post" url => "http://webhookserver:16060/alert_log" } }
}
input 指明了输入来源,filter对日志进行过滤分析操作,output将日志进行输出,且output可以指明多个输出源。
在上面的配置文件里,我指明了输入来源是filebeat,并且发送的目的端口是5044。
然后filter里首先是将filebeat发来的日志转换成json对象,存到一个新字段parsed_json里,filebeat的日志会放到message字段里。接着mutate插件里为日志记录添加了几个字段time(日志时间),uid,level(日志等级),这几个字段都是从parsed_json这个json对象里取出来的,然后用上了date插件,因为我们最后要输出到es里,es里的时间戳字段是@timestamp ,我们需要将日志记录的时间赋值到这个字段上。最后我们在mutate插件里去掉了用于取数据的parsed_json和time字段。
最后就是output部分的配置,我们配置了3个输出源。先是将最后的日志记录打印到了控制台,这是为了方便调试,生产环境可以去掉这个配置。然后是输出到es里,并且索引取名时带上项目组的名称(log_type里存的是项目组的名字)。最后是判断日志的等级,如果是error等级则输出到一个http服务里。这个http服务是为了日志报警使用,开发规范是如果有错误日志必须及时报警到钉钉群里,而这个http的服务的逻辑就是接收错误日志并且发送到钉钉群进行报警处理。
针对多个项目组做日志采集
上述logstash 的配置能体现如何针对多个项目组或者说产品组做日志采集,因为在一台物理主机上有可能会运行多个产品的应用服务,期望的是每个产品组采集的日志索引是不同的,所以在logstash配置文件里,输出到es里的索引名称,我们是这样规定的:
easymonitor-%{[fields][log_type]}-%{+yyyy.MM.dd}
其中索引名里fields.log_type是根据采集的日志归属项目组动态变化的,在api.yml配置的采集规则里,规定了采集/logs/api*.log 下的日志文件,日志记录会带上fields.log_type=project1的标志,所以/logs/api*.log 下的文件输出到es时的索引名是easymonitor-project1-{+yyyy.MM.dd},你完全可以设置其他日志采集规则,配置一个新的采集日志的路径(不同项目组的日志生成路径是不同的)到project2来,这样来达到不同的项目组使用不同的索引名的目的。
