1最接近的三数之和
给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。
返回这三个数的和。
假定每组输入只存在恰好一个解。
示例 1:
输入:nums = [-1,2,1,-4], target = 1 输出:2 解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
示例 2:
输入:nums = [0,0,0], target = 1 输出:0
思路:
-
排序:首先对输入数组进行排序,这样可以使得相同的数字相邻,并且有利于后续的查找和处理过程。
-
遍历:遍历排序后的数组,对每个元素作为基准,使用双指针技巧来找到与目标值最接近的三个数的和。
-
双指针:在每次遍历中,设置两个指针,一个从当前元素的下一个位置开始,另一个从数组末尾开始。这两个指针向中间移动,以便在遍历过程中快速定位和处理。
-
计算和比较:计算当前三个数的和,并与目标值进行比较。根据比较结果,移动指针以调整三个数的选择,使得和尽可能接近目标值。
-
更新答案:在每次计算得到一个三个数的和之后,比较当前和与目标值之间的绝对差与当前答案与目标值之间的绝对差。如果当前和更接近目标值,则更新答案为当前和。
-
返回结果:最终返回找到的最接近目标值的三个数的和作为结果。
代码:
class Solution {
public:int threeSumClosest(vector<int>& nums, int target) {// 初始化答案为前三个数字的和int ans = nums[0] + nums[1] + nums[2];// 对输入数组进行排序sort(nums.begin(), nums.end());// 遍历数组for (int i = 0; i < nums.size(); i++) {// 设置两个指针,一个在数组起始,一个在数组末尾int start = i + 1, end = nums.size() - 1;// 将指针向中间移动while (start < end) {// 计算三个数字的和int sum = nums[start] + nums[end] + nums[i];// 如果和等于目标值,则返回目标值if (sum == target) return target;// 如果当前和与目标值的绝对差小于当前答案与目标值的绝对差,// 则更新答案为当前和if (abs(sum - target) < abs(ans - target)) ans = sum;// 根据当前和与目标值的比较,移动指针if (sum < target) start++;else end--;}}// 返回找到的最接近目标值的和return ans;}
};2电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例 1:
输入:digits = "23" 输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
示例 2:
输入:digits = "" 输出:[]
示例 3:
输入:digits = "2" 输出:["a","b","c"]
提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。
回溯算法思路:
从示例上来说,输入"23",最直接的想法就是两层for循环遍历了吧,正好把组合的情况都输出了。
如果输入"233"呢,那么就三层for循环,如果"2333"呢,就四层for循环.
此时又是回溯法登场的时候了。
理解本题后,要解决如下三个问题:
- 数字和字母如何映射
- 两个字母就两个for循环,三个字符我就三个for循环,以此类推,然后发现代码根本写不出来
- 输入1 * #按键等等异常情况
数字和字母如何映射
可以使用map或者定义一个二维数组,例如:string letterMap[10],来做映射,我这里定义一个二维数组,代码如下
const string letterMap[10] = {"", // 0"", // 1"abc", // 2"def", // 3"ghi", // 4"jkl", // 5"mno", // 6"pqrs", // 7"tuv", // 8"wxyz", // 9
};
回溯法来解决n个for循环的问题
例如:输入:"23",抽象为树形结构,如图所示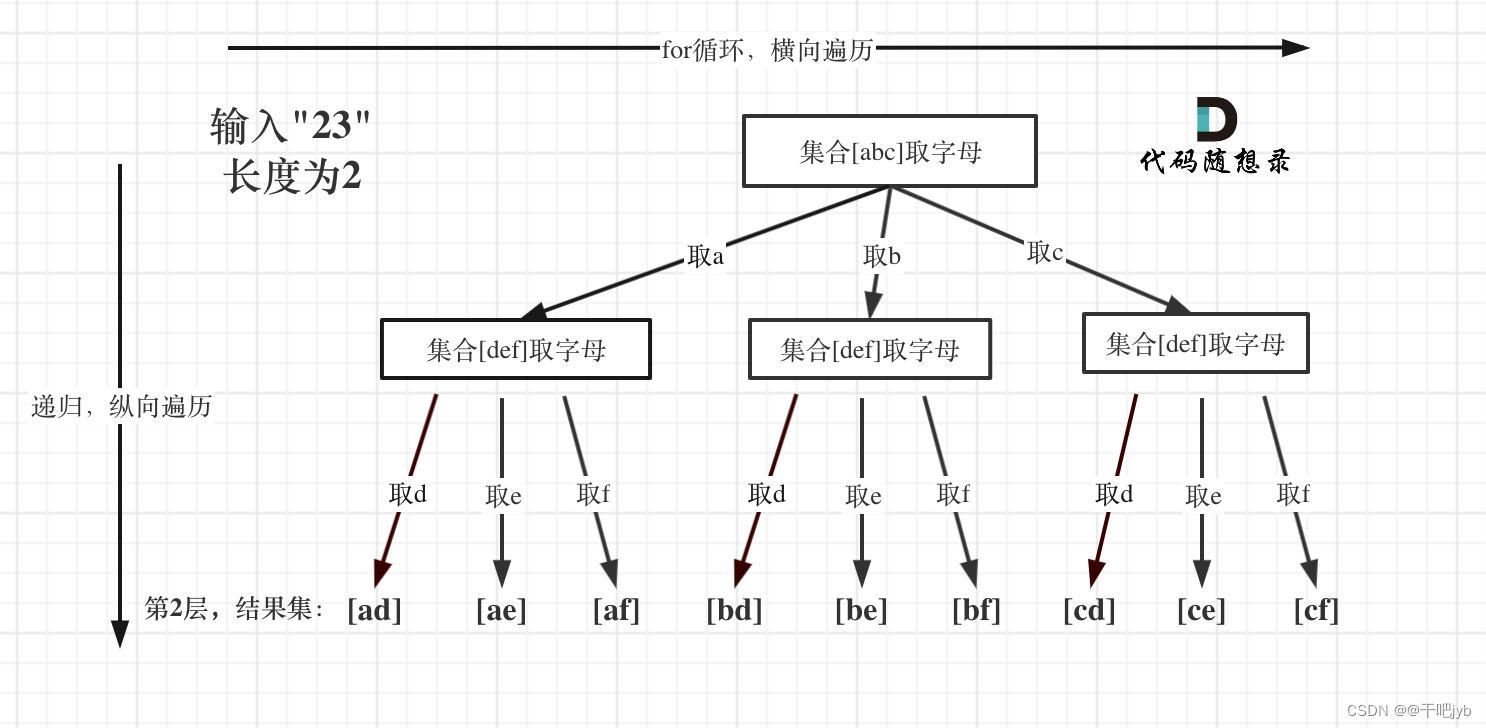
图中可以看出遍历的深度,就是输入"23"的长度,而叶子节点就是我们要收集的结果,输出["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]。
接下来就是回溯三部曲:
1确定回溯函数参数
首先需要一个字符串s来收集叶子节点的结果,然后用一个字符串数组result保存起来,这两个变量我依然定义为全局。
再来看参数,参数指定是有题目中给的string digits,然后还要有一个参数就是int型的index。这个index是记录遍历第几个数字了,就是用来遍历digits的(题目中给出数字字符串),同时index也表示树的深度。
