题目:GaitSet 将跨视角步态识别识别任务中的步态视为一个集合
摘要:
作为一个可以在一定距离内识别的独特的生物特征,步态识别在预防犯罪、法医鉴定,和社会保障等方面具有广阔的应用前景,为了描述一个步态,现存的步态识别方法要么是步态模板方法(模板信息难以保存)要么是步态序列方法(由于要保留不必要的序列约束,所示会失去步态识别的灵活性)在这篇文章中我们提出了一个新奇的视角,将步态视为独立帧的步态序集合,我们提出了一个名为gaitset的新的网络来从步态集合中学习身份信息,基于集合的视角,我们的方法不受帧的排列的影响,可以很自然的整合不同场景下拍摄的不同视频的帧,比如不同的观看角度,不同的穿着不同的携带条件,实验表明,在非正常条件下行走时,我们的单个模型在CASIA-B数据集上达到了95%的rank1 精度,在OU-MVLP 数据集上达到l87.1%的准确率,这些方法表明了我们的方法的准确率达到了最先进的水平,在其他的大量的场景下我们的方法具有很强的鲁棒特性,在背包和穿大衣的行走条件下,我们的方法达到了87.2%和70.4%的准确率,这些都很大程度上超过了现存的最先进的方法,这些方法在小数量帧的样本上依旧可以达到很可观的准确率,比如在CASIA-B数据集仅有7帧的样本上可以达到82.5%的准确率。
1介绍
与其他的生物识别技术如虹膜指纹人脸识别技术不同,步态识别技术是一种独特的生物识别技术,它可以在一定距离下识别,不需要人的配合,也不会对人产生干扰,因此它在预防犯罪法医鉴定 社会保障中具有广阔的应用前景
然而步态识别受其他外部特征的影响,如行走速度、穿着、携带物,相机视角和帧速度,在研究中主要有两种方法识别步态,将步态视为图像和将步态视为视频序列,第一种方法将所有的步态轮廓压缩为一张图片,或者称为步态模板,步态模板很简单容易执行,但是步它容易丢失时间和空间细粒度信息,不同的是第二种方法是直接从原始步态序列中提取特征,然而这些方法易受外部因素干扰,像3DCNN这样的可以提取连续信息的深度神经网络比起单个模板和步态能量图更难以训练,为了解决这些问题我们提出了一种新的视角——将步态轮廓视为集合,作为一个周期运动,步态可以表示为一个周期,,一个轮廓序列中包含一个步态周期 