1 调试代码
if __name__ == '__main__' :config = ModelArgs(dim=8, n_layers=2, n_heads=32, n_kv_heads=32, vocab_size=32000, hidden_dim=None, multiple_of=256, norm_eps=1e-05, max_seq_len=3, dropout=0.0)model = Transformer(config)input_tokens = torch.randint(0, 32000, (1, 3)) # 单个样本,序列长度为128output_logits = model(input_tokens)print(f"Output logits shape: {output_logits.shape}")
2 关键代码
2.1 embedding层
参考
# 调用
h = self.tok_embeddings(tokens)
作用:
用于将离散的单词或标签等转换成一个固定大小的连续向量
ord_indexes 包含了词汇表中的单词索引,embedding_layer 创建了一个嵌入矩阵,每一行代表一个单词的向量。当索引通过嵌入层时,它会返回相应的词向量。
这段代码演示了如何创建一个 nn.Embedding 模块,并使用它来将一个包含索引的张量转换为相应的嵌入向量。具体步骤和作用解释如下:
创建 Embedding 模块:
embedding = nn.Embedding(10, 3)
这一行代码创建了一个 nn.Embedding 模块实例,参数设定如下:
num_embeddings=10表示词汇表大小,即有 10 个不同的单词(或其他离散符号)各自对应一个嵌入向量。
embedding_dim=3表示每个嵌入向量的维度为 3,即每个单词将被映射为一个三维向量。
在创建过程中,模块会自动初始化这些嵌入向量,通常使用随机分布(如均值为 0、标准差为 1 的正态分布)生成初始值。
准备输入数据:
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
这里定义了一个形状为 (2, 4) 的张量 input,代表一个包含两个样本(样本数为 2,即第一维大小)的批次,每个样本由四个整数索引组成(第二维大小)。这些索引表示词汇表中的单词位置,例如:
第一个样本包含单词索引 1, 2, 4, 5。
第二个样本包含单词索引 4, 3, 2, 9。
应用 Embedding 模块
embedding(input)
将 input张量传递给 embedding模块,执行前向传播。embedding 模块会根据 input中的每个索引来查找并返回对应的嵌入向量。输出结果是一个形状为 (2, 4, 3)的张量,含义如下:
第一维仍保持原来的样本数,即有 2 个样本。
第二维与输入相同,表示每个样本包含的单词数(这里是 4 个)。
第三维度对应嵌入向量的维度,即每个单词被映射为一个长度为 3 的向量。
输出张量的具体数值是根据 embedding模块内部存储的嵌入向量随机初始化值计算得出的。由于这些值是随机初始化的,所以示例中的具体数值(如 -0.0251, -1.6902, 0.7172等)是非确定性的,每次运行可能会有所不同。
tensor([[[-0.0251, -1.6902, 0.7172],[-0.6431, 0.0748, 0.6969],[ 1.4970, 1.3448, -0.9685],[-0.3677, -2.7265, -0.1685]],[[ 1.4970, 1.3448, -0.9685],[ 0.4362, -0.4004, 0.9400],[-0.6431, 0.0748, 0.6969],[ 0.9124, -2.3616, 1.1151]]])
综上所述,这段代码的作用是利用 nn.Embedding模块将一批离散的单词索引(代表文本数据中的单词序列)转换为连续的嵌入向量,这些向量可以被后续的神经网络层(如 LSTM、Transformer 或全连接层等)进一步处理,以便进行诸如文本分类、情感分析、机器翻译等自然语言处理任务。
2.2 旋转矩阵的cos、sin
参考
参考
# 调用
freqs_cos = self.freqs_cos[:seqlen]
freqs_sin = self.freqs_sin[:seqlen]
# 定义
# 参数:params.dim:8,params.n_heads:2,max_seq_len:3
freqs_cos, freqs_sin = precompute_freqs_cis(self.params.dim // self.params.n_heads, self.params.max_seq_len)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)
