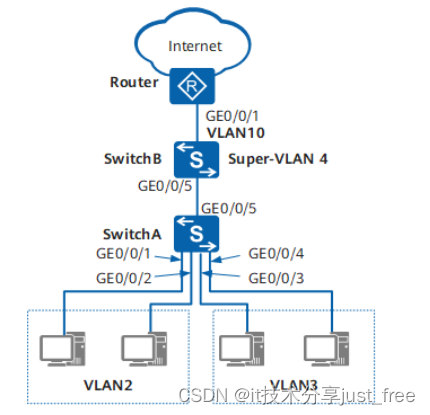
简介
CLIP(Contrastive Language-Image Pre-Training)是OpenAI在2021年初发布的多模态预训练神经网络模型,用于匹配图像和文本。该模型的关键创新之一是将图像和文本映射到统一的向量空间,通过对比学习的方式进行预训练,使得模型能够直接在向量空间中计算图像和文本之间的相似性,无需额外的中间表示。
CLIP模型训练分为三个阶段:
- 对比式预训练阶段:使用图像-文本对进行对比学习训练;
- 从标签文本创建数据集分类器:提取预测类别文本特征;
- 用于零样本预测:进行零样本推理预测。
CLIP的设计灵感在于将图像和文本映射到共享的向量空间,使得模型能够理解它们之间的语义关系。这种共享向量空间使得CLIP实现了无监督的联合学习,可用于各种视觉和语言任务。
在训练完成后,CLIP可用于多种任务,如分类图像、生成文本描述、检索图像等。它具有出色的zero-shot学习能力,只需简单的线性分类器(Linear Probe)或最近邻搜索(KNN)即可完成任务,无需额外训练或微调。
简单使用
使用CLIP模型可以很方便地实现零样本图片分类(Zero Shot Image Classification),广泛效果好,且图片类别(labels)可以自由定义。从这种意义上来讲,它改变了以前CV界关于图片分类的范式,是真正意义上的创新。
应用入门
以下是使用Hugging Face来使用CLIP模型实现零样本图片分类的Python代码。
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModelmodel_path = "/data-ai/usr/lmj/models/clip-vit-base-patch32"
model = CLIPModel.from_pretrained(model_path)
processor = CLIPProcessor.from_pretrained(model_path)
url = "https://static.jixieshi.cn/upload/goods/2022042210295380594_BIG.png"
image = Image.open(requests.get(url, stream=True).raw)
image

text = ["a photo of a computer", "a photo of a mouse", "a photo of a keyboard", "a photo of a cellphone"]
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
logits_per_imagetensor([[23.6426, 20.7598, 28.2721, 17.9425]], grad_fn=<TBackward0>)
probs = logits_per_image.softmax(dim=1)
probs.detach().numpy().tolist()
[[0.009659518487751484,0.000540732522495091,0.9897673726081848,3.2318232115358114e-05]]
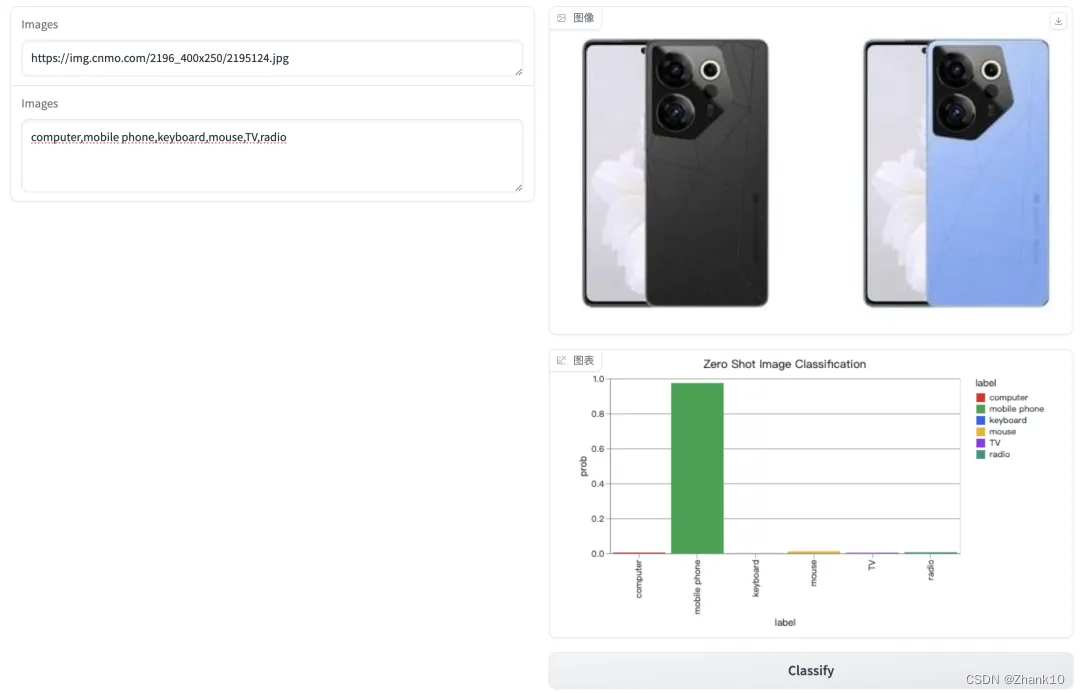
可视化应用
以下是使用Gradio工具来构建零样本图片分类的Python代码:
# -*- coding: utf-8 -*-
import pandas as pd