2确定终止条件
例如输入用例"23",两个数字,那么根节点往下递归两层就可以了,叶子节点就是要收集的结果集。
那么终止条件就是如果index 等于 输入的数字个数(digits.size)了(本来index就是用来遍历digits的)。
然后收集结果,结束本层递归。
3 确定单层遍历逻辑
首先要取index指向的数字,并找到对应的字符集(手机键盘的字符集)
总体来说解题过程如下:
-
确定问题状态:首先,需要确定问题的状态,即每一层递归中需要处理的变量或参数。在 n 个嵌套的 for 循环中,通常每个循环都对应一个状态。
-
编写回溯函数:编写一个递归的回溯函数,它接受当前处理的状态以及当前处理到的层数作为参数。在每一层递归中,根据当前状态确定下一步的可能选择,并递归调用自身处理下一层状态。
-
确定递归结束条件:在编写回溯函数时,需要确定递归的结束条件。通常是达到了问题的边界条件或者处理完所有状态。
-
初始化和清理工作:在调用回溯函数之前,进行一些初始化工作,例如设置初始状态或者结果集。在回溯函数内部,可能需要进行一些清理工作,例如撤销当前状态的改变。
-
调用入口函数:编写一个入口函数,进行一些预处理工作后,调用回溯函数开始解决问题。
回溯法的关键在于,在每一步决策之后,都要进行回溯,即撤销上一步的选择,尝试其他可能的选择,直到找到所有解或者达到边界条件为止。
代码如下:
class Solution {
private:const string letterMap[10] = {"", // 0 对应空字符,通常不会输入0,故而不用处理"", // 1 对应空字符,通常不会输入1,故而不用处理"abc", // 2 对应字符集"abc""def", // 3 对应字符集"def""ghi", // 4 对应字符集"ghi""jkl", // 5 对应字符集"jkl""mno", // 6 对应字符集"mno""pqrs", // 7 对应字符集"pqrs""tuv", // 8 对应字符集"tuv""wxyz" // 9 对应字符集"wxyz"};
public:vector<string> result; // 存储结果的容器string s; // 当前组合的字符串void backtracking(const string& digits, int index) {if (index == digits.size()) { // 当组合长度等于数字串长度时,表示得到一个完整的组合result.push_back(s); // 将当前组合加入结果集return;}int digit = digits[index] - '0'; // 将当前数字字符转换为整数string letters = letterMap[digit]; // 获取当前数字对应的字符集for (int i = 0; i < letters.size(); i++) {s.push_back(letters[i]); // 将当前字符加入组合字符串backtracking(digits, index + 1); // 递归处理下一个数字s.pop_back(); // 回溯,移除最后一个字符,尝试下一个字符}}vector<string> letterCombinations(string digits) {s.clear(); // 清空当前组合字符串result.clear(); // 清空结果集if (digits.size() == 0) {return result; // 如果输入数字串为空,则直接返回空结果}backtracking(digits, 0); // 调用回溯函数,从第一个数字开始生成组合return result; // 返回最终结果}
};
3 四数之和
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < na、b、c和d互不相同nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
输入:nums = [1,0,-1,0,-2,2], target = 0 输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
示例 2:
输入:nums = [2,2,2,2,2], target = 8 输出:[[2,2,2,2
思路:
解决四数之和问题可以使用回溯算法的思想,但实际上更常用的是双指针法。下面我将简要介绍使用双指针法解决四数之和问题的思路:
-
排序数组:首先对给定的数组进行排序。这一步是为了方便后续的双指针移动,并且可以减少重复元素的考虑。
-
双指针遍历:使用两层循环来固定前两个数,在内层循环中使用双指针技巧来寻找后两个数。在双指针移动时,根据当前四数之和与目标值的大小关系来调整指针的移动方向,以尽量接近目标值。
-
跳过重复元素:在移动指针时,需要跳过重复元素,以避免重复的解。
-
收集结果:当找到一组满足条件的四个数时,将其加入结果集中。继续遍历直到完成所有可能的组合。
代码:
class Solution {
public:vector<vector<int>> fourSum(vector<int>& nums, int target) {vector<vector<int>> result;sort(nums.begin(), nums.end()); // 对数组进行排序for (int k = 0; k < nums.size(); k++) {// 剪枝处理:如果当前数字大于目标且为正数,跳出循环,统一通过最后的return返回结果if (nums[k] > target && nums[k] >= 0) {break;}// 对nums[k]去重if (k > 0 && nums[k] == nums[k - 1]) {continue;}for (int i = k + 1; i < nums.size(); i++) {// 2级剪枝处理:如果当前两个数字之和大于目标且为正数,跳出循环if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {break;}// 对nums[i]去重if (i > k + 1 && nums[i] == nums[i - 1]) {continue;}int left = i + 1;int right = nums.size() - 1;while (right > left) {// 避免四数相加可能的整数溢出,使用long类型转换long sum = static_cast<long>(nums[k]) + nums[i] + nums[left] + nums[right];if (sum > target) {right--; // 如果和大于目标值,向左移动右指针} else if (sum < target) {left++; // 如果和小于目标值,向右移动左指针} else {// 找到答案时,将四个数添加到结果集中result.push_back({nums[k], nums[i], nums[left], nums[right]});// 对nums[left]和nums[right]去重while (right > left && nums[right] == nums[right - 1]) right--;while (right > left && nums[left] == nums[left + 1]) left++;// 找到答案时,双指针同时收缩right--;left++;}}}}return result; // 返回结果集}
};4游戏玩法分析 I
SQL Schema
Pandas Schema
活动表 Activity:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ 在 SQL 中,表的主键是 (player_id, event_date)。 这张表展示了一些游戏玩家在游戏平台上的行为活动。 每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
查询每位玩家 第一次登录平台的日期。
查询结果的格式如下所示:
Activity 表: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-05-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+Result 表: +-----------+-------------+ | player_id | first_login | +-----------+-------------+ | 1 | 2016-03-01 | | 2 | 2017-06-25 | | 3 | 2016-03-02 | +-----------+-------------+
思路:从名为Activity的表中选择每个player_id的最早登录时间。为了实现这个目标,我们使用了SQL中的MIN函数,它可以找到给定列中的最小值,这里是event_date,即登录时间。然后,通过GROUP BY子句按照player_id对数据进行分组,以便获取每个player_id的最早登录时间。
代码:
-- 从Activity表中选取每个player_id的最早登录时间
select player_id, -- 选取player_idmin(event_date) AS first_login -- 使用MIN函数获取每个player_id的最早登录时间,并将其命名为first_login
fromActivity -- 从Activity表中查询数据
group byplayer_id; -- 按照player_id进行分组,以便获取每个player_id的最早登录时间5游戏玩法分析 IV
Table: Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id,event_date)是此表的主键(具有唯一值的列的组合)。 这张表显示了某些游戏的玩家的活动情况。 每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)。