从图一中可以看到不同位置的轮廓具有不同的外观,即使它们被打乱,也很容易仅仅依靠观察他们的外观将他们恢复成原顺序,因此我们假设一个轮廓的外观已经包含了它的位置信息,在这种假设下,步态序列的顺序信息不再重要,我们可以直接将步态视为一个提取时间信息的集合,我们提出了一个端到端的深度学习模型——gaitset,模型架构在图二中已展示,我们的输入时一个步态轮廓的集合,首先使用CNN从每个轮廓中单独的提取帧级别的特征,其次,SetPooling 方法将帧级别的特征整合为集合级别的特征,因为方法是用在高级别的特征映射图上而不是原始的步态轮廓图,所以比起步态模板,它更容易保存时空信息,这将会在实验4.3中被证明,水平金字塔的映射架构将集合特征映射到更具有判别性的空间中,来获得更高层次的特征,该方法的优越性如下:
更具灵活性:我们的模型非常的灵活,因为模型的输入除了轮廓的大小没有任何的限制条件,这就意味着,输入集合可以包含任何数量的,任何不同视角拍摄下的任何行走条件的非连续性轮廓,相关实验在4.4节中
更快:我们的模型可以直接识别步态的表征,而不是比较不同步态模板或者轮廓的相似性,因此每个步态轮廓的表征仅仅需要被计算一次,然后通过计算不同样本表征之间的欧几里得距离来完成识别任务
更有效:我们的模型很大程度上提高了CASIA-B 和OU-MVLP数据集上的性能,并且显示出面向视角和行走条件很强的鲁棒特性和在更大的数据集上的泛化能力
2相关工作
2.1 步态识别
步态识别任务可以分为基于模板的和基于序列的两种,第一种首先通过背景减法的方法获得每个帧的轮廓,其次在对齐的轮廓上渲染像素级别的运算符,第三通过机器学习方法(如典型相关分析CCA,线性判别分析,深度学习)提取步态特征,第四通过欧几里得距离或者其他的度量学习方法衡量表征对之间的相似性,最后通过分类器如最近邻分类器给模板分配一个标签
之前的工作大体上将流程分为了两部分,模板生成和模板匹配,生成是将步态压缩为一个图片如步态能量图GEI 还有CGI,模板匹配的方法有视角转化模型,学习两个视角的投影.....最近深度学习在大量的生成任务上表现出了很好的性能,同样也可以用于步态识别任务上
