目录
- 一、文献阅读
- 1.1 摘要
- 1.2 论文背景
- 1.3 论文背景
- 1.4 视频处理特征传播
- 1.5 论文方法
- 二、相关代码
一、文献阅读
论文标题:Object Detection in Videos by High Quality Object Linking
1.1 摘要
与静态图像中的目标检测相比,视频中的目标检测由于图像质量下降而更具挑战性。许多以前的方法都通过链接视频中的相同对象以形成管状结构,并在管状结构中聚合分类得分,从而利用时间上下文信息。这些方法首先使用静态图像检测器来检测每帧中的对象,然后根据不同帧中对象框之间的空间重叠情况或预测相邻帧之间的对象移动情况,来链接这些检测到的对象。
在本文中,我们专注于获得高质量的对象链接结果以实现更好的分类。与以前通过检查相邻帧之间的框来链接对象的方法不同,我们建议在同一帧中链接。为了实现这一目标,我们在以下方面扩展了现有方法:(1)长方体提议网络,提取限制对象运动的时空候选长方体; (2)短tubelet检测网络,检测短视频片段中的短tubelet; (3)短管连接算法,其将时间上重叠的短管连接成长管。在 ImageNet VID 数据集上的实验表明,我们的方法优于静态图像检测器和之前的技术水平。特别是,对于快速移动的物体,我们的方法比静态图像检测器的结果提高了 8.8%。
1.2 论文背景
由于物体运动,同一物体在相邻帧中的位置和外观会发生变化,这可能导致相邻帧中同一物体的边界框之间的空间重叠不足,或者预测的对象移动不够准确。这会影响对象链接的质量,特别是对于快速移动的对象。相比之下,在同一帧内,如果两个边界框有足够的空间重叠,那么它们显然对应于同一物体。基于这些事实,我们提出在同一帧内链接对象,而不是在相邻帧之间,以实现高质量的对象链接。
许多以前的方法都通过链接视频中的相同对象以形成管状结构,并在管状结构中聚合分类得分,从而利用时间上下文信息。这些方法首先使用静态图像检测器来检测每帧中的对象,然后根据不同帧中对象框之间的空间重叠情况或预测相邻帧之间的对象移动情况,来链接这些检测到的对象。
1.3 论文背景
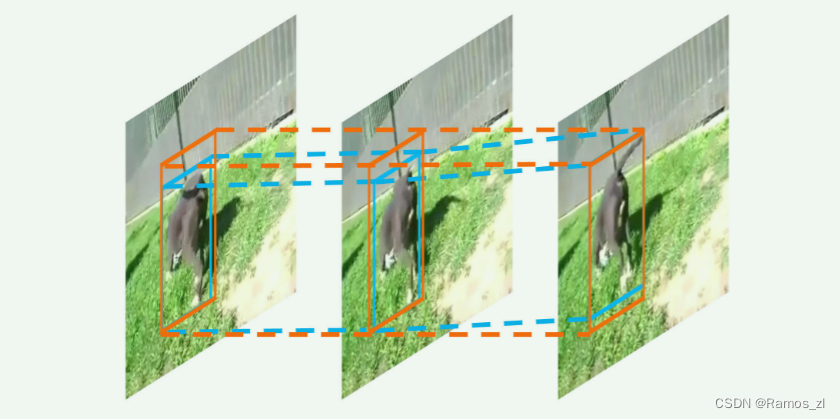
首先将长视频分割成一些时间上重叠的短视频片段。对于每个短视频片段,我们通过将静态图像的区域提议网络 扩展为短视频片段的立方体提议网络,提取出一组立方体提议,即时空候选立方体,它们能够界定对象的运动。位于同一立方体中的跨帧对象被视为同一对象。立方体提议的主要好处是能够在同一帧中实现对象链接,并且它本身就能带来较小的检测性能提升。
这里的静态图像区域提议网络(Region Proposal Network,RPN)是一种用于生成目标候选区域的深度神经网络结构,它通常与卷积神经网络(CNN)结合使用,以在静态图像中识别可能包含目标对象的区域。RPN的核心思想是通过在CNN特征图上的滑动窗口来生成一系列候选区域(也称为锚点或提议)。这些滑动窗口在特征图的不同位置和尺度上进行遍历,每个位置都生成多个不同尺度和长宽比的候选区域。每个候选区域都通过RPN输出一个分数,表示该区域包含目标对象的可能性,以及该区域的精确边界框坐标。RPN通常与Fast R-CNN或Faster R-CNN等目标检测算法结合使用。在这些算法中,RPN首先生成候选区域,然后这些区域被送入后续的卷积层进行分类和边界框回归,以得到最终的目标检测结果。RPN的设计使得目标检测算法能够高效地生成高质量的候选区域,从而提高了检测速度和精度。它已经成为了现代目标检测算法中不可或缺的一部分,并在许多计算机视觉任务中取得了显著的效果。
对于每个立方体提议,我们调整Fast R-CNN来检测短管状物体。更具体地说,我们分别计算每帧中精确的边界框位置和分类得分,形成一个短管状物体,代表短视频片段中链接的对象边界框。我们通过聚合跨帧的边界框分类得分来计算管状物体的分类得分。此外,为了去除空间上冗余的短管状物体,我们将标准的非极大值抑制(NMS)扩展为管状物体重叠测量,这可以防止在逐帧NMS中可能发生的管状物体断裂。通过短管状物体考虑短距离时间上下文有助于检测。
最后,我们将具有足够重叠度的跨时间重叠的短视频片段中的短管状物体进行链接。如果两个盒子来自于两个相邻短管状物体的时间重叠帧(即同一帧),并且具有足够的空间重叠度,则这两个对应的短管状物体会被链接并合并。这里的“盒子”指的是在某一帧中检测到的对象的边界框。如果两个来自相邻短管状物体的盒子(即两个边界框)在时间上重叠的帧(即同一帧)中有足够的空间重叠,那么它们可能代表的是同一个对象。我们利用对象链接来提高分类质量,通过聚合链接管状物体的分类得分来提升正检测的分类得分。

1.4 视频处理特征传播
- 特征传播无对象链接
特征传播是一种技术,用于增强当前帧的特征信息。这通常是通过聚合从相邻帧中传播过来的特征来实现的。这样的方法有助于提升视频处理的准确性,因为它考虑了时间上的连续性,使得每一帧的特征信息不再孤立。无对象链接没有执行对象链接。对象链接是指将不同帧中检测到的同一对象进行关联,形成一个连贯的轨迹。这种链接有助于更准确地识别和跟踪视频中的对象。因此,尽管这些特征传播方法可以增强当前帧的特征信息,但它们并没有利用对象链接来进一步提升性能。 - 带对象链接的特征传播
管状物体提议网络首先通过在第一帧中生成静态对象提议,然后预测后续帧中这些对象的相对运动,来计算管状物体。通过使用CNN-LSTM网络,将管状物体中盒子的特征传播到每个盒子进行分类。除了无对象链接的特征传播外,还链接了相邻帧中的对象以进行特征传播。更具体地说,预测当前帧中每个提议在相邻帧中的相对运动,并将相邻帧中盒子的特征通过平均池化传播到当前帧中对应的盒子。与这些方法不同,我们在同一帧中链接对象,并在帧之间传播盒子得分而不是特征。此外,我们直接为视频片段生成时空立方体提议,而不是像中那样生成每帧提议。 - 带对象链接的得分传播。
第一种方式追踪当前帧中检测到的盒子到其相邻帧,以增强它们的原始检测结果,从而提高对象召回率。同时,得分也被传播以改善分类准确性。这种链接是基于盒子内的平均光流向量。第二种方式使用跟踪算法将对象链接成长管状物体,然后采用分类器来聚合管状物体中的检测得分。Seq-NMS方法通过检查相邻帧中盒子之间的空间重叠来链接对象,而不考虑运动信息,然后聚合链接对象的得分作为最终得分。在中的方法同时预测两个帧中的对象位置以及从前一帧到当前帧的对象运动。然后,他们使用这些运动信息将检测到的对象链接成管状物体。同一管状物体中的对象检测得分通过以某种方式聚合该管状物体中的得分来重新加权。
1.5 论文方法
阶段一:为短视频片段生成立方体提议