这样做的好处在于,提高日志的查询速率,因为各个项目组的日志不太可能相互查询,用不同的索引进行存储,查询时无论是聚合还是过滤都会减少一部分数据量,并且现在我们是将日志都输入到了一台es里,如果某个项目组的日志量过大,将会考虑将这个项目组的日志迁移到新的es里,采用不同的索引名进行项目组的区分也更加容器迁移数据。
对日志的加工过滤
针对于上述logstash 的配置,还有一点十分重要,那就是对日志的加工处理,filebeat如果默认不对日志进行处理,日志将会按换行符进行切割,最终存到es里时,会全部存到message字段里。如下图所示:
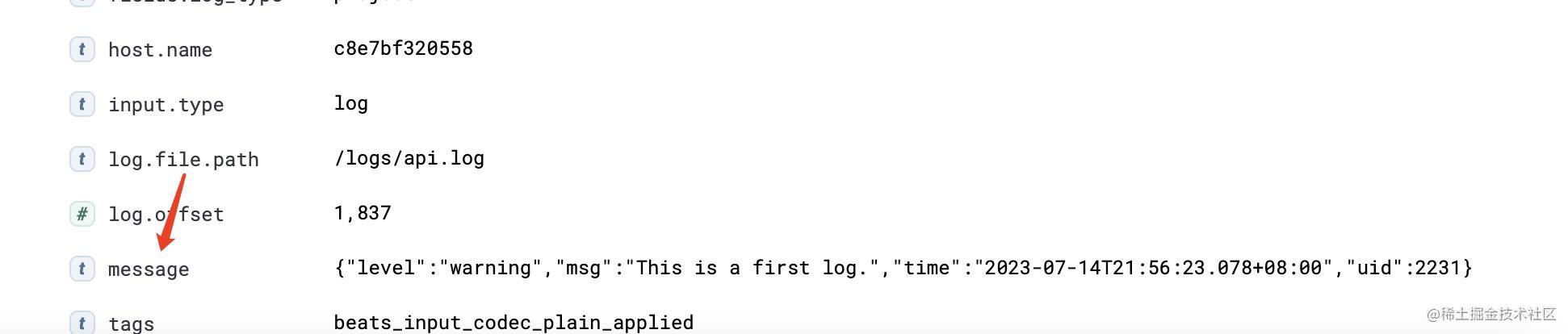
message 字段是text类型 ,是分词存储的,字段类型定义如下:
"message": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }
这意味着有时我们想完整的匹配某段内容时,可能会由于分词规则导致最终搜索不到这个内容,所以我们还需要能够把需要搜索的字段提取出来作为es索引的一个字段,这样才容易进行搜索。提取出来便能成为单独一个字段,es会为其建立索引。
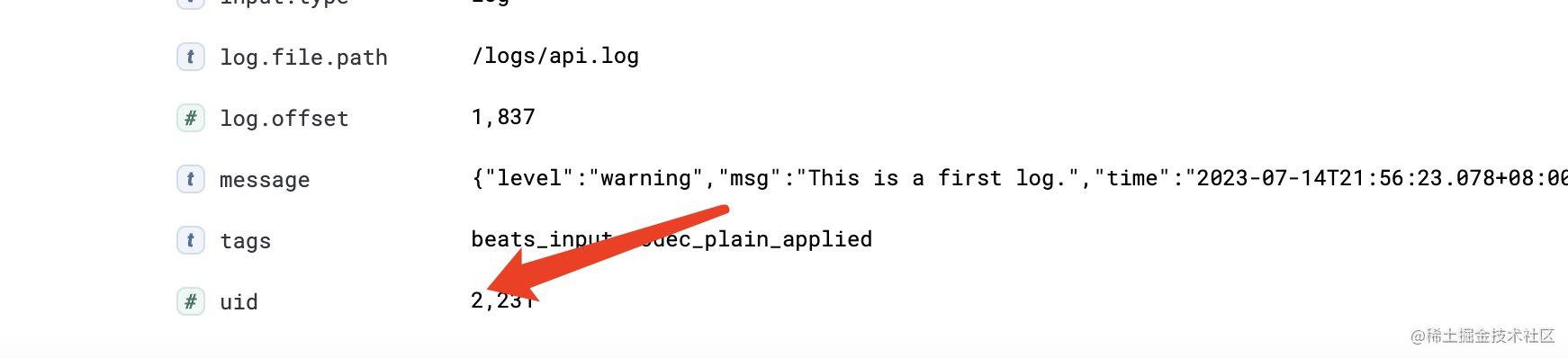
因为uid经常用到,所以就将它提取了出来。
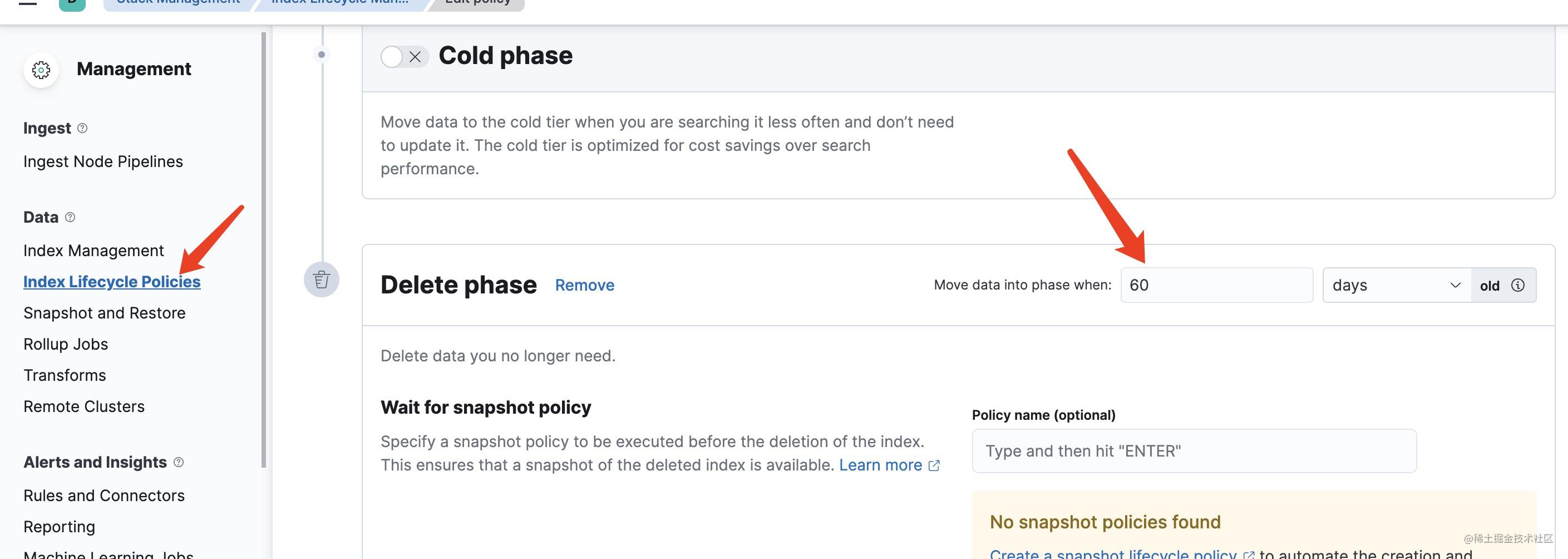
对日志进行生命周期管理
最后再来看看对日志的管理,通常日志保存一段时间就会被删除,这正是和es里索引生命周期的概念一致。
在es里,索引生命周期分为了几个阶段,依次是hot,warm ,cold ,delete阶段 ,delete 阶段可以穿插到任何一个阶段后面,它们挨个的查询频率会降低,我们可以规定一个索引在多少天后或者数据量达到某个值时就由hot阶段进入到了下一个阶段。针对于cold阶段的索引我们甚至可以设置将他们迁移到专门存放cold阶段索引的节点上,通过这样来加速查询与节约成本。
不过在我们的项目里没有设置那么复杂,简单粗暴的设置了索引到达60天后便直接删除了。
总结
总结下,这一节我们完成了EFK组件的搭建与配置,并且详细解释了相关的配置文件和注意事项,再次强调的一点是,别让日志采集占用主机的太多资源,一切以应用程序正常运行为主。
在下一节我将会介绍如何对应用程序进行监控了,这也是我们写应用程序代码比较喜欢关注的地方,下节再见。
在万千人海中,相遇就是缘分,为了这份缘分,给作者点个赞👍🏻不过分吧。