# 定义
# dim=4,end=3,theta=10000
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))t = torch.arange(end, device=freqs.device) # type: ignorefreqs = torch.outer(t, freqs).float() # type: ignorefreqs_cos = torch.cos(freqs) # real partfreqs_sin = torch.sin(freqs) # imaginary partreturn freqs_cos, freqs_sin
作用:
参考
这种旋转操作可以看作是将词向量在复数空间中进行旋转,旋转的角度由位置决定。这样,位置信息就被直接编码到了词向量的方向上,而不仅仅是它的大小。
2.2.1 theta
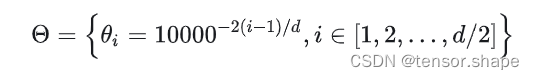
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
torch.arange(0, dim, 2):生成一个从0开始、步长为2、直到但不包括 dim 的整数序列。
**[:(dim // 2)]:**选取该序列的前 dim // 2 个元素。
**.float():**将整数序列转换为浮点数序列。
**(torch.arange(0, dim, 2)[: (dim // 2)].float() / dim):**将浮点数序列中的每个元素除以 dim 进行归一化,得到归一化频率分量。
theta (…):对归一化频率分量进行指数运算,其中指数是 theta,这是频率衰减因子。
1.0 / (…):计算每个频率分量的倒数,得到最终的频率向量 freqs。
**即freq = 1/(10000^(2i/d)) i=d/2
形式化为 [theta_0, theta_1, …, theta_(d/2-1)]
计算词向量元素两两分组之后,每组元素对应的旋转角度theta_i
输出tensor([1.0000, 0.0100])
**
2.2.2 m
t = torch.arange(end, device=freqs.device) # type: ignore
计算m,tensor([0, 1, 2])
2.2.3 m*theta
freqs = torch.outer(t, freqs).float() # type: ignore
计算t与freqs的外积,即m * theta
输出二维矩阵
tensor([[0.0000, 0.0000],[1.0000, 0.0100],[2.0000, 0.0200]])
参考
freqs形式化为 [mtheta_0, mtheta_1, …, m*theta_d/2],其中 m=0,1,…,length-1
每个theta都有m列个角度
2.2.4 正余弦值
freqs_cos = torch.cos(freqs) # real part
freqs_sin = torch.sin(freqs) # imaginary part
return freqs_cos, freqs_sin
计算正余弦值,方便2.3.1节的
xq_out_r = xq_r * freqs_cos - xq_i * freqs_sin
xq_out_i = xq_r * freqs_sin + xq_i * freqs_cos
xk_out_r = xk_r * freqs_cos - xk_i * freqs_sin
xk_out_i = xk_r * freqs_sin + xk_i * freqs_cos
公式与下面结论是一致的。

2.3 Attention
2.3.1 ROPE
# 调用
# RoPE relative positional embeddings
xq, xk = apply_rotary_emb(xq, xk, freqs_cos, freqs_sin)
# 定义
def apply_rotary_emb(xq: torch.Tensor,xk: torch.Tensor,freqs_cos: torch.Tensor,freqs_sin: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:# reshape xq and xk to match the complex representationxq_r, xq_i = xq.float().reshape(xq.shape[:-1] + (-1, 2)).unbind(-1)xk_r, xk_i = xk.float().reshape(xk.shape[:-1] + (-1, 2)).unbind(-1)# reshape freqs_cos and freqs_sin for broadcasting# 用于调整 freqs_cis 张量的形状,以便与输入张量 x 进行有效的广播运算。