生产者消费者模型
生产者消费者模型是一种并发编程模型,用于解决多线程或多进程间的数据共享和同步问题。在这个模型中,有两种角色:生产者和消费者,它们通过共享的缓冲区进行通信。生产者负责生成数据并将其放入缓冲区,而消费者则从缓冲区中获取数据并进行处理。
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而共享的缓冲区进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给缓冲区,消费者不找生产者 要数据,而是直接从缓冲区取,平衡了生产者和消费者的处理能力。这个缓冲区就是用来给生产者和消费者解耦的。
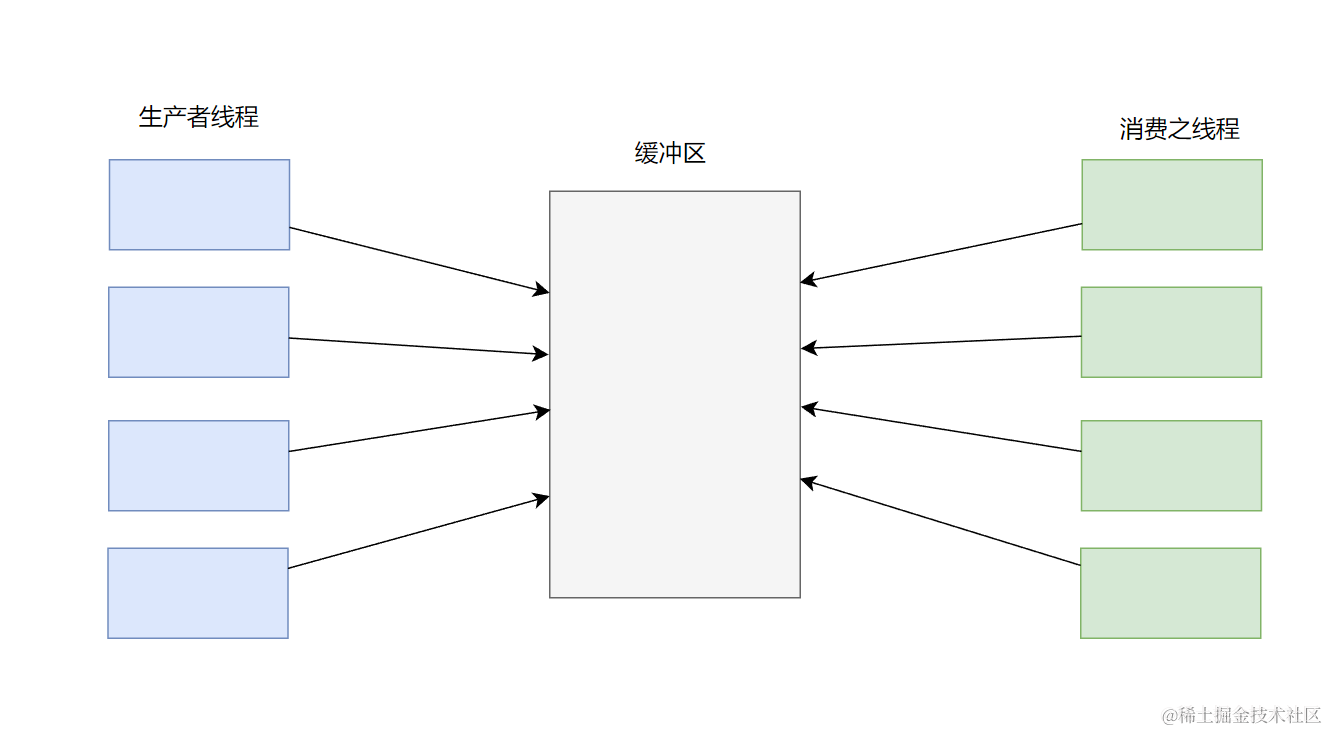
生产者消费者模型的关键在于解决生产者和消费者之间的同步问题,以确保生产者不会向已满的缓冲区中插入数据,消费者不会从空的缓冲区中获取数据。为了实现这种同步,可以使用各种同步原语,例如互斥锁、信号量、条件变量等。
生产者消费者模型的优点:
- 解耦生产者和消费者: 生产者和消费者之间通过队列进行通信和数据传递,使得它们可以独立进行操作。这种解耦提高了代码的灵活性和可维护性,因为你可以更容易地修改或替换生产者和消费者的实现而无需影响其他部分。
- 提高系统的响应性和吞吐量: 生产者和消费者可以并发地工作,生产者不必等待消费者完成处理才能继续生产,消费者也不必等待生产者生成新的数据才能继续消费。这可以提高系统的响应性和吞吐量,尤其是在处理大量数据时。
- 平衡生产和消费速度: 生产者消费者模型可以帮助平衡生产和消费的速度。当生产者的速度快于消费者时,数据会积累在队列中,直到消费者可以处理它们。相反,当消费者的速度快于生产者时,队列中的数据会减少,直到有新的数据生成。
- 简化并发编程: 生产者消费者模型提供了一种结构化的并发编程方式,通过使用队列来处理数据传递和同步,可以避免一些常见的并发编程错误,如竞态条件、死锁等。这使得并发编程更容易理解、调试和维护。
- 支持多个生产者和消费者: 生产者消费者模型可以很容易地扩展以支持多个生产者和消费者。只需使用一个共享的队列来传递数据,多个生产者可以向队列中添加数据,多个消费者可以从队列中取出数据,而无需修改原有的逻辑。
实现生产者消费者模型之前,先搞清楚他们之间的关系:
- 生产者和生产者之间的关系:互斥关系,
- 消费者和消费者之间的关系:互斥关系,
- 生产者和消费者之间的关系:互斥同步关系。
都要有互斥关系是因为生产者和消费者共享一个缓冲区,可能会被多个执行流同时访问,造成数据不一致的问题。所以他们之间都要存在互斥关系。
生产者和消费者之间除了互斥关系,还要有同步关系,如果让生产者一直生产,共享缓冲区满了之后,生产者再生产者数据就会失败,同理,消费者一直消费,缓冲区空了之后,消费者在消费就会失败。
这样就会引起一方饥饿问题,效率是非常低的,我们应该让生产者和消费者访问该容器时具有一定的顺序性,比如让生产者先生产,然后再让消费者进行消费。当缓冲区满了之后,生产者应该停止生产, 通知消费者进行消费。当缓冲区空了之后,消费者停止消费,通知生产者生产数据。
