论文信息
题目:TartanVO: A Generalizable Learning-based VO
作者:Wenshan Wang, Yaoyu Hu
来源:ICRL
时间:2021
代码地址:https://github.com/castacks/tartanvo
Abstract
我们提出了第一个基于学习的视觉里程计(VO)模型,该模型可推广到多个数据集和现实场景,并且在具有挑战性的场景中优于基于几何的方法。
我们通过利用 SLAM 数据集 TartanAir 来实现这一目标,该数据集在具有挑战性的环境中提供了大量多样化的合成数据。此外,为了使我们的 VO 模型能够跨数据集泛化,我们提出了一个大规模损失函数,并将相机内在参数合并到模型中。
实验表明,仅在合成数据上进行训练且无需任何微调的单一模型 TartanVO 可以推广到现实世界的数据集(例如 KITTI 和 EuRoC),在具有挑战性的轨迹上表现出相对于基于几何的方法的显着优势。
Introduction
基于几何的方法 [2,3,4,5] 和基于学习的方法 [6,7,8,9] 都取得了令人印象深刻的进展。然而,为实际应用开发稳健可靠的 VO 方法仍然是一个具有挑战性的问题
一方面,基于几何的方法在许多现实生活中不够稳健[10, 11]。
另一方面,虽然基于学习的方法在许多视觉任务上表现出了强大的性能,包括对象识别、语义分割、深度重建和光流,但我们还没有看到同样的情况发生在 VO 上。
现有的 VO 模型训练的多样性不足,这对于基于学习的方法能够泛化至关重要。
其次,当前大多数基于学习的 VO 模型都忽略了问题的一些基本性质,而这些性质在基于几何的 VO 理论中得到了很好的阐述。
为此,我们提出了一种基于学习的方法,可以解决上述两个问题,并且可以跨数据集泛化。我们的贡献有三个方面。
- 我们通过比较不同数量的训练数据的性能来证明数据多样性对 VO 模型泛化能力的关键影响。
- 我们设计了一个尺度损失函数来处理单目 VO 的尺度模糊性。
- 我们在 VO 模型中创建一个内在层 (IL),以实现跨不同相机的泛化。
Related Work
为了提高性能,端到端 VO 模型往往具有与相机运动相关的辅助输出,例如深度和光流。通过深度预测,模型通过在时间连续图像之间施加深度一致性来获取监督信号 [17, 21]。此过程可以解释为匹配 3D 空间中的时间观察结果。时间匹配的类似效果可以通过产生光流来实现,例如,[16,22,18]联合预测深度、光流和相机运动。
光流也可以被视为明确表达 2D 匹配的中间表示。然后,相机运动估计器可以处理光流数据,而不是直接处理原始图像[20, 23]。如果以这种方式设计,甚至可以根据可用的光流数据单独训练用于估计相机运动的组件[19]。我们遵循这些设计并使用光流作为中间表示。