freqs_cos = reshape_for_broadcast(freqs_cos, xq_r)freqs_sin = reshape_for_broadcast(freqs_sin, xq_r)# apply rotation using real numbersxq_out_r = xq_r * freqs_cos - xq_i * freqs_sinxq_out_i = xq_r * freqs_sin + xq_i * freqs_cosxk_out_r = xk_r * freqs_cos - xk_i * freqs_sinxk_out_i = xk_r * freqs_sin + xk_i * freqs_cos# flatten last two dimensionsxq_out = torch.stack([xq_out_r, xq_out_i], dim=-1).flatten(3)xk_out = torch.stack([xk_out_r, xk_out_i], dim=-1).flatten(3)return xq_out.type_as(xq), xk_out.type_as(xk)
1.1)
# reshape xq and xk to match the complex representation
xq_r, xq_i = xq.float().reshape(xq.shape[:-1] + (-1, 2)).unbind(-1)
xk_r, xk_i = xk.float().reshape(xk.shape[:-1] + (-1, 2)).unbind(-1)
reshape(xq.shape[:-1]
意味着保持所有轴(维度)不变,除了最后一个轴。
(-1, 2) 是新形状的一部分,表示最后两个维度。其中 -1 表示自动计算该维度的大小以保持元素总数不变;2 指定新增的维度大小为 2。
这个操作将原张量 xq 最后一个维度的元素拆分为两个新的维度,每个新维度的大小分别为自动计算的值和固定的 2,即last----[x,2]。
unbind 函数沿着指定的维度(这里是最后一个维度,索引为 -1)将张量分解为多个子张量。在本例中,由于我们重塑后的张量最后一维大小为 2,这一步将会得到两个子张量,分别对应于实部和虚部。
q就分成实部和虚部了,同理也有k
1.2)
xq_out = torch.stack([xq_out_r, xq_out_i], dim=-1).flatten(3)xk_out = torch.stack([xk_out_r, xk_out_i], dim=-1).flatten(3)return xq_out.type_as(xq), xk_out.type_as(xk)
[1,3,2,4]---------------[1,3,2,2]
2.3.2 kv cache
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xvkeys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(keys, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()
1)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
确保缓存键值张量 self.cache_k 和 self.cache_v 在数据类型和设备上与查询张量 xq 保持一致。
2)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
通过这两行代码,实现了对缓存键值张量 self.cache_k 和 self.cache_v 的局部更新。具体来说,将当前批次的键张量 xk 和值张量 xv 存储到缓存中相应的位置,同时保留了缓存中之前批次的键值对信息。这种设计允许模型在处理长序列时,利用之前批次的上下文信息,实现跨批次的注意力计算。
3)
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
从缓存键张量 self.cache_k 和缓存值张量 self.cache_v 中提取当前批次所需的部分
4)
根据需要对键值张量进行重复处理,确保其头数与全局头数一致。repeat_kv 函数实现了张量在特定维度上的重复操作,用于满足自注意力机制中头数的要求。
参考
改进之后,我们GPT根据【天王盖地虎,】生成【宝】,同时还有KV(天王盖地虎,),然后根据KV(天王盖地虎,)和【宝】生成【塔】以及KV(天王盖地虎,宝),以此类推。
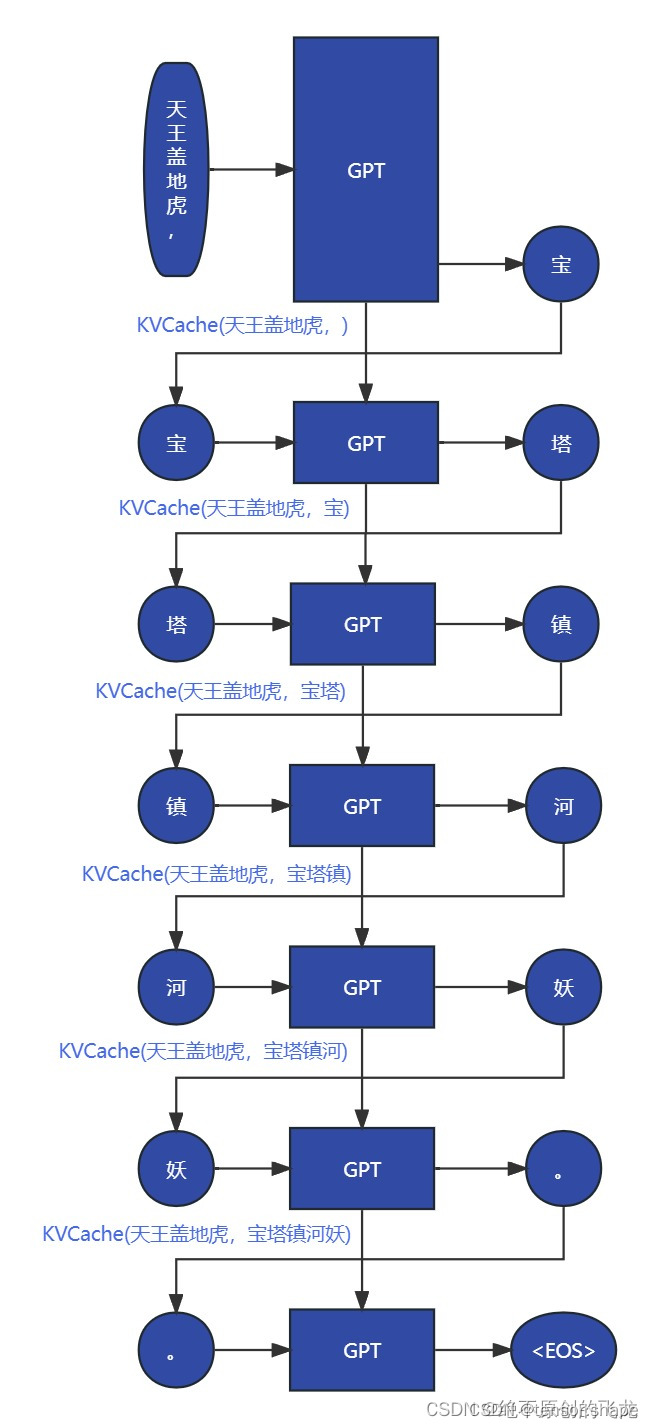
因此,我们可以保存(即缓存)并重复使用先前迭代中的键和值向量(译者注:原文是“query vectors”,可能是作者笔误,此处译者修改为“值向量”)。这种优化简单地被称为 KV 缓存。为“is ”计算输出表征将会变得非常简单。