一.Java中线程安全的集合类
Java中提供了多种线程安全的集合类,它们可以在多线程环境下安全地被多个线程同时访问而无需外部同步。以下是一些常见的线程安全集合类:
- Vector: 类似于 ArrayList 的动态数组,但是所有方法都是同步的,提供了基本的线程安全保证。
- Hashtable: 是一个线程安全的哈希表实现,与 HashMap 类似,但所有操作都是同步的。
- Stack: 继承自 Vector 的线程安全栈实现。
- ConcurrentLinkedQueue: 使用非阻塞算法的线程安全队列实现。
- BlockingQueue: 这是一个接口,它有多个实现类(如 ArrayBlockingQueue, LinkedBlockingQueue 等),这些实现类提供了线程安全的队列操作。
- CopyOnWriteArrayList: 一个线程安全的列表,它在修改操作时复制底层数组,从而避免并发修改异常。
- CopyOnWriteArraySet: 基于 CopyOnWriteArrayList 的线程安全集合。
- ConcurrentHashMap: 提供比 Hashtable 更好的并发性能的线程安全哈希表实现。
- ConcurrentSkipListMap: 线程安全且数据有序的哈希表。
需要注意的是,虽然这些集合类是线程安全的,但在特定场景下可能存在性能差异。例如,Vector和Hashtable的每个操作都是通过synchronized关键字进行同步的,这可能在高并发情况下成为性能瓶颈。而其他一些类,如ConcurrentHashMap,采用了更精细的锁定机制来提高并发性能。
二.多线程下使用ArrayList
- 给自己加锁 : 在涉及线程安全的代码中用(synchronized或者ReentrantLock)加锁
- 使用Collections.synchronizedList包装器:Collections.synchronizedList(new ArrayList ) 给ArrayList各种操作本身不带锁.通过上述套壳之后,得到的新的对象里面的关键方法都带有锁了.
Java 提供了一个便利的方法来创建一个同步的列表,即 Collections.synchronizedList。这个方法返回一个线程安全的列表,所有对它的直接操作都是同步的。但请注意,迭代时用户必须手动对这个列表进行同步。
代码示例:
import java.util.Collections;
import java.util.List;
import java.util.ArrayList;List<Object> syncList = Collections.synchronizedList(new ArrayList<>());public void addToList(Object item) {synchronized(syncList) {syncList.add(item);}
}public Object removeFromList(int index) {synchronized(syncList) {return syncList.remove(index);}
}- 使用并发集合类:CopyOnWriteArrayList 写时拷贝,多个线程读是没有线程安全问题的 如果多个线程读这个顺序表, 没有任何线程安全问题~如果一旦有线程要修改这里的值,就会把该顺序表复制一份,修改复制表中的内容,然后修改引用的指向(原子的)