在这个阶段,系统针对每一个短视频片段(这些片段是原始视频在时间上的分段,且相互之间存在重叠部分),生成一组立方体(或称为容器)。这些立方体旨在跨越多帧绑定相同的对象,即它们表示了对象在连续帧中的可能位置和范围。这些立方体提议是后续处理的基础,帮助系统确定哪些区域可能包含需要关注的对象。
阶段二:短视频片段的短管状物体检测
在有了立方体提议之后,系统进入第二个阶段。对于每一个立方体提议,系统尝试回归(即调整边界框的位置和大小以更准确地匹配对象)并分类一个短管状物体。这个短管状物体实际上是一个边界框的序列,每个边界框都对应视频中的一帧,并定位了那一帧中的对象。为了避免冗余和重叠,系统还会使用非极大值抑制技术来去除那些在空间上过于接近的短管状物体。这些短管状物体代表了短视频片段中对象跨帧的连续存在。
阶段三:整个视频的短管状物体链接
在完成了前两个阶段之后,系统进入第三个阶段,即链接整个视频中的短管状物体。由于视频被分为了时间上重叠的短视频片段,每个片段都生成了自己的短管状物体。在这一阶段,系统需要将这些时间上重叠的短管状物体连接起来,以形成跨整个视频的对象轨迹。这样做可以确保对象在整个视频中的连续性和一致性。同时,通过链接短管状物体,系统还可以进一步优化和细化对象的分类得分,提高对象检测的准确性。
综上,这三个阶段构成了一个完整的视频对象检测与链接流程。前两个阶段为对象检测提供了基础,而第三个阶段则确保了对象在整个视频中的连续跟踪和准确分类。这种方法的优点在于它能够处理视频中的时间连续性和对象运动,从而提高了对象检测的准确性和可靠性。
二、相关代码
yolov5检测代码如下:
import argparse
import time
from pathlib import Pathimport cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import randomfrom models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronizeddef detect(save_img=False):source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_sizesave_img = not opt.nosave and not source.endswith('.txt') # save inference imageswebcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))# Directoriessave_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir# Initializeset_logging()device = select_device(opt.device)half = device.type != 'cpu' # half precision only supported on CUDA# Load modelmodel = attempt_load(weights, map_location=device) # load FP32 modelstride = int(model.stride.max()) # model strideimgsz = check_img_size(imgsz, s=stride) # check img_sizeif half:model.half() # to FP16# Second-stage classifierclassify = Falseif classify:modelc = load_classifier(name='resnet101', n=2) # initializemodelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()# Set Dataloadervid_path, vid_writer = None, Noneif webcam:view_img = check_imshow()cudnn.benchmark = True # set True to speed up constant image size inferencedataset = LoadStreams(source, img_size=imgsz, stride=stride)else:dataset = LoadImages(source, img_size=imgsz, stride=stride)# Get names and colorsnames = model.module.names if hasattr(model, 'module') else model.namescolors = [[random.randint(0, 255) for _ in range(3)] for _ in names]# Run inferenceif device.type != 'cpu':model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run oncet0 = time.time()for path, img, im0s, vid_cap in dataset:img = torch.from_numpy(img).to(device)img = img.half() if half else img.float() # uint8 to fp16/32img /= 255.0 # 0 - 255 to 0.0 - 1.0if img.ndimension() == 3:img = img.unsqueeze(0)# Inferencet1 = time_synchronized()pred = model(img, augment=opt.augment)[0]# Apply NMSpred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)t2 = time_synchronized()# Apply Classifierif classify:pred = apply_classifier(pred, modelc, img, im0s)# Process detectionsfor i, det in enumerate(pred): # detections per imageif webcam: # batch_size >= 