编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
结果格式如下所示:
示例 1:
输入: Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ 输出: +-----------+ | fraction | +-----------+ | 0.33 | +-----------+ 解释: 只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
思路:
- 首先,使用子查询计算出Activity表中不同玩家的数量。
- 然后,通过将Activity表与子查询的结果进行内连接,找出每个玩家参与活动的最早日期。
- 接着,在where子句中,筛选出满足条件“活动日期与最早日期相差1天”的记录。
- 最后,通过计算连续两天参与活动的玩家数量与总玩家数量的比值,并保留两位小数,得到这一比例。
代码:
-- 计算在activity表中,第二天登录的玩家所占的比例select round(count(a.player_id) / (select count(distinct player_id) from activity), -- 计算第二天登录的玩家数量占总玩家数量的比例,并使用round函数四舍五入保留两位小数2) as fraction -- 将计算出的比例保留两位小数,并且作为别名命名为fraction
from activity a -- 为activity表起别名a,以便在查询中引用
join (-- 获取每个玩家的最早登录时间select player_id, -- 选择玩家ID字段min(event_date) as mindate -- 使用min函数找到每个玩家的最早登录时间,并且给这一列起别名为mindatefrom activity -- 从activity表中获取数据group by player_id -- 根据玩家ID进行分组) t on a.player_id = t.player_id -- 将activity表与子查询结果进行内连接,通过玩家ID进行关联
-- 仅选择第二天登录的记录
where datediff(a.event_date, t.mindate) = 1; -- 使用datediff函数计算登录日期与最早登录时间相差的天数,如果相差一天则表示第二天登录6至少有5名直接下属的经理
SQL Schema
Pandas Schema
表: Employee
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | | department | varchar | | managerId | int | +-------------+---------+ id 是此表的主键(具有唯一值的列)。 该表的每一行表示雇员的名字、他们的部门和他们的经理的id。 如果managerId为空,则该员工没有经理。 没有员工会成为自己的管理者。
编写一个解决方案,找出至少有五个直接下属的经理。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入: Employee 表: +-----+-------+------------+-----------+ | id | name | department | managerId | +-----+-------+------------+-----------+ | 101 | John | A | Null | | 102 | Dan | A | 101 | | 103 | James | A | 101 | | 104 | Amy | A | 101 | | 105 | Anne | A | 101 | | 106 | Ron | B | 101 | +-----+-------+------------+-----------+ 输出: +------+ | name | +------+ | John | +------+
思路:首先,内部子查询通过对员工表按照经理ID进行分组,并用COUNT函数统计每个经理ID出现的次数,即其直接下属的人数。然后,使用HAVING子句筛选出直接下属人数至少为5人的经理ID。最外层的主查询使用IN操作符,从员工表中选择经理ID在内部子查询结果中的员工记录,并返回这些经理的姓名
代码:
select name -- 选择姓名字段
from employee -- 从employee表中查询
where id in ( -- 筛选出经理ID在子查询结果中的员工记录select distinct managerid -- 选择去重后的经理IDfrom employee -- 从employee表中查询group by managerid -- 按经理ID分组having count(managerid) >= 5 -- 筛选出直接下属人数至少为5人的经理ID
); -- 结束主查询