第二种方法基于视频序列的方法,直接将一个视频序列的轮廓作为输入,基于提取时间信息的方法它们可以被分为基于LSTM的方法和基于3DCNN的方法,这些方法的优点是:1)可以专注每一个轮廓获得更为全面的空间信息,2)可以获得更多的时间信息,因为使用了专门的架构来提取序列信息,然而这些优势付出的代价是高昂的计算成本。
2.2 无顺序集合上的深度学习
大多的深度学习工作主要关注规律的输入,如序列和图片,无序集合的概念首次在(PointNet)中被引入计算机视觉领域用来解决点云任务,使用无序集合,PointNet可以避免在量化过程中产生噪声和数据扩展,获得一个比较高的性能,因此基于无序集合的方法在点云任务中获得了广泛的应用,
最近这些方法被用于计算机视觉领域如内容推荐和图像字幕用来以集合的形式聚类特征,(Zaheer2017)这个论文进一步形式化了定义在集合上的深度学习任务,刻画了置换不变函数,据我们所致目前还没有将其应用于步态识别领域
3步态识别
在这一节中,我们描述了我们再一个步态轮廓的集合中学习具有鉴别力的信息的方法,整体的流程在图二中已画出
3.1问题公式化
首先我们制定我们的概念——将步态视为一个集合,给定一个含有N个人的数据集,他们的身份是yi i 从1-N 我们假定每一个人的步态剪影服从一分布Pi 这个分布只和他的身份有关系,因此一个人在一个或者多个序列的所有的剪影可以看做n个剪影的集合

在这种假设下,我们将步态识别任务通过三步实现
![]() F是卷积网络,旨在从所有剪影中提取帧级别的特征,G是一个置换不变函数,将帧级别的特征映射到集合级别,这里使用的是Setpooling 操作,H是用来从集合级别的特征学习具有判别性的表达,这个函数通过水平金字塔池化实现
F是卷积网络,旨在从所有剪影中提取帧级别的特征,G是一个置换不变函数,将帧级别的特征映射到集合级别,这里使用的是Setpooling 操作,H是用来从集合级别的特征学习具有判别性的表达,这个函数通过水平金字塔池化实现
输入Xi 是一个四维度的张量(S,C,H,W)

Set pooling
集合池 (SP) 的目标是聚合集合中元素的步态信息,表示为 z = G(V ),其中 z 表示集合级特征,V = {vj |j = 1, 2,..., n} 表示帧级特征。此操作有两个约束。首先,为了将集合作为输入,它应该是一个置换不变函数,其公式如下: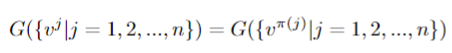