众所周知,单目 VO 系统存在尺度模糊性。然而,大多数监督学习模型没有处理这个问题,而是直接使用模型预测和真实相机运动之间的差异作为监督[20,24,25]。在[19]中,通过将光流划分为子区域并在这些区域之间施加运动预测的一致性来处理尺度。在非学习方法中,如果 3D 地图可用,则可以解决尺度模糊性[26]。 Ummenhofer 等人[20]引入深度预测来校正尺度漂移。 Tateno 等人 [27] 和 Shen 等人 [28] 通过利用 SLAM 系统的关键帧选择技术改善了尺度问题。最近,Zhan 等人[29]使用 PnP 技术来显式求解比例因子。上述方法给 VO 系统带来了额外的复杂性,然而,对于单目设置,尤其是在评估阶段,尺度模糊性并没有完全被抑制。
相反,一些模型选择只产生符合规模的预测。 Wang等人[30]通过在计算损失函数之前对深度预测进行归一化来减少单目深度估计任务中的尺度模糊性。同样,我们将通过定义新的最大尺度损失函数,专注于预测平移方向,而不是从单目图像中恢复全尺寸。
当对来自新环境或新相机的图像进行测试时,基于学习的模型会遇到泛化问题。大多数 VO 模型都是在同一数据集上进行训练和测试的 [16,17,31,18]。一些多任务模型[6,20,32,22]仅测试其在深度预测上的泛化能力,而不是在相机姿态估计上的泛化能力。最近的努力,例如[33],使用模型适应来处理新环境,但是,需要在每个环境或每个摄像机的基础上进行额外的训练。在这项工作中,我们提出了一种通过将相机内在函数直接合并到模型中来实现跨相机/数据集泛化的新颖方法。
Approach
Background
我们关注单目 VO 问题,该问题采用两个连续的未失真图像 { I t , I t + 1 } \{I_t, I_{t+1}\} {It,It+1},并估计相对相机运动 δ t t + 1 = ( T , R ) δ^{t+1}_t = (T, R) δtt+1=(T,R),其中 T ∈ R 3 T ∈ \mathbb{R}^3 T∈R3 是 3D 平移, R ∈ s o ( 3 ) R ∈ so (3) R∈so(3) 表示 3D 旋转。根据对极几何理论[34],基于几何的 VO 有两个方面。
首先,从 I t I_t It和 I t + 1 I_{t+1} It+1中提取并匹配视觉特征。
然后使用匹配结果,计算导致恢复最大尺度相机运动 δ t t + 1 δ^{t+1}_t δtt+1的基本矩阵。
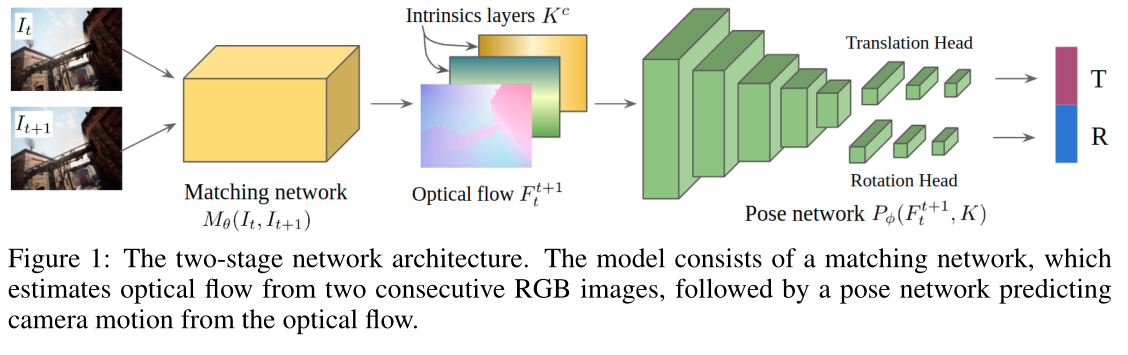
我们的模型由两个子模块组成。
一个是匹配模块 M θ ( I t , I t + 1 ) M_θ(I_t, I_{t+1}) Mθ(It,It+1),从两个连续的 RGB 图像(即光流)。