基于阻塞队列的生产者消费者模型
它利用阻塞队列来实现生产者和消费者之间的同步和通信。在这种模型中,阻塞队列充当生产者和消费者的共享缓冲区。生产者将数据放入队列,而消费者从队列中取出数据进行处理。当队列为空时,消费者会被阻塞直到队列中有数据;当队列已满时,生产者会被阻塞直到队列有足够的空间。
阻塞队列和普通队列的区别:
- 当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中放入了元素。
- 当队列满时,往队列里存放元素的操作会被阻塞,直到有元素从队列中取出。
- 直白一点讲就是阻塞队列有容量上限,而普通队列,以STL中的queue为例,“没有容量上限”。
以单生产单消费为例,使用STL中的queue做为生产者和消费者的共享缓冲区:

#pragma once
#include <iostream>
#include <pthread.h>
#include <queue>
static const int DEFAULT_NUM = 5;
template <class T>
class BlockQueue
{
public:BlockQueue(int capacity = DEFAULT_NUM): _capacity(capacity){pthread_mutex_init(&_mutex, nullptr);pthread_cond_init(&_p_cond, nullptr);pthread_cond_init(&_c_cond, nullptr);}bool IsEmpty(){return _queue.size() == 0;}bool IsFull(){return _queue.size() == _capacity;}void Push(T &task) // 生产者{pthread_mutex_lock(&_mutex);while (IsFull())//防止伪唤醒{pthread_cond_wait(&_p_cond, &_mutex);}_queue.push(task);pthread_cond_signal(&_c_cond);pthread_mutex_unlock(&_mutex);}void Pop(T *task) // 消费者{pthread_mutex_lock(&_mutex);while (IsEmpty()){pthread_cond_wait(&_c_cond, &_mutex);}*task = _queue.front();_queue.pop();pthread_mutex_unlock(&_mutex);}~BlockQueue(){pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_c_cond);pthread_cond_destroy(&_p_cond);}private:std::queue<T> _queue;size_t _capacity;pthread_mutex_t _mutex;pthread_cond_t _p_cond; // 生产者pthread_cond_t _c_cond; // 消费者
