1. 3DGS 是全图的Render, 因此特地写了 full_images_datamanger.py 每个step 取出一张图像。
返回值是一张 全图的 RGB 和对应的 Camera
2. 3D GS 没有生成光线,因此 不需要指定near 和 far,即 collider是None。 但需要对3D 高斯球进行初始化:
- 高斯球的means (中心点的初始化): 输入点云的 坐标当作是 高斯球的中心点:
means = torch.nn.Parameter(self.seed_points[0]) # (Location, Color)
- 高斯球的scale初始化, 使用KNN 算法计算每一个 点云到 最近3个点之间的 距离 distance, 对这个距离求解平均距离,以这个 ave_distance 的 log 对数的结果 当作是 scale 的初始化:
distances, _ = self.k_nearest_sklearn(means.data, 3)
distances = torch.from_numpy(distances)
# find the average of the three nearest neighbors for each point and use that as the scale
avg_dist = distances.mean(dim=-1, keepdim=True)
scales = torch.nn.Parameter(torch.log(avg_dist.repeat(1, 3)))
- 旋转四元数的初始化,随机初始化:
quats = torch.nn.Parameter(random_quat_tensor(num_points))
- opacity的初始化,随机给定一个固定数值从 0.1 初始化:
opacities = torch.nn.Parameter(torch.logit(0.1 * torch.ones(num_points, 1)))
- color 的SH 参数的初始化,从点云的 RGB 直接转化为 SH 系数:
if self.config.sh_degree > 0:shs[:, 0, :3] = RGB2SH(self.seed_points[1] / 255) ## RGB 转化成第0阶的 SH 系数shs[:, 1:, 3:] = 0.0
else:CONSOLE.log("use color only optimization with sigmoid activation")shs[:, 0, :3] = torch.logit(self.seed_points[1] / 255, eps=1e-10)
features_dc = torch.nn.Parameter(shs[:, 0, :])
features_rest = torch.nn.Parameter(shs[:, 1:, :])
SH 的稀疏的 shape 标准是(N,16,3); 3 代表3个通道, N 代表 N个点,16 代表阶数。
第0 阶的参数直接由RGB 转换而来; 之后都是设置为0 进行初始化。 对应的优化参数是:
features_dc = torch.nn.Parameter(shs[:, 0, :]) ## 【N,3】
features_rest = torch.nn.Parameter(shs[:, 1:, :]) ## 【N,15,3】
3. 3D GS 的属性:
self.gauss_params = torch.nn.ParameterDict({"means": means, ## Location"scales": scales, ## 缩放因子"quats": quats, ## 旋转的四元数"features_dc": features_dc,"features_rest": features_rest,"opacities": opacities, ## 不透明度})
这行使用 torch 的 ParameterDict 的 代码相当于 直接使用:
self.means = means;
self.scales = scales;
3.1 首先对于整张 图像进行 DownScale 4 倍:
对图像进行4倍降采样,并修改对应的内参
camera_downscale = self._get_downscale_factor() ## 4
camera.rescale_output_resolution(1 / camera_downscale)
3.2 修改 Camera 的坐标,将其从 nerfstudio 的坐标 旋转 到 opencv 的坐标。 也就是 [-1,-1,1] 的矩阵
# shift the camera to center of scene looking at center
R = camera.camera_to_worlds[0, :3, :3] # 3 x 3
T = camera.camera_to_worlds[0, :3, 3:4] # 3 x 1
# flip the z and y axes to align with gsplat conventions
R_edit = torch.diag(torch.tensor([1, -1, -1], device=self.device, dtype=R.dtype))
R = R @ R_edit
# analytic matrix inverse to get world2camera matrix
R_inv = R.T
T_inv = -R_inv @ T
viewmat = torch.eye(4, device=R.device, dtype=R.dtype)
viewmat[:3, :3] = R_inv
viewmat[:3, 3:4] = T_inv
3.3 在CUDA 中 对3D Gaussian 进行投影:
- 投影的椭圆近似成一个圆, 保存圆的半径 和中心点的xyz 坐标即可
当一个 Gaussian 投影成一个圆之后,那么他的半径 和 椭圆的 标准差是密切相关的:

给定二维高斯分布的协方差矩阵 Σ \Sigma Σ ,通过计算该矩阵的特征值并取其平方根,我们可以得到分布的“半径”,协方差的特征值可以认为是 椭圆的两个方向的半径。求解 下面的方程即可:

可以进一步的展开:
( a − λ ) ( c − λ ) − b 2 = 0 (a-\lambda)(c-\lambda)-b^2=0 (a−λ)(c−λ)−b2=0
圆的圆心,可以直接通过 3D Gaussian 的中心点 Center 投影得到。
-
计算覆盖的像素
快速的方法,将图像分成 16*16 的tile; 计算每一个 Tile 和圆的 相交区域。
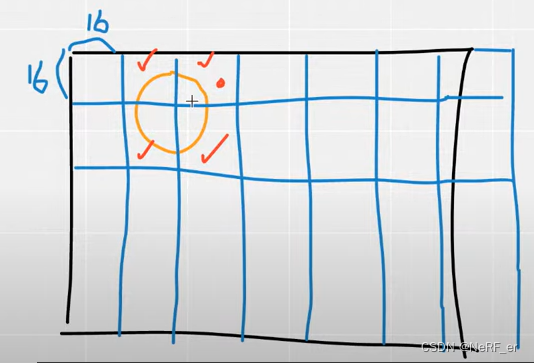
3.对每一个高斯按照深度顺序进行排序
一个Tile 可能会有很多个 Gaussian 进行覆盖, CUDA 程序会根据每一个 Tile 会对其覆盖的 Gaussian 进行深度排序。

-
计算每一个像素的颜色
每一个 Tile 对应着 一个block; 而每一个Pixel 对应着一个 thread。
计算 每一个像素到2D 投影圆的距离,并且依据 高斯分布 求解出 opacity 的大小。