如果性能是个问题,并且你不想手动管理同步,可以考虑使用 java.util.concurrent 包中的线程安全集合类,如 CopyOnWriteArrayList。
代码示例:
import java.util.concurrent.CopyOnWriteArrayList;List<Object> cowList = new CopyOnWriteArrayList<>();public void addToList(Object item) {cowList.add(item);
}public Object removeFromList(int index) {return cowList.remove(index);
}三.多线程下使用队列
多线程下使用队列一般是使用阻塞队列:
Java 提供了多种阻塞队列的实现,它们可以在多线程环境下安全地传递元素。以下是一些常用的阻塞队列种类:
- ArrayBlockingQueue: 一个由数组支持的有界阻塞队列。
- LinkedBlockingQueue: 一个由链表支持的可选边界阻塞队列,其性能通常优于 ArrayBlockingQueue。
- PriorityBlockingQueue: 一个支持优先级排序的无界阻塞队列。
- DelayQueue: 一个使用优先级队列实现的无界阻塞队列,用于延迟元素的传输。
- SynchronousQueue: 一个不存储元素的阻塞队列,适用于传递性设计。
- LinkedTransferQueue: 一个由链表支持的无界阻塞队列,相对于 LinkedBlockingQueue,它提供了更高级的传输操作。TransferQueue 的应用场景是,当不想生产者过度生产消息时,TransferQueue可能非常有用,在这样的设计中,消费者的消费能力将决定生产者产生消息的速度。
- LinkedBlockingDeque: 一个由双向链表支持的可选边界阻塞队列,可以用作栈或队列。
- ConcurrentLinkedQueue: 虽然不是阻塞队列,但它是 Java 中的一个非阻塞线程安全的队列,适用于高并发场景。
这些队列提供了不同的特性和性能特点,适用于不同的应用场景。例如,如果你需要处理具有优先级的任务,可以使用 PriorityBlockingQueue。如果你需要一个不存储任何元素而是直接将生产的元素传递给消费者的队列,那么 SynchronousQueue 可能是合适的选择。
在选择阻塞队列时,需要考虑队列的特性,如是否有界、是否支持优先级、是否支持延迟处理等。此外,还需要考虑预期的使用模式,例如,是否会有多个生产者和消费者,以及它们之间的交互模式。了解这些队列的特点和适用场景,可以帮助你更好地在多线程程序中管理数据的生产和消费。
四.多线程下使用哈希表
HashMap肯定不行,是线程不安全的
HashTable 给HashMap的关键方法加锁来保证线程安全
Hashtable的每个操作都是通过synchronized关键字进行同步的,这可能在高并发情况下成为性能瓶颈.因此就引出了ConcurrentHashMap(并发HashMap)
ConcurrentHashMap的优化:
- 1.最大的优化之处减小了锁的粒度 HashMap由数组+若干的链表 . 若是HashTable若修改两个不同的链表中的数据,也会产生锁竞争,这也相当于给this加锁了;缩小了锁的粒度,就相当于把锁给到了每一个链表,此时若再修改两个不同链表中的值,就不会产生锁冲突了 ConcurrentHashMap相比于HashTable 大大缩小了锁冲突的概率,把一把大锁,转换成多把小锁了。
