开发过程由本人从 架构设计 到 代码实现 独立完成,通过该博客记录分享开发经验
ZyjDataLink 当前的目标是做到 MySQL大数据量的快速同步,后期希望扩展的功能 高度可操作性,融入增量数据库同步,跨数据库同步
ZyjDataLink 需求分析
在实际开发过程中有一种需求场景,将A服务的数据库数据同步到B服务数据库,同步的方法有两种: 全量数据库同步 和 增量数据库同步
全量同步思路 - 使用定时任务定期将A服务数据库读取出来,同时也将B服务数据库读取出来进行比较获取 更新 、删除 、新增 的数据,然后写入B服务数据库
增量同步思路 - 记录A服务数据库的操作日志,对B数据库进行相同的操作
当前目标仅完成 全量同步
ZyjDataLink 整体设计
大数据量的情况下要求快速全量同步,第一个想到 服务拆分,做到功能模块间异步进行 和 采用集群方式做数据量的拆分
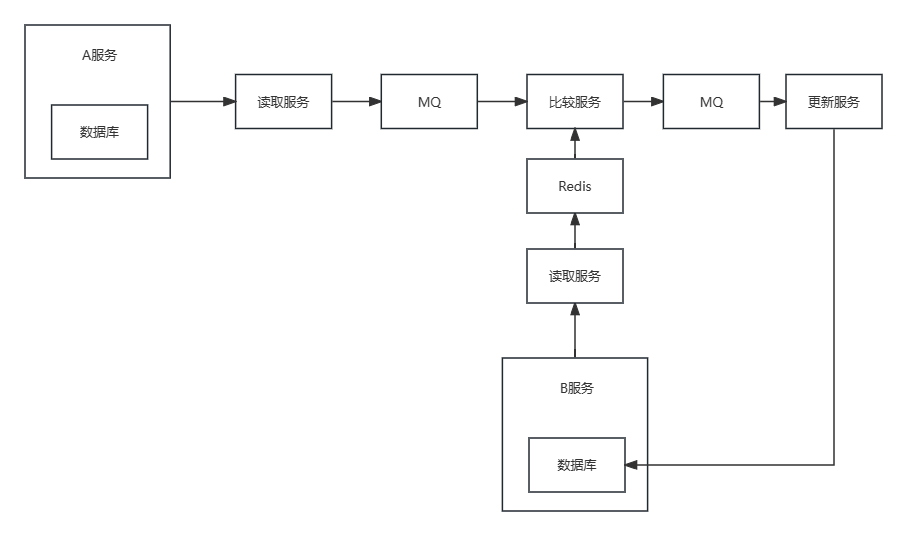
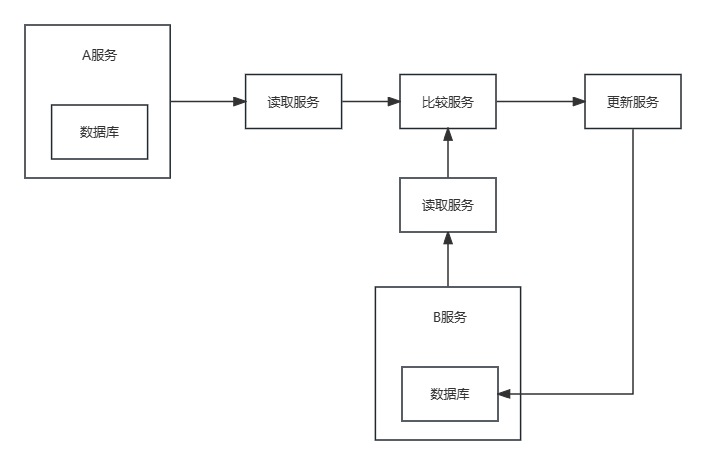
- 服务拆分 - 总体上拆分为 “读” -> “比” -> “写”
“读” - 分别读取出 服务A 和 服务B 的数据
“比” - 逐一比较 两份数据 得到 服务A数据库 相对 服务B数据库 的更新 、删除 、新增 数据
“写” - 根据 获取到的增删改数据 更新 数据库B - 数据拆分 - 做到可集群部署,可同时开启n个“读比写”实例,每个实例处理 <数据总量 / n> 的数据量
ZyjDataLink 详细设计
获取数据
数据拆分读取可以使用 Xxl-Job 的分片任务功能,同一任务中的多个执行器,可以通过XxlJobHelper中的
- getShardTotal 方法 : 获取执行器总数
- getShardIndex 方法 :获取当前执行器的索引
要求 A服务数据库提供一个接口,让 读模块 读取数据,传入的参数是 当前 读服务实例 的索引号 Index 和 读服务实例 的总数 Total
A服务 将 ID 字段对 Total 取模的值等于index的数据读取给 该读服务实例,sql如下
select * from tb_user where id % #{serviceTotal} = #{serviceNum}
另外用相同的方法,读取B服务的数据
比较数据
从A服务中读取的数据可以放在MQ中,从B服务读取的数据可以放在Redis中,比较服务监听MQ,从MQ中获取到数据后和Redis中的数据进行比较
对比思路 - 从MQ获取到数据后,拿着当前数据的id去Redis中获取数据,分两种情况
-
能获取到:能获取到又分为两种情况
- 数据相同:这种情况说明这条数据没有发生改变
- 数据不同:这种情况下说明当前数据发生update
-
不能获取到:不能获取到说明这条数据是insert到A服务数据库中的
如果A服务中的某个数据被删除了,那么比较服务是无法从MQ中获取被删除数据的,但是这条数据会出现在存放B服务数据的Redis中,因此我们需要在进行update和insert的比较过程中,比较一条删除一条,当比较过程结束后,Redis中剩下的数据就是被A服务delete掉的
更新服务
在MQ中创建update、insert、delete三个topic,更新服务监听这三个topic,比较服务将得到的数据放入对应的topic,更新服务获取并修改B服务数据库
因此更进一步精细PPT架构图如下