其中 π 是任何排列,实验表明,虽然 SP 的不同实例化确实对性能有影响,但它们没有太大差异,并且它们都大大超过了基于 GEI 的方法,作者的对比实验中用了max mean median 三个统计函数,同时也用了统计函数的联合函数、attention 机制
HPM水平金字塔映射
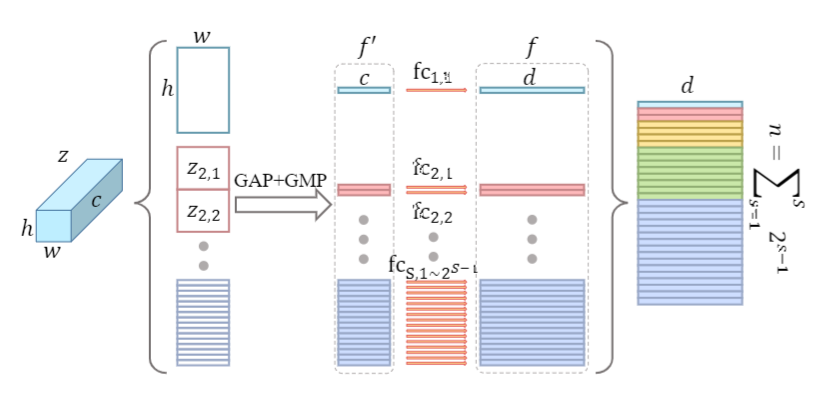
具体来说,HPM有S个尺度SP 提取的特征图被分成高度维度上的 2的s-1 次方条带,然后将全局池化应用于 3-D 条带以获得 1-D 特征。 划分后的特征图通过池化操作GAP+GMP![]() 最后一步是使用 FC 将特征 f 映射到判别空间。由于不同尺度的条带描绘了不同感受野的特征,每个尺度上的不同条带描绘了不同空间位置的特征,因此很自然地使用独立的
最后一步是使用 FC 将特征 f 映射到判别空间。由于不同尺度的条带描绘了不同感受野的特征,每个尺度上的不同条带描绘了不同空间位置的特征,因此很自然地使用独立的
Multilayer Global Pipeline
卷积网络的不同层具有不同的感受野。层越深,感受野越大。因此,浅层特征图中的像素侧重于局部信息和细粒度信息,而较深层的像素则侧重于更全局和粗粒度的信息。通过在不同层的应用 SP 提取的集合级特征具有类比属性。如图2的主要管道所示,卷积网络的最后一层只有一个SP。为了收集各种级别的集合信息,提出了多层全局管道(MGP)。它与主管道中的卷积网络具有相似的结构,将不同层的集合级特征添加到 MGP 中。MGP 生成的最终特征图也将通过 HPM 映射到 ∑ 2s-1 特征,MGP 后的 HPM 在主管道后不与 HPM 共享参数。
训练细节
训练细节在所有实验中,输入是一组大小为 64 × 44 的对齐轮廓。轮廓直接由数据集提供,并根据 (Takemura et al.2018b)。训练集中的集合基数设置为 30。选择 Adam 作为优化器(Kingma 和 Ba 2015)。HPM 中的尺度数设置为 5。 BA+ 三元组损失中的边距设置为 0.2。该模型使用 8 个 NVIDIA 1080TI GPU 进行训练。