一、依赖,其中ES版本为7.6.2
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>TestHadoop3</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.1</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.6</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.12.3</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.6.2</version></dependency></dependencies></project>
二、定义表示word count 结果的实体类
package cn.edu.tju;import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;public class MyDBWritable implements DBWritable, Writable {private String word;private int count;public String getWord() {return word;}public void setWord(String word) {this.word = word;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}@Overridepublic void write(PreparedStatement statement) throws SQLException {statement.setString(1, word);statement.setInt(2, count);}@Overridepublic void readFields(ResultSet resultSet) throws SQLException {word = resultSet.getString(1);count = resultSet.getInt(2);}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(word);out.writeInt(count);}@Overridepublic void readFields(DataInput in) throws IOException {word = in.readUTF();count = in.readInt();}
}三、定义mapper和reducer
package cn.edu.tju;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private IntWritable one = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String valueString = value.toString();String[] values = valueString.split(" ");for (String val : values) {context.write(new Text(val), one);}}
}package cn.edu.tju;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.Iterator;public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {Iterator<IntWritable> iterator = values.iterator();int count = 0;while (iterator.hasNext()) {count += iterator.next().get();}context.write(key, new IntWritable(count));}
}四、自定义类,实现接口OutputFormat
package cn.edu.tju;import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;import java.io.IOException;public class MyOutputFormat extends OutputFormat<Text, IntWritable> {@Overridepublic RecordWriter<Text, IntWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {return new MyRecordWriter();}@Overridepublic void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {}@Overridepublic OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {NullOutputFormat<NullWritable, NullWritable> format = new NullOutputFormat<>();OutputCommitter outputCommitter = format.getOutputCommitter(context);return outputCommitter;}
}其中getRecordWriter方法返回了一个RecordWriter类的对象。自定义的RecordWriter类如下:
package cn.edu.tju;import com.google.gson.Gson;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;import java.io.IOException;
import java.util.Random;
import java.util.UUID;public class MyRecordWriter extends RecordWriter<Text, IntWritable> {private RestHighLevelClient client;public MyRecordWriter() {client = new RestHighLevelClient(RestClient.builder(HttpHost.create("xx.xx.xx.xx:9200")));}@Overridepublic void write(Text key, IntWritable value) throws IOException, InterruptedException {IndexRequest indexRequest = new IndexRequest("demo6");indexRequest.id(UUID.randomUUID().toString());MyDBWritable myDBWritable = new MyDBWritable();myDBWritable.setWord(key.toString());myDBWritable.setCount(value.get());Gson gson = new Gson();String s = gson.toJson(myDBWritable);indexRequest.source(s, XContentType.JSON);IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println(indexResponse);}@Overridepublic void close(TaskAttemptContext context) throws IOException, InterruptedException {client.close();}
}其中构造方法创建了一个ES 客户端对象。write方法用来把数据写入ES.
