ViveNAS是一个开源的NAS文件服务软件,有一套独立自创的架构,ViveNAS希望能做到下面的目标:
- 能支持混合使用高性能的介质(NVMe SSD)和低性能介质(HDD,甚至磁带)。做到性能、成本动态均衡。因此ViveNAS使用了LSM tree结构,使用其带来的分层能力。
- 能提供文件接口,对象接口统一访问。ViveNAS的中间层 libvivenas 提供了用户态文件语义,方便对象存储对接开发。
- 要方便使用EC进一步降低数据存储的成本,底层数要避免随机写。此目标通过PureFlash的Append only file达到。
- 分布式存储的其他横向扩展、高可用能力,通过底层的PureFlash系统达到。
其结构介绍祥见ViveNAS - 一个基于LSM tree的文件存储实现 (一)_pureflash 元数据-CSDN博客
简单讲,ViveNAS包括了PureFlash后端存储,rocksdb引擎,vivenas文件系统,以及ganesha前端接口四个部分。
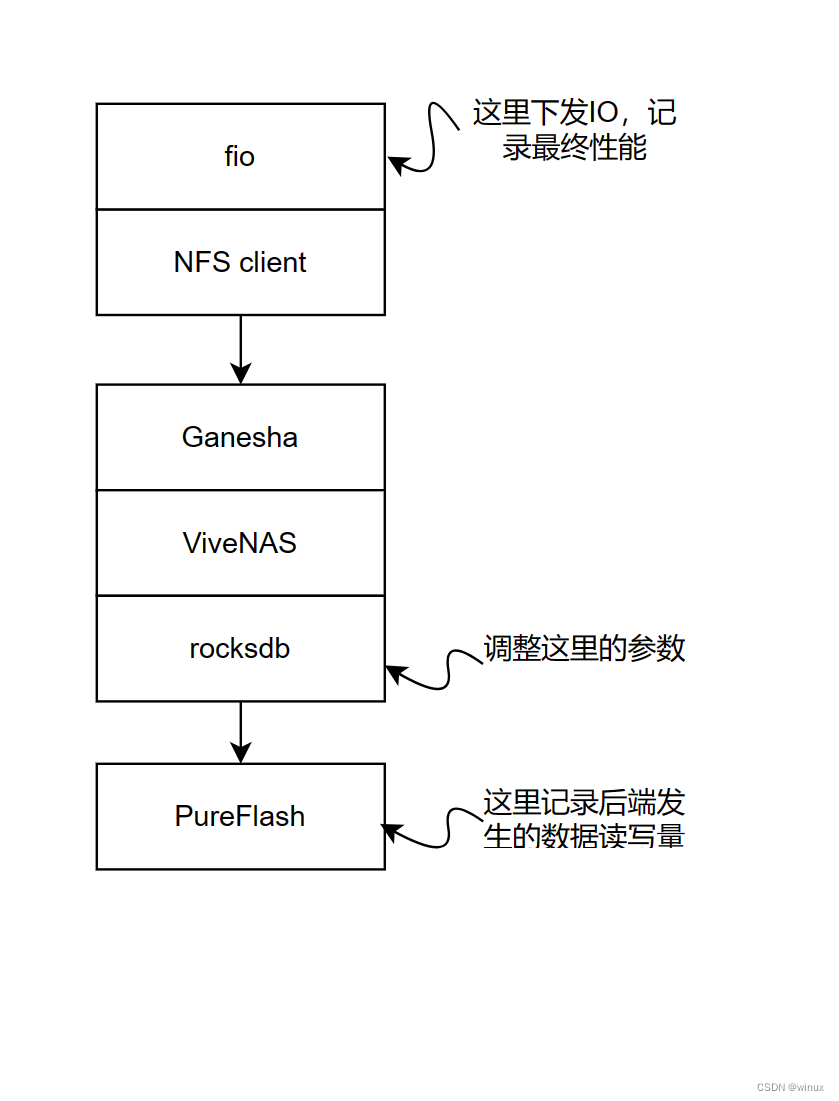
本文记录的是调整rocksdb 的num_levels参数对最终性能的影响。
测试硬件为: 阿里云虚机 ecs.hfr7.3xlarge 12C96G。
为避免后端存储对性能的影响,使用ramdisk代替SSD作为PureFlash的物理盘。
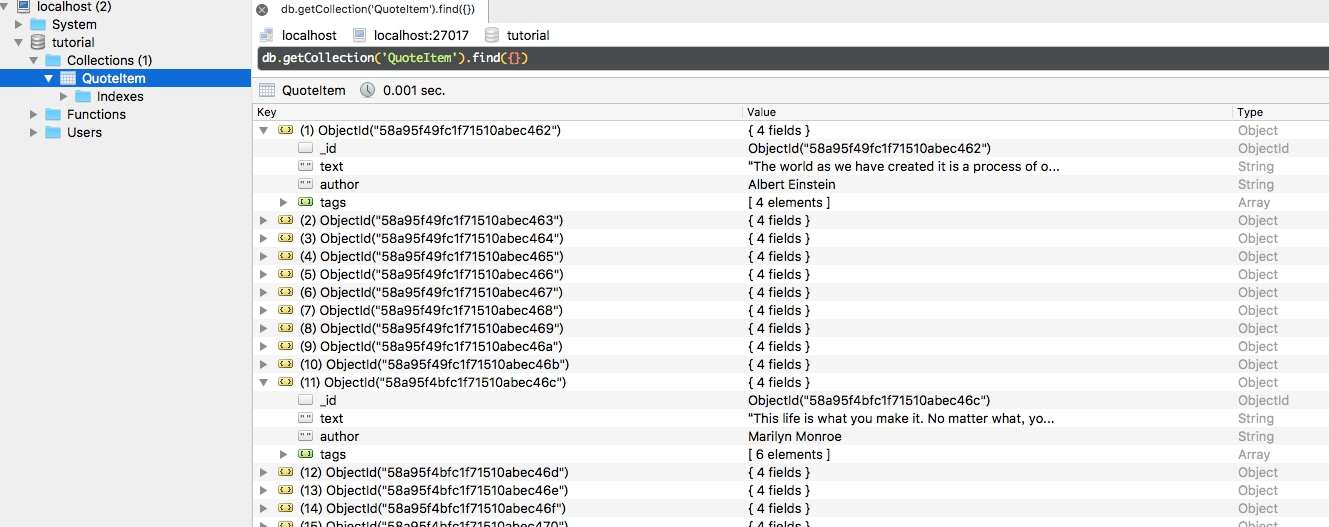
测试操作:
本次进行了三次测试,分别设置data column family 的num_levels 为7,4,2 进行测试(meta column family 一直保持为缺省的7);