1)在CASIA-B中,小批由第3.5节中介绍的方式组成,p = 8和k = 16。我们将C1和C2中的通道数量设置为32,在C3和C4中设置为64,在C5和C6中设置为128。在此设置下,我们的模型的平均计算复杂度为8.6GFLOPs。学习率设置为 1e - 4。对于 ST,我们训练我们的模型 50K 次迭代。对于 MT,我们将其训练 60K 次迭代。对于 LT,我们将其训练 80K 次迭代。2)在 OU-MVLP 中,由于它包含比 CASIA-B 多 20 倍的序列,我们使用具有更多通道的卷积层(C1 = C2 = 64,C3 = C4 = 128,C5 = C6 = 256),并用更大的批量大小(p = 32,k = 16)对其进行训练。在前 150K 次迭代中学习率为 1e - 4,然后在 100K 迭代的其余部分更改为 1e - 5。
考虑到 max(·) 的 SP 在 NM 和 BG 子集上也实现了第二好的性能,并且具有最简洁的结构,我们在 GaitSet 的最终版本中将其选择为 SP。
比较了 HPM 中独立权重的影响。可以看出,使用独立权重在每个子集上将准确度提高了大约 2%。在实验中,我们还发现引入独立权重有助于网络更快地收敛。Tab 的最后两行。2 表明 MGP 可以为所有三个测试子集带来改进。这一结果与第3.4节中提到的理论一致,即从主管道的不同层中提取的集合级特征包含不同的有价值的信息。
实验结果
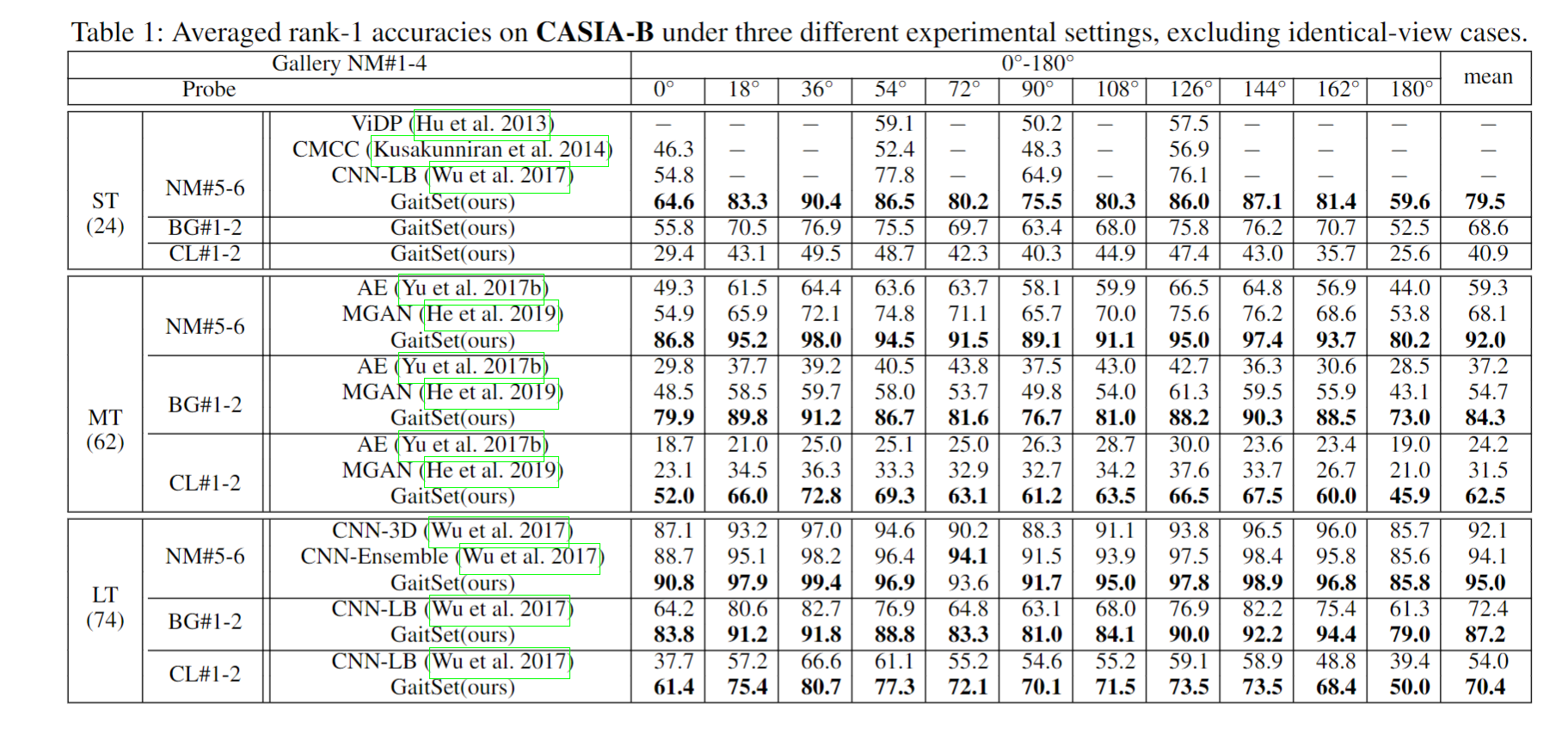
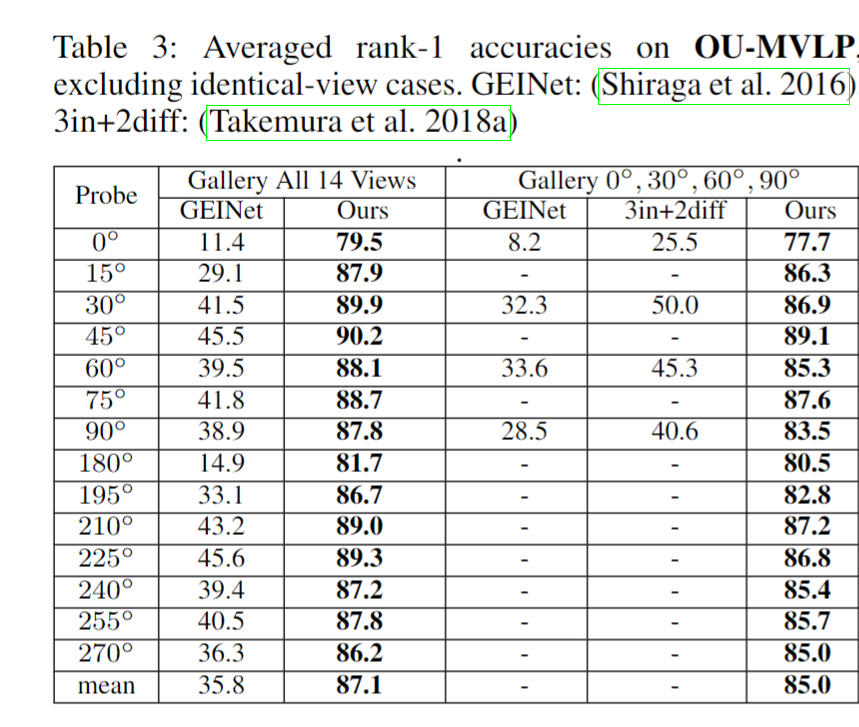
通过三个新颖的场景来研究 GaitSet 的实用性。1)当输入集仅包含几个轮廓时,它的表现如何。2)不同视图的轮廓能否提高识别精度。3)模型是否可以有效地从包含在不同行走条件下拍摄的轮廓的集合中提取判别表示。
1)我们的方法在只有 7 个轮廓的情况下达到了 82% 的准确率。结果还表明,我们的模型充分利用了步态的时间信息。由于1)随着轮廓数量的增加,精度单调上升。2)当样本包含超过25个轮廓时,精度接近最佳性能。这个数字与一个步态周期包含的帧数量一致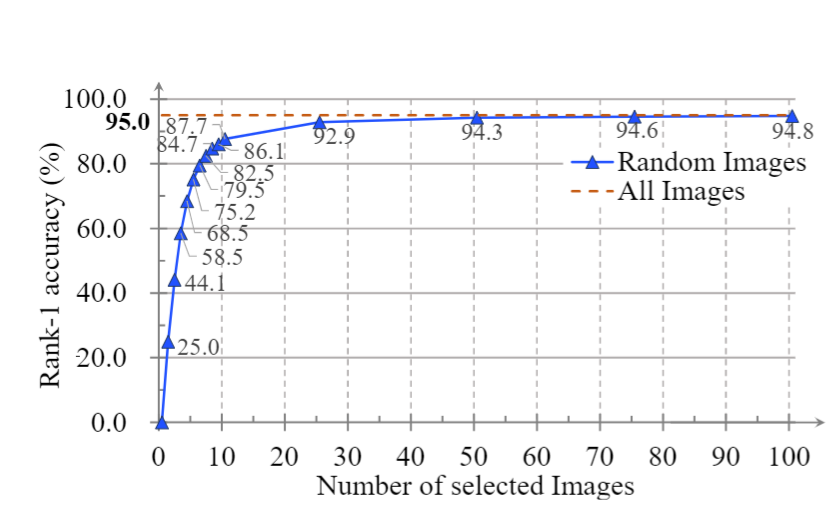 。