};
这是一个基于 pthread 库实现的简单的阻塞队列(BlockQueue)模板类,其中包含了生产者和消费者的实现。
主要组成部分和功能包括:
_queue: 使用 STL 的队列实现的底层存储数据结构。_capacity: 队列的最大容量。_mutex: 互斥锁,用于保护队列的访问和操作。_p_cond: 用于生产者等待的条件变量。_c_cond: 用于消费者等待的条件变量。
以下是类中的主要方法:
Push: 生产者使用的方法,向队列中添加元素。如果队列已满,生产者将被阻塞,直到有空间可用。Pop: 消费者使用的方法,从队列中取出元素。如果队列为空,消费者将被阻塞,直到有数据可用。IsEmpty: 判断队列是否为空。IsFull: 判断队列是否已满。- 构造函数和析构函数负责初始化和销毁所需的互斥锁和条件变量。
在push方法中,先获取互斥锁 _mutex,然后判断队列是否已满,如果队列已满,则该生产者线程会等待条件变量 _p_cond,直到队列有空间可用。然后生产者将数据放入队列,发送信号给消费者 _c_cond,最后释放互斥锁。
达到了生产者和消费者之间的同步关系。
由于互斥锁的作用,在任何时刻只有一个生产者线程能够执行 Push 操作,从而保证了生产者之间的互斥关系。当一个生产者线程正在向队列中添加数据时,其他生产者线程会被阻塞在获取互斥锁的操作上,直到当前生产者线程释放互斥锁。Pop方法同理,保证了消费者和消费者之间的互斥关系。
注意:
在生产者消费者模型中,判断队列是否为空或已满是一个关键的操作,它决定了生产者和消费者线程是否需要等待或继续执行。使用 while 循环进行判断的主要原因是为了防止虚假唤醒。
虚假唤醒是指在等待条件变量时,线程在没有收到信号的情况下醒来的现象。这种情况可能发生在多线程编程中,即使条件没有发生变化,线程也可能在等待期间被唤醒。因此,为了避免虚假唤醒,使用 while 循环进行条件判断是比较安全的做法。
还有一种解释就是,使用if语句判断后, pthread_cond_wait(&_p_cond, &_mutex);函数一旦调用失败,就会执行后面的代码,访问临界资源。这种解释更为合理。
基于循环队列的生产者消费者模型
这种模式中,环形队列充当生产者和消费者的缓冲区。在这种模式中,生产者负责向环形缓冲区中写入数据,而消费者负责从缓冲区中读取数据进行处理。
对于生产者和消费者来说,它们关注的资源是不同的:
- 生产者关注的是环形队列当中是否有空间(blank),只要有空间生产者就可以进行生产。
- 消费者关注的是环形队列当中是否有数据(data),只要有数据消费者就可以进行消费。
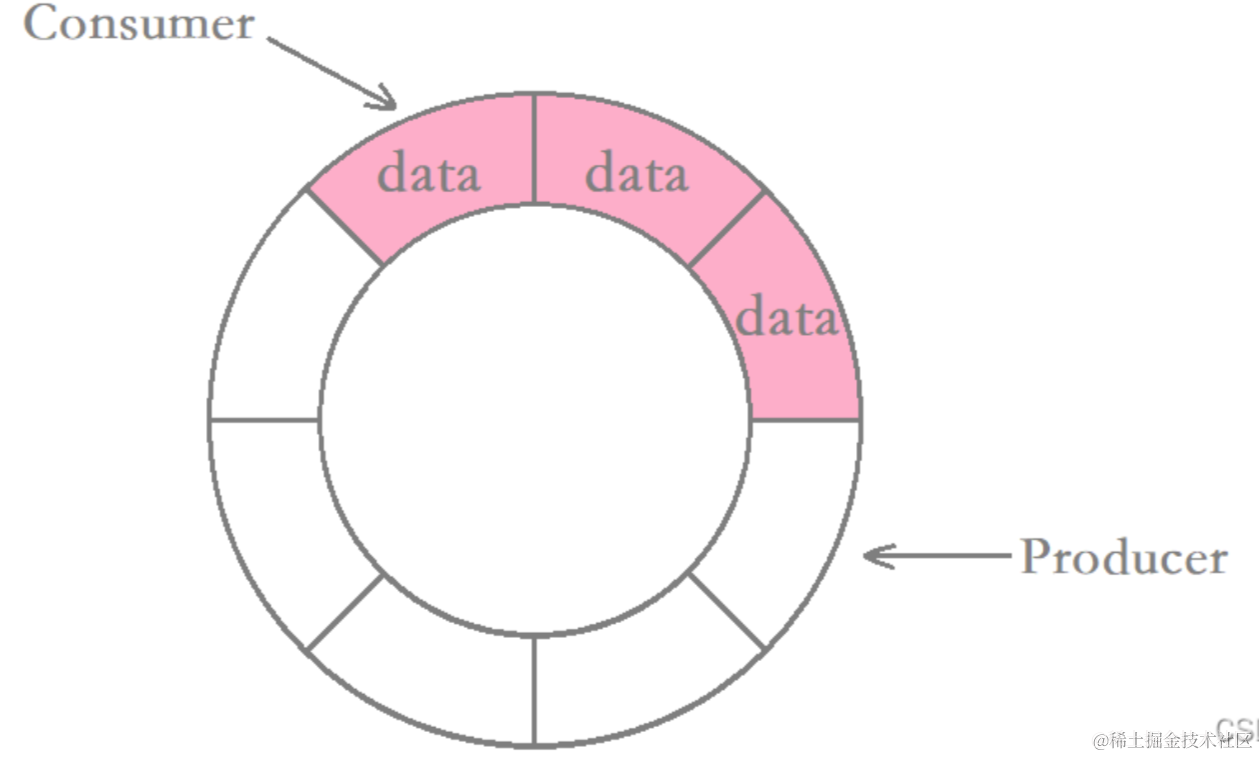
使用信号量描述环形队列的空间资源(blank_sem)和数据资源(data_sem)。在初始化信号量的时候,给他们设定不同的值。
- blank_sem的初始值我们应该设置为环形队列的容量,因为刚开始时环形队列当中全是空间。