另一个是位姿模块 P ϕ ( F t t + 1 ) P\phi(F_t^{t+1}) Pϕ(Ftt+1),它从匹配结果中恢复相机运动 δ t t + 1 δ_t^{t+1} δtt+1(图 1)。
这种模块化设计也广泛应用于其他基于学习的方法,特别是无监督 VO
Training on large scale diverse data
泛化能力一直是基于学习的方法最关键的问题之一。之前的大多数监督模型都是在 KITTI 数据集或由微型飞行器(MA V)收集的 EuRoC 数据集 [36]。
大多数无监督方法也只在非常统一的场景中训练模型(例如 KITTI 和 Cityscape [37])。据我们所知,目前还没有基于学习的模型表现出在多种类型场景(汽车/MA V、室内/室外)上运行的能力。为了实现这一目标,我们认为训练数据必须涵盖不同的场景和运动模式。
TartanAir [11] 是一个大规模数据集,具有高度多样化的场景和运动模式,包含超过 400,000 个数据帧。它提供多模态地面真实标签,包括深度、分割、光流和相机姿势。场景包括室内、室外、城市、自然和科幻环境。数据通过模拟针孔相机收集,该相机在 3D 空间中以随机且丰富的 6DoF 运动模式移动。
我们在任务中利用单目图像序列 { I t } \{I_t\} {It}、光流标签 { F t t + 1 } \{F ^{t+1}_t \} {Ftt+1} 和地面实况相机运动 { δ t t + 1 } \{δ^{t+1}_t\} {δtt+1}。我们的目标是共同最小化光流损耗 L f L_f Lf 和相机运动损耗 L p L_p Lp。端到端损耗定义为:
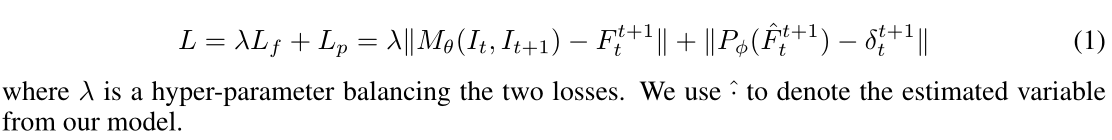
Up-to-scale loss function
在大多数现有的基于学习的VO研究中,模型通常忽略尺度问题并尝试用尺度来恢复运动。如果模型是使用相同的相机并在相同类型的场景中进行训练和测试的,这是可行的。但一旦相机发生变化就不可行。
按照基于几何的方法,我们仅从单目序列中恢复最大尺度的相机运动。知道尺度模糊度只影响平移 T T T ,我们为 T T T 设计了一个新的损失函数,并保持旋转 R R R 的损失不变。我们为 L P L_P LP 提出了两个大规模损失函数:余弦相似度损失 L p c o s L^{cos}_p Lpcos 和归一化距离损失 L p n o r m L^{norm}_p Lpnorm 。 L p c o s L^{cos}_p Lpcos 由估计的 T ^ \hat{T} T^ 和标签 T T T 之间的余弦角定义:

Cross generalization by encoding camera intrinsics