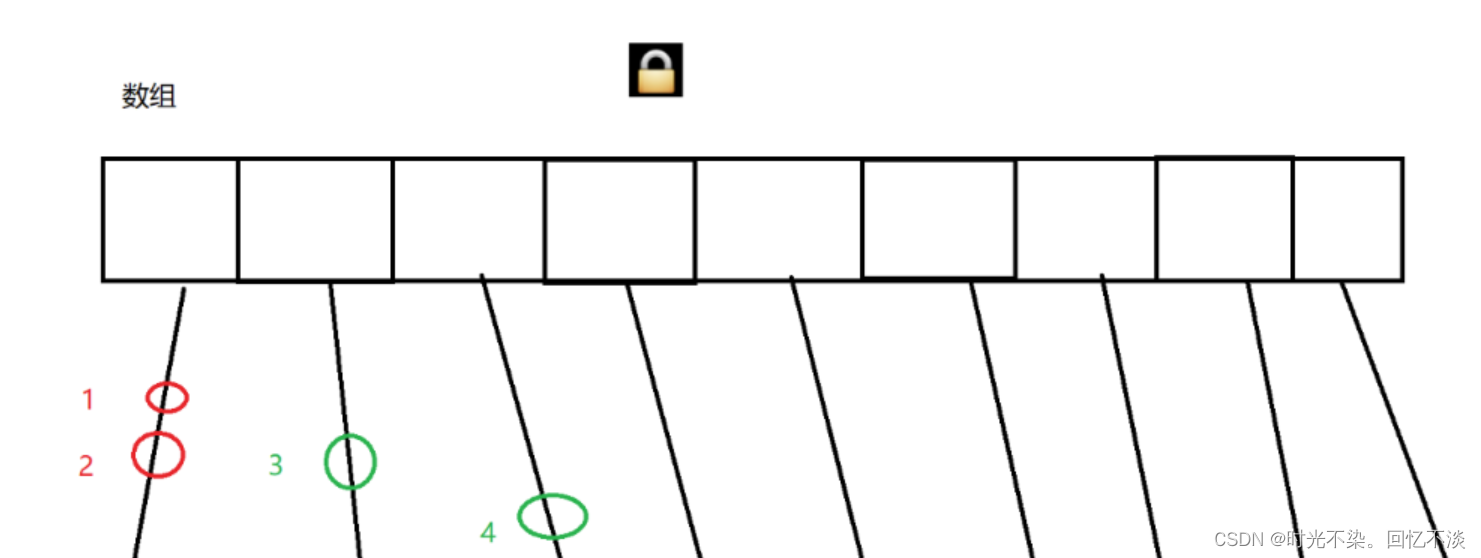
此时元素1和元素2在同一链表上,如果线程A修改(增删)元素1,线程B修改元素2,那么此时是有线程安全问题的(相邻两元素并发的插入或者删除的时候,相邻两节点的next指向可能会发生改变)。如果线程A修改(增或者删)元素3,线程B修改元素4,,这个情况相当于多个线程修改不同的变量,那么此时是没有线程安全问题的。
使用HashTable,锁冲突概率就太大了,任何两个元素的操作都会有锁冲突,即使是处在不同的链表上,这就是不用HashTable的主要原因。
ConcurrentHashMap做法是,每个链表有各自的锁(而不是大家共用同一个锁了),具体来说,就是使用每个链表的头结点,作为锁对象(两个线程针对同一个锁对象加锁才有锁竞争,才有阻塞等待,针对不同对象,没有锁竞争)。
此时,把锁的粒度变小了,针对12这个情况,是针对同一把锁进行加锁,会有锁竞争,会保证线程安全。针对34这个情况,是针对不同的锁进行加锁,不会有锁竞争了,没有阻塞等待,程序就会更快。 - 2.针对读操作,不加锁,只针对写操作加锁
读和读之间没有冲突;写和写之间有冲突,可以加锁;读和写之间没有冲突,但是很多场景下,读写之间不加锁控制,如果写操作不是原子的,那么会产生脏读,所以使用了 volatile 保证了原子性。 - 3.充分的使用了CAS原子操作~减少了一些加锁 -比如针对哈希表元素个数的维护
- 4.针对扩容操作的优化:
扩容本质上是创建一个更大的数组,把旧的Hash表中的元素都给搬运到新的数组上,如果Hash表的元素本身非常多,这里的扩容操作就会消耗很长时间.
扩容优化:HashMap的扩容操作是一把梭哈 . 在某次插入元素的操作中,整体完成扩容…而ConcurrentHashMap则是每次操作都只是搬运一部分元素~~就是在扩容的过程中,同时存在两份哈希表,一份是旧的,一份是新的.插入操作,直接往新的上插,删除操作,新的旧的都删除,查找操作新的和旧的都需要查询.
小结:
一.Hashtable和HashMap、ConcurrentHashMap 之间的区别?
- HashMap: 线程不安全. key 允许为 null
- Hashtable: 线程安全,使用 synchronized 锁 Hashtable 对象, 效率较低,key 不允许为 null
- ConcurrentHashMap: 线程安全,使用 synchronized 锁每个链表头结点, 锁冲突概率低, 充分利用
- CAS 机制,优化了扩容方式,key 不允许为 null
二. ConcurrentHashMap在jdk1.8做了哪些优化?
- 取消了分段锁, 直接给每个哈希桶(每个链表)分配了一个锁(就是以每个链表的头结点对象作为锁对象)。将原来 数组 + 链表 的实现方式改进成 数组 + 链表 / 红黑树 的方式,当链表较长的时候(大于等于8 个元素)就转换成红黑树。
- PS:分段锁是 Java1.7 中采取的技术,Java1.8 中已经不再使用了,简单的说就是把若干个哈希桶分成一个"段", 针对每个段分别加锁,目的也是为了降低锁竞争的概率。当两个线程访问的数据恰好在同一个段上的时候, 才触发锁竞争。
三.ConcurrentHashMap的读是否要加锁?
读操作没有加锁,目的是为了进一步降低锁冲突的概率,为了解决脏读,保证读到刚修改的数据, 搭配了