- data_sem的初始值我们应该设置为0,因为刚开始时环形队列当中没有数据。
生产者
对于生产者,生产者每生产数据时要先申请空间资源。
- 如果blank_sem的值不为0,则信号量申请成功,此时生产者可以进行生产操作。
- 如果blank_sem的值为0,则信号量申请失败,说明没有空间资源了。此时生产者需要在blank_sem的等待队列下进行阻塞等待,直到环形队列当中有新的空间后再被唤醒。
当生产者生产完数据时,应该释放数据资源。
- 当生产者生产完数据后,意味着环形队列当中多了一个
data位置,因此我们应该对data_sem进行V操作。
消费者
对于消费者,消费数据时要先申请数据资源。
- 如果data_sem的值不为0,则信号量申请成功,此时消费者可以进行消费操作。
- 如果data_sem的值为0,则信号量申请失败,此时消费者需要在data_sem的等待队列下进行阻塞等待,直到环形队列当中有新的数据后再被唤醒。
当消费者消费完数据后,应该释放空间资源。
- 当消费者消费完数据后,意味着环形队列当中多了一个
blank位置,因此我们应该对blank_sem进行V操作。
PV 操作
P(proberen,荷兰语中的“尝试”)和 V(verhogen,荷兰语中的“增加”)是用于信号量操作的原语,常见于并发编程中,用于实现临界区的互斥和同步。
- P 操作(也称为 wait 操作): P 操作用于尝试获得资源或进入临界区。它通常被用来请求一个资源或临界区的访问权限。如果资源可用(信号量的值大于零),则 P 操作将信号量的值减一,并允许程序继续执行。如果资源不可用(信号量的值等于零),则 P 操作将阻塞当前线程,直到资源可用为止。
- V 操作(也称为 signal 操作): V 操作用于释放资源或退出临界区。它通常被用来释放一个已经占用的资源或退出一个临界区。V 操作将信号量的值加一,表示资源已经被释放。如果有其他线程在等待该资源,则 V 操作会唤醒其中一个等待线程,使其可以继续执行。
- 在使用信号量实现的生产者-消费者模型中,P 操作用于减少信号量的值来表示消费者消耗一个资源,而 V 操作用于增加信号量的值来表示生产者产生一个资源。这样可以保证在资源有限的情况下,生产者和消费者之间能够协调合作,避免竞态条件和死锁等问题。
简易实现一个
#include <iostream>#include <semaphore.h>#include <pthread.h>#include <vector>static const int NUM = 8;template<class T>class RingQueue{private:void P(sem_t& s){sem_wait(&s);}void V(sem_t& s){sem_post(&s);}public:RingQueue(int capacity = NUM):_capacity(capacity){_queue.resize(_capacity);sem_init(&_blank_sem,0,_capacity);sem_init(&_data_sem,0,0);}void