测试负载用fio产生,用NFS将ViveNAS文件系统挂载到同一个主机上,对nfs文件系统进行读写。首先 进行一次4K随机写(RW), 然后换不同IO大小进行随机读(RR), fio每次运行30s.
测试脚本详见:ViveNAS/testing/perf-stat.sh at master · cocalele/ViveNAS (github.com)
得到如下的测试结果:

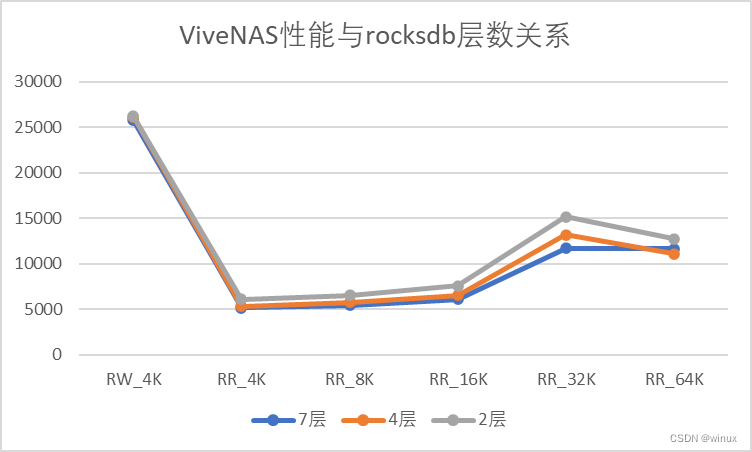
可以看到有这么几个现象:
1) num_levels对初始写的性能影响不大。
2) num_levels对实际造成的底层存储写入量影响也不大,这个还是比较诧异的。
3)num_levels对读操作的影响明显。特别是32K 随机读表现的更为明显。
简单分析一下,
ViveNAS处理大IO读(16K) 比 小IO(4K)性能要好的多。这一点可能跟ViveNAS保存数据以64KB为一个extent有关。无论客户端请求的数据块是4K还是16K,底层都要读取最少64KB数据。
算一下读放大倍数也证实了这点,4K随机读伴随着43倍写放大。32K随机读只有1.7倍,64K随机读更是降低到了0.5倍,也就是大部分数据都在rocksdb或者PureFlash AOF cache处得到了复用。

这个测试结果还是揭示了很多问题,接下来的研究以及改进方向如下:
1. 修改ganesha了worker thread的数量,看其对结果的影响
2. 修改libvivenas的vn_read/vn_write操作为异步的,看其对结果的影响
3. 修改rocksdb Get函数,提供随机读能力,去掉不必要的读放大。