1p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.countelse:p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)p = Path(p) # to Pathsave_path = str(save_dir / p.name) # img.jpgtxt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txts += '%gx%g ' % img.shape[2:] # print stringgn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwhif len(det):# Rescale boxes from img_size to im0 sizedet[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()# Print resultsfor c in det[:, -1].unique():n = (det[:, -1] == c).sum() # detections per classs += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string# Write resultsfor *xyxy, conf, cls in reversed(det):if save_txt: # Write to filexywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywhline = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label formatwith open(txt_path + '.txt', 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n')if save_img or view_img: # Add bbox to imagelabel = f'{names[int(cls)]} {conf:.2f}'plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)# Print time (inference + NMS)print(f'{s}Done. ({t2 - t1:.3f}s)')# Stream resultsif view_img:cv2.imshow(str(p), im0)cv2.waitKey(1) # 1 millisecond# Save results (image with detections)if save_img:if dataset.mode == 'image':cv2.imwrite(save_path, im0)else: # 'video' or 'stream'if vid_path != save_path: # new videovid_path = save_pathif isinstance(vid_writer, cv2.VideoWriter):vid_writer.release() # release previous video writerif vid_cap: # videofps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))else: # streamfps, w, h = 30, im0.shape[1], im0.shape[0]save_path += '.mp4'vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))vid_writer.write(im0)if save_txt or save_img:s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''print(f"Results saved to {save_dir}{s}")print(f'Done. ({time.time() - t0:.3f}s)')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcamparser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--view-img', action='store_true', help='display results')parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')parser.add_argument('--nosave', action='store_true', help='do not save images/videos')parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')parser.add_argument('--augment', action='store_true', help='augmented inference')parser.add_argument('--update', action='store_true', help='update all models')parser.add_argument('--project', default='runs/detect', help='save results to project/name')parser.add_argument('--name', default='exp', help='save results to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')opt = parser.parse_args()print(opt)check_requirements(exclude=('pycocotools', 'thop'))with torch.no_grad():if opt.update: # update all models (to fix SourceChangeWarning)for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:detect()strip_optimizer(opt.weights)else:detect()运行结果如图: