作者:陈之炎
本文约3500字,建议阅读8分钟
本文介绍了多模态强化学习。多模态强化学习是将多个感知模态和强化学习相结合的方法,能够使智能系统从多个感知源中获取信息,并利用这些信息做出更好的决策。这种方法对于处理现实世界中的复杂任务具有潜在的价值,并为智能系统的发展提供了新的研究方向。
强化学习是一种机器学习方法,其通过智能体与环境的交互来学习最优的决策策略。早期的强化学习主要集中在单一模态数据上,如状态信息和奖励信号。经典的强化学习算法,如Q-learning和深度强化学习(DRL),在各种领域取得了重大突破。
多模态学习涉及多个感知模态的融合和处理,如图像、语音、文本等。该领域的研究主要关注如何从多模态数据中提取有用的特征,并利用这些特征进行模式识别、分类和生成等任务。多模态学习已经在计算机视觉、自然语言处理、语音识别等领域取得了显著的成果。
随着多模态学习和强化学习的发展,研究者开始将两者结合起来,形成了多模态强化学习的研究方向。多模态强化学习的目标是通过融合多种感知模态的数据,提供更全面的信息来进行决策和学习。这样的方法可以帮助智能体更好地理解环境和任务,并做出更准确的决策。
2023年5月28日,以李飞飞为代表的人工智能团队,发布了题为“’VIMA: General Robot Manipulation with Multimodal Prompts ”(多模态提示符下的通用机器人操作)一文,正式拉开了多模态智能体强化学习的序幕,接下来,让我们仔细研读一下李飞飞的研究,论文中的代码和演示视频,可在vimalabs.github.io.上获取。

通用机器人操纵任务可以通过多模态提示来表达,李飞飞团队开发了一个新的模拟基准,其中包括成千上万个程序生成的桌面任务,具有多模态提示, 60多万个用于模拟学习的专家轨迹,以及用于系统泛化的四级评估协议。它是一个基于Transformer的机器人智能体( VIMA ),它能自回归地处理输入提示命令并输出电机功率。VIMA具有实现强大模型可扩展性和数据效率,在给定相同的训练数据的前提下,零样本泛化设置最多可达2.9倍的任务成功率,即便在训练数据少了10倍的情况下, VIMA的性能仍然比最好的竞争变体好2.7倍。
VIMA的目标是构建一个能够执行多模态联运提示的机器人智能体。为了学习有效的多任务机器人策略,VIMA构建出一种具有多任务编码器-解码器架构和以物体为中心的机器人智能体。
具体来说,机器人需要学习策略π ( 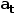 | P, H) ,其中H: =[
| P, H) ,其中H: =[ 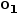 ,
, 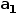 ,
, 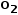 ,
, 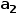 ,...,
,...,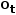 ]表示历史观察
]表示历史观察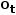 ∈O和历史动作
∈O和历史动作 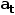 ∈ A在步长内的相互作用。对多模态联运提示进行编码。
∈ A在步长内的相互作用。对多模态联运提示进行编码。
在利用交叉注意力层对输入提示进行编码过程中,冻结预训练语言模型和解码机器人动作命令, VIMA采用以物体为中心的表示,从边界框坐标和裁剪的RGB补丁中计算标记。
词汇切分提示中有三种格式的原始输入:文本、单个物体的图像和完整桌面场景的图像。对于文本输入,使用预训练的T5标记器和词嵌入来获取单词标记;对于完整桌面场景的图像,首先使用域微调的Mask R-CNN 提取出单个物体。将每个物体表示为装订框和裁剪的图像。然后,通过使用边界框编码器和ViT 分别对其进行编码来计算出物体标记。由于Mask R-CNN的不完美性,物体的边界框可能会有噪声,裁剪的图像可能具有不相关的像素;对于单个物体的图像,以相同的方式获取标记,使用虚拟边界框。提示标记化后,将生成一系列交错的文本和视觉标记,然后通过预训练的T5编码器对提示进行编码。由于T5已经在大型文本语料库上进行了预训练,因此VIMA继承了语义理解能力和鲁棒性。
机器人控制器。设计多任务策略的挑战性是选择合适的调节机制。在架构图1 中,机器人控制器(解码器)由提示序列P和历史轨迹序列H 之间的交叉注意力层实现调节。
VIMA 模型采用了Transformer架构,在PyTorch 框架下实现,VIMA 的架构如下:
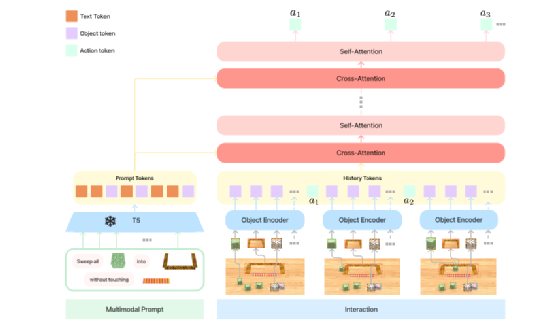
图1 VIMA 架构图
1.多模态提示标记化
通常有三种格式的多模态提示符,文本输入、全景图片和单个物体图片。对于文本输入提示符,按照自然语言处理标准管道,将源语言标记化,作为T5 预训练标记的输入,通过T5 预训练模型嵌入查找表获取对应单词标记;对于全景图片提示符,首先利用Mask R-CNN检测模型对全景图片进行微调,提取出其中的单个物体,每个物体用一张图片和一个边界框表示。边界框的格式为 xcenter, ycenter, height, width(横坐标中心,纵坐标中心,高度和宽度),将每个维度值除以上边界的坐标值之后,对边界框格式值进行归一化,使其在[0,1] 之间。将边界框的值输入MLP边界框编码器,提取出特征向量。处理单张图片时,先将矩形图片处理成正方形图片,再将图片大小修正为预配置的大小,将其送入ViT中提取出图片特征。最终获得物体的标记,并携带边界框特征和图片特征,将它们映射为嵌入维度;对于单个物体图片输入提示符,作上述相同的处理,唯一的区别是单个物体图片输入提示符没有边界框,标记化模型的超参数在表1 中列出:
种类 | 超参数 | 数值 |
文本标记化 | 标记器 | T5-base 标记器 |
嵌入维度 | 768 | |
图像标记化 | ViT输入图像大小 | 32*32 |
ViT补丁大小 | 16 | |
ViT宽度 | 768 | |
ViT层数 | 4 | |
ViT头数 | 24 | |
边界框MLP | 隐含层维度 | 768 |
隐含层深度 | 2 | |
提示编码 | 预训练的LM | T5-base |
N个未冻结层 | 2 | |
位置编码 | 绝对 | |
标记适配器ML深度 | 2 |
表1 标记化模型的超参数列表
在获取到提示的标记序列之后,将其传递给预训练的t5-base编码器,生成提示编码。为了防止发生灾难性遗忘,在物体标记和T5 编码器之间加入MLP 适配器,VIMA 会冻结其他层,只对语言编码器的最后两层进行微调,采用绝对位置编码进行学习,模型超参数在表1 中列出。
2.观察编码
全部的RGB 观察均为全景图片,同理,按照上述流程获取到物体的标记,由于需要提供前视和由上到下俯视两种视图,对物体对象按照前视和由上到下俯视的顺序对物体标记进行排序,对最终效果的状态进行独热编码。将物体标记与最终效果状态级联并将其转化为观察标记。采用绝对位置编码进行学习,观察编码的模型超参数在表2 中列出
超参数 | 数值 |
观察标记维度 | 768 |
终端效果嵌入维度 | 2 |
位置编码 | 绝对 |
表2 观察编码模型的超参数列表
3.动作编码
在实现观察编码的同时,VITA 模型也要实现动作编码,和历史动作相交织,需要对过往动作标记化,动作编码利用双层MLP 对过往动作实现编码,隐含层维度为256,将输出映射为标记维度,从而获取到动作标记。
4. 序列建模
VIMA 机器人控制为一个解码器,能够自回归预测未来动作。为了解码提示标记,在历史标记和提示标记之间执行交叉注意力机制,具体来说,将历史标记当作Query序列,提示标记当作 Key-value 序列,输入到交叉注意力模块当中。再将输出的“提示知晓轨迹”标记输入到自注意力模块当中,交替使用交叉注意力模块和自注意力模块L 次,这一过程可以用以下伪代码来描述。
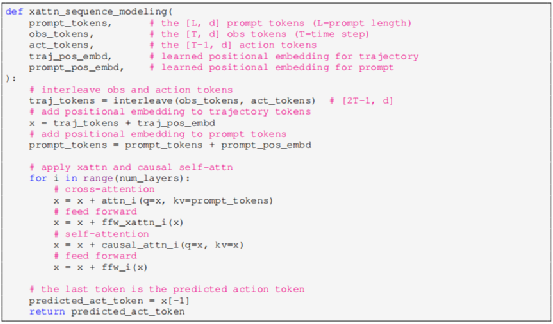
5.动作解码
获取到预测动作标记之后,将其映射到动作空间A得到预测的动作,通过一组动作头来实现动作解码。动作空间中包含两组SE(2) 姿态,每一组姿态用六个独立的头(两个头代表x,y坐标,四个头代表四象旋转)解码离散动作,最后将这些离散动作集成映射为连续的动作。两组姿态独立建模,由于采用的是交替注意力机制,两组姿态的性能相当。动作解码的模型超参数见表3。
超参数 | 数值 |
隐含层维度 | 512 |
隐含层深度 | 2 |
激活函数 | ReLU |
X轴离散容量 | 50 |
y轴离散容量 | 100 |
旋转离散容量 | 50 |
表3 动作解码的模型超参数
结论
李飞飞团队的研究工作引入了一种新颖的多模态提示公式,将各种机器人操作任务转换为均匀序列建模问题。并在VIMA-B ENCH中实例化了这种架构, VIMA-B ENCH是一种具有多模态任务和系统评估协议的基准。VIMA的概念为基于Transformer的智能体,能够实现视觉目标达成、一次性视频模拟和单一模型的新概念落地等任务。通过多方面的实验,证明了VIMA具有很强的模型可扩展性和零样本泛化能力。可以将VIMA多模态智能体设计作为未来工作的起点。
编辑:王菁
校对:汪雨晴
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
 点击“阅读原文”加入组织~
点击“阅读原文”加入组织~