目录
一,栈_刷题必备
二,stack实现
1.什么是容器适配器
2.STL标准库中stack和queue的底层结构
了解补充:容器——deque
1. deque的缺陷
2. 为什么选择deque作为stack和queue的底层默认容器
三,queue实现
1. 普通queue
2,优先级队列(有难度)
<1>. 功能
<2>. 模拟实现
1). 利用迭代器_构造
2).仿函数
sort函数中的仿函数使用理解
四. 反向迭代器(以list为例)
2. 关于迭代器文档一个小细节
结语

一,栈_刷题必备
常见接口:
stack() 造空的栈empty() 检测 stack 是否为空size() 返回 stack 中元素的个数top() 返回栈顶元素的引用push() 将元素 val 压入 stack 中pop() 将 stack 中尾部的元素弹出
简单应用,刷点题:
155. 最小栈
栈的压入、弹出序列_牛客题霸_牛客网
150. 逆波兰表达式求值
二,stack实现
思路:在C语言期间,我们可以通过链表,数组形式实现过stack,而数组形式效率更高,所以stack的实现可以直接复用vector接口,包装成栈先进后出的特性。
#pragma once
#include <iostream>
#include <vector>
#include <list>
using namespace std;
namespace my_s_qu
{template <class T >class stack{public:void push_back(const T& x){Data.push_back(x);}void Pop(){Data.pop_back();}T& top(){return Data.back();}const T& top() const {return Data.back();}bool empty() const{return Data.empty();}size_t size() const{return Data.size();}private:vector<T> Data;};
}很简单不是吗? 到这里并没有结束,我们发现,我们的栈只能通过vector实现。根据c++标准库,我们还差个适配器的实现,换句话说,我们实现的栈不支持容器适配器。

1.什么是容器适配器

2.STL标准库中stack和queue的底层结构

回到我们栈的实现,我们仅支持vector模式设计,优化为成容器适配器支持所有容器,都能支持栈的先进后出的特性。(在我看来这中思想更为重要)
namespace my_s_qu
{template <class T, class container = deque<T> > // 添加容器模板{public:void push_back(const T& x){Data.push_back(x);}......
private:container Data; // 容器换成模板};
}其中deque又是什么?
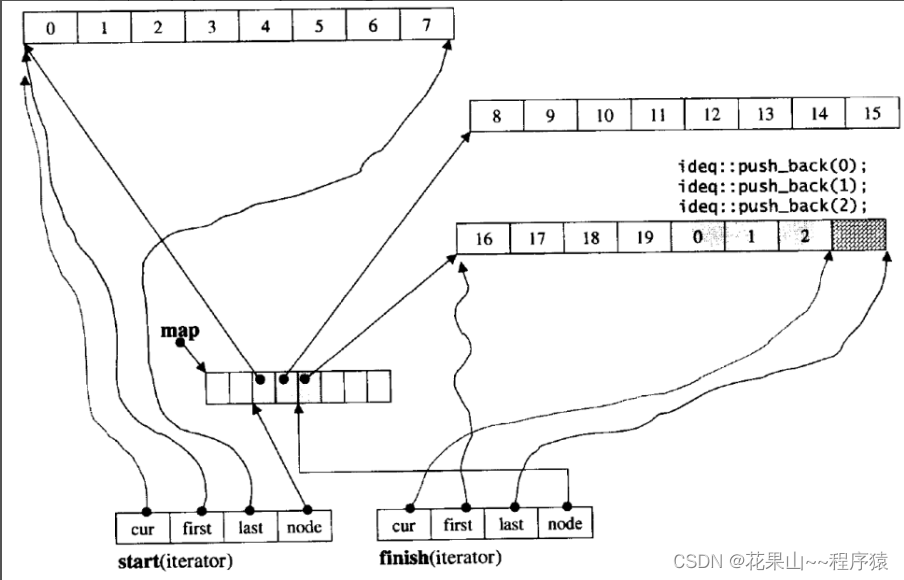
了解补充:容器——deque
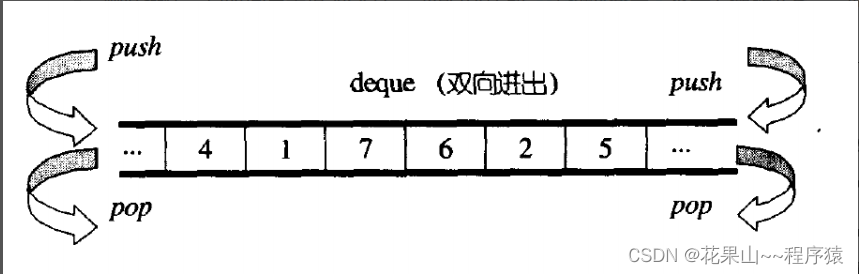

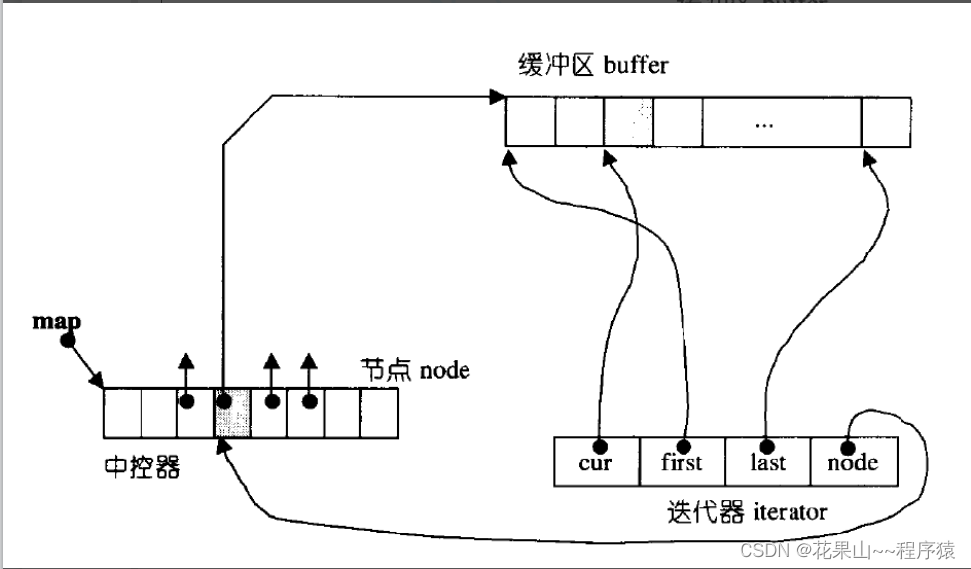
那deque是如何借助其迭代器维护其假想连续的结构呢?
1. deque的缺陷
优势:
与vector比较,deque的 优势是: 头部插入和删除效率高。 不需要搬移元素,效率特别高,而且在 扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较, 优势: 支持随机访问。其底层是连续空间, 空间利用率比较高,不需要存储额外字段。
缺陷:
不适合遍历。因为在遍历时,deque的迭代器要 频繁的去 计算每个数据的位置,导致 效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list, deque的应用并不多,而目前能看到的一个应用就是, STL用其作为stack和queue的底层数据结构。
2. 为什么选择deque作为stack和queue的底层默认容器
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
三,queue实现
1. 普通queue
queue实现,我们这次以容器适配器进行。
template <class T, class container = deque<T>>class queue{public:void push_back(const T& x){Data.push_back(x);}void Pop(){Data.pop_front();}T& back(){return Data.back();}const T& back() const{return Data.back();}T& front(){return Data.front();}const T& front() const{return Data.front();}bool empty() const{return Data.empty();}size_t size() const{return Data.size();}private:container Data;};2,优先级队列(有难度)

简介:
<1>. 功能
priority_queue()/priority_queue(fifirst, last) 构造一个空的优先级队列empty( ) 检测优先级队列是否为空,是返回true,否则返回falsetop( ) 返回优先级队列中最大(最小元素),即堆顶元素push(x) 在优先级队列中插入元素xpop() 删除优先级队列中最大(最小)元素,即堆顶元素pop_back() 删除容器尾部元素
<2>. 模拟实现
完成优先级队列,需要用到堆方面的知识,如果堆大家不太熟悉了,建议将堆实现内容复习一遍:
详解树与二叉树的概念,结构,及实现(上篇)_花果山~~程序猿的博客-CSDN博客
利用堆方面知识,完成最基础的框架:
namespace my_priority_queue
{template <class T, class container = vector<T>> class priority_queue{public:// 自定义类型,不需要给他初始化void ajust_up(size_t child){int parent;while (child > 0){parent = child / 2;if (_pri_queue[child] > _pri_queue[parent]) // 写大堆{std::swap(_pri_queue[child], _pri_queue[parent]);child = parent;parent = child / 2;}else{break;}}}T& top(){return _pri_queue[0];}bool empty(){return _pri_queue.empty();}void push(const T& x){_pri_queue.push_back(x);// 向上调整ajust_up(_pri_queue.size() - 1);}size_t size(){return _pri_queue.size();}void ajust_down(){size_t parent = 0;size_t child = 2 * parent + 1;while (child < _pri_queue.size()){if (child + 1 < _pri_queue.size() && _pri_queue[child + 1] > _pri_queue[child]){child++;}if (_pri_queue[parent] < _pri_queue[child]){std::swap(_pri_queue[parent], _pri_queue[child]);parent = child;child = parent * 2 + 1;}else{break;}}}void pop(){std::swap(_pri_queue[0], _pri_queue[size() - 1]);// 向下调整_pri_queue.pop_back();ajust_down();}private:container _pri_queue;};
}这里我们会有一个疑问,那我们要构建升序怎么办? 仿函数会解释
1). 利用迭代器_构造
// 自定义类型,不需要给他初始化priority_queue(){}template <class newiterator>priority_queue(newiterator begin, newiterator end): _pri_queue(){while (begin != end){push(*begin);begin++;}}2).仿函数
在该场景下,我们的优先级队列已经实现了降序的功能,那我们如何实现升序? 什么你说再写一段,改一下符号??
这里仿函数就得引出了,仿函数,那么它并不是函数,那是什么? (仿函数比如:less, greater)

仿函数本质是一个类,根据上图中,compare 模板,说明这里的仿函数,就是用来灵活改变大小堆符号的。
我们直接实现结果:
template <class T>struct less{bool operator()(const T& left, const T& right)const{return left < right;}};template <class T>struct greater{bool operator()(const T& left, const T& right)const{return left > right;}};这个两个类都是重载了operator(),因此我们在实例化对象后,使用:
template <class T,class compare = less<T>>
compare t;
cout << t(1, 2) << endl;
从外表来看,就像一个函数调用,但实际是,一个类的成员函数的调用
t.operator(1,2)
这样我们就可以直接改变仿函数的类,来控制大小堆了。
sort函数中的仿函数使用理解
函数模板中:
 sort函数作为行参中使用:
sort函数作为行参中使用:

sort(s.begin, s.end, greater<int> () ); // 函数中是要做参数的,我们加个括号就是一个匿名对象了
四. 反向迭代器(以list为例)
如果有小伙伴还学习普通迭代器,请参考这篇文章中的普通迭代器实现。
【STL】list用法&试做_底层实现_花果山~~程序猿的博客-CSDN博客
参考list源码,这里直接说结果,发现源码通过借用普通迭代器来构造反向迭代器。
直接上代码:
namespace my_list
{template <class T>struct list_node{list_node(const T& data = T()): _data(data), _next(nullptr), _prv(nullptr){}T _data;list_node* _next;list_node* _prv;};template <class T, class Ref, class Ptr>struct list_iterator{typedef list_node<T> Node;typedef list_iterator< T, Ref, Ptr> iterator;Node* _node;list_iterator(Node* node): _node(node){}bool operator!= (const iterator& it){return _node != it._node;}bool operator==(const iterator& it){return _node == it._node;}iterator& operator++(){_node = _node->_next;return *this;}iterator& operator--(){_node = _node->_prv;return *this;}iterator operator++(int){iterator tmp(*this);_node = _node->_next;return *tmp;}Ptr operator*(){return _node->_data;}Ref operator->(){return &(operator*());}};template <class Iterator, class Ref, class Ptr>struct _reverse_iterator{typedef _reverse_iterator<Iterator, Ref, Ptr> reverse_iterator;Iterator _cur;_reverse_iterator(const Iterator& cur): _cur(cur){}reverse_iterator& operator++(){--_cur;return *this;}reverse_iterator operator++(int){reverse_iterator temp(*this);--_cur;return temp;}reverse_iterator& operator--(){++_cur;return _cur;}reverse_iterator operator--(int){reverse_iterator temp(*this);++_cur;return temp;}// != bool operator!=(const reverse_iterator& end){return _cur != end._cur;}bool operator==(const reverse_iterator& end){return _cur == end._cur;}// * Ptr operator*() {auto tmp = _cur;--tmp;return *tmp;}// ->Ref operator->(){return &(operator*());}};template <class T>class list{typedef list_node<T> Node;public:typedef list_iterator<T, T*, T&> iterator;typedef list_iterator<T, const T*, const T&> const_iterator;typedef _reverse_iterator<iterator, T*, T&> reverse_iterator;typedef _reverse_iterator<const_iterator, const T*, const T&> const_reverse_iterator;reverse_iterator rbegin(){return reverse_iterator(end());}const_reverse_iterator rbegin() const{return const_reverse_iterator(end());}reverse_iterator rend(){return reverse_iterator(begin());}const_reverse_iterator rend() const{return const_reverse_iterator(begin());}iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}
..... //list其他成员函数这里就不再赘述了设计思路比较简单,本质上是复用普通迭代器的函数,其他重载函数思想跟普通函数差不多。但这里也有一个比较艺术性的设计:

那这里我们来讨论一下,这个反向迭代器是否能给vector使用?? 答案是肯定的
看图: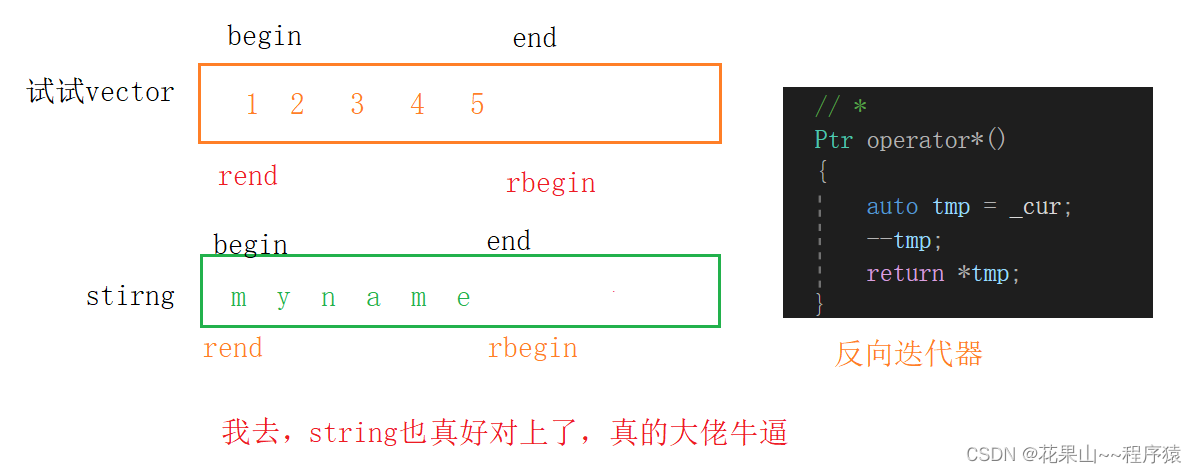
结论:反向迭代器:迭代器的适配器。
2. 关于迭代器文档一个小细节
那是不是所有的容器都合适呢?
不一定,因为容器的普通迭代器最起码要支持++,--接口(比如:foward_list就不支持--,所以其没有反向迭代器)
这里补充一些关于[STL]文档的使用,从迭代器功能角度分为三类:
1. forward_iterator (单向迭代器) 支持——> ++ 比如: foward_list等等
2. bidirectional_iterator(双向迭代器) ——> ++ -- 比如: list等
3. radom_access_iterator (随机迭起器) ——> ++ -- + - 比如:vector, deque等, 第三中迭代器继承1,2种
那意义又是什么??
意义:就是提示在使用迭代器时,接口会提示你合适的的迭代器类型。

结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获请留下你的小赞,你的点赞和关注将会成为博主创作的动力。