Push(const T& task){P(_blank_sem);_queue[_p_index] = task;V(_data_sem);_p_index++;_p_index %= _capacity;}void Pop(T& task){P(_data_sem);task = _queue[_c_index];V(_blank_sem);_c_index++;_c_index %= _capacity;}~RingQueue(){sem_destroy(&_blank_sem);sem_destroy(&_data_sem);}private:std::vector<T> _queue;size_t _capacity;int _p_index = 0;int _c_index = 0;sem_t _blank_sem;//空间资源sem_t _data_sem;//数据资源};
这是一个基于 pthread 库实现的简单的环形队列(RingQueue)模板类,其中包含了生产者和消费者的实现。
主要组成部分和功能包括:
_queue: 使用 STL 的vector实现的底层存储数据结构。_capacity: 环形队列的容量,表示队列最多可以存储多少个元素。_p_index: 表示生产者应该将任务放置到队列中的位置。_c_index: 表示消费者应该从队列中取出任务的位置。_blank_sem: 用于控制空闲空间,表示队列中还有多少空闲位置。_data_sem:用于控制数据资源,表示队列中已经有多少数据可用。
以下是类中的主要方法:
Push: 生产者使用的方法,先申请空间资源,将任务存放到环形队列中,然后释放数据资源。更新_p_index以支持下一次生产,由于是环形队列,更新索引时要注意。Pop: 消费者使用的方法,先申请空间资源,将任务从索引位置获取,然后释放空间资源。更新_c_index以支持下一次消费。P:方法用于执行 P 操作(等待信号量)。V:方法用于执行 V 操作(发送信号量)。- 构造函数和析构函数负责初始化和销毁所需的环形队列和信号量。
两种模型的区别
基于环形队列的阻塞队列和简单的阻塞队列在实现上有一些区别,主要在于同步机制
- 阻塞队列:通常使用条件变量来实现阻塞和唤醒操作。当队列满时,生产者通过条件变量等待队列不满;当队列为空时,消费者通过条件变量等待队列不为空。
- 环形队列:可以使用信号量来实现阻塞和唤醒操作。生产者在向环形队列添加元素时,如果队列已满,会通过信号量进行等待;消费者在从环形队列取出元素时,如果队列为空,会通过信号量进行等待。
同步机制的不同 导致了他们的使用场景也有所不同。
- 阻塞队列: 阻塞队列适用于需要线程安全和阻塞特性的场景,且缓冲区大小可以动态调整的情况下。它适用于生产者和消费者之间处理速度不匹配的情况,可以很好地解耦生产者和消费者,提高系统的灵活性和可维护性。
- 环形队列: 环形队列适用于需要固定大小缓冲区的场景,且缓冲区大小事先已知的情况下。它适用于内存使用有限且需要循环利用的情况。