五、定义主类
package cn.edu.tju;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;public class MyWordCount6 {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration(true);//hdfs路径configuration.set("fs.defaultFS", "hdfs://xx.xx.xx.xx:9000/");//local 运行configuration.set("mapreduce.framework.name", "local");configuration.set("yarn.resourcemanager.hostname","xx.xx.xx.xx");//configuration.set("mapreduce.job.jar","target\\TestHadoop3-1.0-SNAPSHOT.jar");//job 创建Job job = Job.getInstance(configuration);//job.setJarByClass(MyWordCount.class);//job namejob.setJobName("wordcount-" + System.currentTimeMillis());//输入数据路径FileInputFormat.setInputPaths(job, new Path("/user/root/tju/"));job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setMapperClass(WordCountMapper.class);//job.setCombinerClass(MyCombiner.class);job.setReducerClass(WordCountReducer.class);job.setOutputFormatClass(MyOutputFormat.class);//等待任务执行完成job.waitForCompletion(true);}
}其中 job.setOutputFormatClass(MyOutputFormat.class);用来指定reduce的结果写到哪里。输入数据来自hdfs
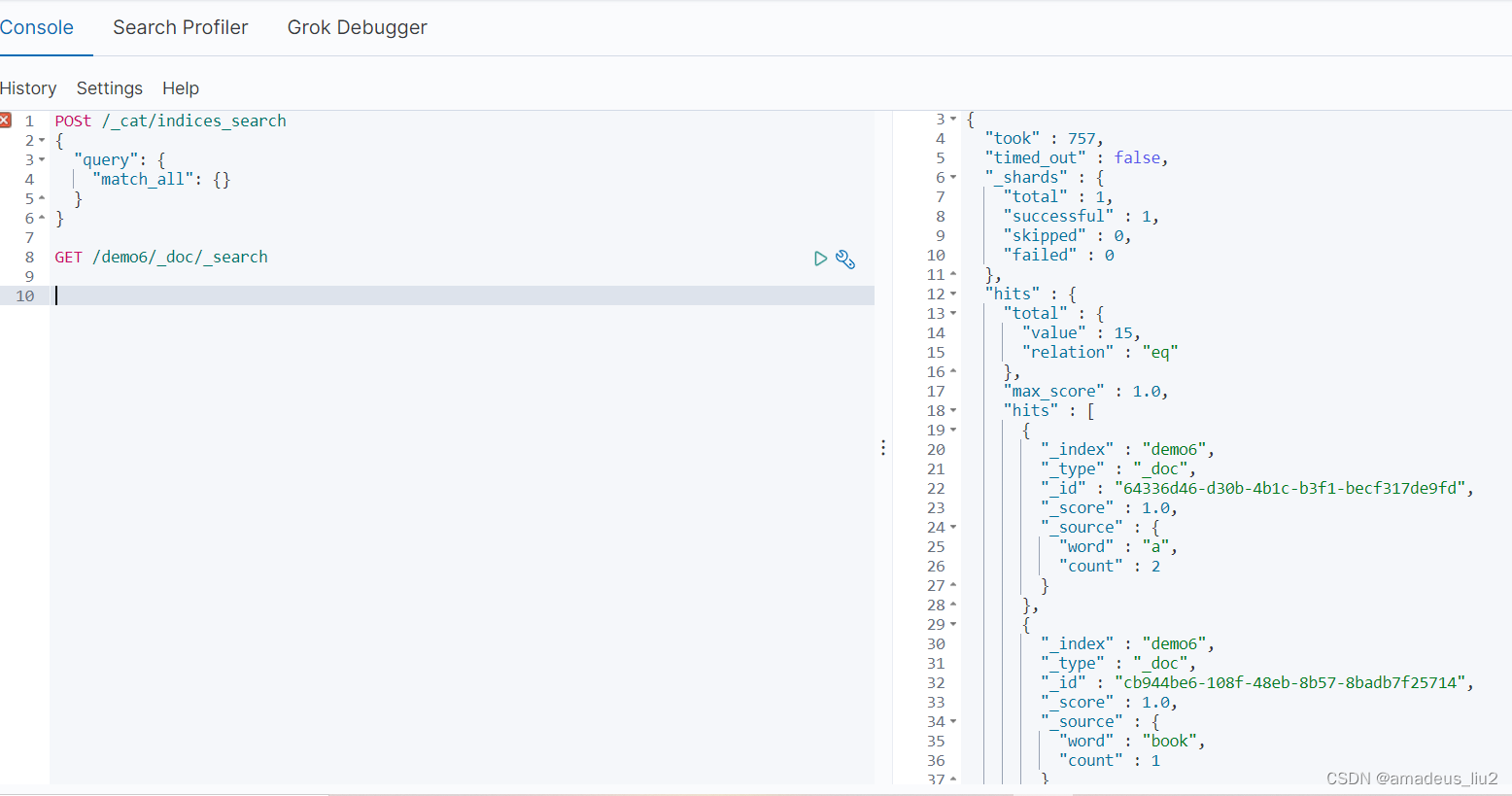
六、任务执行后在ES查询数据