在对极几何理论中,从基本矩阵恢复相机位姿时需要相机本征(假设图像未失真)。事实上,基于学习的方法不太可能推广到具有不同相机内在特性的数据。想象一个简单的情况,相机更换了更大焦距的镜头。假设图像的分辨率保持不变,相同量的相机运动将引入更大的光流值,我们称之为内在模糊度。
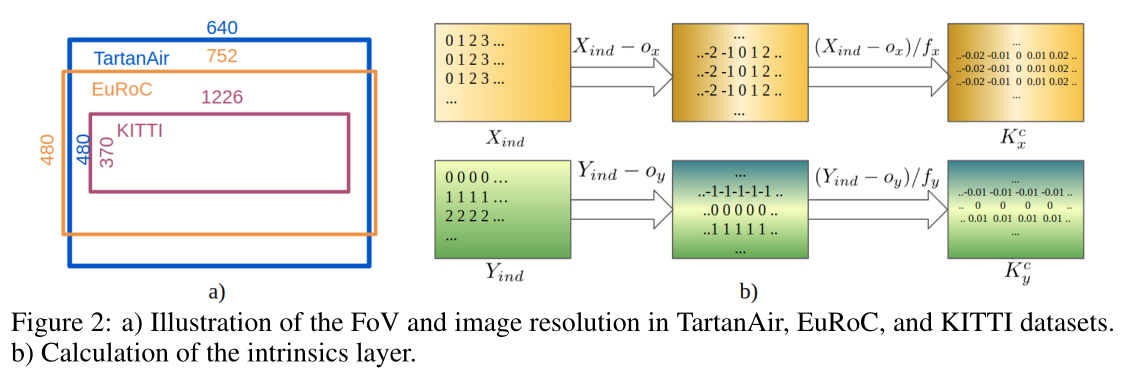
对于内在模糊性的一个诱人的解决方案是扭曲输入图像以匹配训练数据的相机内在。然而,这不太实用,尤其是当相机差异太大时。如图2-a所示,如果模型在TartanAir上训练,扭曲的KITTI图像仅覆盖TartanAir视野(FoV)的一小部分。训练后,模型学会利用视场中所有可能位置的线索以及这些线索之间的相互关系。扭曲的 KITTI 图像中不再存在一些线索,导致性能急剧下降。
Instrinsics layer
我们建议训练一个以 RGB 图像和相机内部参数作为输入的模型,以便于该模型可以直接处理来自各种相机设置的图像。
具体来说,我们设计了一个新的姿态网络 P ϕ ( F t t + 1 , K ) P_\phi(F^{t+1}_t , K) Pϕ(Ftt+1,K),而不是仅从特征匹配 F t t + 1 F^{t+1}_t Ftt+1 中恢复相机运动 T t t + 1 T^{t+1}_t Ttt+1 ,该网络也取决于相机内在参数 K = { f x , f y , o x , o y } K = \{f_x ,f_y,o_x,o_y\} K={fx,fy,ox,oy},其中 f x f_x fx和 f y f_y fy是焦距, o x o_x ox和 o y o_y oy表示主点的位置。

Data generation for various camera intrinsics
为了使模型可以跨不同相机推广,我们需要具有各种相机内在特性的训练数据。
TartanAir 只有一组相机内在函数,其中 f x = f y = 320 、 o x = 320 f_x = f_y = 320、o_x = 320 fx=fy=320、ox=320 和 o y = 240 o_y = 240 oy=240。我们通过随机裁剪和调整输入图像大小 (RCR) 来模拟各种内在函数。
如图3所示,我们首先在随机位置以随机大小裁剪图像。接下来,我们将裁剪后的图像调整为原始大小。
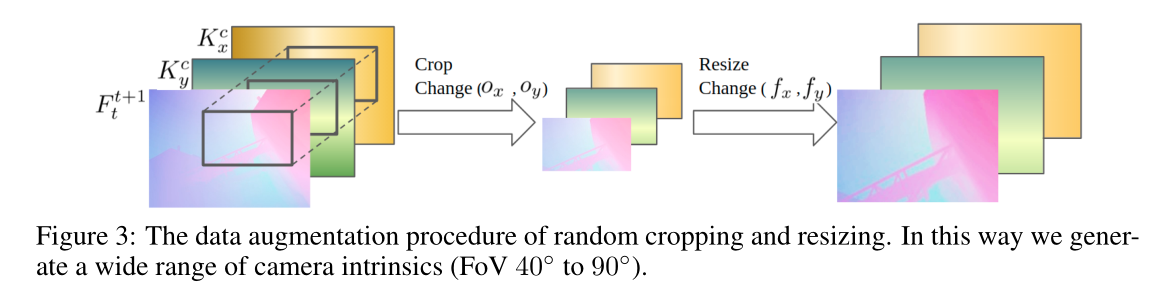
IL 的优点之一是,在 RCR 期间,我们可以使用图像裁剪 IL 并调整其大小,而无需重新计算 IL。为了覆盖 FoV 在 40° 到 90° 之间的典型相机,我们发现在 RCR 期间使用高达 2.5 的随机调整大小因子就足够了。
请注意,地面实况光流还应根据调整大小因子进行缩放。我们在训练中使用非常积极的裁剪和移动,这意味着光学中心可能远离图像中心。尽管所得的内在参数在现代相机中并不常见,但我们发现泛化能力得到了提高
Experimental