。
2)模型可以聚合来自不同视图的信息并提高性能。这可以通过我们在第4.2节中讨论的视图和准确性之间的模式来解释。包含输入集中的多个视图可以让模型收集并行和垂直信息,从而提高性能
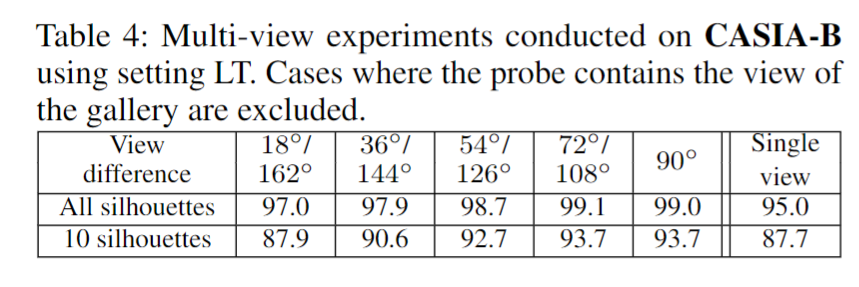
3)随着轮廓数的增加,准确率仍然会提高。其次,当轮廓数固定时,结果揭示了不同行走条件之间的关系。BG 和 CL 的轮廓包含大量但不同的噪声,这使得它们相互补充。因此,它们的组合可以提高准确性。然而,NM的轮廓包含很少的噪声,因此用其他两个条件的轮廓替换其中一些噪声不能带来额外的信息,而只能带来噪声,从而降低精度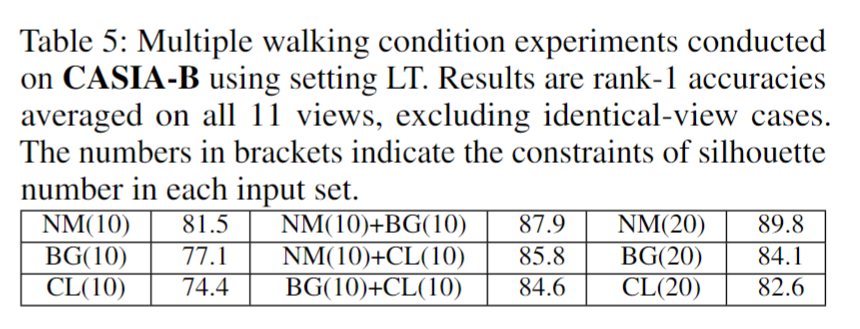
个人反思
今天读到张军平老师写的高质量读研中提到了gaitset 论文作者在写这篇文章以及做实验过程中的一些困难“两个人花了近3个月的时间来调试模型,却没有让步态集合方法获得实质性的性能提升。如果按常规的试错逻辑,大家可能就会放弃了。而他们却始终坚信自己的思路没有问题,还有改进的空间。通过不断的尝试和对技术方案的细微调整,最终,这一方法取得了突破性的进展。”这种精神很值得我们学习,耐得住寂寞,享受研究的过程,不断地突破自己的认知,这才是科研的意义,今天又重新学习了Gaiset 这篇文章,又学到了不少知识和研究方法,比如HPM水平金字塔映射具体是怎么实现的,set 集合的motivation 无序集的概念是来自于PointNet,置换不变函数参考了DeepSet,HPM是在行人重识别领域HPP 的基础上进行改进,最终的置换不变函数选取了Max 因为它简单且高效,在Problem Formulation中 将问题抽象为函数表达,使得实现过程更加清晰,在4.4 Practicality 实验章节中还对gait set 的实用性进行了分析,结果表明 在输入集仅包含几个轮廓时也能实现很好的效果,不同视图的轮廓能否提高识别精度,模型可以有效地从包含在不同行走条件下拍摄的轮廓的集合中提取判别表示。行人重识别的很多方法可以用在步态识别。各个领域都是互通的,所以以后读论文不能只局限在步态领域,要广泛涉猎,大量阅读提高自己的知识面。