import gradio as gr
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModelmodel_path = "./models/clip-vit-base-patch32"
model = CLIPModel.from_pretrained(model_path)
processor = CLIPProcessor.from_pretrained(model_path)
print("load model...")def image_predict(image_url, prompts):image = Image.open(requests.get(image_url, stream=True).raw)labels = prompts.split(',')inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)outputs = model(**inputs)logits_per_image = outputs.logits_per_imageprobs = logits_per_image.softmax(dim=1).detach().numpy().tolist()[0]return image, gr.BarPlot(value=pd.DataFrame({"label": labels,"prob": probs,}),x="label",y="prob",width=400,color='label',title="Zero Shot Image Classification",tooltip=["label", "prob"],y_lim=[0, 1])if __name__ == '__main__':with gr.Blocks() as demo:with gr.Row():with gr.Column():image_urls = gr.TextArea(lines=1, placeholder="Enter image urls", label="Images")prompt = gr.TextArea(lines=3, placeholder="Enter labels, separated by comma", label="Labels")with gr.Column():search_image = gr.Image(type='pil')plot = gr.BarPlot()submit = gr.Button("Classify")submit.click(fn=image_predict,inputs=[image_urls, prompt],outputs=[search_image, plot])demo.launch(server_name="0.0.0.0", server_port=50073)
效果图如下:
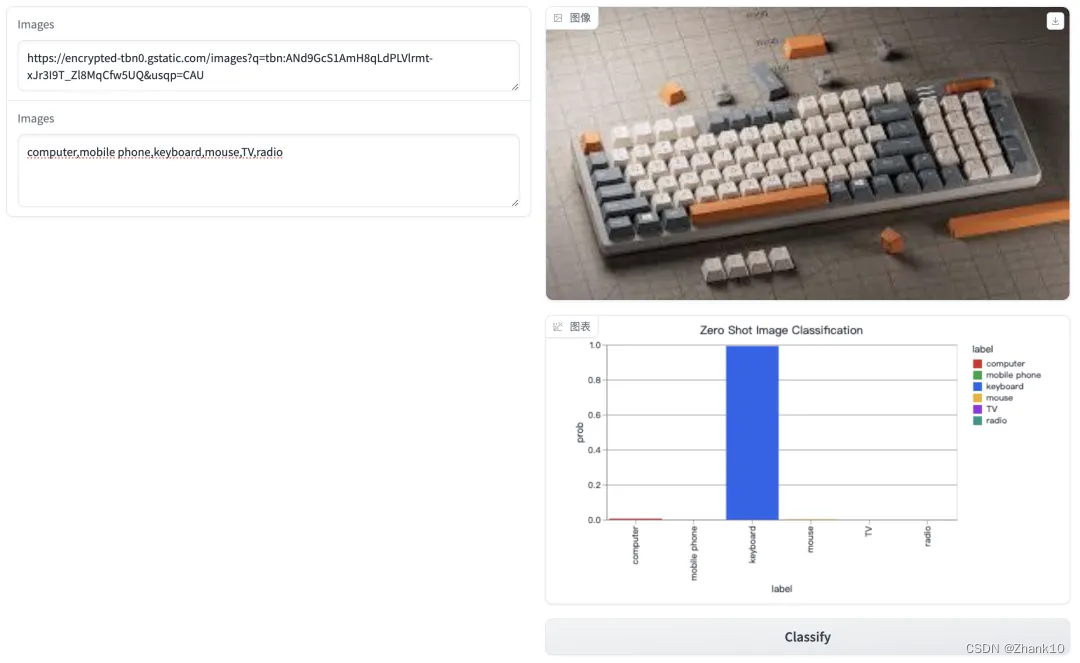
参考
CLIP:多模态领域革命者:https://bbs.huaweicloud.com/blogs/371319
CLIP in Hugging Face:https://huggingface.co/docs/transformers/model_doc/clip
openai/clip-vit-base-patch32 · Hugging Face
OpenAI Clip:https://openai.com/research/cli